Morphological Addressing of Identity Basins in Text-to-Image Diffusion Models
Abstract: We demonstrate that morphological pressure creates navigable gradients at multiple levels of the text-to-image generative pipeline. In Study~1, identity basins in Stable Diffusion 1.5 can be navigated using morphological descriptors -- constituent features like platinum blonde,'' beauty mark,'' and 1950s glamour'' -- without the target's name or photographs. A self-distillation loop (generating synthetic images from descriptor prompts, then training a LoRA on those outputs) achieves consistent convergence toward a specific identity as measured by ArcFace similarity. The trained LoRA creates a local coordinate system shaping not only the target identity but also its inverse: maximal away-conditioning produces eldritch'' structural breakdown in base SD1.5, while the LoRA-equipped model produces ``uncanny valley'' outputs -- coherent but precisely wrong. In Study~2, we extend this to prompt-level morphology. Drawing on phonestheme theory, we generate 200 novel nonsense words from English sound-symbolic clusters (e.g., \emph{cr-}, \emph{sn-}, \emph{-oid}, \emph{-ax}) and find that phonestheme-bearing candidates produce significantly more visually coherent outputs than random controls (mean Purity@1 = 0.371 vs.\ 0.209, p<0.00001p < 0.00001 p<0.00001, Cohen's d=0.55d = 0.55 d=0.55). Three candidates -- \emph{snudgeoid}, \emph{crashax}, and \emph{broomix} -- achieve perfect visual consistency (Purity@1 = 1.0) with zero training data contamination, each generating a distinct, coherent visual identity from phonesthetic structure alone. Together, these studies establish that morphological structure -- whether in feature descriptors or prompt-level phonological form -- creates systematic navigational gradients through diffusion model latent spaces. We document phase transitions in identity basins, CFG-invariant identity stability, and novel visual concepts emerging from sub-lexical sound patterns.







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
This paper looks at how text-to-image AI art models, like Stable Diffusion, organize what they “know” inside their hidden space. The authors show that:
- You can steer a model toward a famous person’s look without using their name or photos—just by describing their features (like “platinum blonde hair,” “beauty mark,” “1950s glamour”).
- Even made‑up words built from meaningful sound chunks (like “cr-” in “crash” or “-oid” in “android”) can guide the model to create new, consistent visual ideas.
They call this “morphological addressing,” meaning they use the shape of features—either visual traits or sound pieces—to find reliable paths through the model’s inner “map.”
The main questions (in simple terms)
- Can we reach a specific person’s “look” in a model without saying their name, just by stacking the right descriptive features?
- If we keep training a small add‑on to the model using only the images it creates from those descriptions, will it get better at reaching that look?
- What happens if we try to push the model away from that look—do we get chaos or something strangely consistent?
- Do nonsense words built from sound clusters that often “feel like” certain meanings (like “-oid” for robot‑like) create more consistent images than random gibberish?
- Do these tricks show that the model’s hidden space is organized into “basins” or “valleys” you can navigate into and out of?
How they tested it (methods you can picture)
Study 1: Finding an identity by its features
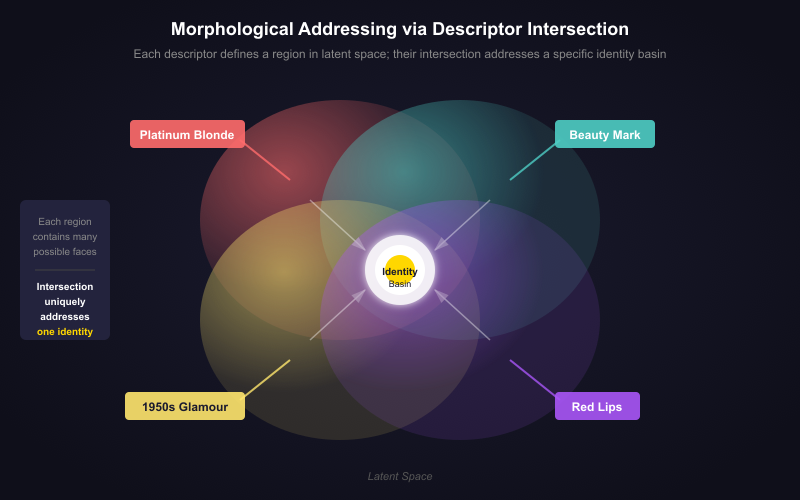
Think of the model’s imagination as a landscape with valleys. Each valley is a familiar “look” it learned during training. A famous person’s look is like a deep valley.
- Instead of using the person’s name, the authors used a recipe of visual features (for example: “platinum blonde,” “beauty mark,” “1950s Hollywood glamour”) to guide the model toward that valley.
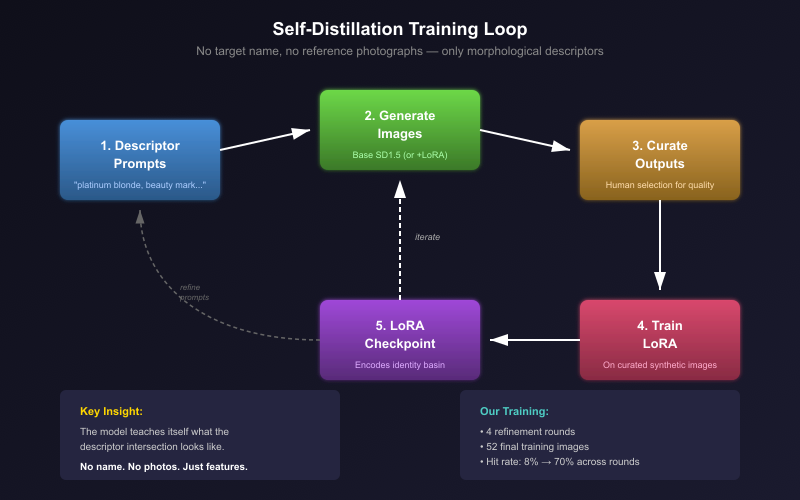
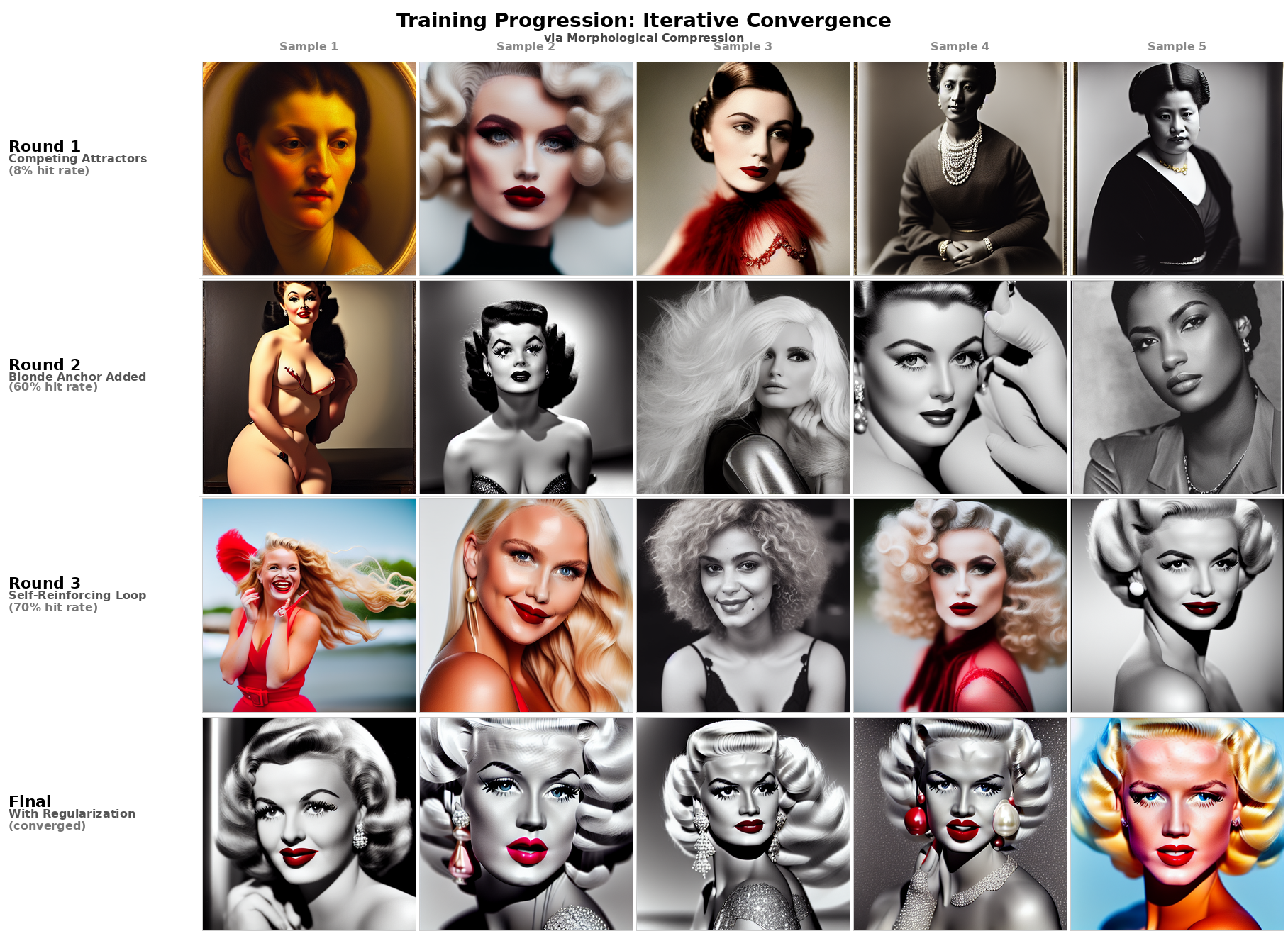
- They then ran a loop: 1) Generate images from those descriptors, 2) Pick the best ones, 3) Train a small adapter called a LoRA on those selected images, 4) Repeat.
This “self‑distillation” loop gradually sharpened the model’s aim. To measure how close images were to the same face, they used ArcFace, a face‑matching tool that turns a face into a fingerprint‑like number so you can compare similarity.
Push–pull tests: Steering away on purpose
They tried three prompting strategies to see how the model behaves when pushed away from the target look:
- Push only: Describe the “opposite” style (e.g., sharp angles, cold lighting, 1980s corporate look).
- Pull only: Use the target’s features as things to avoid (negative prompt).
- Push + Pull: Combine both—push toward the opposite and pull away from the target at the same time.
They ran these both on the base model and on the model with their trained LoRA.
Study 2: Making new ideas with sound-shaped nonsense words
They built 200 made‑up words from sound bits known as phonesthemes—little sound clusters that often hint at meaning in English:
- Onsets like “cr-” (crash/crack) often feel like impact or roughness,
- Suffixes like “-oid” feel robot‑like or “resembling something.”
They compared these to random made‑up words without those sound patterns. For each word, they generated 16 images and asked: do the images made by the same word look like they belong together more than they look like images from other words?
They used a CLIP model (which turns images and text into comparable numbers) to check “Purity@1”: for each image, is its closest neighbor also from the same word’s set? Higher purity means tighter, more consistent visual identity.
What they found (key results)
Study 1: Feature-based navigation works—and reveals structure
- The self‑distillation loop worked. Starting with only feature descriptors, their hit rate for getting the target “look” rose from about 8% to around 70% at best. The LoRA they trained acted like a local coordinate system that reliably guided the model into that identity’s “valley.”
- When they tried to move away from the target:
- Push only produced coherent but different styles.
- Pull only (avoid the target features) produced scattered, inconsistent results.
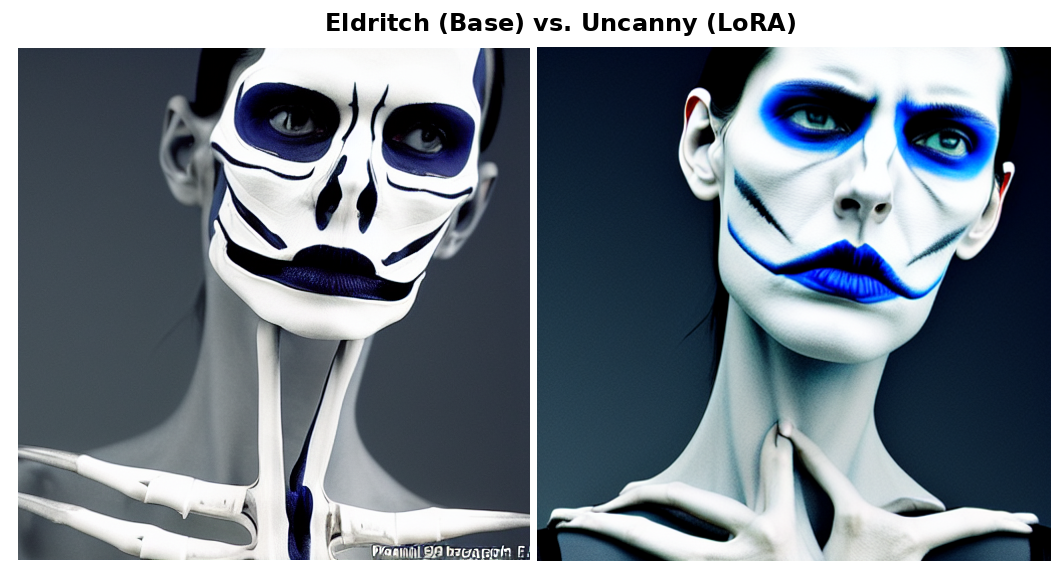
- Push + Pull made the base model generate “eldritch” images—obvious distortions and breakdowns.
- With the LoRA added, Push + Pull moved those “eldritch” glitches into the “uncanny valley”—faces looked almost normal but felt precisely wrong. The LoRA dragged the model back toward human‑like coherence even when pushed into weird regions. The authors call this “coherence drag.”
- Changing guidance strength (CFG) didn’t break identity consistency, suggesting the target “valley” is stable, not a fragile setting.
- Adjusting how strongly the LoRA influenced the image showed “phase transitions”—instead of gradually blending, images “snapped” from one look to another at certain thresholds. That’s like stepping over a ridge between two valleys: sudden switch, not smooth slide.
Why this matters: It shows the model’s inner world has real, structured basins. And small adapters can both pull you into a basin and shape how the model fails when you try to escape it.
Study 2: Sound-shaped nonsense words create real, repeatable visuals
- Made‑up words with phonestheme structure produced significantly more consistent image sets than random pronounceable nonsense. Average Purity@1 was higher for phonestheme words (about 0.371) than for random ones (about 0.209).
- Three phonestheme words—snudgeoid, crashax, broomix—produced perfect consistency (every image’s nearest neighbor was from the same word) and had no signs of being pre‑existing terms:
- snudgeoid → consistent mechanical/robotic humanoids (“-oid” + heavy/“snudge” feel),
- crashax → rugged, impact‑ready vehicles (“cr-” + “-ax” machinery vibe),
- broomix → a comic‑style character with a European bande dessinée feel (“broom” + “-ix” like Asterix).
- Pronounceability alone didn’t help—random pronounceable strings weren’t better than unpronounceable ones. The winning ingredient was the sound‑meaning pattern.
Why this matters: Even sub‑word sound patterns can act like navigation hints for the model, helping it invent new, coherent visual ideas from scratch.
Why this is important (implications)
- Mapping without names or photos: If a model “remembers” a look, you may not need the person’s name or pictures to reach it—feature recipes can be enough. That’s useful for creative control, but it also raises questions about privacy and memorization.
- Better steering tools: Small adapters like LoRA don’t just point toward a concept—they reshape how the model behaves around it, including how it breaks when pushed too far. That could help make models more predictable and safer.
- New concepts from sound alone: The fact that phonestheme words can conjure brand‑new, consistent visual identities suggests a powerful way to invent characters, styles, or creatures by carefully choosing sound pieces. It also shows these models pick up deep patterns from language that go beyond dictionary meanings.
- A more realistic mental map: The “phase transitions” and “valleys” idea gives developers and artists a clearer way to think about how to explore and control a model’s internal space—more like navigating a terrain with ridges and basins than flipping dials at random.
In short, the paper shows that both visual feature recipes and sound‑pattern recipes create reliable paths through a model’s imagination. That makes it easier to find, avoid, or even invent “identities” in AI image generation—opening creative possibilities and highlighting the need for careful, responsible use.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide follow-up research.
- Generalization beyond a single icon: Does morphological addressing and self-distillation work for a broad spectrum of identities (e.g., less-photographed individuals, non-celebrities, non-human concepts)? Build a benchmark across many targets to quantify success rates and failure modes.
- Formal definition of “identity basin”: Provide a rigorous operationalization (e.g., topology, density, boundaries) using latent inversion and manifold analysis to validate claims of attractor regions, sharp boundaries, and phase transitions.
- Ground-truth identity verification: Replace internal clustering metrics with identity correctness against curated reference sets (e.g., ArcFace similarity to known identities’ galleries), not just pairwise similarity among generated outputs.
- Statistical rigor of Study 1 results: Test the reported ArcFace similarity gains for significance and confidence intervals; expand sample sizes beyond 10 seeds; explore robustness across random initializations and prompts.
- Descriptor ablations and minimal addressing sets: Systematically assess which morphological descriptors are necessary/sufficient; quantify the effect of single descriptors, removal tests, and conflicting descriptors on basin navigation.
- LoRA-induced “coherence drag” mechanism: Probe why LoRA shifts “eldritch” breakdown to “uncanny valley” outputs; use feature attribution, layer-wise activations, or latent traversals to identify causal pathways.
- Push–pull conditioning parameterization: Explore negative prompt strength scaling, relative weighting, and CFG interaction; map how push-only, pull-only, and combined vectors vary in effect across parameter sweeps.
- Model and tokenizer dependence: Replicate on SDXL/SD2.1 and non-CLIP pipelines; test whether effects persist with different text encoders/tokenizers (e.g., T5, multilingual tokenizers) and samplers.
- Non-portrait domains: Extend experiments to objects, scenes, and multi-entity compositions to test whether morphological addressing helps where compositional binding often fails.
- Basin strength quantification: Empirically relate identity “basin strength” to training frequency/coverage; measure how hit rates scale with estimated presence of a concept in training data.
- Self-distillation contamination risks: Evaluate whether training on model-generated images amplifies memorization or induces mode collapse; test with inversion-based checks against known training exemplars.
- Ethical and safety implications: Analyze how morphological addressing can bypass name filters to recreate protected identities; propose detection/mitigation strategies for privacy and misuse.
- Reproducibility gaps: Provide missing implementation details (e.g., optimizer, learning rate, GPU/hardware, training time), release code/LoRA weights, and publish curated training sets to enable independent replication.
- Comparison with Concept Sliders and other personalization methods: Conduct head-to-head studies on control granularity, sample efficiency, composability, and inverse shaping to situate contributions relative to prior work.
- ArcFace suitability for stylized faces: Validate identity metrics with multiple recognizers (e.g., FaceNet, MagFace) and human judgements; assess sensitivity to style, pose, and lighting.
- Multi-identity interference: Measure how one LoRA reshapes neighboring basins and whether multiple LoRAs interact (e.g., composability, catastrophic interference, or basin merging).
- Phase transition quantification: Replace descriptive observations with formal analyses (e.g., change-point detection across LoRA weight sweeps, bifurcation diagrams, decision boundary mapping).
- Tokenization analysis in Study 2: Report actual BPE segmentations for each candidate; identify which sub-tokens drive coherence and verify they align with the hypothesized phonesthemes.
- Purity@1 metric limitations: Control for CLIP embedding biases and pool-dependent nearest-neighbor effects; add silhouette scores, cluster separation indices, and alternative encoders (e.g., DINOv2, ImageBind) for triangulation.
- Prompt framing effects: Test “a {candidate}” vs “the {candidate}”, bare tokens, and contextual prompts; quantify how determiners and syntax influence visual coherence.
- Component-level modeling of phonesthemes: Use regression or mixed-effects models to estimate onset, nucleus, and suffix contributions and interactions, controlling for length and phonotactic constraints.
- Reconciling -ix suffix results: Explain why BROOMIX achieves perfect purity while -ix performs poorly on average; test for corpus-driven associations (e.g., Asterix) and hidden contamination.
- Automated contamination checks: Move beyond manual searches by deploying web-scale string/image retrieval, multilingual detection, and embedding-based similarity to pre-existing concepts.
- Cross-model and cross-lingual robustness of phonestheme effects: Evaluate whether sound-symbolic structure induces coherence in other languages and models with different tokenization schemes.
Practical Applications
Immediate Applications
The following applications can be deployed with current diffusion tooling (e.g., SD 1.5), LoRA fine-tuning frameworks, and standard evaluation models (ArcFace, CLIP). Each item notes sector fit, potential tools/workflows, and key assumptions.
- Morphology-only personalization without target photos
- Sector: software, media/entertainment, marketing
- What: Fine-tune LoRA adapters using synthetic images generated from intersecting feature descriptors (e.g., “platinum blonde,” “1950s glamour”) instead of names or photos to achieve consistent “icon-adjacent” styles.
- Tools/workflows: “Descriptor Intersection Trainer” (Kohya_ss + curated descriptor prompts + iterative self-distillation); neutral prompts (“portrait of a person”) for inference.
- Assumptions/dependencies: Target identity basin is strong in the base model; curated descriptor lists; adherence to legal/ethical guidelines around likeness rights and celebrity representation.
- Style steering and stability testing via push–pull conditioning
- Sector: software (model evaluation/QA), safety/red-teaming
- What: Use positive inverse descriptors (push) combined with negative target descriptors (pull) to probe sparse latent regions and observe failure modes (eldritch vs. uncanny).
- Tools/workflows: “Push–Pull Test Harness” (fixed seeds across arms; ArcFace/CLIP clustering analysis).
- Assumptions/dependencies: Access to CFG and negative prompts; consistent seed control; models that expose classifier-free guidance.
- Coherence drag as a safety rail for photorealism
- Sector: software, content moderation/safety
- What: Deploy LoRA adapters that “pull” outputs toward coherent human-like structure even in sparse regions, reducing grotesque breakdowns during generation.
- Tools/workflows: “Coherence Rail LoRA” preloaded on production pipelines; guardrail prompts in UGC platforms.
- Assumptions/dependencies: LoRA trained on coherent human-centric data; ongoing monitoring for “uncanny valley” mis-specifications.
- Identity proximity monitoring for brand safety and compliance
- Sector: policy/compliance, marketing, media
- What: Measure identity convergence (ArcFace similarity) to detect when generations drift toward recognizable individuals; gate or alert when similarity exceeds thresholds.
- Tools/workflows: “Identity Proximity Monitor” (ArcFace embeddings; configurable alert thresholds); log prompts and seeds for auditability.
- Assumptions/dependencies: Threshold calibration by legal/compliance teams; documented policy for handling high-similarity outputs.
- Prompt engineering with phonesthemes for consistent concept generation
- Sector: media/entertainment, game/film concept art, education
- What: Use sound-symbolic clusters (e.g., cr-, sn-, -oid, -ax) to coin nonsense prompts that yield internally consistent visual identities (e.g., “crashax,” “broomix,” “snudgeoid”).
- Tools/workflows: “Phonestheme Prompt Composer” (onset/nucleus/suffix selector; CLIP-based Purity@k scorer); creative exploration UI for artists.
- Assumptions/dependencies: English-centric phonestheme associations in CLIP/BPE; contamination checks to avoid unintended real-world referents.
- Reproducible pipeline settings via CFG-invariant identity stability
- Sector: software/ML ops
- What: Standardize inference parameters (CFG sweeps, LoRA weights) to achieve stable outputs across seeds/guidance ranges.
- Tools/workflows: “CFG Stability Profiler” (reports identity clustering across CFG values; recommended presets per LoRA).
- Assumptions/dependencies: LoRA adapters exhibiting CFG invariance; robust seeding and version control.
- Phase-aware mixing of styles using LoRA weight sweeps
- Sector: creative tooling (photo editors, model UIs)
- What: Provide “snap-to-attractor” sliders that expose discrete phase transitions rather than assuming linear interpolation between identities.
- Tools/workflows: UI/SDK control for LoRA weight with visual preview grid; “Attractor Map” overlay.
- Assumptions/dependencies: Pre-profiled LoRA weight thresholds for phase transitions; user education to avoid overfitting to a single basin.
- Curriculum materials for linguistics and AI literacy
- Sector: education
- What: Classroom demos showing how sound symbolism (phonesthemes) impacts visual coherence in text-to-image models; assignments using Purity@k scoring.
- Tools/workflows: Lesson kits with candidate lists; CLIP-based evaluators; reproducible seed sets.
- Assumptions/dependencies: Access to a local SD1.5 pipeline; instructor guidance on ethical prompt design.
Long-Term Applications
These applications require further research, scaling, policy development, or productization beyond current off-the-shelf setups.
- Latent space cartography and “identity basin atlases”
- Sector: software tools for generative AI, research
- What: Systematic mapping of identity attractors, basin boundaries, and phase transitions across models; searchable atlas to guide prompt engineering and fine-tuning.
- Tools/products: “Latent Atlas” (ArcFace/CLIP embeddings, basin boundary visualizations, LoRA influence fields); APIs for safe navigation.
- Assumptions/dependencies: Cross-model generalization (SDXL, Imagen, Midjourney-like stacks); scalable evaluation; robust privacy/IP policies.
- Morphological gating to prevent targeted likeness reproduction
- Sector: policy, platform safety
- What: Detect descriptor intersections that address protected identities and dynamically attenuate or block generation; move beyond name filters.
- Tools/products: “Morphology Gatekeeper” (descriptor intersection detector; similarity gating; audit logs for regulators).
- Assumptions/dependencies: Clear legal standards for likeness; regulator-approved thresholds; user consent mechanisms.
- Privacy-preserving de-identification filters
- Sector: healthcare, public-sector data sharing, journalism
- What: Use inverse shaping (push–pull away from identity basins) to de-identify faces or sensitive entities while retaining photorealistic coherence for analysis or publication.
- Tools/workflows: “Inverse Identity Filter” (LoRA + negative descriptors; ArcFace dissimilarity targets); risk scoring.
- Assumptions/dependencies: Formal privacy evaluations; bias assessments; assurances that outputs do not map to other real identities.
- Synthetic identity and asset libraries for IP-safe content creation
- Sector: media/entertainment, gaming, advertising
- What: Generate consistent, novel “cryptid” characters and vehicles via phonestheme prompts; build proprietary asset catalogs with uniqueness guarantees (Purity thresholds).
- Tools/products: “Cryptid Studio” (phonestheme composer + Purity scoring + contamination checks; style packs); licensing workflows.
- Assumptions/dependencies: Automated contamination detection across multilingual corpora; long-term distinctiveness monitoring.
- Benchmarks and standards for memorization and identity safety
- Sector: academia, standards bodies, policy
- What: Establish ArcFace/CLIP-based metrics (Purity@k, identity proximity) to quantify memorization and control risks in diffusion models; certification schemes for deployment.
- Tools/products: Open benchmark suites; “Memorization Report Cards”; auditor toolchains.
- Assumptions/dependencies: Community consensus; diverse datasets; reproducibility across vendors.
- Generalized “coherence drag” design for multimodal models
- Sector: software, robotics (perception), safety
- What: Engineer adapters that stabilize outputs in sparse regions across modalities (text, audio, vision) to avoid catastrophic failures while preserving diversity.
- Tools/products: “Coherence Adapters” for vision/audio LMs; cross-modal evaluation (e.g., structural anomaly detectors).
- Assumptions/dependencies: Evidence of similar basin dynamics in other modalities; robust safety testing.
- Cross-lingual phonestheme exploration and tokenizer-aware prompt design
- Sector: research, international product localization
- What: Study sound symbolism across languages to design tokenizer-aware prompts that yield consistent, culturally appropriate outputs; localized cryptid generation.
- Tools/products: “Phonestheme Lab” (multi-language BPE analysis; prompt generators; Purity/contamination pipelines).
- Assumptions/dependencies: Multilingual training exposure in text encoders; cultural/linguistic validation.
- Adaptive UI controls for “descriptor intersection” navigation
- Sector: creative software
- What: Visual navigators that let users intersect feature descriptors to move across identity/style basins, with live feedback on proximity to protected identities.
- Tools/products: “Descriptor Navigator” (Venn-like UI; real-time ArcFace similarity meter; safe-mode toggles).
- Assumptions/dependencies: Fast embedding inference; user education; policy-compliant defaults.
- Compliance-aware generative advertising
- Sector: marketing/advertising
- What: Campaign tools that generate icon-adjacent aesthetics (e.g., “1950s glamour”) while avoiding implicit celebrity likeness; automatic similarity audits before publication.
- Tools/products: “Brand-safe Generator” (descriptor curation; ArcFace audit; legal export reports).
- Assumptions/dependencies: Collaboration with legal teams; sector-specific risk thresholds; archiving for audits.
- Standard operating procedures for LoRA training from synthetic descriptors
- Sector: ML platforms, enterprise AI
- What: Enterprise-grade SOPs that codify descriptor selection, self-distillation loops, phase transition checks, and CFG invariance testing for reliable deployment.
- Tools/workflows: “LoRA SOP Pack” (checklists; automated evaluations; governance dashboards).
- Assumptions/dependencies: Internal MLOps maturity; dataset governance; periodic retraining to track model updates.
Notes on feasibility across applications:
- Many effects rely on SD 1.5-like architectures, CLIP/BPE tokenization, and ArcFace embeddings; portability to other model families must be validated.
- Identity basin strength determines success; cultural icons are more addressable than underrepresented identities.
- Legal/ethical dependencies (likeness rights, consent, content provenance) are central; policies must account for descriptor-based addressing that bypasses name filters.
- Contamination checks are essential for phonestheme concepts to ensure outputs do not inadvertently reference real entities.
Glossary
- Angular margin loss: A loss function that enforces angular separation between classes to produce highly discriminative embeddings in face recognition models. "ArcFace \citep{deng2019arcface} is a face recognition model trained with angular margin loss to produce discriminative embeddings for identity verification."
- ArcFace: A face recognition model that outputs identity embeddings optimized with angular margin loss for verification tasks. "We evaluated all outputs using ArcFace face recognition embeddings, which provide quantitative measures of identity similarity independent of subjective assessment."
- Byte-Pair Encoding (BPE): A subword tokenization method that decomposes words into frequent character pairs, enabling models to handle novel or rare words. "The text encoder that converts prompts into conditioning vectors (CLIP ViT-L/14 in SD~1.5) processes input through byte-pair encoding (BPE), decomposing words into sub-word tokens."
- CLIP ViT-L/14: A specific CLIP encoder architecture (Vision Transformer, large, patch size 14) used to map text and images into a joint embedding space. "The text encoder that converts prompts into conditioning vectors (CLIP ViT-L/14 in SD~1.5) processes input through byte-pair encoding (BPE)..."
- Classifier-Free Guidance (CFG): A diffusion sampling technique that combines conditioned and unconditioned model predictions to control adherence to prompts. "Classifier-free guidance (CFG) in diffusion models works by computing two predictions at each denoising step: one conditioned on the prompt, one unconditioned."
- CFG invariance: Robustness of generated identity under varying classifier-free guidance strengths. "This CFG invariance suggests the LoRA established robust navigational pathways rather than fragile parameter-dependent behavior."
- Coherence drag: A coined effect where a fine-tuned adapter pulls outputs in sparse regions back toward human-like coherence, yielding subtly incorrect results. "We term this effect 'coherence drag.'"
- Compositional binding failure: A generation failure mode where attributes are incorrectly assigned across multiple entities in a prompt. "A known limitation of diffusion models is compositional binding failure---difficulty correctly assigning attributes to multiple entities in complex prompts."
- Concept Sliders: Parameter-efficient controls that isolate low-rank directions corresponding to concepts, enabling composable edits in diffusion models. "Concept Sliders \citep{gandikota2024concept} demonstrated that LoRA adaptors can identify low-rank parameter directions corresponding to specific concepts, enabling precise and composable control over attributes like age, style, and expression."
- Cross-attention maps: Internal attention structures that reveal how models align textual tokens with image regions during generation. "\citet{chefer2023attend} proposed that diffusion models learn a 'hidden language' where cross-attention maps reveal how concepts decompose during generation."
- Crungus: A notable prompt phenomenon where a nonsense word consistently elicits a coherent visual entity across models. "In 2022, the internet discovered 'Crungus'---a nonsense word that, when used as a prompt in text-to-image models, reliably produced a consistent and distinctive creature across different seeds, models, and platforms."
- DDIM inversion: A technique to invert generated images back into the diffusion model’s latent trajectory (h-space) for semantic manipulation. "\citet{kwon2023diffusion} identified that DDIM inversion h-space contains interpretable semantic directions, showing that simple arithmetic operations on these representations can modify specific attributes."
- Decision boundaries: Sharp separations in latent space that cause outputs to snap between distinct attractors rather than interpolate smoothly. "the latent space contains distinct attractor regions separated by decision boundaries, not smooth probability gradients."
- Denoising step: An iteration in diffusion sampling where noise is progressively removed using model predictions. "Classifier-free guidance (CFG) in diffusion models works by computing two predictions at each denoising step: one conditioned on the prompt, one unconditioned."
- DreamBooth: A personalization method that fine-tunes a model on a few target images, preserving generality via a prior loss. "DreamBooth \citep{ruiz2022dreambooth} fine-tunes the entire model on 3--5 photographs, binding a unique identifier to the subject through 'prior preservation loss' to prevent overfitting."
- Eldritch: A descriptive term used for outputs exhibiting obvious structural breakdown and non-human anomalies. "base SD1.5 produces 'eldritch' structural breakdown..."
- GLORP Theory: A proposed framework where meaning emerges from geometric position in embedding space rather than explicit semantics. "We term this framework 'GLORP Theory' (Generative Latent Output from Random Prompts), though the acronym itself emerged through collaborative AI systems attempting to domesticate the original meaningless centroid."
- Identity basin: A stable attractor region in latent space corresponding to a specific memorized identity. "identity basins in Stable Diffusion 1.5 can be reliably navigated using morphological descriptors---constituent features like 'platinum blonde,' 'beauty mark,' and '1950s glamour'---without using the target identity's name or photographs."
- InsightFace buffalo_l: A pre-trained face recognition model variant that outputs 512-D embeddings for identity analysis. "We used the buffalo_l model from InsightFace, which extracts 512-dimensional embedding vectors from detected faces."
- LAION: A large-scale web-scraped dataset whose captions can trigger memorized outputs in diffusion models. "demonstrated that prompting Stable Diffusion with exact LAION captions can reproduce near-identical training images, including identifiable individuals."
- Latent space: The model’s internal representation space where semantic concepts and identities form structured regions. "Together, these studies establish that morphological structure---whether in training-level feature descriptors or prompt-level phonological form---creates systematic navigational gradients through the latent spaces of diffusion models."
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method that learns small adapter matrices to steer model behavior. "We trained a LoRA on Stable Diffusion 1.5 using synthetic training images generated from morphological descriptor prompts---no photographs of Marilyn Monroe, no use of her name."
- Low-rank adapter matrices: Compact trainable components that modify model behavior without changing base weights. "LoRA \citep{hu2021lora}, originally developed for LLMs, enables parameter-efficient fine-tuning by training low-rank adapter matrices rather than modifying base weights directly."
- Negative prompts: Conditioning that specifies attributes to avoid, creating directional pressure away from those features. "Negative prompts in diffusion models (implemented through classifier-free guidance) were originally intended to exclude unwanted attributes---'low quality,' 'watermark,' etc."
- Phase transitions: Abrupt qualitative shifts in outputs indicating discrete changes between attractor basins. "we observed sharp phase transitions rather than gradual interpolation."
- Phonestheme: A sub-morphemic sound cluster associated with consistent meanings across words. "Drawing on phonestheme theory from linguistics, we generate 200 novel nonsense words constructed from English sound-symbolic clusters (e.g., cr-, sn-, -oid, -ax)..."
- Prior preservation loss: A regularization term in DreamBooth that prevents overfitting by maintaining generality. "DreamBooth \citep{ruiz2022dreambooth} fine-tunes the entire model on 3--5 photographs, binding a unique identifier to the subject through 'prior preservation loss' to prevent overfitting."
- Purity@1: A clustering metric indicating how tightly a candidate’s outputs group together in embedding space relative to all others. "Three candidates---snudgeoid, crashax, and broomix---achieve perfect visual consistency (Purity@1 = 1.0) with zero training data contamination..."
- Push-pull conditioning: A protocol combining inverse descriptors (push) with negative target descriptors (pull) to navigate away from an attractor. "Our 'push-pull' conditioning protocol combines positive inverse descriptors with negative target descriptors, which we observe creates enough directional force to overshoot stable attractors entirely and access sparse latent regions."
- Self-distillation: An iterative loop where a model trains on its own generated outputs to refine its behavior without external data. "Through a self-distillation loop (generating synthetic images from descriptor prompts, then training a LoRA on those outputs), we achieve consistent convergence toward a specific identity as measured by ArcFace similarity."
- Sound symbolism: The phenomenon where sound patterns carry semantic associations that influence meaning or model outputs. "Our second study draws on a separate tradition: sound symbolism and phonestheme theory."
- Stable Diffusion 1.5: A widely used text-to-image diffusion model version serving as the base for experiments. "identity basins in Stable Diffusion 1.5 can be reliably navigated using morphological descriptors..."
- Textual Inversion: A technique that learns a new pseudo-word embedding to represent a concept using reference images. "Textual Inversion \citep{gal2022image} instead learns new pseudo-word embeddings from similar reference images."
- Tokenizer artifacts: Unintended behaviors arising from how tokenizers split or encode text, sometimes yielding spurious coherence. "The standard explanation invoked tokenizer artifacts or random attractor basins."
- Uncanny valley: Outputs that are anatomically plausible yet subtly wrong, producing an unsettling effect. "the LoRA-equipped model produced 'uncanny valley' outputs---coherent but precisely wrong."
- Word2Vec embeddings: Vector representations learned from text corpora that capture semantic relationships among words. "Using Word2Vec embeddings, we found that 'glorp' (word #49 in the original list) emerged as closest to the mathematical center---the word whose position in embedding space minimized distance to the average of all others."
Collections
Sign up for free to add this paper to one or more collections.