- The paper introduces a federated DRL framework that dynamically optimizes RU sleep control to decrease energy use while preserving user QoS.
- It evaluates centralized and continuous-action methods, showing that the TD3 approach outperforms DQN variants by achieving over 50% energy reduction.
- Federated TD3 demonstrates up to 43.75% faster convergence and 37.4% lower training energy, proving its scalability in dense Open RAN deployments.
Scalable Deep Reinforcement Learning for Energy-Efficient Open RAN
O-RAN Architecture and Motivation
Densely deployed base stations in RAN environments are the principal contributors to network energy consumption, and next-generation Open RAN (O-RAN) architectures exacerbate this due to their flexible yet large-scale deployments. To address mounting operational expenditures and the environmental impact, dynamic energy-saving strategies are indispensable without sacrificing QoS guarantees for UEs.
O-RAN's disaggregated architecture splits the traditional BS into RUs, DUs, and CUs, with RUs as dominant energy consumers due to RF chains and PA components. The architecture introduces a hierarchical control plane, comprising Near-RT RICs for low-latency execution and a Non-RT RIC for longer-timescale policy orchestration, interfaced through standardized A1/E2/O1 protocols. This separation creates an ideal substrate for the integration of scalable, AI-driven energy management solutions.
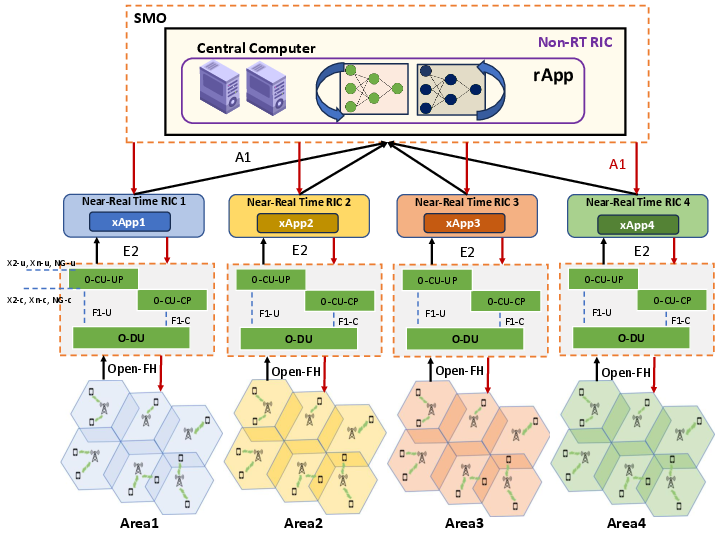
Figure 1: O-RAN system integrating 3GPP and O-RAN interfaces, distributed across four geographical zones, with Near-RT RICs for local xApp control and a central Non-RT RIC for policy aggregation.
The core optimization problem is the dynamic selection of sleep/active states for M distributed RUs serving K UEs, captured as an NP-hard combinatorial minimization of time-averaged network energy. The formulation is as an MDP, with the state encompassing UE downlink rates, historical RU activations, PRB utilization, and UE spatial coordinates—normalized to address the disparate dynamic ranges. Actions correspond to all possible binary RU activation vectors, and the reward function is a Lagrangian relaxation balancing normalized energy consumption and the fraction of unsatisfied UEs.
The per-timestep power model factors in (1) fixed operational power, (2) load-dependent transmission power proportional to PRB allocation and amplifier efficiency, and (3) state-transition power when switching RUs to active mode.
Centralized DRL Methods
Three centralized DRL approaches were designed:
- DQNMA exploits the full joint RU action space, outputting Q-values for all 2M activation vectors. While expressive, scalability collapses for M>10 due to exponential action dimensionality.
- DQNSA restricts each action to toggling a single RU state per step, reducing the space to $2M$ but compromising action expressiveness and adaptation speed.
- TD3, a continuous-action policy-gradient method, predicts activation likelihoods per RU and applies deterministic thresholding to realize binary actions. Dual critics and target smoothing mitigate Q-value overestimation, and policy update delays stabilize convergence.
Federated DRL in the O-RAN Control Hierarchy
Scalability and heterogeneity challenge centralized DRL, especially in multi-area O-RAN deployments. The proposed solution embeds a federated DRL training protocol: each regionally localized Near-RT RIC xApp maintains a DRL agent, performing local policy refinement using private environment data. Periodically, policy and value network parameters are aggregated (FedAvg) at the Non-RT RIC, synchronized across all regions, and redistributed, in alignment with O-RAN's hierarchical control interfaces.
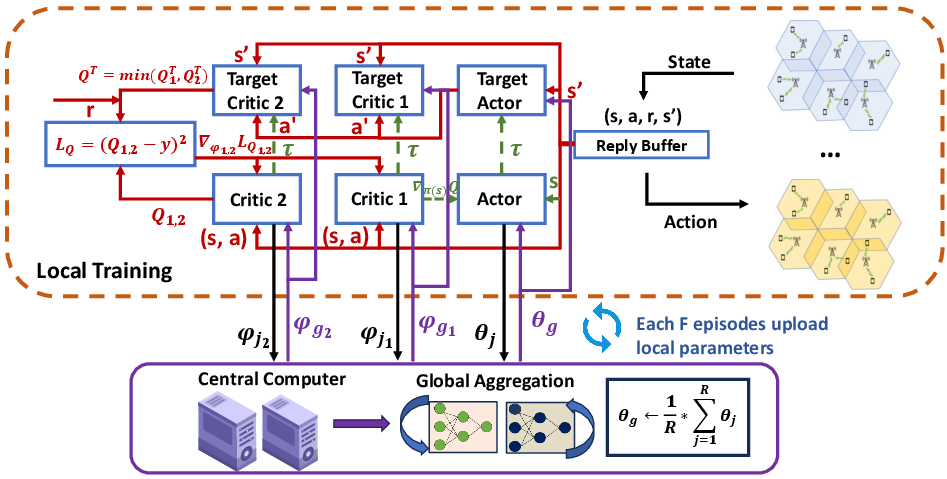
Figure 2: Fed-TD3 workflow, illustrating local actor/critic updates, parameter aggregation at the Non-RT RIC, and distribution of averaged models to regional xApps.
This design (1) curbs inter-region communication by eschewing raw data sharing, (2) supports client policy heterogeneity, and (3) preserves low latency for near-real-time control. Both Q-learning and policy-gradient variants are supported via parameter averaging, with critic sharing enhancing value function generalization and actor aggregation promoting robust policy updates.
Evaluation: Simulation Scenarios and Results
Simulations employ three physical layouts: single 500×500 m regions (6 RUs), extended 1000×1000 m areas (12 RUs), and composite 1000×1000 m macroregions (24 RUs, four subregions). UEs are assigned periodic mobility, and the UMi path-loss/fading model is used.
The comparative reward analysis demonstrates that TD3 consistently outperforms all DQN variants in both stability and final reward, affirming the necessity of continuous-action models for high-dimensional, combinatorial control.
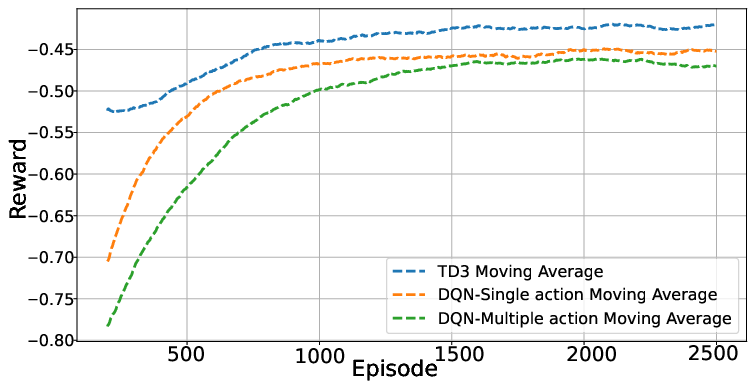
Figure 3: Reward trajectories for TD3, DQNMA, and DQNSA in small-scale settings, highlighting TD3 superiority.
In terms of energy consumption, all models deliver over 50% reduction compared to static-all-active RU operation, with TD3 achieving a further 6% advantage over DQNMA/DQNSA. As network size increases, DQNMA is omitted due to unmanageable action spaces, with TD3's energy savings remaining robust.
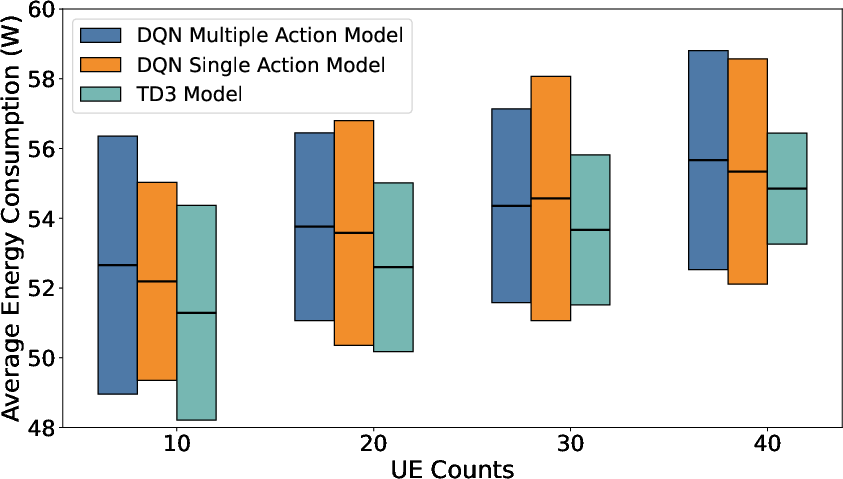
Figure 4: Average energy consumption in 500×500 m area by user density and model, with 6 RU deployment.
Federated DRL models (Fed-TD3, Fed-DQNMA, Fed-DQNSA) were then compared both in isolation and against centralized baselines. Fed-TD3 achieves up to 43.75% faster convergence (statistically significant; p=0.0309) and 37.4% lower total training energy than centralized approaches.
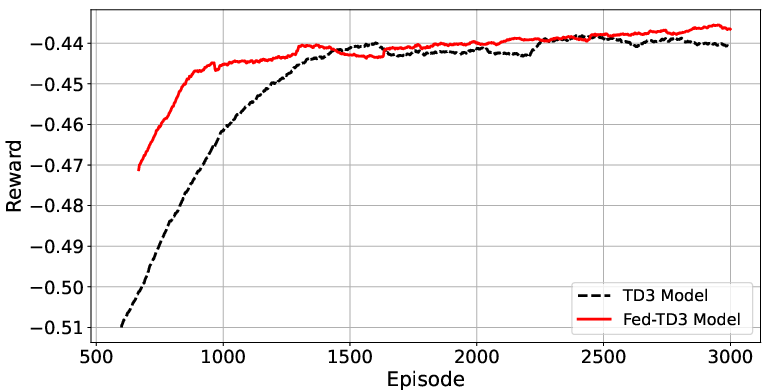
Figure 5: Fed-TD3 and centralized TD3: reward and convergence profile comparisons in small-region deployments.
All federated models substantially reduce training energy, attributed to both parallelized training and diminished communication overhead.
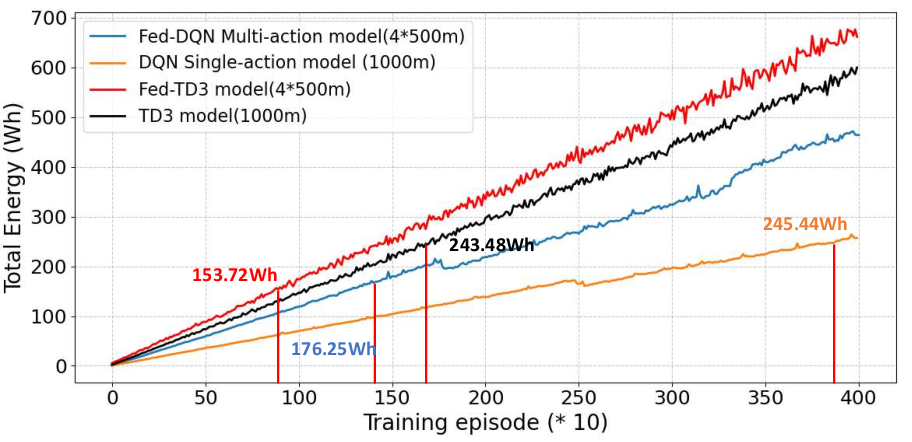
Figure 6: Cumulative training energy versus episode for federated and centralized models, revealing marked improvements by Fed-TD3 and Fed-DQNMA.
Performance generalization to composite macroregions confirms that federated policies scale and generalize, matching or exceeding centralized training in composite testbeds—especially as the action/state spaces grow.
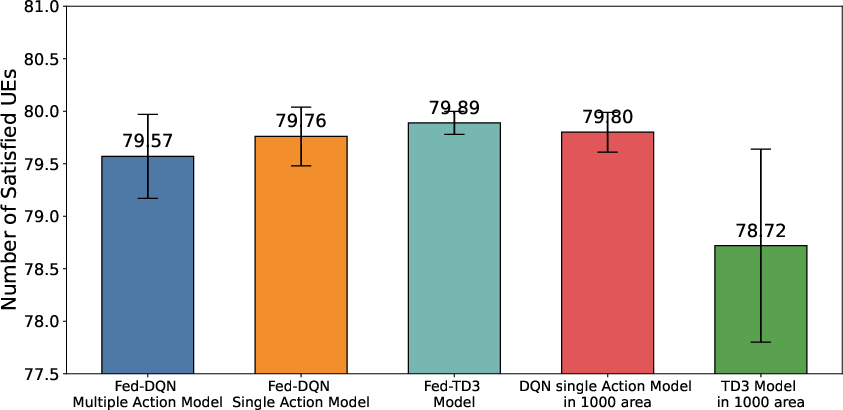
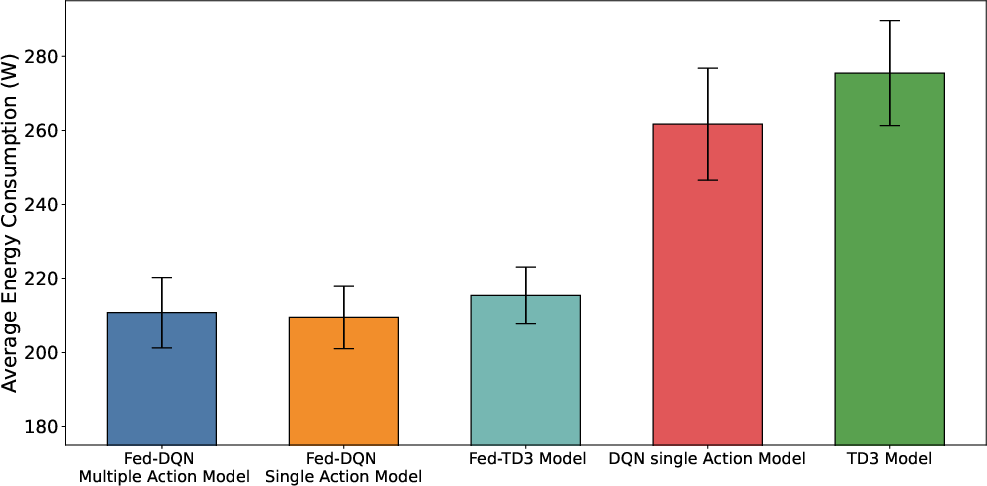
Figure 7: Side-by-side comparison of federated versus centralized approaches for energy and user satisfaction in composite environments.
Implications and Future Directions
This research demonstrates that integrating federated DRL into O-RAN's hierarchical control system yields energy savings exceeding 50% while ensuring user QoS. Strong numerical evidence shows that policy-gradient algorithms such as TD3, especially when federated, are ideally suited for the scalability constraints of practical dense deployments. The systematic reduction in training energy consumption and statistical convergence improvement validate federated DRL as a protocol-level enhancement for future RANs.
Practical deployment implications include: elimination of raw data pooling across O-RAN regions, intrinsic support for local policy variation, and rapid policy adaptation to dynamic network conditions. From a theoretical standpoint, the results advocate for hierarchical, multi-agent DRL systems with federated value/policy sharing in multi-layer telecom environments.
Anticipated research directions include: investigation of client heterogeneity impacts on global policy optimality, meta-learning extensions for faster regional adaptation, actor-critic methods with explicit environment variations, and theoretical analysis of convergence rates and generalization in federated RAN settings.
Conclusion
The proposed scalable federated deep reinforcement learning framework for O-RAN achieves significant energy efficiency gains and practical scalability. Policy-gradient methods under federated protocols align naturally with the O-RAN disaggregated control stack, providing a foundation for future intelligent, energy-adaptive RAN operation in ultra-dense mobile networks.