- The paper introduces PipeLive, a novel method for live in-place pipeline parallelism reconfiguration in dynamic LLM serving environments.
- It details a coordinated protocol featuring dynamic KV cache resizing, layer stacking, and incremental patching to minimize service interruption (<100ms).
- Empirical evaluations demonstrate up to 36% performance gains and significant improvements in TTFT and TPOT on heterogeneous GPU setups.
Efficient Live In-place Pipeline Parallelism Reconfiguration for Dynamic LLM Serving: An Analytical Summary of PipeLive
Motivation and Problem Statement
Modern LLM inference frameworks typically employ pipeline parallelism (PP) to partition model layers across multiple GPUs. However, contemporary systems adopt static PP configurations, which introduce a critical rigidity under real-world dynamic serving conditions—such as workload bursts, shifting prompt/generation ratios, and heterogeneous GPU deployments. Existing solutions require a service to stop and restart to update PP mappings, which is practically prohibitive due to downtime and lost state. The key technical bottleneck is live, in-place reconfiguration: dynamic redistribution of model layers and associated KV caches across saturated GPUs, preserving in-flight requests and minimizing inference disruption.
The paper presents PipeLive, a system targeting this gap by providing live, in-place PP reconfiguration, even in environments with dynamic workloads and heterogeneous hardware. The design addresses non-trivial system challenges: (a) memory pressure prohibits naïve coexistence of both old and new layer/KV layouts, (b) existing KV cache designs are statically allocated and non-resizable, and (c) KV cache consistency must be maintained during online reconfiguration.
Workload-dependent optimal PP configurations and total throughput variations under typical hardware exemplars (A100 vs. L40S) are empirically established (Figure 1).
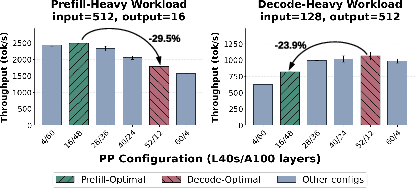
Figure 1: Total token throughput under different PP configurations on a two-GPU setup (A100 + L40S) with two different workloads, optimal PP configuration shift as workload characteristics change.
PipeLive System Design
System Architecture and Protocol
PipeLive consists of a hierarchical architecture comprising a Reconfiguration Coordinator and per-GPU Reconfiguration Workers. The Coordinator assesses reconfiguration feasibility under current memory and cache states, orchestrates the reconfiguration plan—comprising KV cache resizing, layer weight migration, and KV state transfer—and determines a safe atomic switch point with minimal interruption (Figure 2).
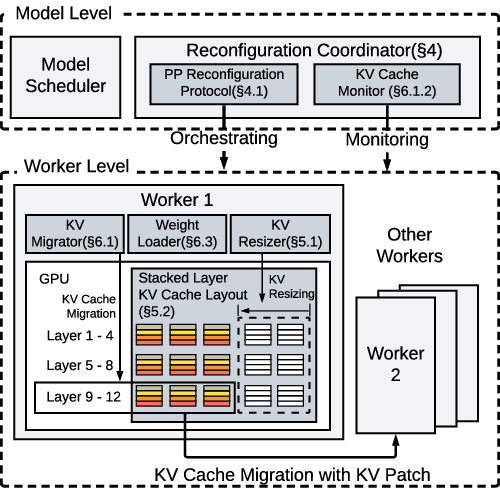
Figure 2: Architecture of PipeLive.
The in-place reconfiguration workflow (Figure 3) unfolds in five tightly orchestrated phases: (1) feasibility analysis and construction of a transient configuration where each GPU may host both source and target layers; (2) global KV cache shrinking to free memory; (3) asynchronous, prioritized weight loading and KV migration; (4) convergence tracking with coordinated incremental KV patching (covered later); and (5) atomic switch and resource reclamation. The design minimizes service interruption and optimizes resource utilization.
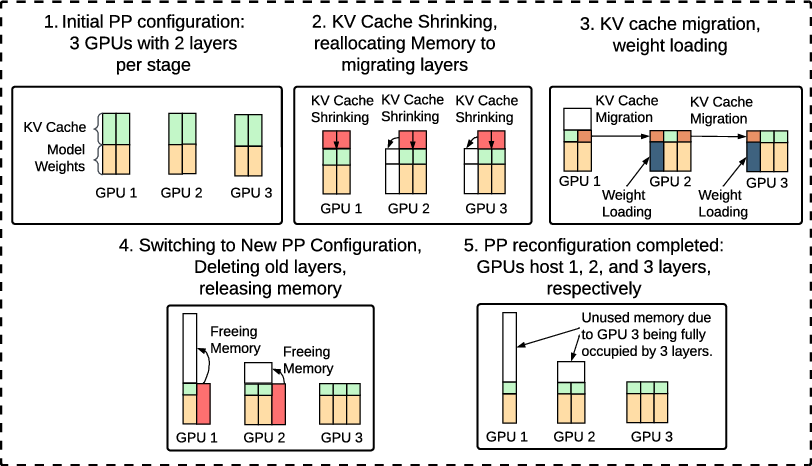
Figure 3: Live in-place PP reconfiguration workflow in PipeLive.
A protocol-level timeline (Figure 4) exposes the asynchronous and parallelizable nature of weight loading and KV cache migration vis-à-vis barriers for critical state transitions.
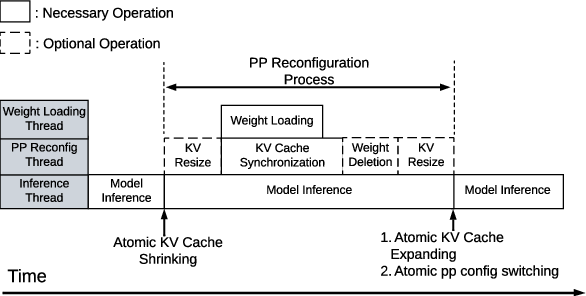
Figure 4: Timeline of asynchronous PP reconfiguration protocol.
Dynamic KV Cache Management
PipeLive introduces block-level, non-contiguous KV cache management by extending the PagedAttention kernel. This enables dynamic in-place resizing and supports allocation granularity decoupled from layer count. Each logical KV block may physically reside in any GPU location, and allocations/frees only update block tables, yielding negligible atomic update latency (Figure 5).
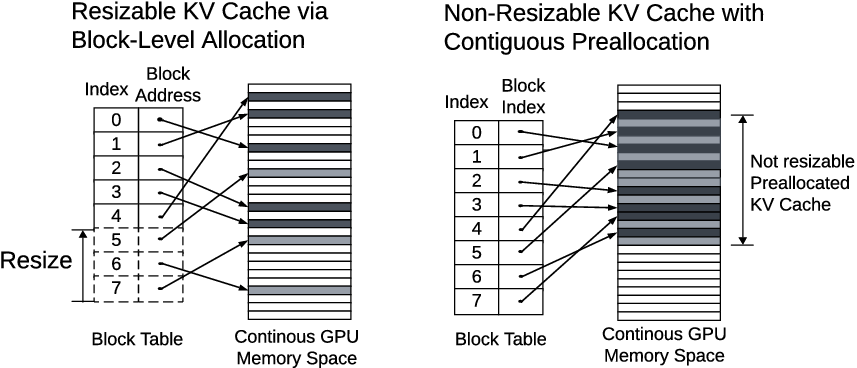
Figure 5: PipeLive extends PagedAttention to access non-contiguous GPU memory, enabling dynamic KV cache resizing during live migration.
To further combat internal GPU memory fragmentation—introduced by the large allocation units enforced by CUDA VMM compared to typical small KV block sizes—layer stacking is implemented: multiple layers’ KV blocks are packed into single allocation units, effectively amortizing fragmentation and tuning reconfiguration granularity (Figure 6).
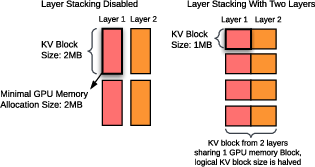
Figure 6: Layer stacking KV cache layout in PipeLive. Stacking two layers into one GPU memory block halved the logical KV block size.
Layer stacking introduces a trade-off between memory efficiency and reconfiguration flexibility, which is quantitatively justified in the evaluation.
Safe and Efficient State Synchronization
A critical technical innovation is concurrent KV migration with fine-grained patching. PipeLive leverages NCCL for GPU-GPU transfers, but observes that running concurrent inference and migration communicators can induce deadlocks (Figure 7). A two-phase handshake protocol with asymmetric entry semantics and worker-local mutexes avoids this condition, preserving inference priority and overlapping as much migration as possible.
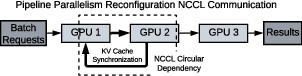
Figure 7: NCCL Communications in PP Reconfiguration. A circular dependency exists between GPU 1 and GPU 2, causing a deadlock.
For KV state migration, workers employ a dirty-flagged bitmap and patching mechanism, conceptually analogous to live VM migration: only incremental delta KV updates since the last sync are transferred. The coordination algorithm adaptively tracks lag between scheduled and applied tokens and defines a convergence threshold for safe cutover. This mechanism keeps reconfiguration-induced service interruption tightly bounded (<<100ms under load), with all other state migration amortized in the background.
Weight migration is similarly backgrounded via prioritized asynchronous streams.
Empirical Evaluation
Workload-Dependent Optimality and Reconfiguration Savings
The heterogeneity of GPU characteristics (A100 vs. L40S) yields distinct, sharply variable optimal PP splits depending on prefill (input)-heavy vs. decode (generation)-heavy load patterns. The optimal configuration, as well as the penalty for misalignment, shifts by over 20–30% in throughput across workloads.
PipeLive's reconfiguration protocol is evaluated on heterogeneous two-GPU topologies with Qwen3-30B and LLaMA 3-70B. Benchmarks alternate between prefill-heavy and decode-heavy phases with 200 requests to mimic real-world burst and mode shifts.
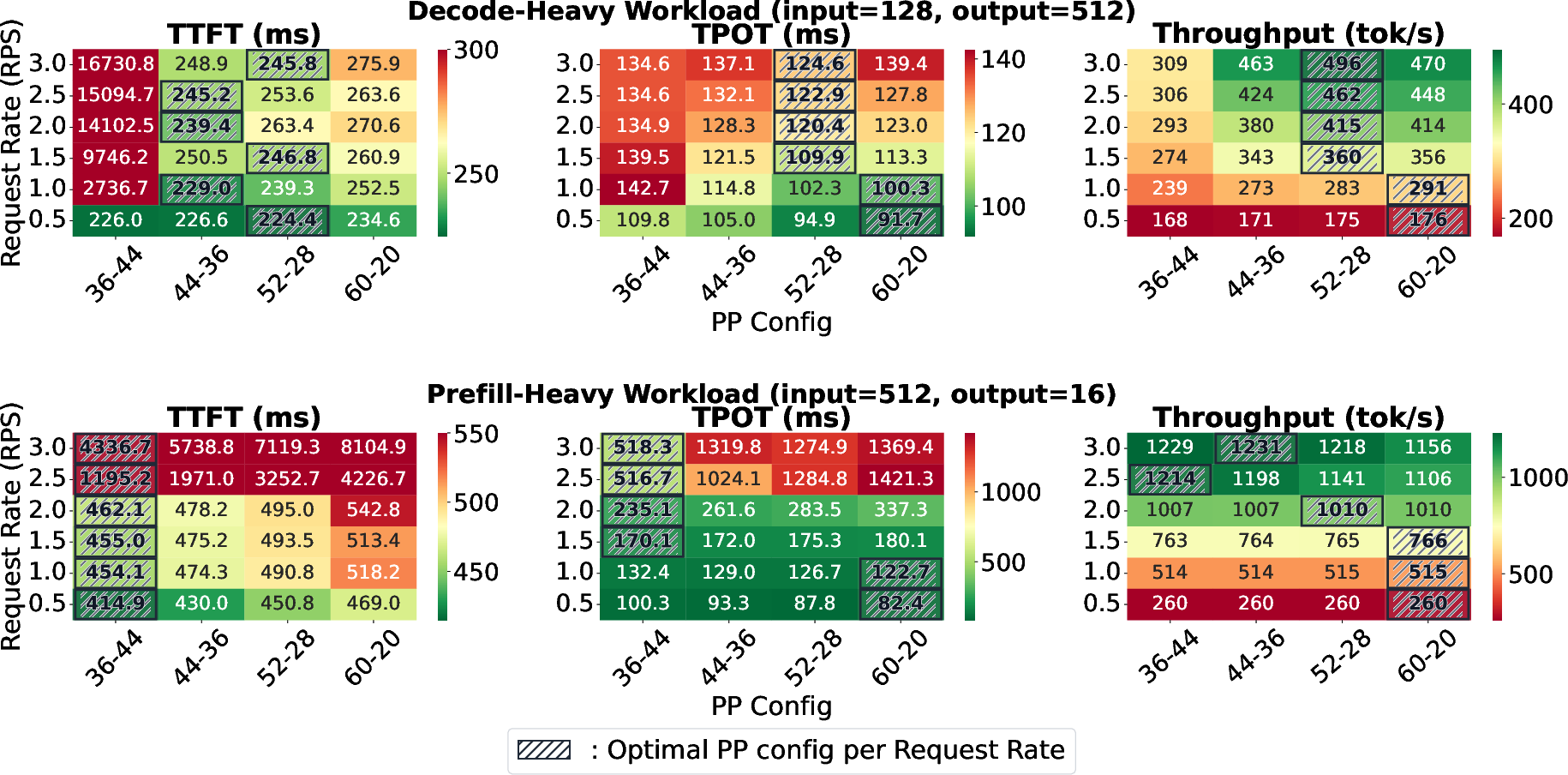
Figure 8: Performance of different PP configurations for heterogeneous GPUs under varying workloads.
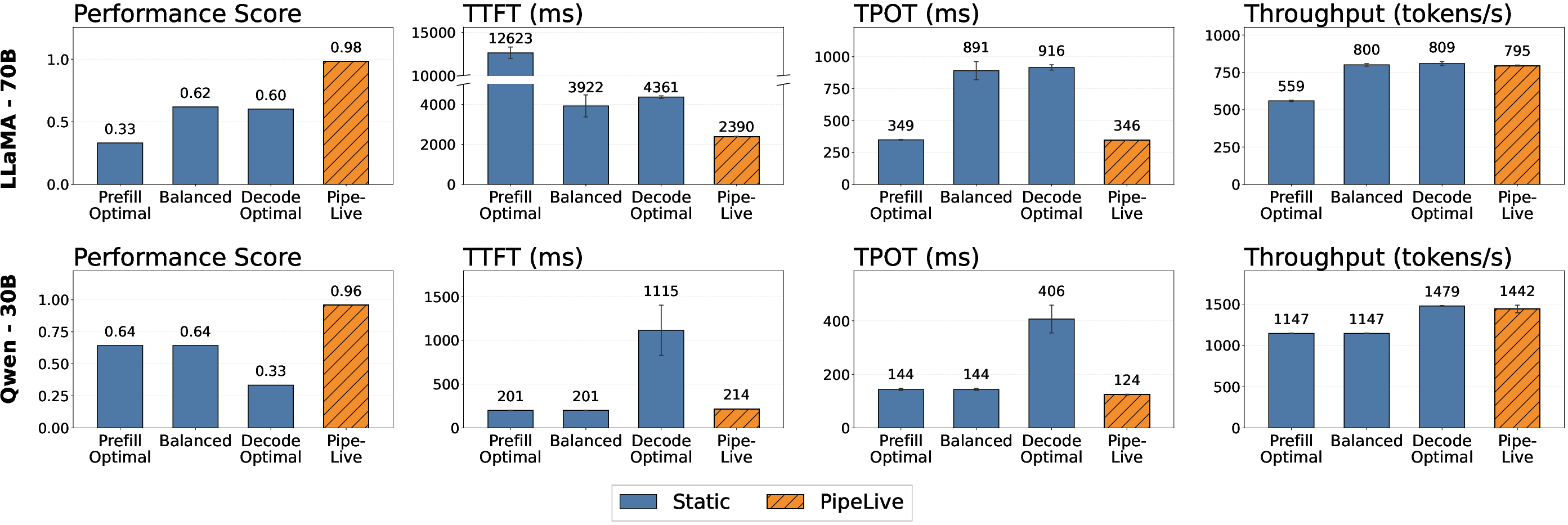
Figure 9: Performance of different PP configurations for heterogeneous GPUs under the mixed decode-heavy and prefill-heavy workloads.
PipeLive achieves a 33–36% composite performance gain over static PP baselines, outperforming both prefill- and decode-optimized static deployments on all composite metrics. On larger models, PipeLive’s dynamic KV resizing and configuration switching prevent catastrophic TTFT degradation due to cache overload and enables up to 45% improvement in TTFT and 61% in TPOT over balanced static deployments. On smaller models, it balances latency and throughput, outperforming all baselines by exploiting workload-aware optimal splits.
Importance of KV Resizing
The contribution of dynamic KV resizing is isolated and quantified (Figure 10). Disabling resizing results in severe KV cache overload, with resulting TTFT spikes under only modest load. Enabling resizing eliminates overload and increases sustainable request rate by up to 2.5x.
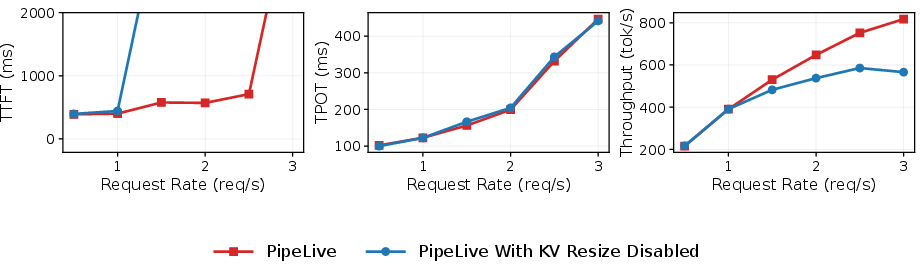
Figure 10: End-to-end performance of PP reconfiguration with kv resizing disabled and enabled under mixed workload.
Layer Stacking Trade-offs
Layer stacking substantially reduces fragmentation, nearly doubling effective KV cache utilization as compared to no stacking (Figure 11). While higher stacking factors flatten fragmentation, overly coarse stacking reduces partitioning granularity, harming adaptability and fine-grained load balancing (Figure 12). The default configuration of stacking four layers achieves optimal trade-offs, reducing TTFT by up to 51%.
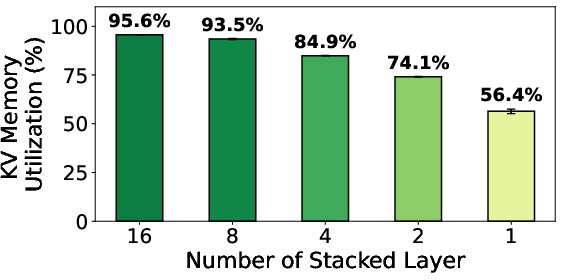
Figure 11: Effective KV utilization with different numbers of stacked layers.
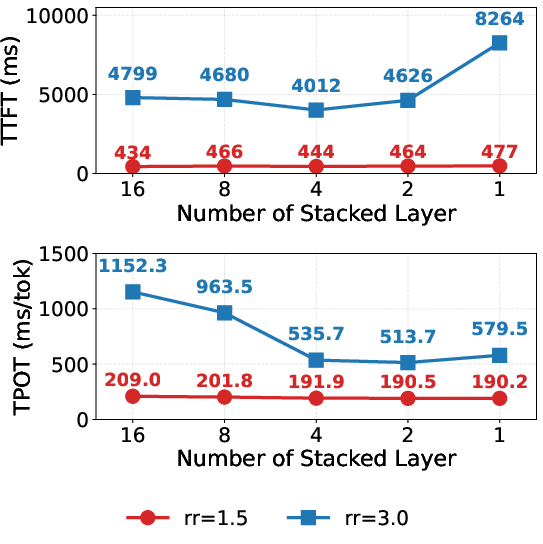
Figure 12: End-to-end performance of PP reconfiguration with different numbers of stacked layers. When it equals 1, layer stacking is disabled.
KV Patch Mechanism's Latency and Migration Benefits
The patch-based incremental migration keeps service stop time minimal (≈10 ms), compared to seconds for baselines without patching (Figure 13), essentially backgrounding migration overhead. Quantitative gains in TTFT reach 49.7% (patch enabled) and 72.4% (with both async weight loading and patching), with TPOT improvements up to 29.5% and 26.7% respectively (Figure 14).
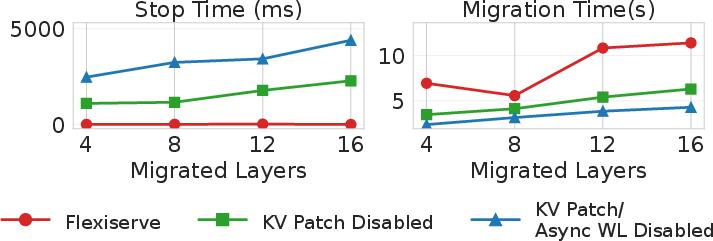
Figure 13: Comparison of stop time and migration time under different migrated layers with different migration modes.
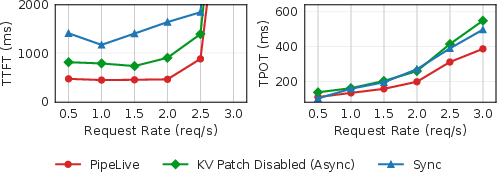
Figure 14: End-to-end tests of performance of PP reconfiguration with different migration modes.
Implications and Prospects
PipeLive’s unified protocol for live, in-place PP reconfiguration addresses a critical bottleneck in dynamic LLM serving. By decoupling memory layout from layer assignment, mitigating fragmentation, and ensuring state consistency with minimal service interruption, PipeLive enables runtime adaptation to workload and resource variations that static deployments cannot match. The technical innovations—especially dynamic non-contiguous KV cache resizing, layer stacking, and incremental patch-based state synchronization—address previously unmanageable practical barriers to real-world reconfiguration.
Pragmatically, the design supports critical features for multi-tenancy, elasticity, and serving in highly variable or serverless environments. The abstraction and mechanisms are orthogonal and composable with parallelism forms beyond pipeline parallelism, opening the path to joint PP/TP/DP (pipeline/tensor/data) optimizations.
The theoretical implication is that dynamic per-request or per-phase adaptation of model resource mapping—informed by prefill/decode load factoring, GPU heterogeneity, and request concurrency—can be realized without introducing the previously prohibitive overhead of restart-based reconfiguration. It suggests future research directions on integrated dynamic resource scheduling and combined data/model parallel serving stacks.
Conclusion
PipeLive establishes a robust and efficient methodology for live, in-place pipeline parallelism reconfiguration for LLM serving, enabling minimal-disruption switching between optimal configurations under heterogeneous and dynamic workloads (2604.12171). Through joint innovation in memory layout, migration orchestration, and coordination protocol, PipeLive demonstrates substantial real-world performance gains and resilience, with strong implications for scalable, elastic, and latency-sensitive LLM service architectures. Future research may extend these principles to multi-parallelism integration, adaptive resource forecasting, and broader deployment scenarios such as serverless and multi-cluster environments.

