LightMat-HP: A Photonic-Electronic System for Accelerating General Matrix Multiplication With Configurable Precision
Abstract: Matrix multiplication is a fundamental kernel in large-scale artificial intelligence and scientific computing, but its performance on conventional electronic accelerators is increasingly constrained by memory bandwidth and energy efficiency. Photonic computing offers a promising alternative due to its ultra-high bandwidth, massive parallelism, and low power dissipation. However, most existing photonic systems are limited to low-precision computation because of analog optical modulation constraints and noise accumulation, which restricts their applicability in precision-critical workloads. To address this limitation, we propose LightMat-HP, a hybrid photonic-electronic computing system that enables end-to-end acceleration of general matrix multiplication with configurable computational precision. LightMat-HP adopts block floating-point (BFP) arithmetic to reduce computational complexity while enabling flexible precision-performance tradeoffs. To overcome the precision limitations of photonic devices, we propose a slicing-based photonic multiplication scheme that exploits the high accuracy of low bit-width photonic multiplication in combination with digital accumulation to achieve high-precision mantissa multiplication. A tile-based matrix multiplication dataflow is further designed to support matrices of arbitrary sizes. We experimentally validate LightMat-HP on a photonic computing prototype and evaluate its performance through large-scale simulations. The results demonstrate that LightMat-HP outperforms FPGA, GPU, and a state-of-the-art photonic accelerator across throughput, latency, and energy efficiency, particularly for small- and medium-sized matrix multiplications, owing to its highly parallel photonic architecture, efficient data movement, and slice-based BFP arithmetic.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
LightMat-HP: A simple guide to speeding up math with light
1) What is this paper about?
This paper introduces LightMat-HP, a new kind of computer system that uses both light (photons) and electricity (electronics) to do one of the most common and important math operations in AI and science: matrix multiplication. The clever part is that it can adjust how precisely it calculates, so it can be both fast and accurate when needed.
Think of it as a super-fast calculator that uses flashes of light to multiply lots of numbers at once, while regular electronics handle the parts that need careful, exact steps.
2) What questions were the researchers trying to answer?
The paper focuses on three big questions:
- Can we use light to speed up matrix multiplication, which is the heavy-lifting behind AI models and scientific simulations?
- Since light-based (photonic) devices are very fast but not perfect at high precision, can we still get accurate results for serious, high-precision work?
- Can we build a practical system that mixes light and electronics to get the best of both speed and accuracy, and that works for matrices of any size?
3) How did they do it?
They built a hybrid system that splits the work between light and electronics in smart ways.
Key ideas, explained with simple analogies:
- Block Floating Point (BFP): Imagine a group of numbers that all share the same “zoom level” (exponent), but keep their own details (mantissas). Sharing the zoom level saves space and makes the math simpler and faster, while staying accurate enough for most jobs.
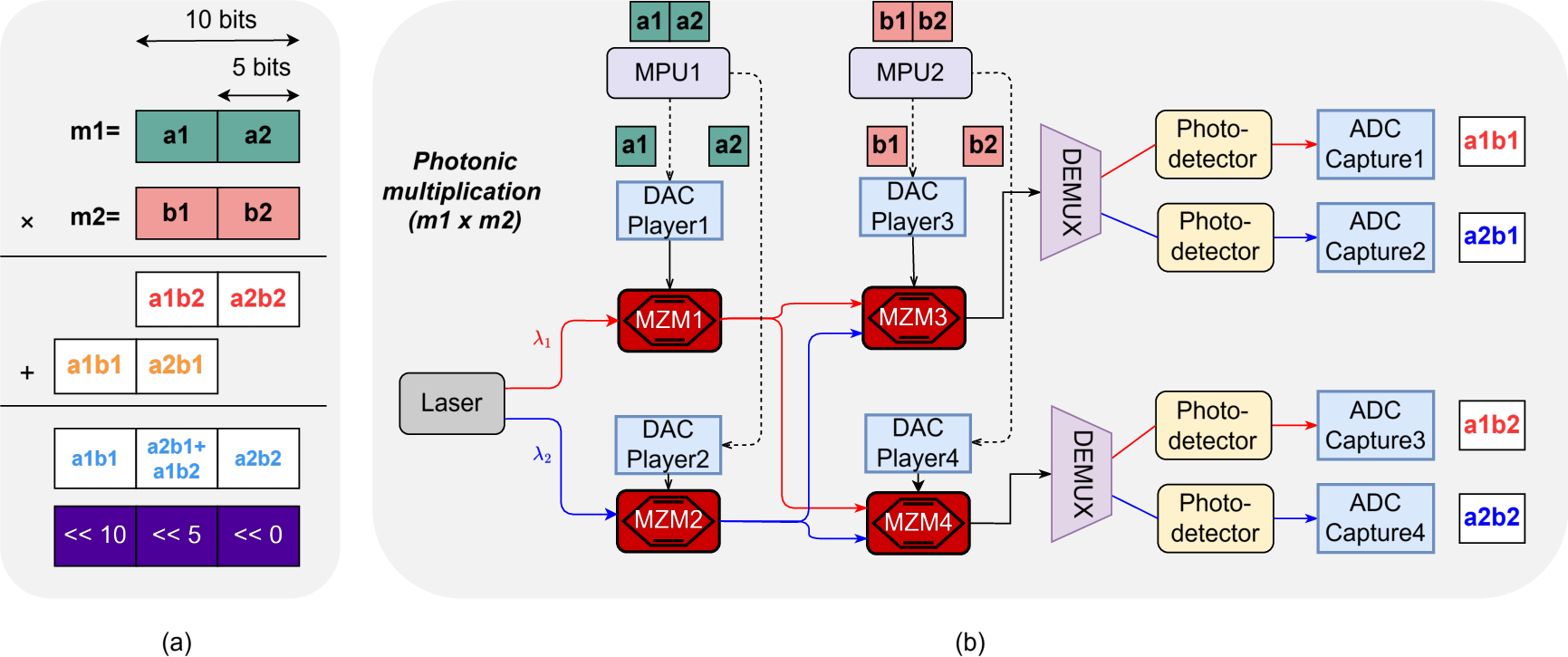
- Slicing numbers for multiplication: Big numbers are hard for light to multiply accurately. So the system chops each number into small chunks (like cutting a chocolate bar into small pieces). It multiplies the small pieces using light (which it does very well), then adds the pieces back together using digital electronics. This gives a precise final result without asking the light-based part to do something it’s bad at.
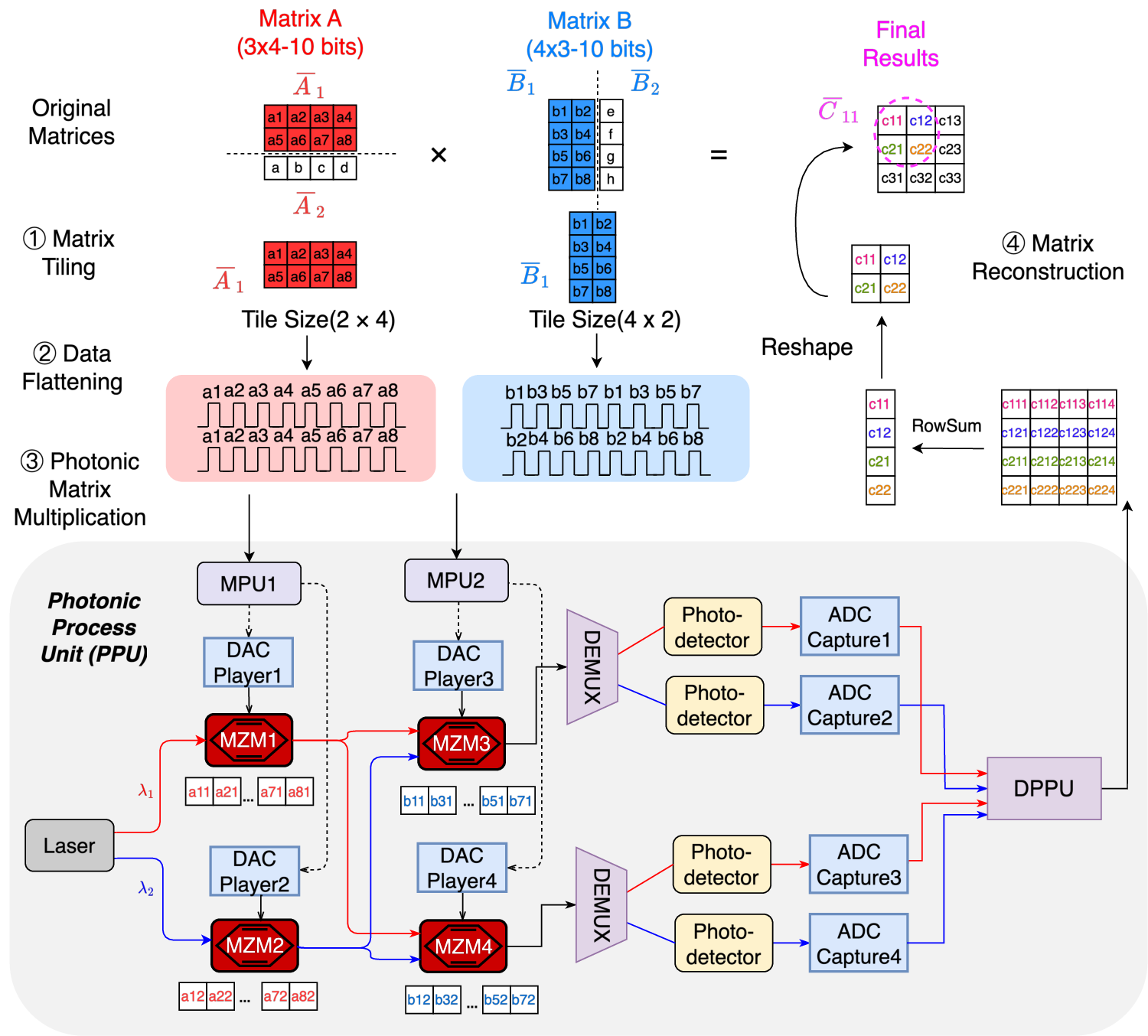
- Tiling matrices: Big matrices are cut into smaller tiles (like tiling a floor). The system multiplies these tiles piece by piece, which fits well with its hardware and keeps data moving efficiently.
- Photonic Processing Unit (PPU): This is the light-based “engine.” It uses devices called modulators to encode numbers onto light and multiply them. It also uses different colors (wavelengths) of light at the same time—like sending multiple messages through different colored laser beams—so it can do many multiplications in parallel. Electronics then read the light results and add them up carefully.
- Why mix light with electronics? Light is extremely fast and energy-efficient for multiplication. Electronics are better for memory, control, and precise addition. By combining them, the system stays fast and accurate.
In short: Light does lots of small, fast multiplications in parallel; electronics set up the problem, slice and combine numbers, and make sure the final answers are accurate.
4) What did they find, and why is it important?
Here are the main results:
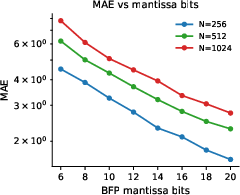
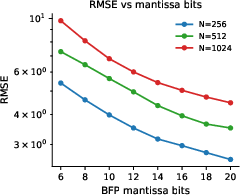
- Light is very accurate for small-number chunks: When multiplying low-bit-width numbers (about 3–5 bits), the photonic hardware is highly accurate. For larger, higher-precision numbers, errors grow if you try to do it all at once with light.
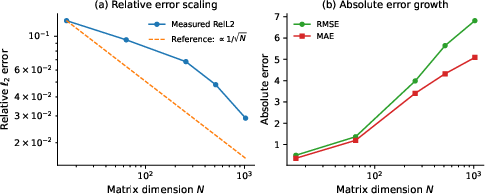
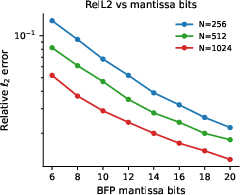
- Slicing works: By slicing bigger numbers into these small pieces, multiplying them with light, and then combining the pieces digitally, the system achieves high-precision results. In tests, dot products (the core of matrix multiplication) stayed within about 1% error or better, which is excellent for many AI and science tasks.
- Errors behave nicely: The small mistakes made by the light hardware look like random noise, and when you add many results together, these errors tend to cancel out. That makes the system reliable and predictable.
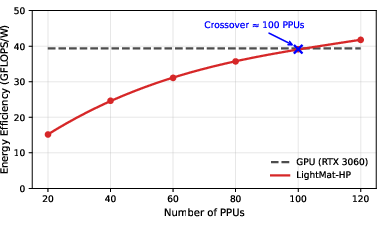
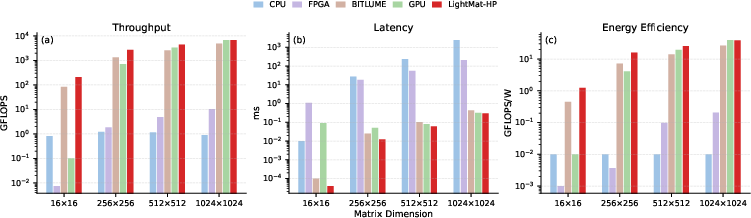
- It’s fast and energy-efficient: Compared to CPUs, GPUs, FPGAs, and even a strong photonic baseline, LightMat-HP delivered higher throughput (more answers per second), lower latency (answers arrive sooner), and better energy efficiency—especially for small and medium matrix sizes, which are common in many AI layers.
Why this matters: AI models are getting bigger and hungrier for compute power. Traditional electronics are hitting limits in speed, heat, and energy use. A system that uses light to do the heavy math can keep AI moving forward without burning tons of power.
5) What’s the impact?
LightMat-HP shows that:
- Photonics and electronics together can handle high-precision math, not just rough estimates.
- Precision can be tuned: you can trade a bit of speed for more accuracy when you need it, by slicing into more pieces—no new hardware required.
- This could cut energy use and speed up training and inference in AI, and accelerate scientific simulations, making large-scale computing more sustainable.
- It points toward future computers where light handles massive, parallel math at blazing speeds while electronics keep everything accurate and organized.
In short, LightMat-HP is a promising step toward faster, greener computing for the AI and science of tomorrow.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list synthesizes what remains missing, uncertain, or unexplored in the paper and can guide concrete follow‑up research:
- Limited end-to-end hardware validation: the paper reports prototype experiments for scalar multiplication and dot products but does not show a full GEMM executed entirely on the hardware prototype (including complete data movement, tiling, slicing, digitization, accumulation, and BFP conversions) with measured latency, throughput, and energy.
- Reproducibility of performance claims: the abstract claims superiority over CPU/GPU/FPGA and a photonic baseline, but the methodology, datasets, matrix sizes, batch regimes, and detailed metrics for those comparisons are not provided in the text; a rigorous, transparent benchmarking suite is needed.
- ADC/DAC constraints under high-speed operation: the system relies on 14‑bit DACs and 12‑bit ADCs, but the effective number of bits (ENOB) at 4 GS/s is not measured; the impact of ENOB, sampling jitter, and front-end bandwidth/linearity on overall accuracy and SNR is not quantified.
- Sign and zero handling in intensity modulation: the approach uses intensity-modulated MZMs (nonnegative outputs), but the encoding and processing of signed mantissas (including negative values) and zeros are not described; concrete schemes (e.g., differential encoding, offset-biasing, or sign-bit side channels) and their overhead/accuracy need to be specified and validated.
- Generality of error assumptions: error distributions are assumed approximately Gaussian and zero-mean, but validation is limited; the presence of systematic biases from MZM nonlinearity, residual bias errors, drift, and wavelength-dependent effects—and their persistence across devices and time—needs characterization.
- Robustness to input distributions: experiments use uniform/Gaussian positive inputs; evaluation on realistic signed and heavy-tailed distributions typical of DNNs (e.g., activations/weights) and HPC workloads is missing.
- Application-level impact: there is no assessment of how BFP+slice-based photonic GEMM affects end-to-end task accuracy (e.g., DNN training/inference accuracy, scientific solver residuals) across representative models and datasets.
- Numerical stability of accumulation: digital accumulation is used to mitigate analog noise, but the summation algorithm (e.g., naïve, pairwise, Kahan) is not specified; the effect of accumulation order on rounding error and drift for large K is unquantified.
- Overflow/underflow and rounding policies in BFP: handling of edge cases (e.g., saturation, denormals, subnormals), rounding modes, and deterministic reproducibility for BFP quantization/rescaling are not detailed.
- BFP block sizing strategy: the paper proposes shared exponents per row/column blocks but does not analyze how block size choices impact accuracy, overflow risk, and bandwidth; an auto-tuning policy for block sizes versus error/throughput is needed.
- Precision scaling limits: while low-bit (3–6) photonic multiplication is accurate, the latency/throughput/energy implications when scaling mantissa precision to FP32/FP64-equivalent mantissas (e.g., 23/52 bits requiring many slices) are not explored.
- Run-time reconfigurability overheads: the control-plane and data-path costs to change slice width, block sizes, and tile dimensions at run time are not quantified (reconfiguration latency, SRAM reloads, scheduling stalls).
- Tile sizing and SRAM constraints: tile size is bounded by DAC-player SRAM (32 KB), but the impact of this constraint on external memory traffic, reuse, and overall throughput for large matrices is not analyzed.
- Data movement bottlenecks: the energy and latency associated with streaming tiles from external memory to DAC SRAMs and returning ADC results to DRAM are not measured; roofline analyses that include I/O are absent.
- Digital post-processing scalability: the capacity and energy of DPPUs for slice accumulation, shifting, and matrix reconstruction at line rates (and for multiple PPUs) are not quantified; potential digital-side bottlenecks remain unclear.
- Photonic addition trade-offs: the paper opts for digital accumulation but does not quantify when partial in-photonic accumulation (e.g., limited-depth optical summation) would reduce ADC bandwidth/energy or how noise-growth would trade off against ADC savings.
- WDM scaling and crosstalk: only two wavelengths are shown; the challenges of scaling to many wavelengths (crosstalk, filter roll-off, group delay, equalization, thermal drift) and their impact on accuracy and SNR are not addressed.
- Optical power and splitting losses: parallelism increases optical splitting losses and required laser power; there is no power budget or SNR analysis for scaling the number of PPUs and wavelengths.
- Laser source requirements: transitioning from a single tunable laser to multi-line sources (e.g., combs) introduces new stability and power distribution issues; these requirements and their energy/area costs are not discussed.
- Calibration and drift management: maintaining linear operation with many MZMs demands continuous bias control and possible predistortion; the calibration procedure, frequency, overhead, and impact on uptime and energy are not quantified.
- Predistortion and linearization: the paper assumes operation in linear regions but does not investigate digital/analog predistortion methods to push effective precision or mitigate nonlinearity-induced bias.
- Thermal and environmental sensitivity: the effects of temperature variations on MZM transfer, WDM filters, and photodetectors, and the required thermal control (and its power cost) are not analyzed.
- Synchronization and timing alignment: alignment of multiple high-speed DAC/ADC channels and compensations for skew/jitter are unspecified; their effect on slice multiplication accuracy is unmeasured.
- Dynamic range management: strategies to prevent ADC saturation/clipping while maximizing SNR (gain control, scaling of mantissas, laser power control) are not described.
- Error correlation across slices and time: the assumption that errors cancel during accumulation ignores potential temporal or slice-wise correlations; measurements of error autocorrelation and its impact on dot-product scaling are missing.
- Negative and signed mantissa experiments: prototype experiments appear to use positive-only operands; empirical validation with signed mantissas (including sign-encoding overhead and error) is lacking.
- Complex-valued GEMM: many optical/HPC applications require complex arithmetic; extension of the slicing and accumulation scheme to complex multiplications (and the cost in slices/PPUs) is not treated.
- Integration and packaging: the prototype is benchtop with discrete components; pathways and challenges to an integrated photonic-electronic package (coupling losses, area, heat removal, RF/optical co-design) are not explored.
- Host and software stack: interfaces to BLAS libraries, kernel scheduling, and compiler/runtime support for BFP tiling and precision configuration are not specified; software integration remains an open task.
- Reliability and variability: device-to-device variability, aging, and their impact on calibration and accuracy over lifetime are not characterized; in-field self-test and recalibration strategies are absent.
- Fault detection and recovery: mechanisms to detect channel failures (e.g., a failed MZM/wavelength) and re-route work or adjust precision on the fly are not discussed.
- Security and isolation: potential cross-talk between wavelengths/PPUs as an information leakage path or a QoS isolation challenge in multi-tenant settings is not considered.
- Energy per MAC breakdown: the energy contributions of lasers, modulators, drivers, ADC/DACs, and digital post-processing are not decomposed; measured energy/MAC under different precisions and tile sizes is needed.
- Scaling to convolutions/attention: although GEMM underlies many layers, the mapping of convolution/attention operators (with reuse and sparsity) to the tile+BFP+slicing flow and the achievable data-reuse benefits are not evaluated.
- Auto-tuning of precision and tiling: there is no mechanism to jointly choose slice width, BFP block size, and tile size to meet user-specified accuracy/latency/energy targets across varying workloads and matrices.
Practical Applications
Immediate Applications
The following use cases can be piloted with current-generation hybrid photonic–electronic prototypes and near-term engineering effort, especially for small- and medium-sized matrix multiplications where LightMat-HP shows the strongest advantage.
- Photonic GEMM coprocessor for latency-critical AI inference
- Sectors: Software/AI, Cloud & Edge Computing, Robotics
- What it enables: Offloading attention, fully-connected, and small-block convolution GEMMs to a photonic coprocessor with configurable precision for low-latency, energy-efficient inference. Particularly effective for batch=1 and small/medium matrix sizes common in transformers (per-head attention), MLP blocks, and on-device inference.
- Tools/products/workflows: PCIe/CXL accelerator card with a LightMat-HP PPU array; a BLAS provider (e.g., “photonBLAS”) with FP↔BFP conversion kernels; PyTorch/TensorFlow backends that select mantissa slice-width per layer; runtime scheduler to tile, slice, and offload GEMMs; calibration utilities for bias/linearization.
- Assumptions/dependencies: Stable optoelectronic stack (MZMs, lasers, WDM, ADC/DAC); driver/SDK integration; sufficient host-memory bandwidth (no optical memory); model accuracy tolerance to BFP and <1% RE at dot-product level; thermal/bias control and periodic re-calibration.
- Batched small/medium GEMM accelerator in HPC libraries
- Sectors: Scientific Computing, Computational Chemistry, Signal Processing
- What it enables: Speedups for batched BLAS routines (e.g., strided batched GEMM) prevalent in quantum chemistry kernels, preconditioners, and iterative solvers that repeatedly multiply many small matrices.
- Tools/products/workflows: MKL/OpenBLAS plugin targeting LightMat-HP; batch-aware tiler to pack many small matrices; autotuner to pick tile size and slice-width; job scheduler that routes eligible kernels.
- Assumptions/dependencies: Kernel shapes align with the photonic sweet spot (small/medium matrices); accuracy budgets compatible with BFP mantissa slicing; host↔accelerator data transfer amortized via batching.
- Massive MIMO baseband and beamforming acceleration
- Sectors: Telecommunications (5G/6G RAN), Defense Comms
- What it enables: Real-time precoding, detection, and beamforming (dense but moderate-size matrices) with low latency and high energy efficiency; photonics’ WDM parallelism aids throughput.
- Tools/products/workflows: Baseband accelerator module colocated with RU/DU; blocks for matrix inversion approximations via iterative GEMMs; integration with SDR toolchains.
- Assumptions/dependencies: Tight integration with RF/FPGA stacks; deterministic latency; environmental stabilization; accuracy/linearity sufficient for EVM/BER targets.
- Energy-efficient inference appliances for recommender systems and personalization
- Sectors: Internet Services, Retail, Advertising Technology
- What it enables: Low-power inference of MLP-heavy recommenders and rerankers with small to medium dense layers; run-time tradeoffs between accuracy and energy via mantissa slice-width control.
- Tools/products/workflows: On-prem inference boxes; model-serving frameworks (e.g., Triton) with photonic GEMM backend; SLO-aware precision scheduler (latency/accuracy knobs).
- Assumptions/dependencies: Model retraining or calibration to tolerate BFP; workload characterization to ensure high offload coverage.
- Real-time radar/sonar/ultrasound beamforming and matched filtering
- Sectors: Aerospace/Defense, Industrial Sensing, Healthcare (ultrasound)
- What it enables: Low-latency matrix ops in front-end signal chains (beamforming, adaptive filtering) where matrices are modest-sized but time-critical.
- Tools/products/workflows: Ruggedized photonic compute modules; DSP pipelines offloading GEMMs; precision profiles per mode (search/track).
- Assumptions/dependencies: Environmental hardening; compliance/certification (especially in medical); algorithm robustness to BFP precision.
- Robotics and autonomous systems prototyping
- Sectors: Robotics, Automotive
- What it enables: Onboard, energy-efficient acceleration of perception/planning networks with small/medium layers; configurable precision to meet latency and power budgets.
- Tools/products/workflows: ROS2 nodes with photonic BLAS backend; layer-wise precision autotuning; power/thermal-aware scheduling on heterogeneous SoCs.
- Assumptions/dependencies: Size/weight/power constraints of current photonic modules; need for robust calibration in mobile conditions; software integration effort.
- Academic testbed for analog-aware algorithms and co-design
- Sectors: Academia, Research Labs
- What it enables: Empirical exploration of BFP arithmetic under photonic noise; layer-wise precision scheduling; error-compensation methods; analog-aware training/inference.
- Tools/products/workflows: Open-source drivers, error models, and simulators; curriculum kits for optoelectronic computing; reproducible benchmarks (GEMM microbenchmarks, ML models).
- Assumptions/dependencies: Access to a stable prototype; measurement infrastructure for SINAD/ENOB tracking; community benchmarks.
- Compiler/runtime support for precision and tiling
- Sectors: Software Tools, EDA/Compilers
- What it enables: Automatic selection of mantissa bit-width, slice count, and tile sizes per kernel to meet accuracy/SLO constraints; hybrid digital-analog scheduling.
- Tools/products/workflows: MLIR/TVM backends; cost models combining throughput, energy, and error; verification harnesses for end-to-end numerical error.
- Assumptions/dependencies: Accurate, portable error models; operator coverage beyond GEMM as needed by frameworks.
- Early “green compute” procurement pilots and benchmarks
- Sectors: Policy, Public Sector IT, Sustainability
- What it enables: Pilot programs that evaluate photonic GEMM accelerators on standardized small/medium GEMM suites (and ML inference) with energy/latency/accuracy reporting.
- Tools/products/workflows: Benchmark suites and reporting formats; guidance for energy labeling (e.g., joules/GEMM at given RE).
- Assumptions/dependencies: Access to devices; consensus metrics; independent validation.
Long-Term Applications
These use cases will benefit from further R&D in integration, scaling (multi-PPU arrays), higher effective precision, optical I/O/memory co-design, and robust software ecosystems.
- Full-scale AI training acceleration (transformers and beyond)
- Sectors: AI/ML, Cloud Computing
- What it could enable: End-to-end training with mixed-precision BFP (e.g., FP16/BF16-equivalent mantissas via slicing) and dynamic layer-wise precision; substantial energy and time-to-train reductions.
- Tools/products/workflows: Photonic “tensor cores” integrated into training nodes; PyTorch/XLA backends with precision schedulers; optimizer-aware precision control; distributed photonic GEMM in data/model/sequence parallelism.
- Assumptions/dependencies: Higher-precision accumulation and stability for backprop; larger, tightly-coupled PPU arrays; improved ENOB and drift control; high-bandwidth memory fabrics to feed GEMMs.
- High-precision HPC (FP32/FP64) linear algebra at scale
- Sectors: Climate/Weather, CFD, Computational Physics, Genomics
- What it could enable: Acceleration of double-precision GEMMs and solvers through deeper slicing and digital accumulation, reducing exascale energy budgets.
- Tools/products/workflows: Photonic-enabled BLAS/LAPACK/MAGMA; distributed linear algebra frameworks; autotuners for precision vs. iteration count.
- Assumptions/dependencies: Further improvements in analog linearity, noise mitigation, and calibration to make deep slicing practical; algorithmic compensation for residual errors.
- On-package photonic tensor cores for CPUs/GPUs
- Sectors: Semiconductors, Data Center
- What it could enable: Co-packaged silicon photonics with CMOS logic for ultralow-latency GEMM units; shared thermal/clock/power domains; reduced data-movement energy.
- Tools/products/workflows: Chiplet-based PPUs on interposers; CXL/CPI-connected accelerators; unified programming models across digital and photonic cores.
- Assumptions/dependencies: Mature heterogeneous packaging; integrated lasers or efficient laser coupling; thermal design and bias control at scale.
- In-network compute and photonic offload NICs
- Sectors: Cloud Networking, HPC
- What it could enable: Offloading GEMM-heavy primitives near the network (e.g., collective ops re-expressed via small GEMMs, embedding lookups with small MLPs) to reduce end-to-end latency and core load.
- Tools/products/workflows: SmartNICs with photonic GEMM blocks; collective libraries aware of offload; photonic switching fabrics with compute islands.
- Assumptions/dependencies: Co-design of network stack and compute; deterministic latency; photonic integration in NIC form factors.
- Sustainable data centers with photonic compute tiers
- Sectors: Energy, Cloud, Policy
- What it could enable: Fleet-wide energy reductions by routing eligible GEMMs to photonic tiers; carbon-aware schedulers that select precision/throughput modes.
- Tools/products/workflows: Energy-aware job placement; telemetry for joules/GEMM and RE; procurement standards and incentives for hybrid photonic–electronic nodes.
- Assumptions/dependencies: Operational maturity, supply chain scaling, standardized metrics, and integration into DC orchestration.
- Medical imaging and real-time reconstruction
- Sectors: Healthcare
- What it could enable: Accelerated CT/MRI iterative reconstruction and ultrasound imaging pipelines; improved throughput or lower dose via faster solvers/GEMMs.
- Tools/products/workflows: Vendor toolchains with photonic BLAS backends; certified medical devices with hybrid compute.
- Assumptions/dependencies: Regulatory certification; deterministic accuracy; higher-precision support for clinically critical workloads.
- Automotive domain controllers for ADAS/AV
- Sectors: Automotive
- What it could enable: Energy-efficient inference/training-on-wheels for perception and sensor fusion where moderate matrix sizes dominate; hard real-time guarantees.
- Tools/products/workflows: Automotive-grade photonic compute modules; ISO 26262-compliant toolchains; safety monitors for bias/thermal drift.
- Assumptions/dependencies: SWaP constraints, ruggedization, lifecycle stability, and safety certification.
- Edge AR/VR and wearable AI
- Sectors: Consumer Electronics
- What it could enable: On-device acceleration of small/medium GEMMs in SLAM, hand/eye tracking, and generative tasks at tight power envelopes.
- Tools/products/workflows: Photonic SoCs; mobile SDKs with per-layer precision profiles; battery-aware precision scaling.
- Assumptions/dependencies: Miniaturization of lasers, modulators, and ADC/DAC; cost reduction and thermal solutions.
- Standardization and regulation for analog AI accelerators
- Sectors: Policy, Standards Bodies
- What it could enable: Industry-wide benchmarks for energy/latency/accuracy trade-offs under analog noise; labeling and procurement guidance; safety/robustness test suites.
- Tools/products/workflows: Open benchmarks for small/medium GEMMs and ML inference; conformance tests for error bounds and drift management.
- Assumptions/dependencies: Multi-stakeholder consensus; accessible reference hardware; independent labs.
- Photonic–electronic co-design toolchains
- Sectors: EDA, Academia, Semiconductor IP
- What it could enable: End-to-end compilers that map FP workloads to BFP with slice-based photonic execution; numerical verification under noise; lifecycle calibration planning.
- Tools/products/workflows: IR extensions for precision annotations; cost/error models; co-simulation of optics-electronics-numerics.
- Assumptions/dependencies: Accurate device-level models; validated system-level error propagation models; collaboration across disciplines.
Glossary
- Analog-to-Digital Converter (ADC): An electronic device that digitizes analog signals for processing in the electronic domain. "all ADCs provide 12-bit quantization resolution"
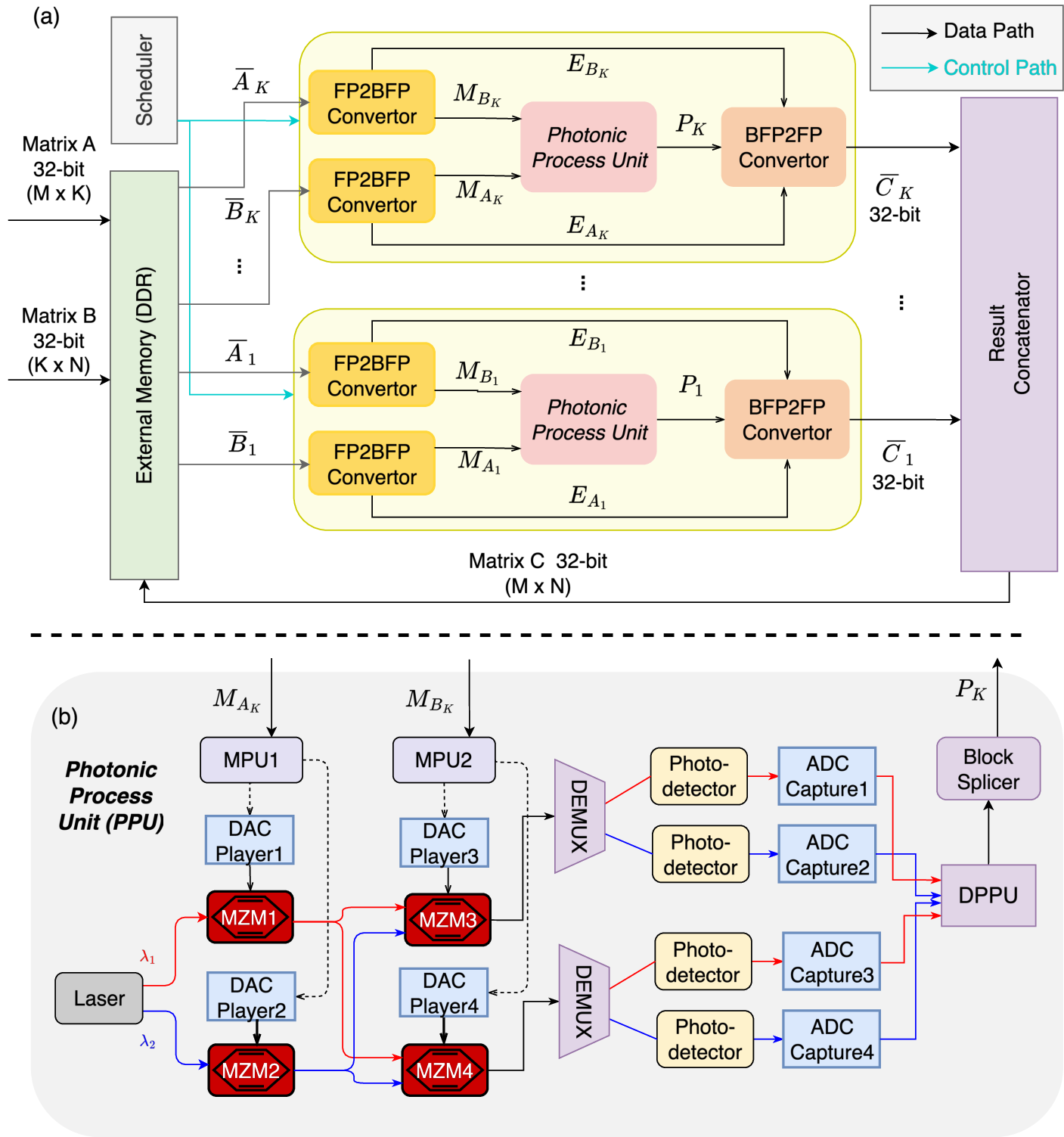
- BFP2FP (precision conversion module): A module that converts Block Floating-Point representations back to standard floating-point format after photonic computation. "two precision conversion modules (FP2BFP and BFP2FP) for the conversion between FP and BFP"
- Bias drift: Slow changes in a device’s operating point (e.g., modulator bias) that degrade linearity and accuracy over time. "including modulator nonlinearity and bias drift"
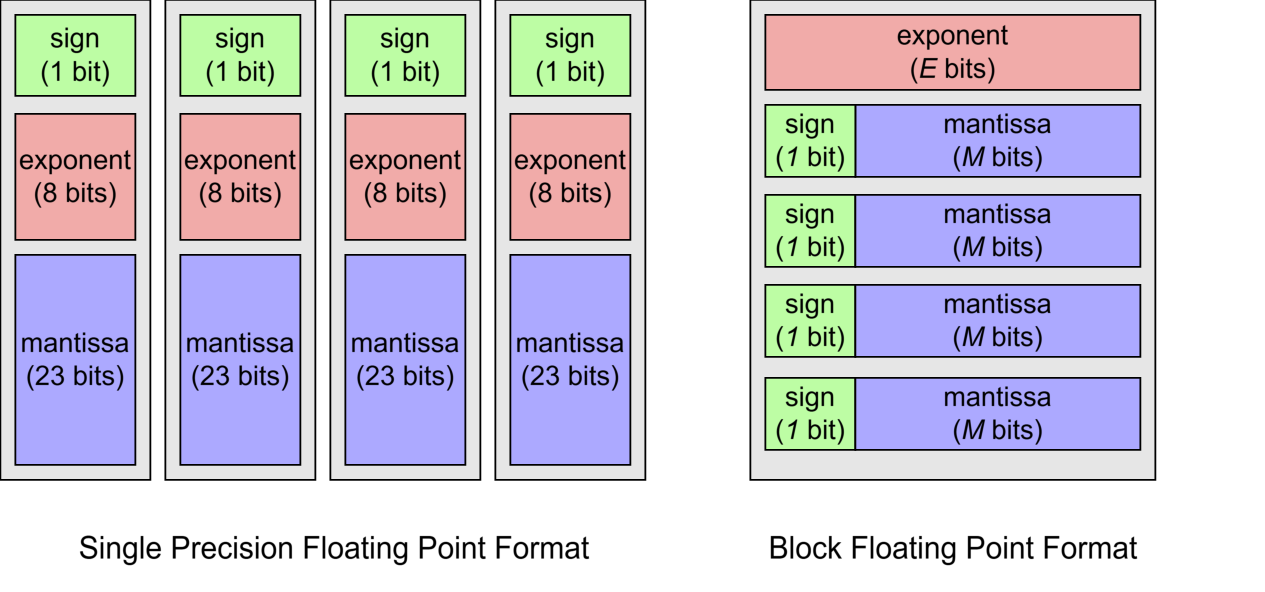
- Block Floating-Point (BFP) format: A numeric representation where a block of values shares a single exponent while maintaining individual mantissas to balance dynamic range and hardware cost. "The Block-Floating-Point format~\cite{oppenheim2003realization} is a numerical representation that bridges the gap between traditional floating-point (FP) and fixed-point formats."
- Block splicer: A digital component that assembles slice-level and tile-level partial results into complete outputs. "Finally, the block splicer assembles the multiplication results belonging to the same matrix title and streams them back to the electronic subsystem."
- Continuous-wave laser (tunable): A laser source emitting a continuous optical wave whose wavelength can be adjusted for modulation and multiplexing. "A tunable continuous-wave laser~\cite{laserdiodesourceTunableDiode} is used to generate a carrier waveform at ."
- Demultiplexing (by wavelength): The process of separating multiplexed optical signals into individual wavelength channels. "The resulting optical signals are then demultiplexed by wavelength"
- Dennard scaling: A historical scaling rule stating that power density stays constant as transistors get smaller, whose ending contributes to modern power constraints. "the slowdown of Moore's Law and the end of Dennard scaling have increasingly limited further miniaturization of transistors"
- Digital Post-Processing Unit (DPPU): A digital module that aligns, shifts, and accumulates slice-level photonic products to reconstruct final results. "forwarded to the Digital Post-Processing Units (DPPUs), which accumulate and align the products of slice multiplications"
- Digital-to-Analog Converter (DAC): An electronic device that converts digital data into analog signals to drive optical modulators. "All DACs on the ZCU111 feature 14-bit quantization resolution"
- Effective Number of Bits (ENOB): A measure of a system’s usable resolution considering noise and distortion, limiting achievable precision. "the effective number of bits (ENOB), determined by the measured SINAD, imposes an upper bound on the precision of the photonic multiplication system."
- Electro-optic effect: The change in a material’s refractive index in response to an electric field, used to modulate light in photonic devices. "changes their relative phase via the electro-optic effect."
- FP2BFP (precision conversion module): A module that converts standard floating-point values into Block Floating-Point blocks for photonic processing. "two precision conversion modules (FP2BFP and BFP2FP) for the conversion between FP and BFP"
- GEMM (General Matrix–Matrix Multiplication): A core linear algebra operation multiplying two matrices, central to AI and scientific computing workloads. "This makes BFP more robust than pure integer quantization for general GEMM workloads."
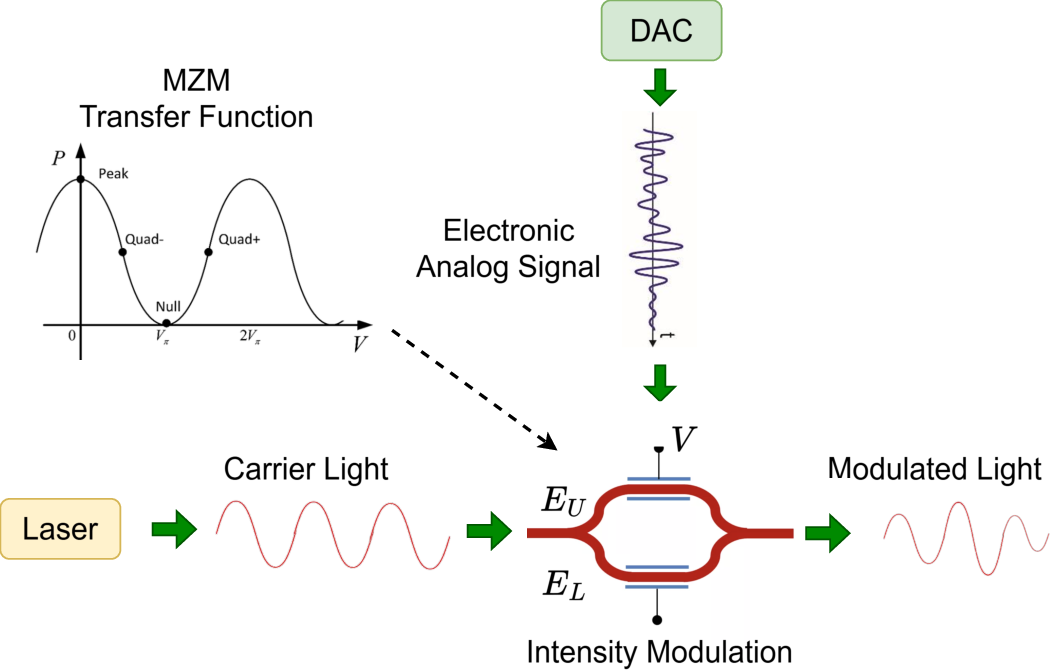
- Half-wave voltage (Vπ): The voltage required on a modulator to induce a phase shift of π between interferometer arms, setting the modulation scale. "and is the half-wave voltage required to induce a phase shift between the two arms."
- HP-GEMM (High-Precision General Matrix Multiplication): GEMM performed at high numerical precision, challenging for analog photonic systems. "such as high-precision general matrix multiplication (HP-GEMM)."
- Intensity transfer function: The nonlinear function relating a modulator’s input voltage to its output optical intensity. "According to the MZM intensity transfer function, different input voltages (representing different digital data) induce different phase shifts"
- Mach–Zehnder Modulator (MZM): An interferometric optical modulator that encodes electrical signals onto light via controlled phase shifts. "MachâZehnder Modulator (MZM)~\cite{saleh2019fundamentals} is a core photonic device for encoding digital signals onto optical carriers."
- Memory wall: A performance bottleneck caused by the disparity between processor speed and memory bandwidth/latency. "the inherent memory wall problem of the von Neumann architecture further constrains the performance of electronic computing systems."
- Mixed-signal electronic interfaces: Circuits handling both analog and digital signals, contributing non-idealities like distortion in hybrid systems. "and distortion from mixed-signal electronic interfaces, dominate the error behavior."
- Optical interconnects: Communication links using light rather than electricity, offering low-loss, high-bandwidth data movement. "Compared with electrical interconnects, optical interconnects generate almost no resistance or capacitance losses during data transmission"
- Optical splitting: Dividing an optical signal into multiple paths to enable fan-out and parallel operations. "Optical signal reuse is achieved through optical splitting and interconnection to enable parallel analog multiplication"
- Photodetector: A device that converts optical signals back into electrical signals for digitization. "The modulated light is converted to an electrical signal using a Thorlabs RXM15EF photodetector~\cite{thorlabs_rxm15ef}, which has a bandwidth of 15 GHz."
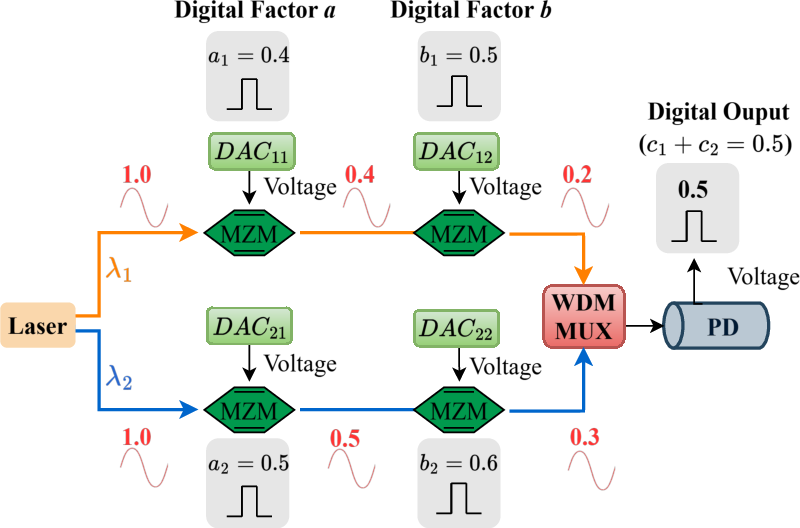
- Photonic addition: Summing optical powers at different wavelengths, typically via a WDM multiplexer, to implement additions. "Photonic addition is achieved by combining optical signals at different wavelengths through a WDM multiplexer"
- Photonic computing: Performing computation using light, exploiting high bandwidth and parallelism in the optical domain. "Photonic computing has emerged as a promising alternative."
- Photonic Processing Unit (PPU): A modular photonic core that performs parallel analog multiplications on mantissa slices. "The PPU employs four MZMs to perform four parallel photonic multiplications per cycle"
- Polarization controller: A device used to set and maintain the polarization state of light for stable modulator operation. "A Thorlabs polarization controller is placed between the two modulators to maintain the correct polarization state."
- Radio Frequency (RF) signal: High-frequency electrical signal used to drive modulators for encoding data onto optical carriers. "the digital data is converted to a Radio Frequency (RF) analog signal, which drives the phase shifters"
- Shot noise: Fundamental optical noise due to the discrete nature of photons, affecting analog photonic precision. "including electro-optic modulator nonlinearity, laser relative intensity noise, shot noise, and distortion from mixed-signal electronic interfaces"
- Signal-to-noise-and-distortion ratio (SINAD): A metric combining noise and distortion that determines the effective precision of analog systems. "computational accuracy is fundamentally limited by the system signal-to-noise-and-distortion ratio (SINAD)"
- Slicing-based photonic multiplication: Decomposing high-bit-width operands into low-bit slices for accurate photonic multiplication with digital recomposition. "a slicing-based, precision-configurable photonic multiplication scheme that exploits the high accuracy of low bit-width photonic computation"
- Tile-based matrix multiplication dataflow: A strategy that partitions matrices into tiles to manage data movement and parallelism efficiently. "A tile-based matrix multiplication dataflow is further designed to support matrices of arbitrary sizes."
- von Neumann architecture: A computing architecture with shared memory for data and instructions, leading to bandwidth bottlenecks in modern systems. "the inherent memory wall problem of the von Neumann architecture"
- Wavelength-Division Multiplexing (WDM): A technique that carries multiple data channels on different wavelengths simultaneously for parallelism. "optical channels naturally support multi-wavelength parallelism via wavelength-division multiplexing (WDM)"
- WDM multiplexer (MUX): A device that combines multiple wavelength channels into a single optical path for power-summing or transmission. "When their outputs are merged by the WDM MUX, their optical powers simply accumulate"
Collections
Sign up for free to add this paper to one or more collections.