- The paper introduces WHOLE-MoMa, a two-stage pipeline that uses randomized whole-body controller rollouts and offline RL to enhance high-DoF mobile manipulation.
- It employs Q-chunking with diffusion-based policies to overcome sub-optimal controller limitations, achieving up to 98% simulation success on door tasks.
- The approach reduces reliance on human teleoperation and demonstrates robust sim-to-real transfer with up to 80% success in real-world tests.
Whole-Body Mobile Manipulation via Offline RL on Sub-optimal Controllers
Introduction and Motivation
Mobile manipulation (MoMa) in real-world environments demands coordinated motion generation across all robotic embodiments—base and arms—particularly for articulated object interaction tasks such as opening doors, drawers, and cupboards. Classical approaches based on hierarchical optimization, such as whole-body controllers (WBCs), provide powerful motion-generation priors but are brittle and require extensive manual tuning. Conversely, learning-based methods—especially those relying on teleoperation—demonstrate generalization but are costly in both data acquisition and engineering. The core hypothesis in "Whole-Body Mobile Manipulation using Offline Reinforcement Learning on Sub-optimal Controllers" (2604.12509) is that even a sub-optimal WBC can serve as an effective structural prior: it can focus exploration on meaningful regions of the state-action space, structuring data collection to enable sample-efficient offline RL improvements.
The proposed pipeline, WHOLE-MoMa, follows a two-stage design: (1) trajectory data generation via randomized WBC rollout, and (2) offline RL leveraging expressive action-chunked policies with Q-chunking and advantage-weighted policy extraction.
The WBC is formulated as a Hierarchical Quadratic Programming (HQP) problem to optimize for multi-objective tasks, imposing strict prioritization over constraints, task objectives, and regularization. However, as visualized in Figure 1, WBCs are inherently myopic: the configuration that is optimal for one stage (e.g., reaching a handle) may be suboptimal or even infeasible for subsequent articulated interaction due to lack of horizon reasoning.

Figure 1: A whole-body controller (WBC) provides a strong but sub-optimal motion-generation prior; it solves a multi-objective optimization problem per embodiment, but instantaneously, without planning through subsequent interaction.
Data is collected by parameter-randomizing the WBC, inducing coverage over task-relevant behaviors without requiring human teleoperation. This process is summarized in Figure 2, where each demonstration is scored with a reward signal combining task success, articulation progress, and spatial error reduction.
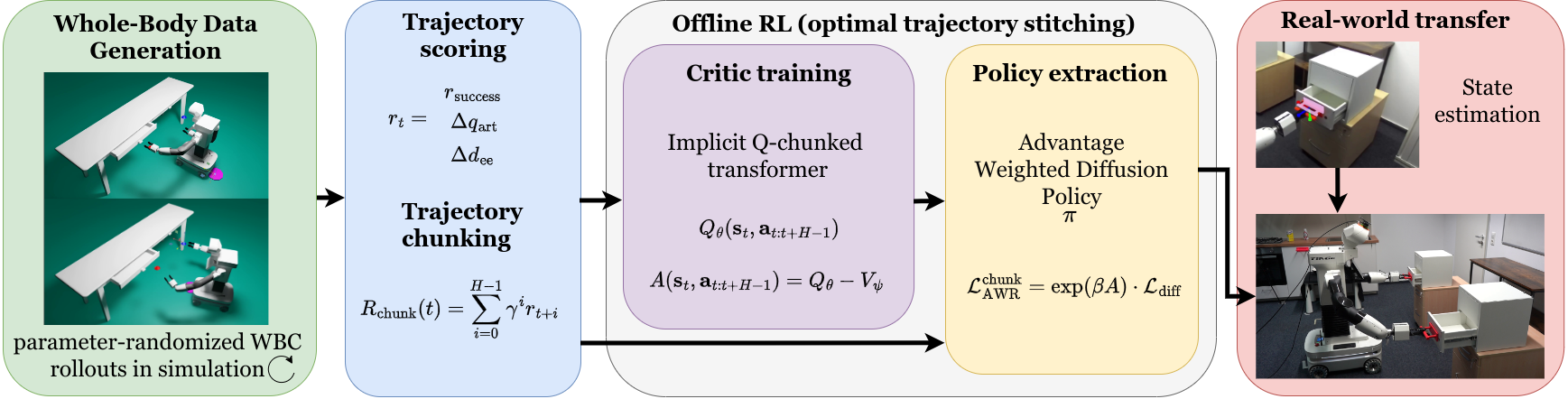
Figure 2: WHOLE-MoMa pipeline. Randomized WBC rollouts produce diverse demonstrations; offline RL with Q-chunking and chunked AWR trains expressive diffusion policies for whole-body coordination.
Offline RL is applied to the sub-optimal dataset using an extended Implicit Q-Learning (IQL) framework coupled with "Q-chunking." The latter relabels the data with temporally extended action sequences (chunks), trains a transformer-based Q-function for horizon-H action evaluation, and extracts policies using a chunk-level Advantage-Weighted Regression (AWR) objective. The chosen policies are expressive—diffusion-based architectures predictive over action chunks—enabling temporally consistent, multimodal control in high DoF mobile manipulation (over 21 DoFs per policy).
Experimental Setup
Evaluation is performed on three tasks of increasing difficulty in both simulation and real-world deployment:
- Door: Push open and traverse through a door.
- Drawer: Simultaneous closing and opening of disparate drawers (bimanual).
- Cupboard: Open a cupboard while simultaneously placing an object inside (most challenging, continuous coordination).
All tasks utilize the Tiago++ holonomic mobile manipulator. Simulation leverages Isaac Sim and GAPartNet articulated objects. Demonstrations are generated purely by randomizing WBC parameters; no human teleoperation data is used.
Figure 3 details the simulated and real environments, spanning the abovementioned tasks.


Figure 3: Simulated and real whole-body mobile manipulation environments across all three tasks—escalating in complexity from door to cupboard interactions.
Offline training involves 3k WBC-generated trajectories per task, state representation including full proprioceptive and object articulation state, and action as full joint-velocity control. All RL policies predict over action chunks (horizon 16, state history of 5), and Q-functions utilize transformer architectures, per recent advances in sequence-level RL.
Numerical Results
Key findings include:
- Success rates: WHOLE-MoMa surpasses all baselines, achieving 98% (door), 80% (drawer), and 78% (cupboard) simulation success rates. Imitation learning and unstructured RL baselines lag behind, especially in high-coordination scenarios (44% for RL on drawers, 0% on cupboards).
- Real-world zero-shot transfer: Policies trained purely in simulation and on WBC data generalize with 80% success (drawer) and 68% success (cupboard) on the real Tiago++ without any tuning or real-world data.
- Policy extraction: Advantage-weighted regression (AWR) yields the most stable improvements over the WBC prior, outpacing gradient-based (DDPG+BC) and sample selection (IDQL, RISE) offline RL heads.
- Ablative studies: Transformer diffusion policies and Q-chunking are critical for high performance—removal induces drops exceeding 20% on complex bimanual tasks.
Qualitative Behaviors and Robustness
A critical evaluation of policy behaviors (see Figure 4) shows concrete strengths and weaknesses. The WBC, while generally successful in reaching, may fail during simultaneous articulation due to local optima or myopic planning (e.g., failing to open one drawer while closing another). Pure behavior cloning with diffusion is susceptible to imprecision, occasionally applying excessive force and breaking manipulation handles. In contrast, WHOLE-MoMa consistently achieves simultaneous articulation, demonstrating compounded policy expressiveness and improved credit assignment.




Figure 4: Qualitative comparisons in the real-world drawer manipulation task: WBC gets stuck; BC/diffusion is imprecise and breaks the handle; WHOLE-MoMa succeeds in simultaneous close/open.
Critical analysis of failure modes (see Figure 5) highlights the importance of robust state estimation, especially for tasks requiring sustained kinematic coordination (e.g., pose estimation drift in the cupboard task can cause policy stalling during articulation or object placement).


Figure 5: On real cupboard articulation, accurate pose tracking yields success, but poor estimation can stall the policy during articulation/placement.
Practical and Theoretical Implications
This research demonstrates that an unoptimized classical controller, when used as a structured demonstration generator, can dramatically improve the efficiency and feasibility of whole-body offline RL in high-DoF articulated manipulation. The approach eliminates the expensive need for teleoperated whole-body data and reduces dependency on reward engineering and policy hand-tuning.
On the theoretical front, the introduction and adaptation of Q-chunking and action chunking to offline RL with expressive diffusion policies provides evidence for the utility of temporally extended policy/critic alignment, especially in high-dimension, temporally extended coordination tasks.
From a practical viewpoint—especially in sim-to-real transfer—the method exhibits robustness beyond the simulation domain, with high success rates achieved without any real-world on-policy data. However, deployment sensitivity to pose estimation highlights the need for further research into robust observation models, e.g., learning visual encoders with extensive domain randomization or sensor fusion techniques.
Limitations and Future Work
Current limitations are predominantly tied to:
- Articulation precision: Small pose errors can stall or destabilize execution. Approaches integrating compliance or impedance strategies could mitigate these.
- State estimation reliance: The current pipeline leans on explicit pose tracking for articulated objects; alleviating this via camera-based visual encoders and domain randomization is a future direction.
- Offline-only training: Incorporating online RL or on-policy refinement initialized from WHOLE-MoMa could close remaining gaps in sim-to-real transfer and articulate failure cases robustly.
Conclusion
WHOLE-MoMa leverages sub-optimal WBCs as structural priors for scalable, teleoperation-free data generation, in combination with advanced offline RL (Q-chunking with transformer-based, diffusion policies) to achieve robust, whole-body mobile manipulation. The approach outperforms standard baselines in both simulation and real-world deployment, highlighting a feasible pathway to scalable, expressive, model-free control in high-dimensional manipulation without high-cost human demonstration data.
(2604.12509)