- The paper introduces AffordSim, which integrates open-vocabulary affordance prediction with VLM-driven scene generation to automate data collection and benchmarking for robotic manipulation.
- It demonstrates robust cross-embodiment deployment and advanced domain randomization, which together enhance sim-to-real transfer performance across diverse robotic tasks.
- Experimental results reveal that affordance-guided grasping significantly improves success rates in semantically sensitive tasks compared to generic grasp estimation methods.
AffordSim: A Scalable Framework for Affordance-Aware Robotic Manipulation Data Generation and Benchmarking
Introduction
AffordSim introduces an integrated simulation framework that addresses the critical gap in robotic manipulation: the lack of affordance-aware trajectory generation in existing platforms. By incorporating open-vocabulary 3D affordance prediction based on VoxAfford, AffordSim enables automated generation of manipulation demonstrations that target functional object regions specified by natural language instructions. This facilitates both large-scale data collection and rigorous benchmarking of manipulation policies—particularly for tasks where semantically correct interaction with task-relevant object parts is essential.
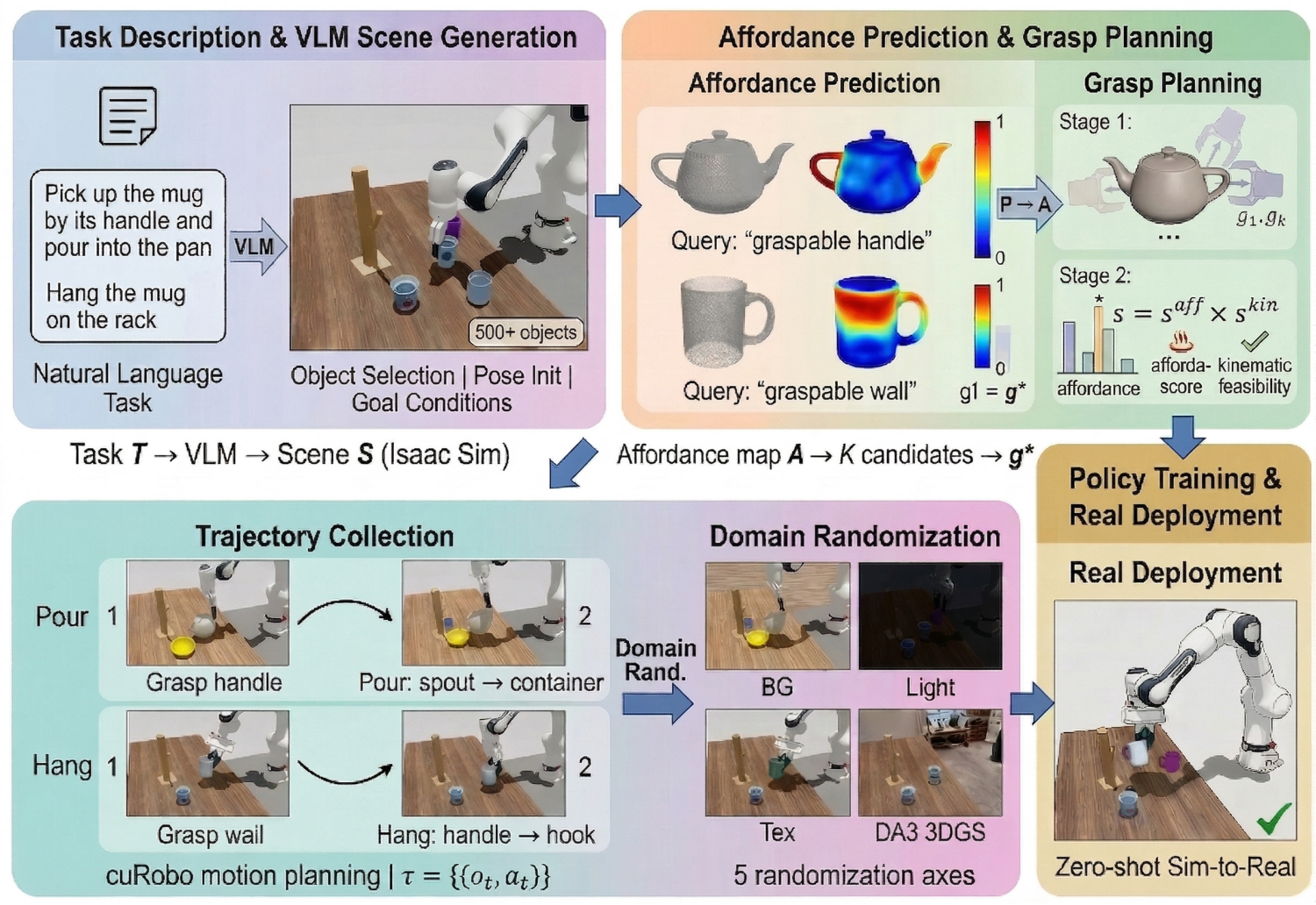
Figure 1: Overview of the AffordSim pipeline, which leverages VLM-based scene generation, VoxAfford affordance prediction, and domain randomization for sim-to-real transfer.
Framework Architecture and Simulation Pipeline
AffordSim’s core technical advances include automated VLM-driven scene and task generation, integration of the VoxAfford model for open-vocabulary 3D affordance detection, affordance-aware grasp selection, and advanced domain randomization for sim-to-real transfer.
Given a natural language task instruction, the VLM configures a simulation scene, including selection and pose initialization of relevant objects and choice of robot embodiment. VoxAfford predicts spatial affordance heatmaps on object point clouds, guiding grasp candidates toward high-confidence functional regions. A constrained optimization jointly scores candidate grasps for both affordance alignment and kinematic feasibility. Motion plans are then generated and executed within NVIDIA Isaac Sim for four supported robot platforms (Franka FR3, Panda, UR5e, Kinova), and domain randomization is applied across lighting, textures, object poses, and real-scene background reconstructions using 3D Gaussian Splatting (DA3).

Figure 2: Visualization of domain randomization in AffordSim, illustrating the impact of randomizing pose, lighting, background, and noise across several representative tasks.
The framework supports scalable, automated generation of demonstrations across a 50-task benchmark spanning seven manipulation categories with varying degrees of affordance complexity.
Benchmarks: Task Coverage and Policy Evaluation
AffordSim’s benchmark is organized around seven manipulation types: grasping, placing, stacking, pushing/pulling, pouring, mug hanging, and long-horizon composite tasks, addressing increasing levels of affordance dependency and sequencing. The system leverages a library of 500+ objects, with a subset 3D-scanned for added fidelity. For each task, 300 demonstrations are collected under heavy domain randomization, and four imitation learning methods are evaluated: BC, Diffusion Policy, ACT, and Pi 0.5.

Figure 3: Representative tasks across all seven AffordSim manipulation categories, highlighting task diversity and complexity.
Experimental Analysis
Aggregate and Per-Category Results
AffordSim exposes the performance boundary of modern imitation learning with respect to affordance complexity. Grasping achieves high success rates (up to 93%), indicating that current policies can reliably execute simple pick-ups given affordance guidance. However, tasks necessitating precise, semantically-correct manipulation—such as pouring into narrow-mouthed containers (success rates as low as 1–43%) and mug hanging (0–47%)—remain inadequately solved.
Pi 0.5 consistently outperforms all baselines (mean success rate 61%), with Diffusion Policy and ACT trailing (44% and 35%, respectively); BC falls substantially behind, failing to generalize to multimodal, affordance-sensitive tasks.
Importance of Affordance Integration
Ablation studies demonstrate that policies leveraging automated affordance-guided grasps (VoxAfford) substantially outperform those using generic grasp estimation (AnyGrasp), especially on tasks with task-specific functional region requirements. Manual, human-specified grasps set an upper bound that is only closely approached in affordance-rich regions; when VoxAfford’s training set covers the necessary affordance queries, performance approaches oracle levels. Coverage gaps for non-standard affordances (e.g., mug body grasps for hanging) degrade policy competence and highlight the importance of extending affordance training data.
Cross-Embodiment Generalization
AffordSim supports trajectory and data generation for multiple robot arms without task-specific retuning. Success rates are consistent across Franka FR3, Panda, and Kinova (83–95%), but somewhat lower for UR5e (83%), attributed to the latter’s kinematic singularities in high-orientation tasks rather than any affordance inference error.
Figure 4: Cross-embodiment deployment of affordance-aware policies on Franka FR3, Panda, UR5e, and Kinova robots.
Sim-to-Real Transfer and Robustness
When evaluated on a real Franka FR3, zero-shot transfer success rates track simulation difficulty: grasping (60%) and push/pull (40%) remain feasible, while pouring and mug hanging drop significantly (20% and 10%, respectively). Domain randomization, particularly with DA3-based scene backgrounds, enhances robustness to environmental perturbations and supports transferability even to visually altered deployment spaces. Absence of DR during training substantially impairs performance and generalization.
Limitations and Future Directions
AffordSim’s effectiveness is contingent on the coverage and precision of the VoxAfford model: rare-object geometries, occlusions, and non-canonical affordances degrade prediction reliability. The framework does not address deformable object manipulation or bimanual/in-hand complexity, which demand alternative simulation engines and richer functional region representations. The DA3-based real-scene background capture, while photorealistic, requires additional image acquisition effort per workspace and may not generalize in more dynamic or mobile robot deployments.
Future research directions include expanded affordance annotation datasets, learning from dynamic human demonstration, richer task sequencing, and integration of deformable object affordance modeling.
Conclusion
AffordSim establishes object affordance as a primary axis for robotic policy evaluation and manipulation data generation. By unifying open-vocabulary affordance prediction, automated multimodal scene construction, and robust domain randomization, AffordSim delivers scalable, high-fidelity training data and exposes the unsolved nature of affordance-demanding tasks under current policy paradigms. Its benchmark provides a foundation for systematic progress and comparison across future models, architectures, and affordance modeling advances.