- The paper demonstrates that using a hybrid Transformer–ESN with an H-score objective significantly reduces O-RAN KPI dimensionality while preserving prediction accuracy.
- It achieves over 45× dimensionality reduction, yielding 41.9% and 29.9% MSE reductions for RSRQ and spectral efficiency, respectively, under limited data regimes.
- This innovative two-stage framework enables scalable, bandwidth-efficient KPI testing, promising improved performance for future 6G/NextG O-RAN deployments.
Introduction and Motivation
Open Radio Access Network (O-RAN) systems, pivotal for emerging 6G and NextG architectures, introduce operational flexibility but substantially increase test and monitoring complexity due to their high-dimensional, multivariate KPI landscape. Current O-RAN test specifications require the collection and tracking of extensive KPI sets across diverse layers and functional domains, resulting in large-scale, redundant, and highly-correlated metric streams from thousands of network elements. This explosion in dimensionality poses severe challenges for test scalability, transmission overheads, and efficient root-cause analysis, especially as O-RAN deployments scale.
To address these challenges, this work proposes moving away from exhaustive raw KPI monitoring towards data-driven extraction of compact, task-aligned low-dimensional representations, or embeddings, that robustly characterize underlying system state and service performance. These embeddings are intended to serve as a sufficient statistic, retaining all information critical for prediction and optimization tasks, while removing redundancy and irrelevant variation. The paper develops a two-stage framework—based on a novel hybrid Transformer–Echo State Network (ESN) architecture trained with an information-theoretic H-score objective—for O-RAN KPI processing and assessment.
System Flow and Architectural Overview
The proposed pipeline for O-RAN testing comprises sequential stages: KPI acquisition in a SDR-based testbed, preprocessing and aggregation, temporally-aware representation learning via the H-score-trained Transformer-ESN, and lightweight prediction using the learned embeddings.
Figure 1: System flow diagram outlining O-RAN KPI collection, preprocessing, feature extraction with Transformer-ESN, and KPI prediction.
The first stage extracts low-dimensional, task-relevant features from temporal KPI sequences using a hybrid neural model. The second stage evaluates these representations by training a simple MLP predictor on the embeddings to forecast key target KPIs—reference signal received quality (RSRQ) and spectral efficiency. Performance is benchmarked against models using the original high-dimensional input and established dimensionality reduction baselines.
A core methodological element is the use of the H-score as the training objective. Unlike mutual information maximization—which is intractable in high dimensions—the H-score leverages empirical covariances between latent features from input and output, providing a tractable variational proxy for learning sufficient low-dimensional statistics.
The decomposition involves finding functions fi(X) and gi(Y) such that the pointwise mutual information is approximated as PMI(x,y)≈i=1∑nfi(x)gi(y). The H-score, defined using empirical covariances and cross-moments, is then used as a trainable loss to guide deep feature extraction towards optimal sufficiency.
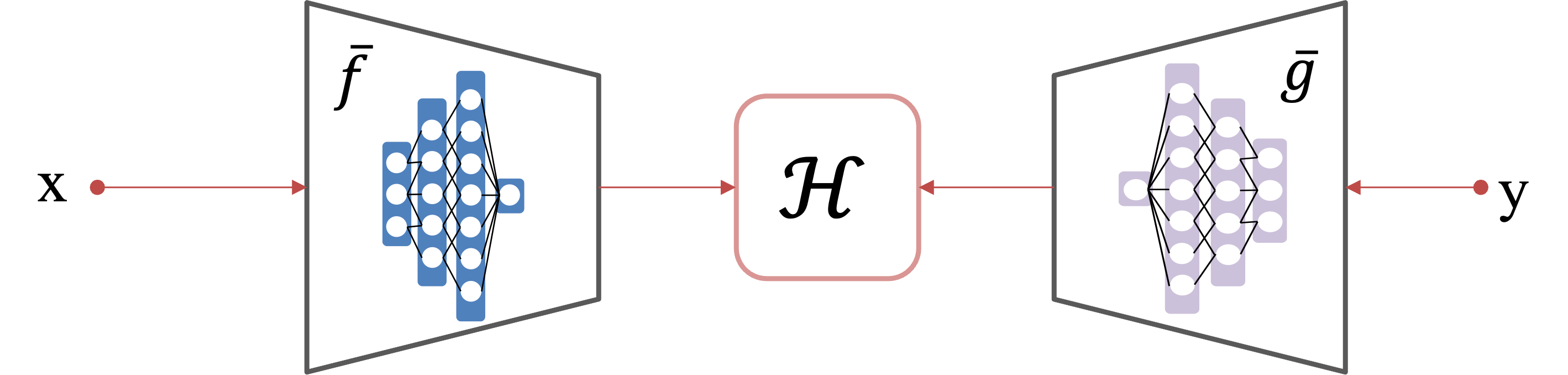
Figure 2: The structure of the H-score network aligning input (Transformer-ESN) and target (MLP) features in a shared latent space.
The feature extractor combines a Transformer encoder—responsible for capturing long-range dependencies and non-local correlations— with an ESN reservoir that models fast, fine-grained temporal transitions. Raw input sequences (e.g., 28 time steps of 13 KPIs) are embedded, passed through stacked Transformer layers, and projected into an ESN whose final reservoir state (possibly concatenated with sequence features) forms the n-dimensional representation.
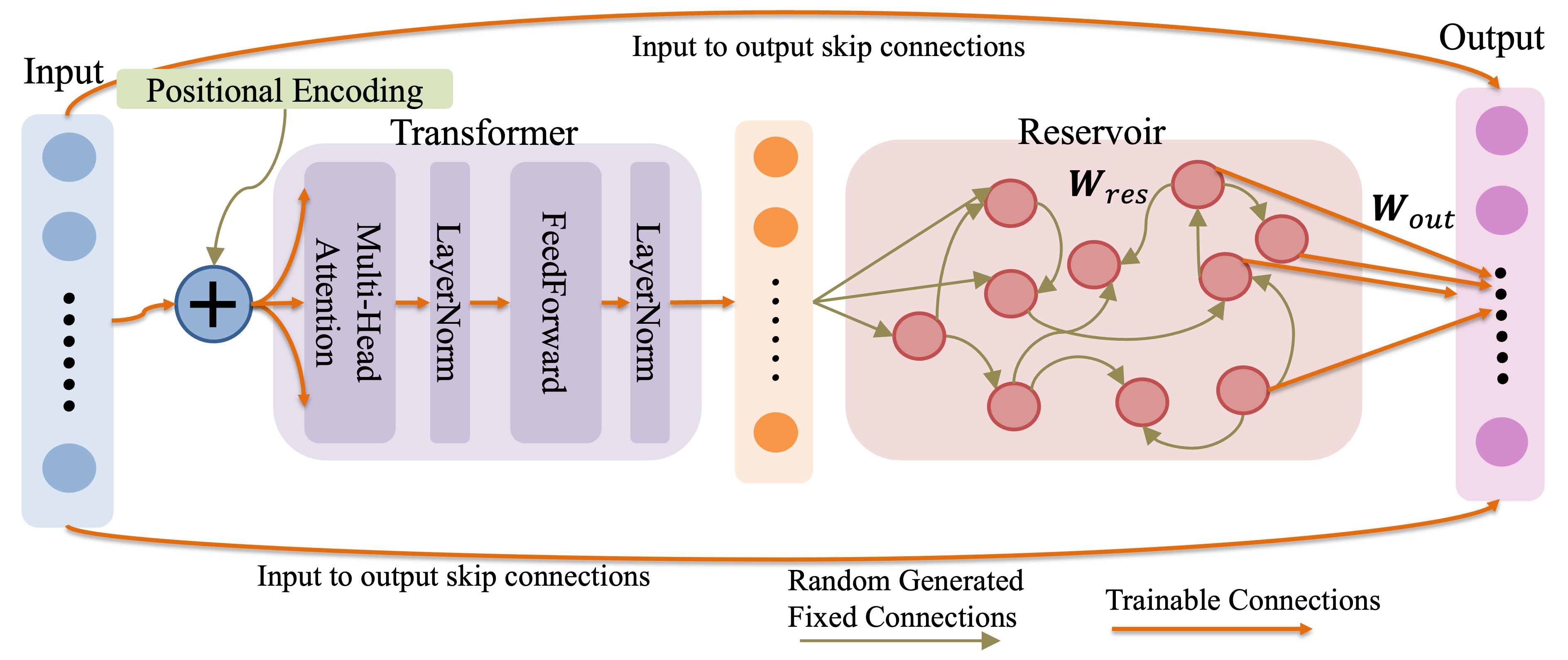
Figure 3: Detailed pipeline of the hybrid Transformer–ESN feature extraction mechanism for temporally-aware low-dimensional embedding generation.
This hybrid architecture is motivated by Transformer effectiveness in sequence modeling and ESN efficiency in capturing nonlinearity with minimal training (due to fixed random recurrent weights), yielding a robust, data-efficient pipeline for KPI sequence reduction.
Experimental Testbed and Dataset
Data were acquired from two O-RAN testbed deployments—one emulated in a cloud-based CCI xG platform, the other using local SDR hardware. The setup included a near-RT RIC, SDR-based BS/UE nodes, a video streaming stack, and an interferer for emulating real-world wireless variability.
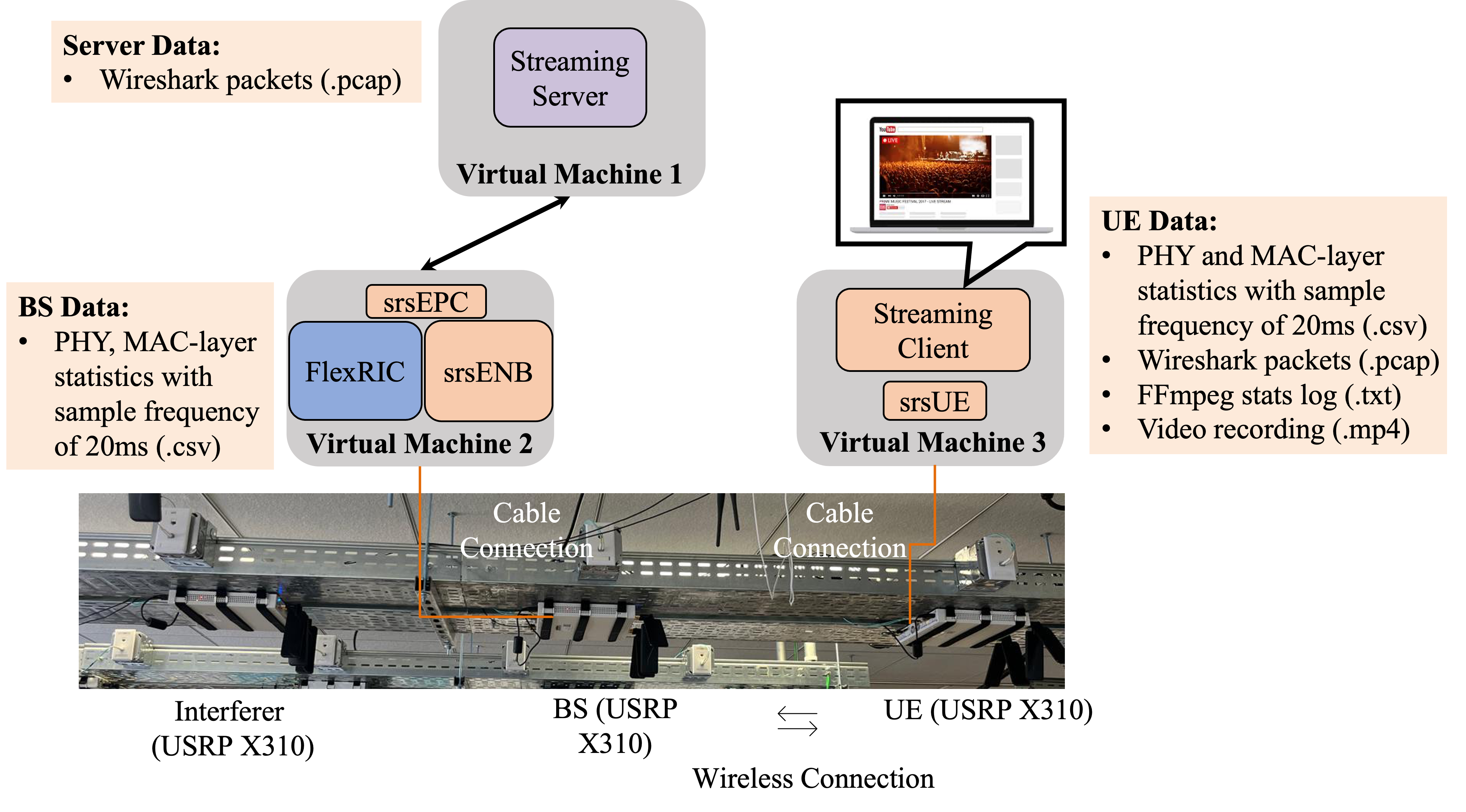

Figure 4: O-RAN testbed deployments integrating SDR-based radio elements, application-layer instrumentation, and controlled interference.
KPI logs were sampled at 20 ms granularity, preprocessed (averaging, filtering, missing value imputation), and arranged into sliding windows for input/target sequence pair extraction. The resultant dataset comprised 59,441 samples with 13 core O-RAN KPIs (including RSRP, SINR, BLER, delay, spectral efficiency). Public release supports reproducibility and benchmarking.
Empirical Results
Embedding Dimension Tradeoff
Empirical evaluation demonstrated rapid improvement in prediction MSE as embedding dimension n increased from 2 to 8, with diminishing returns thereafter. At n=8 (yielding >45× dimensionality reduction), prediction performance saturated, suggesting that 8 latent factors are sufficient for the core O-RAN KPI dynamics and service characterization.
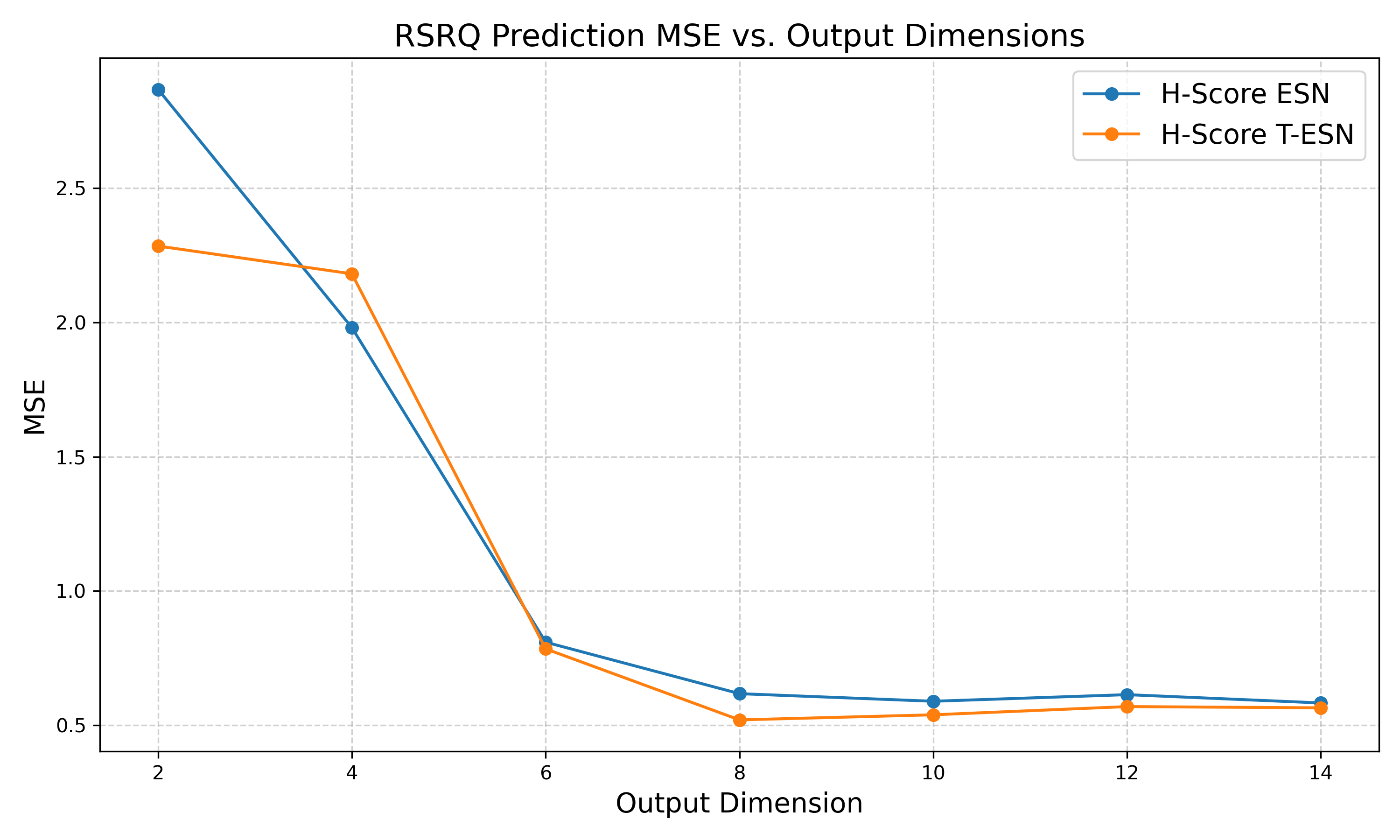
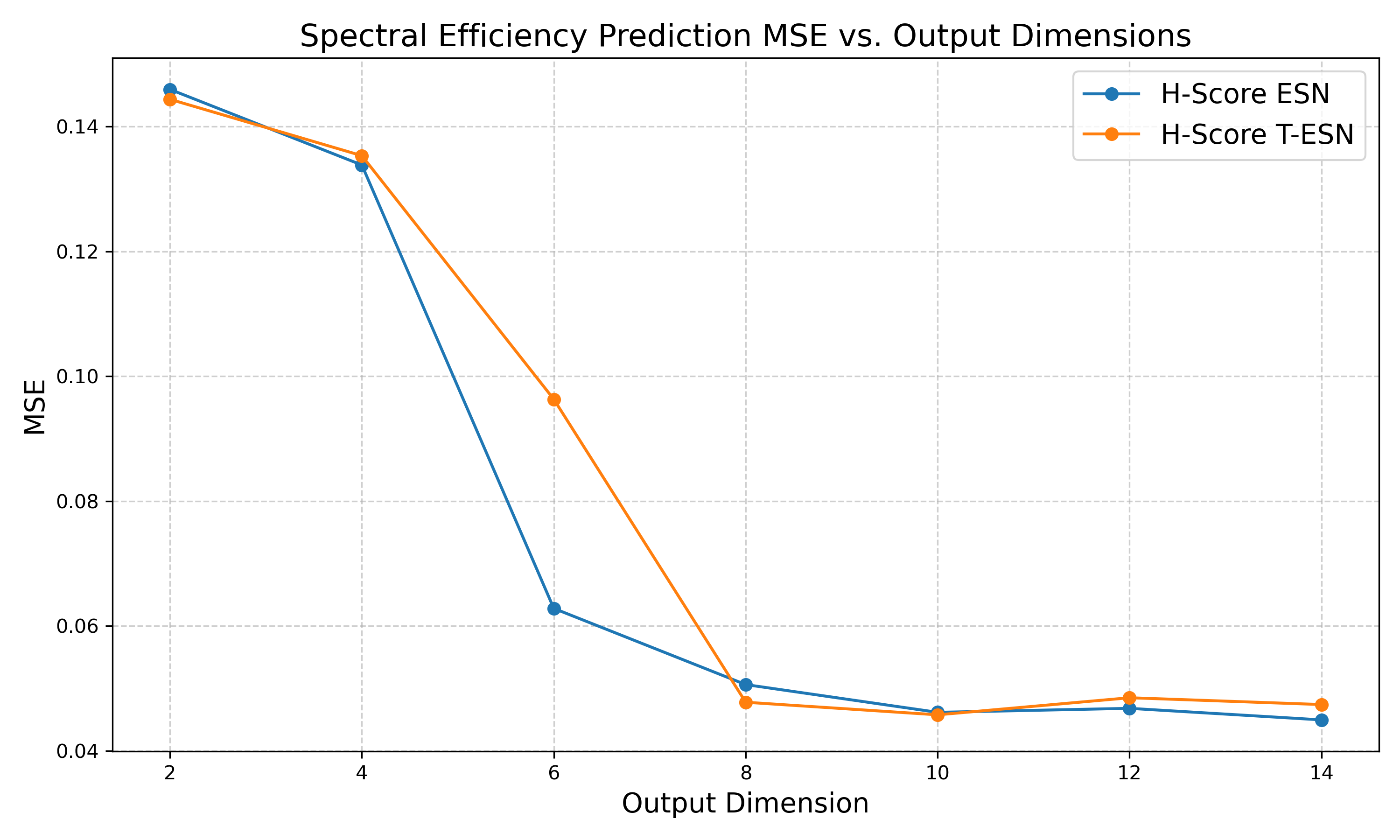
Figure 5: Effect of latent dimension on KPI prediction MSE, showing saturation by n=8.
Full Data Regime
In scenarios with abundant training samples and compute, direct modeling from all observed KPIs yielded strongest predictive accuracy (as expected). However, H-score-based embeddings with both pure ESN and Transformer-ESN architectures achieved nearly comparable results for both RSRQ and spectral efficiency, incurring only minimal increase in error relative to using all features. Autoencoder-based dimensionality reduction was notably inferior, confirming the necessity of task-relevant, information-theoretic objectives for sufficiency.
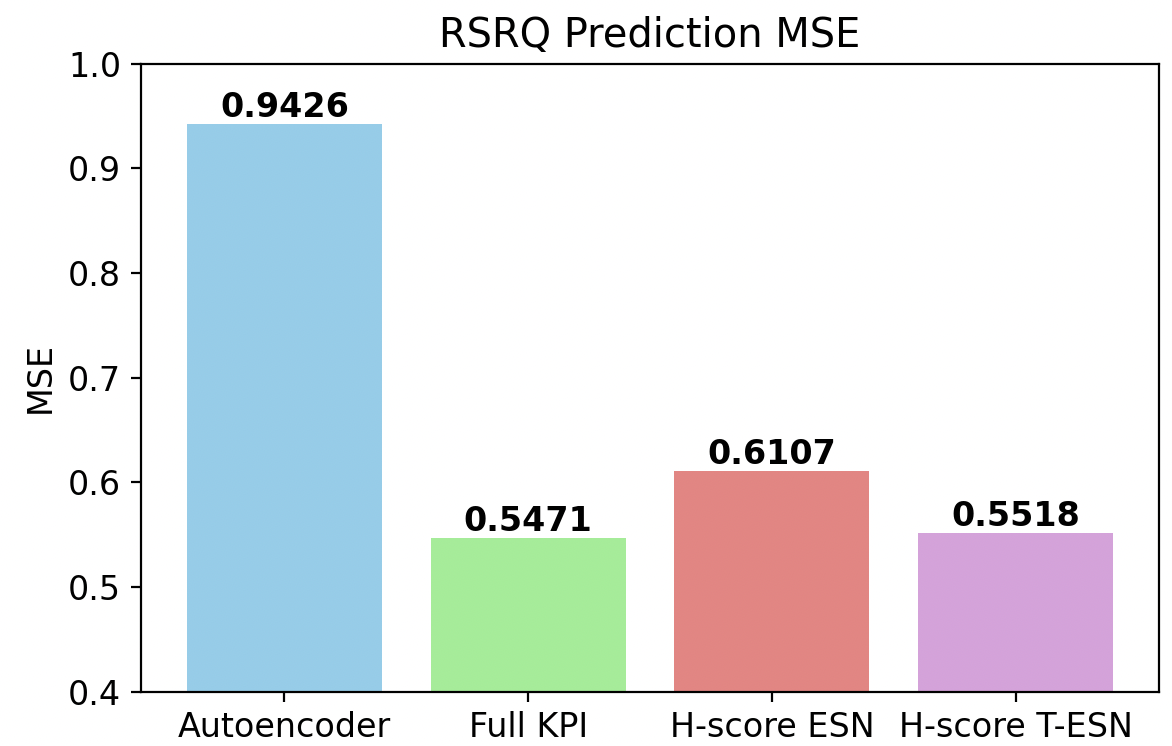
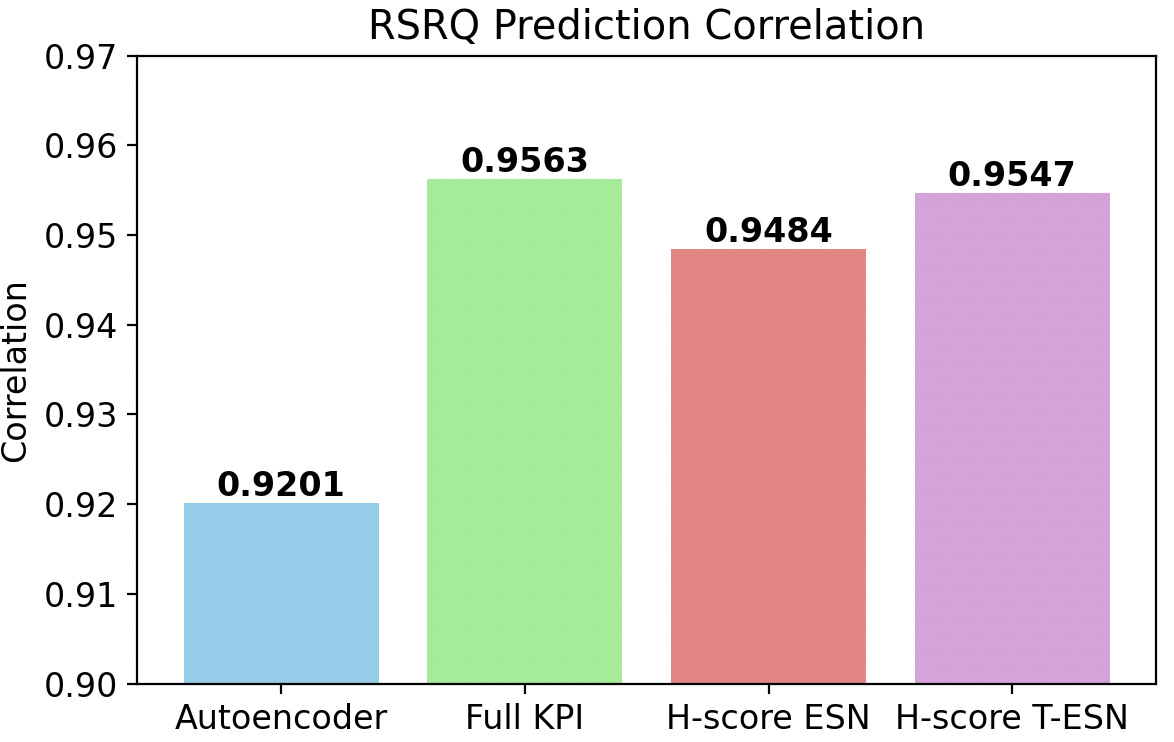
Figure 6: RSRQ prediction results under full training regime, comparing various feature extraction and prediction strategies.
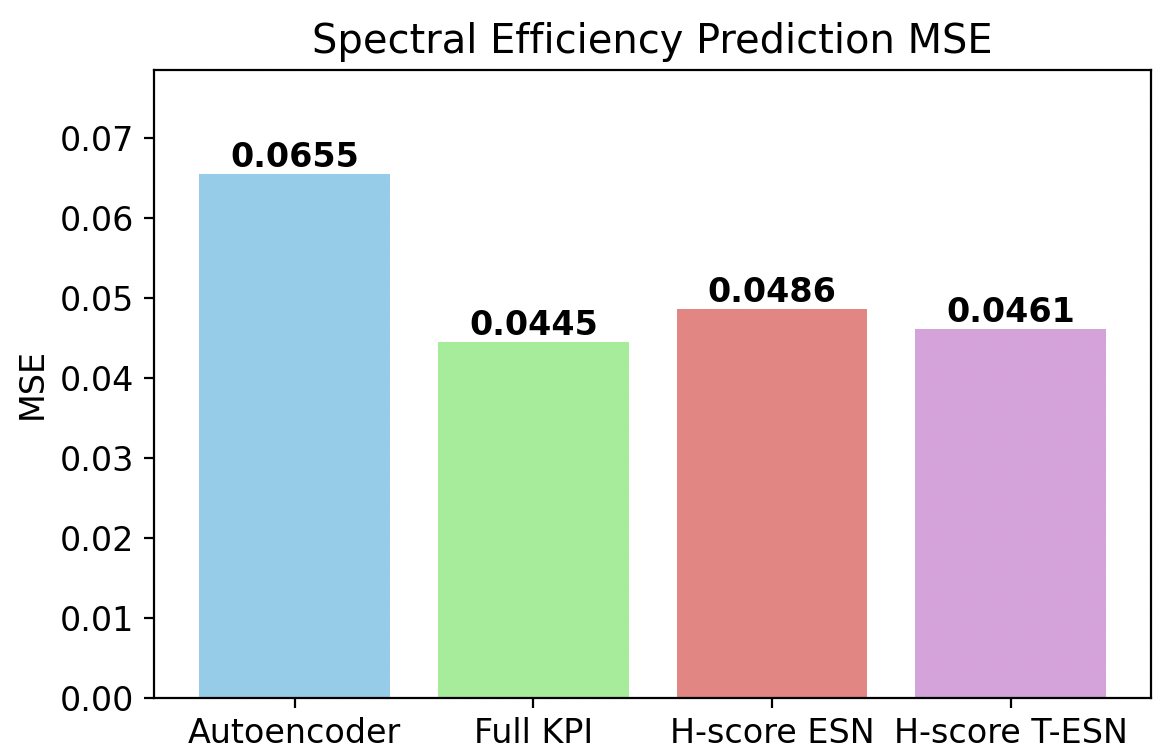
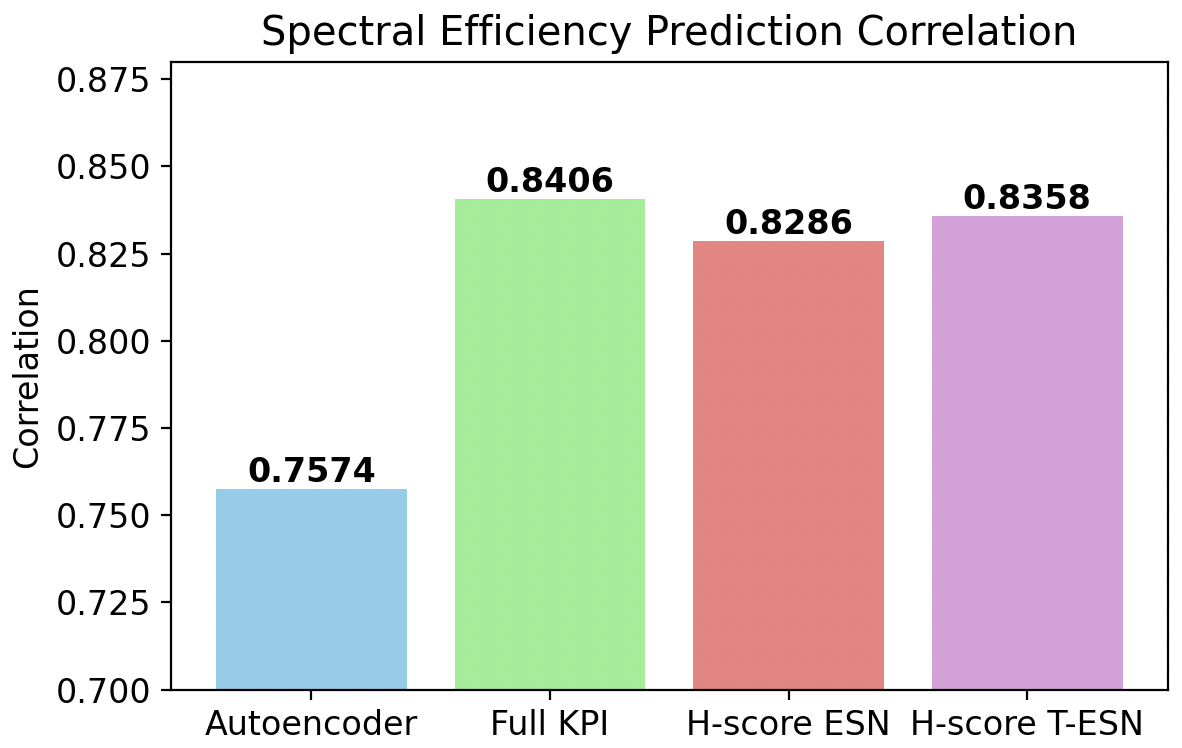
Figure 7: Spectral efficiency prediction under full-training regime; minimal gap exists between high-dimensional and H-score-based predictions.
Data-limited and Training-limited Regime
Under severe constraints—only 5% of data and a small number of training epochs—the superiority of H-score-based low-dimensional representations was pronounced. The performance of models directly trained on the full KPI set degraded significantly due to overfitting and sample complexity. In contrast, the H-score-trained Transformer-ESN achieved:
- 41.9% reduction in RSRQ prediction MSE
- 29.9% reduction in spectral efficiency prediction MSE
compared to the full-input baseline, under identical data/compute budgets. The compact, information-aligned latent representations dramatically improved sample efficiency and generalization.
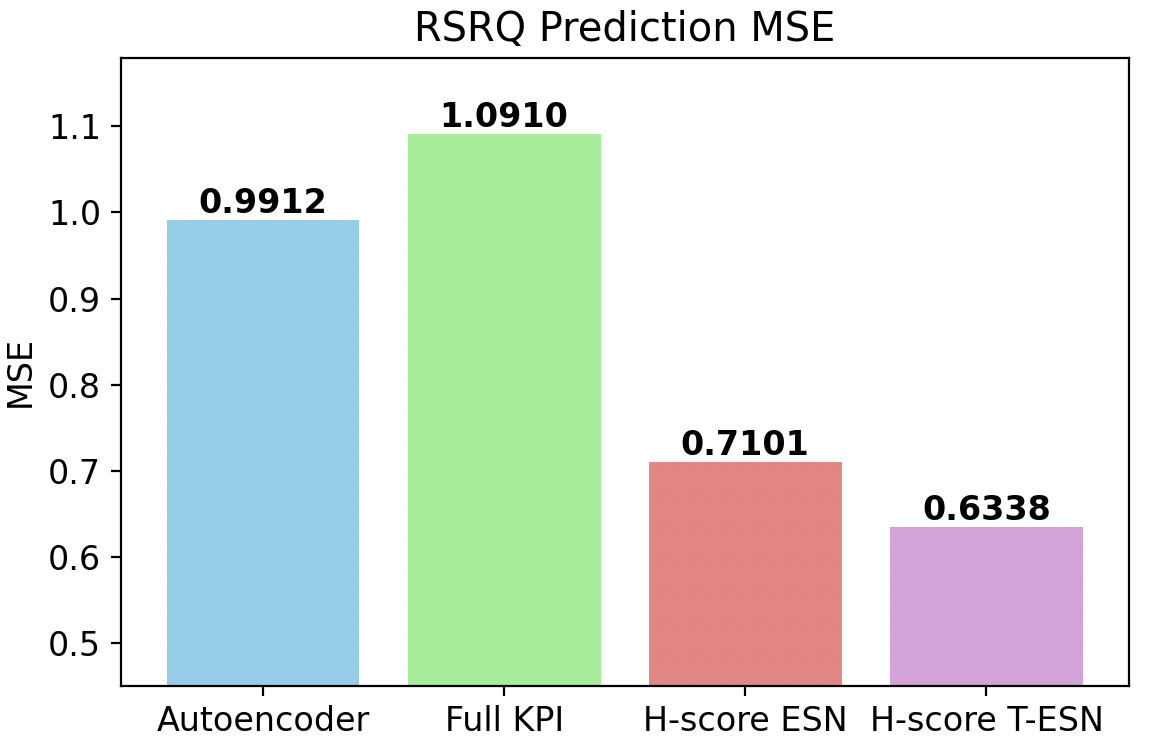
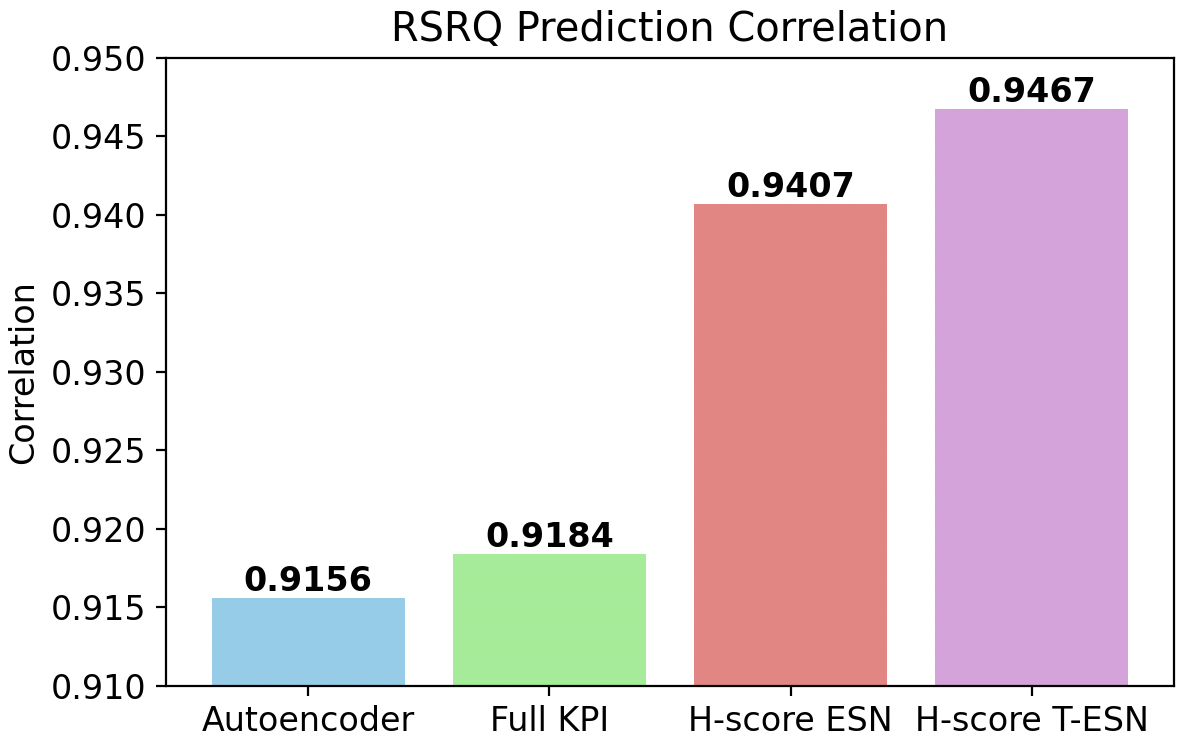
Figure 8: RSRQ prediction under data and time constraints: H-score T-ESN achieves lowest error and highest correlation.
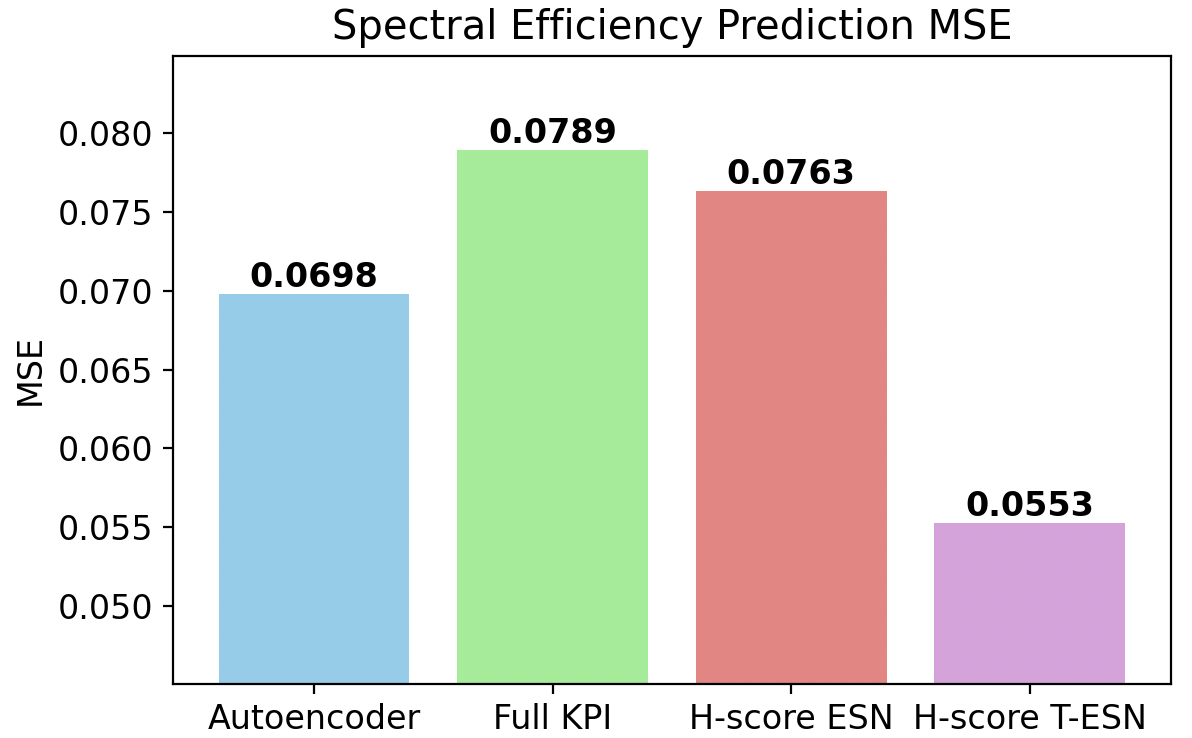
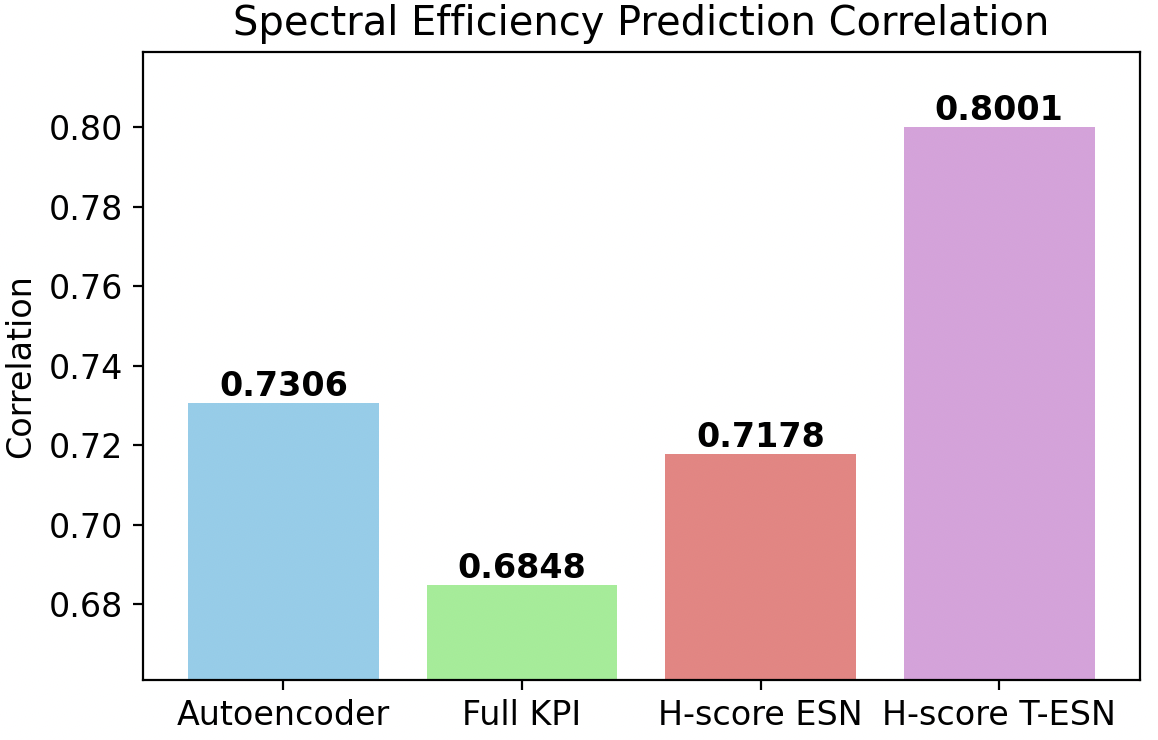
Figure 9: Spectral efficiency prediction in few-shot regime: H-score-based T-ESN significantly outperforms conventional and Autoencoder approaches.
Theoretical and Practical Implications
This work demonstrates that substantial portions of high-dimensional O-RAN KPI data are redundant for network assessment tasks, confirming that the dynamics are governed by a small number of latent variables. Information-theoretic training—particularly H-score maximization—yields low-dimensional embeddings with high task-utility and generalization, drastically reducing transmission and storage overheads in operational 6G/NextG O-RAN deployments.
Of particular note is the contradiction to the widespread paradigm that “more features always yield better accuracy in high-capacity low-bias regimes”; in practice, for data- and resource-limited O-RAN environments, compact representations can outperform full-dimensional predictors. These findings inform the design of future O-RAN SMO/ML pipelines, advocating for embedding-based KPI ingestion, bandwidth-frugal telemetry, and sample-efficient online adaptation.
Speculation and Future Directions
This framework opens pathways for explainable and adaptable O-RAN management. Extensions could target:
- Online, real-time adaptation of H-score embeddings for non-stationary environments.
- Structured embeddings incorporating explicit domain priors (e.g., causal structure).
- Integration with federated or privacy-aware O-RAN intelligence.
Further, the architecture is extensible to other multivariate time sequence analysis domains (industrial IoT, cyber-physical systems), catalyzing broader adoption of Transformer-Reservoir hybrids in sequence modeling with robust low-sample efficiency.
Conclusion
This paper presents a rigorous, empirically-validated two-stage framework for extracting low-dimensional, information-theoretic representations of high-dimensional O-RAN KPIs using a hybrid Transformer–ESN encoder trained with H-score maximization (2604.12958). The approach achieves strong accuracy–efficiency tradeoffs, particularly excelling in data-scarce and compute-limited test regimes. The findings motivate a shift in O-RAN test and analytics from exhaustive metric monitoring to judicious, task-centric embedding learning, with direct practical implications for the scalability and adaptability of next-generation wireless systems.