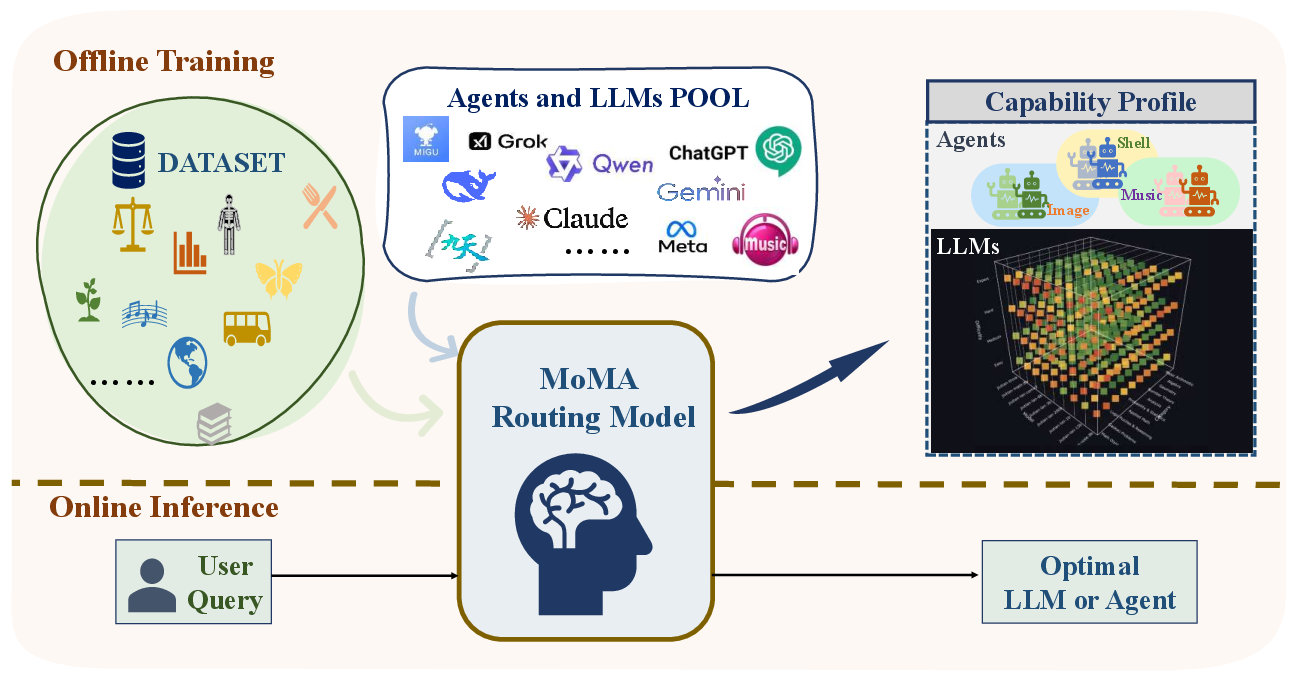
- The paper presents MoMA, a unified routing framework that dynamically directs queries to specialized agents or optimal LLMs based on a cost-performance trade-off.
- It employs a two-stage system using data augmentation, a MoE head, and Pareto optimization for fine-grained, query-specific model selection.
- Empirical evaluations show MoMA reduces costs by up to 37% while maintaining performance, effectively scaling across diverse domains and models.
Generalized Routing for Model and Agent Orchestration: The MoMA Framework
This essay provides a technical analysis of "Towards Generalized Routing: Model and Agent Orchestration for Adaptive and Efficient Inference" (2509.07571), which introduces MoMA, a unified routing framework for orchestrating both LLMs and AI agents. The framework is designed to optimize inference efficiency and cost-effectiveness in heterogeneous, real-world AI service environments.
The proliferation of LLMs and domain-specific agents has led to a highly heterogeneous AI ecosystem, where user queries span a wide range of domains and task complexities. Existing routing solutions are typically limited to either LLM selection or agent invocation, and often fail to scale across diverse model pools or adapt to the evolving landscape of available execution units. The core challenge addressed is the development of a generalized, adaptive router that can:
MoMA Framework Overview
MoMA (Mixture of Models and Agents) is a two-stage routing system that integrates both LLM and agent routing. The framework is depicted in Figure 2.
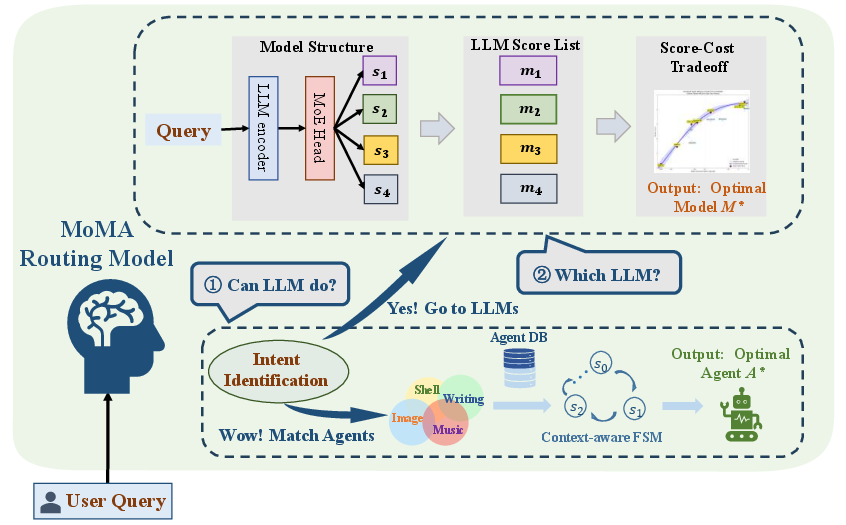
Figure 2: The MoMA routing model framework.
Upon receiving a user query, MoMA first attempts to route the query to a specialized agent if the task is well-defined and matches agent capabilities. If no suitable agent is found, the query is routed to the most appropriate LLM, selected from a heterogeneous pool based on a cost-performance trade-off. This hierarchical approach leverages the determinism and efficiency of agents while retaining the flexibility and generality of LLMs.
LLM Routing: Data, Architecture, and Optimization
Training Data Construction and Augmentation
A large-scale, hierarchically organized dataset (Dtrain, ~2.25M instances) is constructed to profile LLM capabilities across domains (science, writing, technology, programming) and task complexities. The dataset is augmented using a BERT-based selection mechanism and LLM-as-a-judge pairwise comparisons, producing fine-grained performance labels for model pairs.
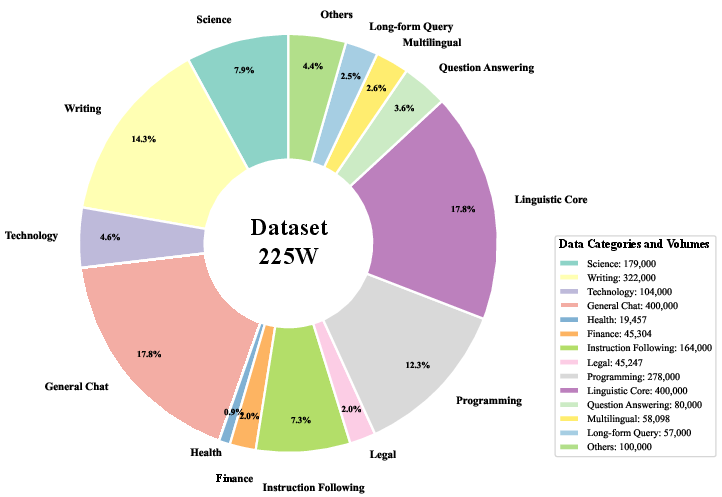
Figure 3: Training data distribution by category.
Router Architecture
The LLM router employs a pre-trained, instruction-tuned LLM (Qwen-3) as an encoder, extracting hidden states as feature representations. These are passed to a Mixture-of-Experts (MoE) head, which dynamically selects the top-k experts (corresponding to candidate LLMs) for each query. The output is an M-dimensional vector of predicted performance scores, one per LLM.
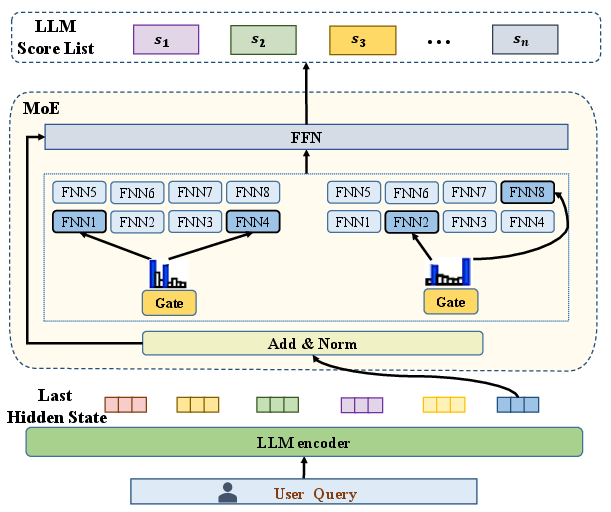
Figure 4: LLM routing network structure.
The router is trained using a categorical cross-entropy loss over five pairwise comparison outcomes, with additional modeling of "strong" and "weak" wins/losses via a logit-based margin. The optimization objective is to minimize the discrepancy between predicted and true pairwise outcomes, supporting fine-grained, query-specific model selection.
Score-Cost Trade-off and Pareto Optimization
For each query, the router constructs a Pareto frontier over candidate LLMs, balancing normalized performance scores and inference costs. The TOPSIS algorithm is used to select the LLM closest to the ideal point (maximal performance, minimal cost), with user-adjustable weights for cost vs. performance. This enables dynamic adaptation to user preferences and system constraints.
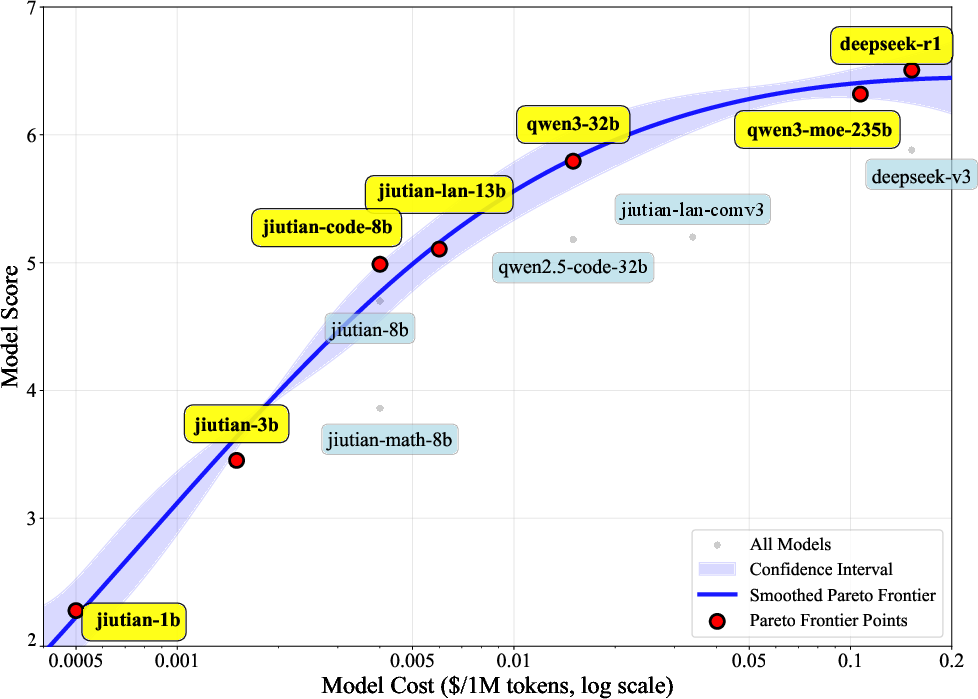
Figure 5: The Pareto frontiers curve for score-cost.
Agent Routing: Hierarchical and Context-Aware Selection
Agent routing is implemented as a two-layer hierarchical retrieval system:
- First Layer: Coarse-grained classification of the query into agent categories using semantic embeddings and k-means clustering over agent descriptions.
- Second Layer: Fine-grained selection within candidate categories using a context-aware finite state machine (FSM), integrating rule-based and embedding-based semantic disambiguation.
A token logits masking strategy is employed during LLM-based agent selection to prevent invocation of unavailable agents, ensuring robust and safe routing. The system supports efficient scaling via KV-cache-based prefetching and automated category assignment for new agents.
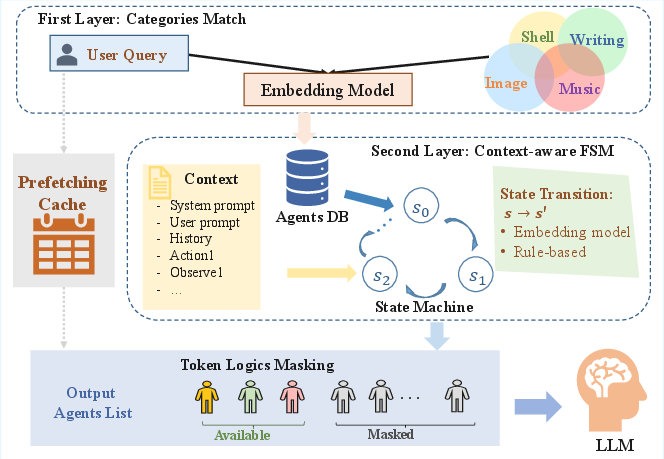
Figure 6: The Agent Routing framework.
Empirical Evaluation
Model Capability Profiling
Experiments on the Jiutian LLM series demonstrate that model performance varies significantly across mathematical subfields and difficulty levels, validating the need for fine-grained, query-specific routing.
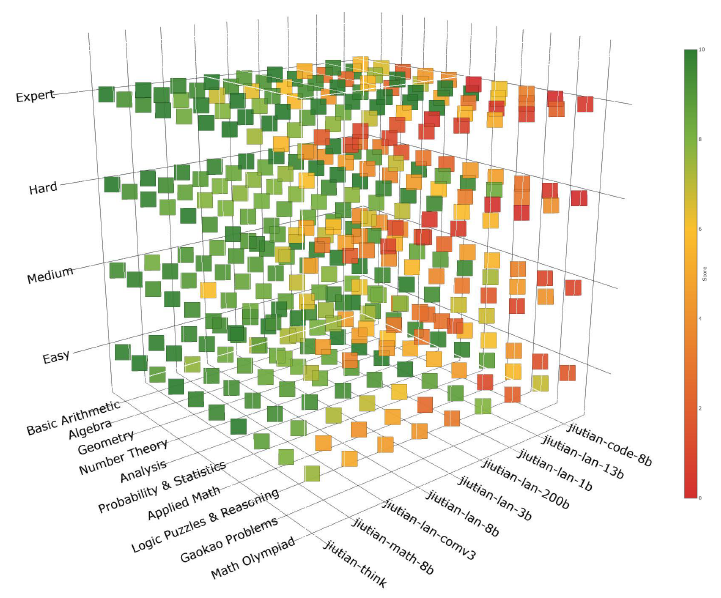
Figure 7: Exploring the performance of Jiutian serial LLMs in the mathematics domain.
MoMA is evaluated on AIME2024 (mathematics), LiveCodeBench (code generation), and SimpleQA (general knowledge) using a diverse set of LLMs (1B–235B parameters, including open-source and proprietary models). Key findings include:
- Performance-First Routing: MoMA matches or exceeds the best single LLM (qwen3-235b-a22b) while reducing cost by 31.46%.
- Auto-Routing: Achieves near-optimal performance at significantly lower cost (37.19% reduction compared to performance-priority).
- Cost-Priority Routing: Selects lightweight models for maximal efficiency with acceptable performance degradation.
MoMA outperforms SFT-based and contrastive learning-based routers in cost-performance trade-off, scalability, and adaptability.
Model Usage Distribution
Analysis of model usage under different routing preferences reveals that MoMA dynamically leverages specialized lightweight models (e.g., jiutian-math-8b, jiutian-code-8b) for domain-specific tasks, while defaulting to larger models only when necessary. This highlights the underutilized value of smaller, specialized models in practical deployments.
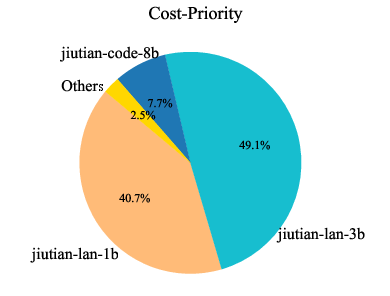
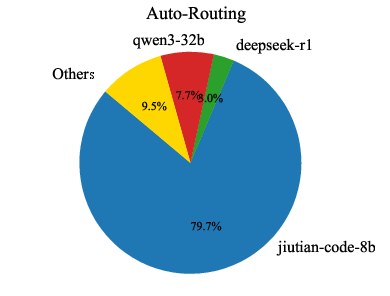
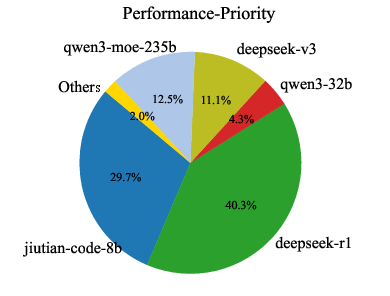
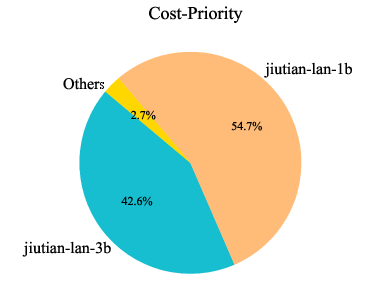
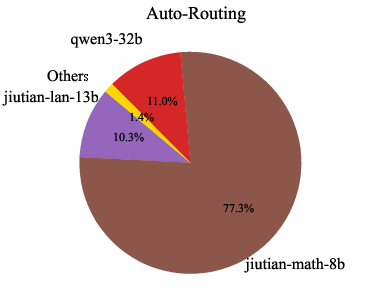
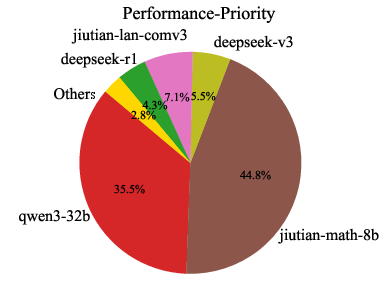
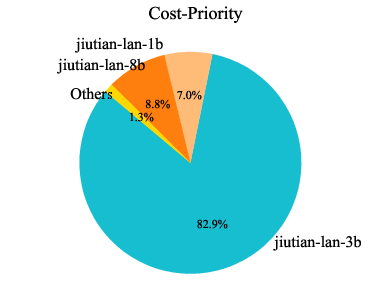
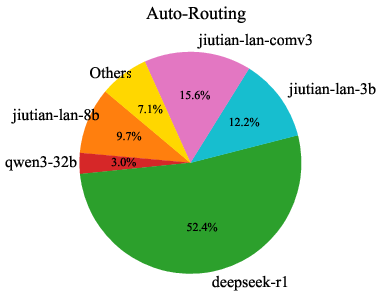
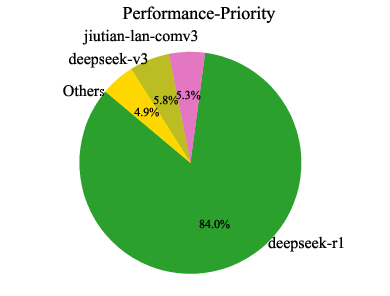
Figure 8: Model usage percentage across code, mathematical, and general knowledge domains. Each domain corresponds to three preferences: cost-priority, auto-routing, and performance-first (from left to right).
System Deployment and Practical Considerations
MoMA has been deployed with a dozen high-quality LLMs and over 20 expert agents, covering domains such as programming, mathematics, translation, and healthcare. The system supports real-time, dynamic orchestration, efficient scaling, and automated agent onboarding. The hierarchical routing and caching strategies ensure low latency and high throughput in production environments.
Implications and Future Directions
The MoMA framework demonstrates that unified, adaptive routing across heterogeneous LLMs and agents is both feasible and beneficial for real-world AI services. The approach enables:
- Fine-grained, query-specific orchestration for optimal cost-performance trade-off.
- Scalable integration of new models and agents without retraining the entire system.
- Dynamic adaptation to user preferences and evolving system constraints.
Future research directions include:
- Extending the routing framework to support multi-modal and multi-turn interactions.
- Incorporating reinforcement learning for continual adaptation of routing policies.
- Exploring federated or decentralized routing architectures for privacy-preserving inference.
Conclusion
MoMA represents a significant advance in the orchestration of heterogeneous AI execution units, providing a practical, scalable, and adaptive solution for efficient inference in complex, real-world environments. By unifying LLM and agent routing with a principled, data-driven approach, MoMA achieves state-of-the-art cost-performance trade-offs and lays the groundwork for future developments in generalized AI service routing.