- The paper introduces InfiniLoRA, decoupling LoRA computation from base-model inference to improve resource utilization and scalability.
- It demonstrates that disaggregation and hybrid parallelism yield up to 3.05x higher serviceable request rates and a 54% improvement in SLO attainment.
- It employs host-bypass RDMA and hardware-specialized kernels to reduce tail latency and optimize GPU resource allocation.
InfiniLoRA: Disaggregated Multi-LoRA Serving Architecture for LLMs
Motivation and Architectural Evolution
Current LLM serving frameworks rely heavily on Low-Rank Adaptation (LoRA) for parameter-efficient fine-tuning, enabling rapid customization and supporting multi-tenant, multi-task deployments. However, the scaling of base models through Mixture-of-Experts (MoE) architectures leads to substantial inflation of LoRA adapter footprints. KV cache requirements further compound memory fragmentation, sharply limiting LoRA cache residency under coupled designs, which bind LoRA adapters, base model weights, and KV cache within each LLM instance. This produces severe tail-latency inflation and resource underutilization. Empirical results demonstrate dramatic tail TTFT escalation and SLO attainment degradation as LoRA cache ratio decreases (Figure 1).
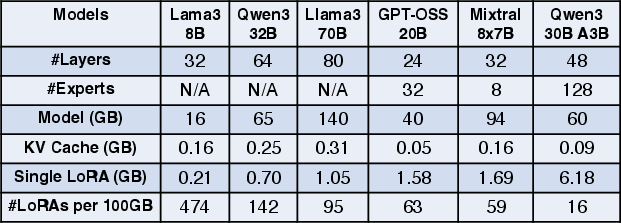
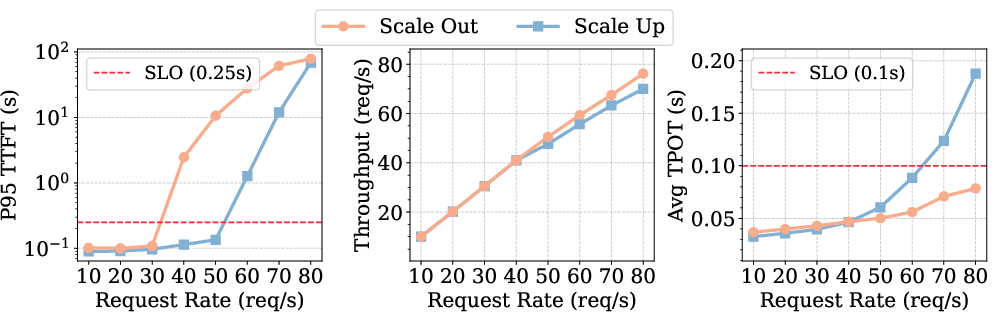
Figure 2: Memory overhead comparison for model weights, KV cache (1024 tokens), and LoRA adapters in dense versus MoE models, with LoRA rank =64.
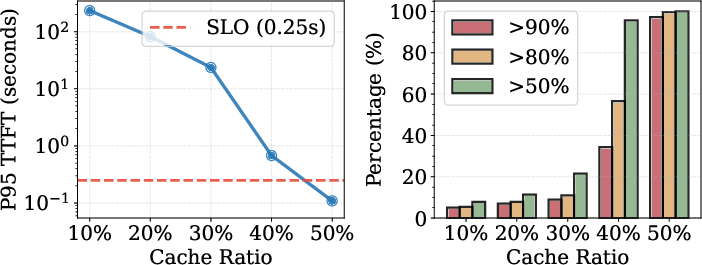
Figure 1: TTFT sensitivity and SLO attainment for varying LoRA cache ratios: lower ratios induce drastic tail-latency inflation and widespread SLO violations.
Coupled designs suffer from fundamental bottlenecks: scaling out duplicates base model and KV cache across instances, minimally increasing cache capacity but wasting memory; scaling up increases cache granularity but expands communication scope, incurs synchronization overhead, and restricts parallelism. These limitations trace directly to the architectural entanglement of LoRA and base model inference.
InfiniLoRA: Disaggregated LoRA Execution
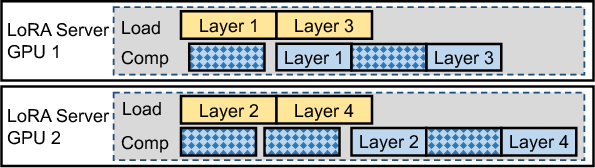
InfiniLoRA decouples LoRA computation from base model inference, introducing a dedicated LoRA Server that manages adapters and executes LoRA computation remotely. LLM instances become LoRA-agnostic, allowing independent scaling and efficient resource utilization.
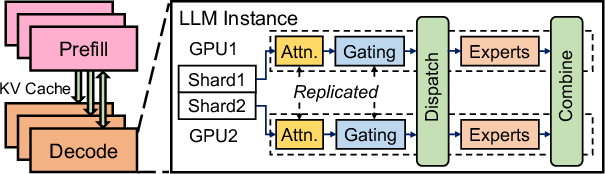
Figure 3: Prefill–decode disaggregated deployment: LLM instances use 2 GPUs each, orchestrated via expert parallelism.
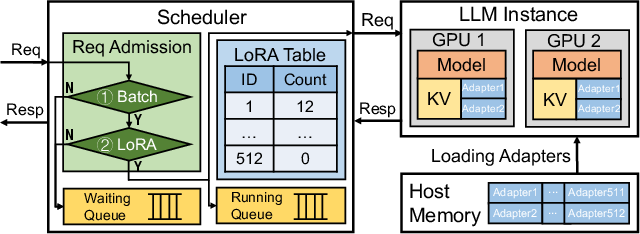
Figure 4: The standard coupled design for multi-LoRA serving, showing cache contention and fragmented memory allocation.
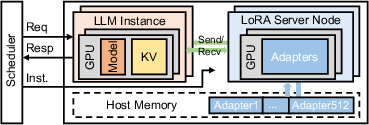
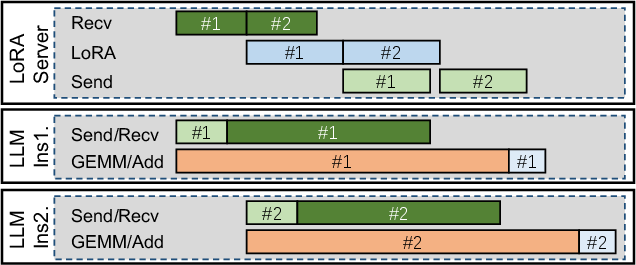
Figure 5: InfiniLoRA's disaggregated architecture: LoRA-adapter residency and computation are handled by a centralized server and are decoupled from LLM instances.
Communication between LLM instances and the LoRA Server is optimized through host-bypass, GPU-initiated push-based RDMA transfers, eliminating sender-receiver synchronization and minimizing network latency (Figure 6).
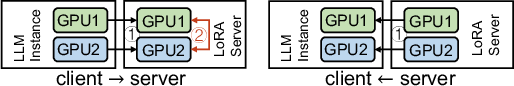

Figure 6: Push-based RDMA protocol for client-server GPU communication, reducing round-trip overhead and batch admission latency.
Parallelism-Aware LoRA Server Design
InfiniLoRA abstracts LoRA adapters as a 3D tensor indexed by adapter, layer, and expert, enabling flexible partitioning. Four parallelization strategies are analyzed: data parallel, pipeline parallel, expert parallel, and hybrid parallelism (EPx–PPy). Hybrid parallelism achieves optimal trade-offs between communication peer count, compute volume, and synchronization scope, balancing load across GPUs while minimizing critical-path extension.
SLO-Driven Resource Provisioning
Provisioning LoRA cache and computation resources is formalized through probabilistic modeling: given adapter invocation probabilities and batch size, the minimum cache size to achieve a target immediate admissibility rate (IAR) is computed via binary search and dynamic programming. Maintaining IAR≥0.95 ensures tail TTFT SLO attainment; throughput constraints are derived through profiling communication and computation latencies. These formulas yield optimal GPU allocations to guarantee TTFT and TPOT SLOs for dynamic workloads.
Critical-Path Optimizations
Critical-path optimizations include:
Experimental Evaluation
Extensive evaluation across five MoE benchmarks (Mixtral-8x7B, DBRX, GPT-OSS-20B, Scaled-MoE, Qwen3-30B-A3B) shows:
- InfiniLoRA achieves 3.05× higher average serviceable request rate than S-LoRA while meeting TTFT and TPOT SLOs (Figure 8).
- SLO attainment rate is improved by an average of 54.0% over S-LoRA.
- Throughput increases by 7.3% on average, and up to 24.7% on DBRX, with fewer LLM instances.
- Higher effective batch size and decoupled resource allocation enhance GPU utilization.
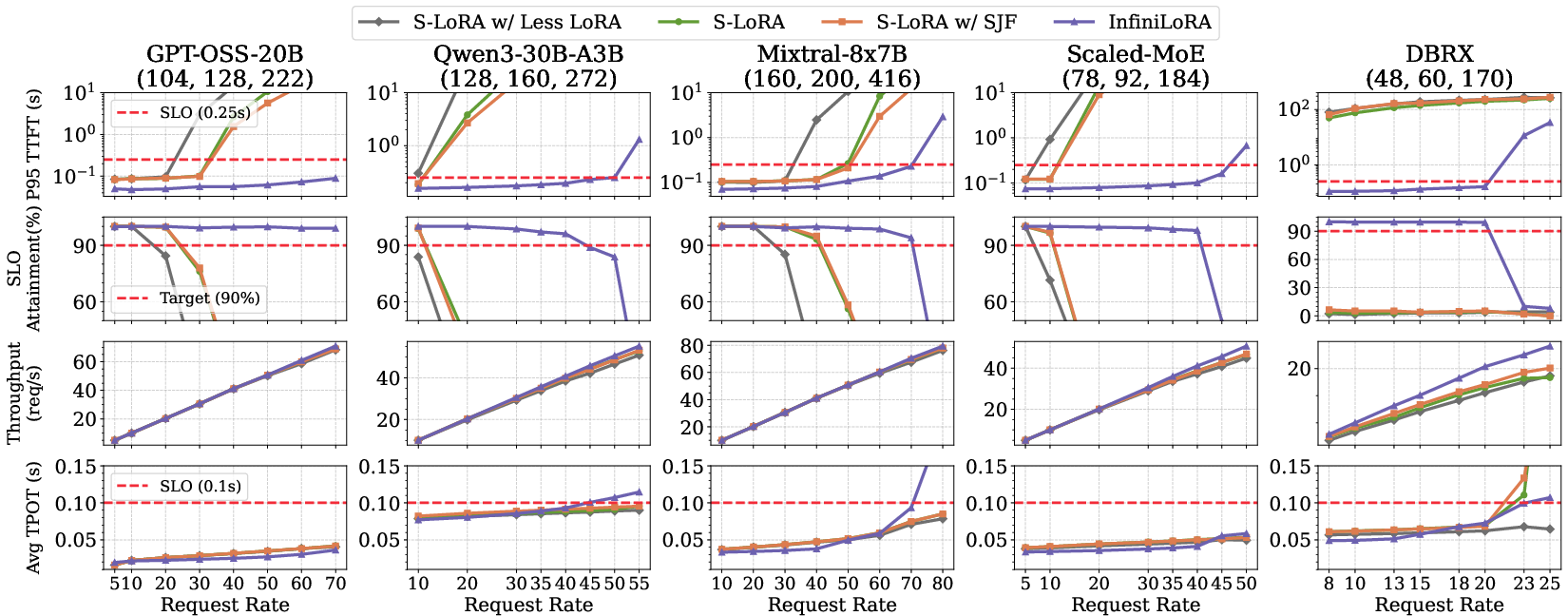
Figure 8: InfiniLoRA versus S-LoRA and S-LoRA/SJF baselines for P95 TTFT, SLO attainment, throughput, and TPOT under increasing request load.
Scaling experiments indicate:
- LoRA Server resource allocation is the dominant bottleneck for supporting more concurrent LLM instances (Figure 9).
- Expanding LoRA Server GPUs directly alleviates cache contention and improves SLO attainment (Figure 10).
- Hybrid parallelism (EP4–PP2) achieves optimal load balance and throughput under disaggregated LoRA execution.
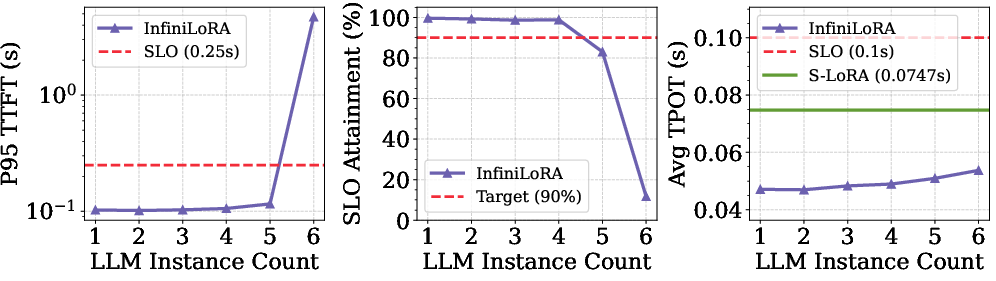
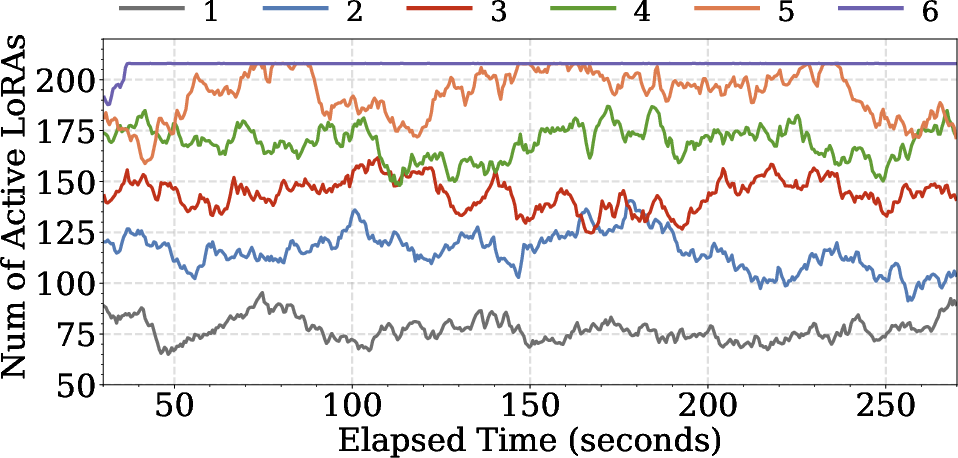
Figure 9: Scalability metrics as the number of LLM instances increases: TPOT remains below SLO with sufficient LoRA Server capacity.
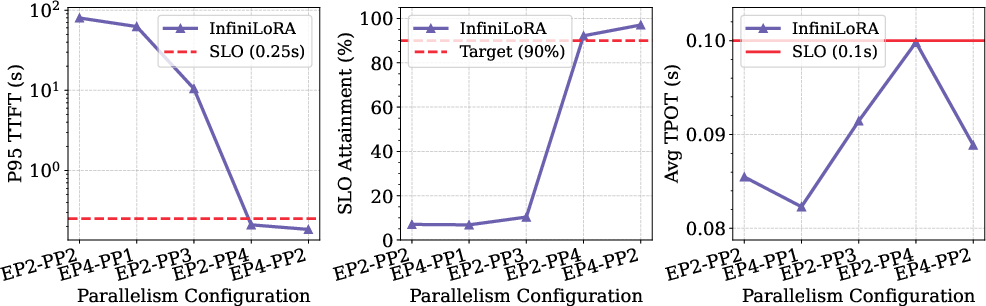
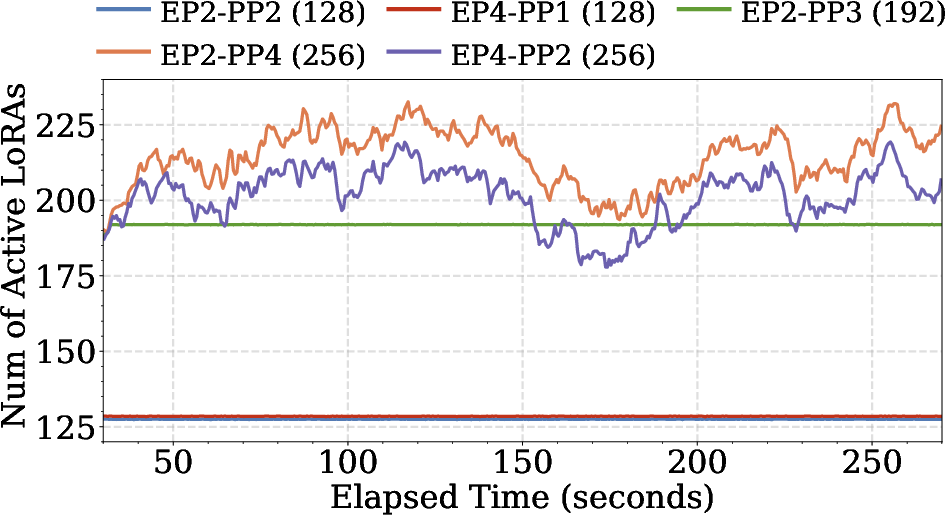
Figure 10: Impact of LoRA Server parallelism configuration on TTFT, SLO attainment, and TPOT performance.
Ablation studies confirm that naive disaggregation (without critical-path optimization) degrades TTFT; incremental addition of overlap, layer-wise loading, and hardware-specialized kernels collectively reduce TTFT by 11× and decrease TPOT by 30% (Figure 11).
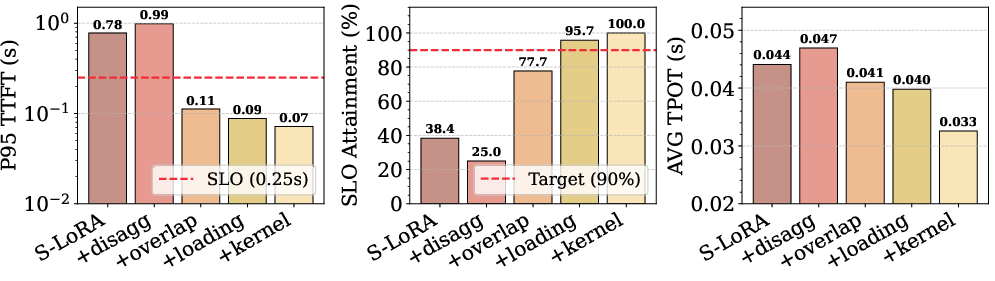
Figure 11: Stepwise optimization benefits for critical-path reductions; full kernel optimization realizes SLO attainment.
Practical and Theoretical Implications
Disaggregated LoRA execution provides architectural flexibility for scaling multi-tenant, multi-task LLM deployments, decoupling memory bottlenecks and tail-latency inflation from base model inference. This enables systematic SLO-driven resource provisioning for dynamic access patterns and adapter popularity skew, extending applicability to data-center and edge environments.
InfiniLoRA's optimizations address communication and compute fragmentation, informed by probabilistic modeling and hardware profiling. The decoupling design offers a clear path toward supporting massive adapter pools (O(1000+)), which is crucial for future agent-centric personalized and RL-driven LLM workflows.
Future Directions
Future work may encompass:
- Integrating advanced scheduling policies (Cannikin [zhu2025Cannikin], Chameleon [Iliakopoulou2025Chameleon]) to further mitigate tail effects under extreme skewed access.
- Unified memory management with KV cache and LoRA cache in elastic pools (FASTLIBRA [zhang2025fastlibra], MemServe [hu2024memservecontextcachingdisaggregated]).
- Disaggregated model-system co-design for attention and expert modules (MegaScale-Infer [zhu2025megascleinfer]), leveraging network and GPU concurrency at larger scales.
- Fine-grained LoRA loading orchestration (AuLoRA [Shi2025aulora], Rock [Wu2025rockserving]) to minimize load-driven TPOT inflation.
Conclusion
InfiniLoRA defines a scalable, resource-efficient, and SLO-driven paradigm for multi-LoRA LLM serving, decoupling LoRA execution from base-model inference and systematically optimizing the critical path. Empirical results validate substantial improvements in request admission, SLO satisfaction, and throughput, supporting widespread adoption in multi-tenant and expert-centric LLM serving architectures (2604.07173).