- The paper introduces an affordance-based generative framework to synthesize diverse robotic manipulation trajectories.
- It decomposes expert demonstrations into key phases and uses 3D keypoint correspondence with DINOv2 for semantic matching across objects.
- Experimental results show a 24% improvement on unseen tasks and robust zero-shot cross-category generalization in both simulation and real-world settings.
AffordGen: A Framework for Affordance-based Demonstration Generation for Robotic Manipulation
Introduction
AffordGen addresses longstanding limitations in visuomotor imitation learning for robotic manipulation, specifically the data hunger and poor generalization across geometric and semantic variations in task environments. While recent synthetic data generation pipelines enhance spatial diversity, their scope is usually restricted to a single object instance, leading to inadequate generalization to novel and cross-category objects. AffordGen proposes a novel approach: treating affordance correspondence not as a mapping for planner-based transfer, but rather as a powerful generative prior to produce large-scale, semantically meaningful, and geometrically diverse manipulation trajectories. This synthesis of affordance knowledge and closed-loop policy learning yields robust zero-shot generalization and state-of-the-art success rates in both simulation and real-world tasks.
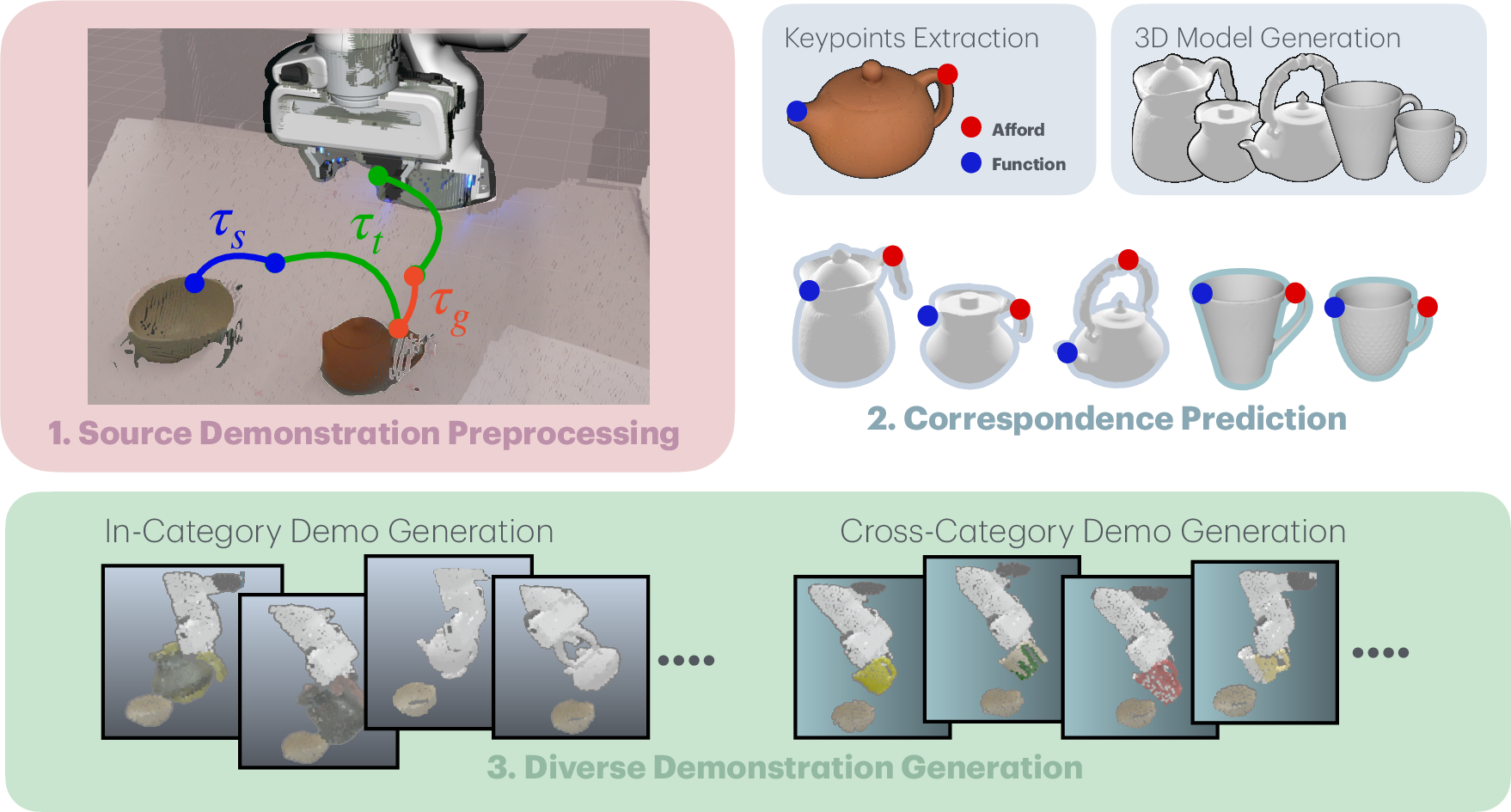
Figure 1: AffordGen pipeline overview: segmentation of expert demonstrations, 3D keypoint correspondence via VFMs, and trajectory generation leveraging affordance knowledge across categories.
Methodology
AffordGen proceeds through several technical stages to generate data-efficient training sets supporting robust closed-loop visuomotor policies.
Demonstration Decomposition and Keypoint Extraction
AffordGen begins by decomposing a single expert demonstration into canonical manipulation sub-stages: grasp (ΩG), skill (ΩS), and transition (ΩT). Grasping and skill stages are considered to encode most of the task-relevant semantics. From the initial demonstration, the system extracts the grasp timestamp, skill phase, and crucial 3D keypoints—specifically affording and function points. Semantic segmentation (typically via SAM2) on RGB-D frames localizes objects in the workspace to prepare data for further processing.
Semantic Correspondence Across 3D Meshes
A critical innovation in AffordGen is the establishment of accurate 3D keypoint correspondences between the source mesh and arbitrary target objects. Each mesh is normalized into a canonical space and rendered from multiple views. For each keypoint, DINOv2 is used to compute robust feature descriptors and identify nearest-neighbor keypoints by maximizing contextual cosine similarity. This process is agnostic to category boundaries, allowing correspondence transfer across distinct but functionally similar object classes.
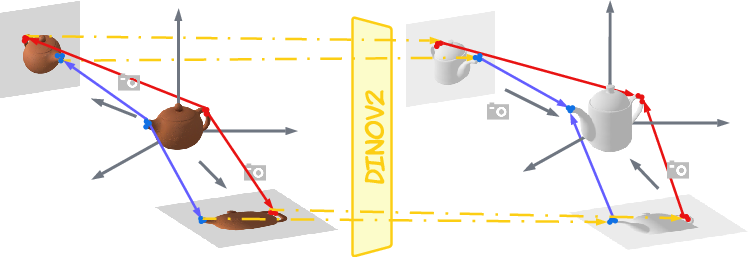
Figure 2: Mapping of semantic keypoints between source and target meshes in canonical 3D space using DINOv2 feature similarity.
Trajectory Generation and Motion Synthesis
The core data generation proceeds by replaying grasp and skill segments onto novel mesh instances. The approach rigidly maintains end-effector-to-affording-point and function-point-to-goal-object transformations, justified empirically by the functional consistency within manipulation skills. Transition segments are synthesized using collision-free planners or spherical linear interpolation in SE(3). The resulting trajectories are rendered directly in simulation, replacing the active and robot components while preserving real background and occlusion artifacts for increased realism. This hybrid digital cousin approach ensures generalizability and mitigates the sim-to-real gap.
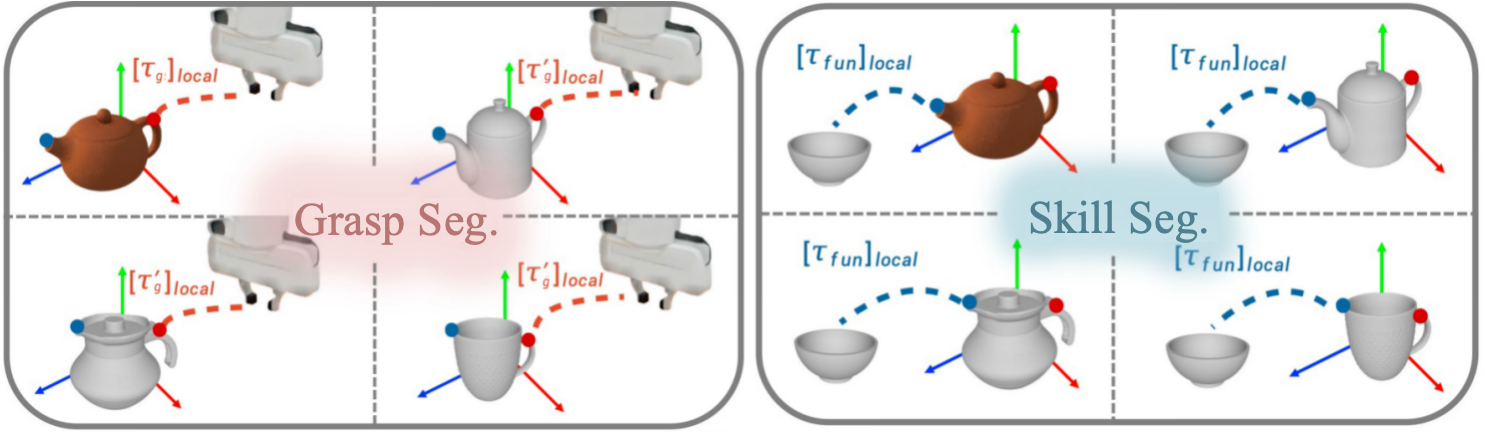
Figure 3: Consistent replay of grasp and skill trajectory segments across diverse 3D object meshes.
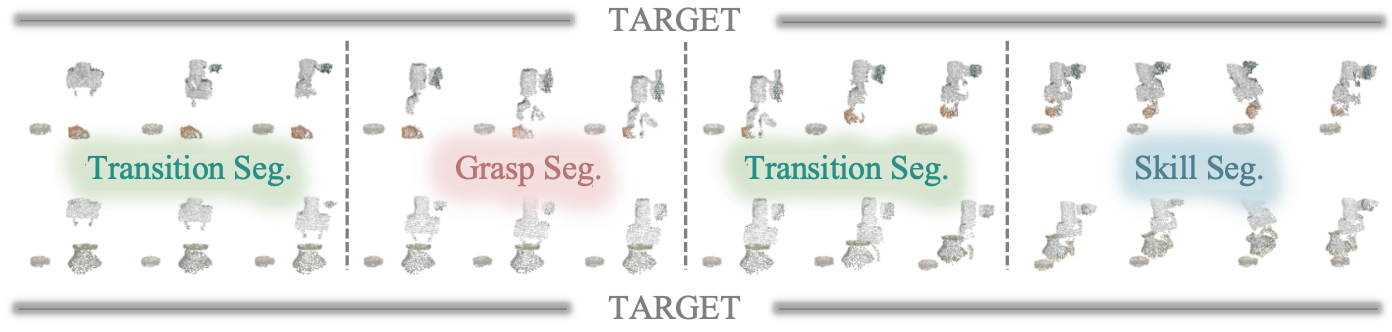
Figure 4: Example: Source versus generated teapot pouring trajectories, segmented by manipulation phase, demonstrating preservation of semantic skill across instantiations.
Experimental Results
Experiments span both extensive simulation using ManiSkill3 and real-world, hardware-in-the-loop evaluations. Four benchmark tasks (teapot pouring, mug hanging, knife cutting, and shoe organizing) test in-category and cross-category generalization.
In-Category Generalization
Trained exclusively on AffordGen-generated demonstrations, closed-loop policies achieve high spatial and geometric generalization to hundreds of unseen object meshes and configurations. Under settings such as 100×10 (100 meshes, 10 demos per mesh), AffordGen policies outperform DemoGen and CPGen by an average of 24.1% in simulation and 24.3% in real scenarios on unseen object evaluations.

Figure 5: Simulation task setup: four manipulation tasks used to evaluate in-category and cross-category transfer.
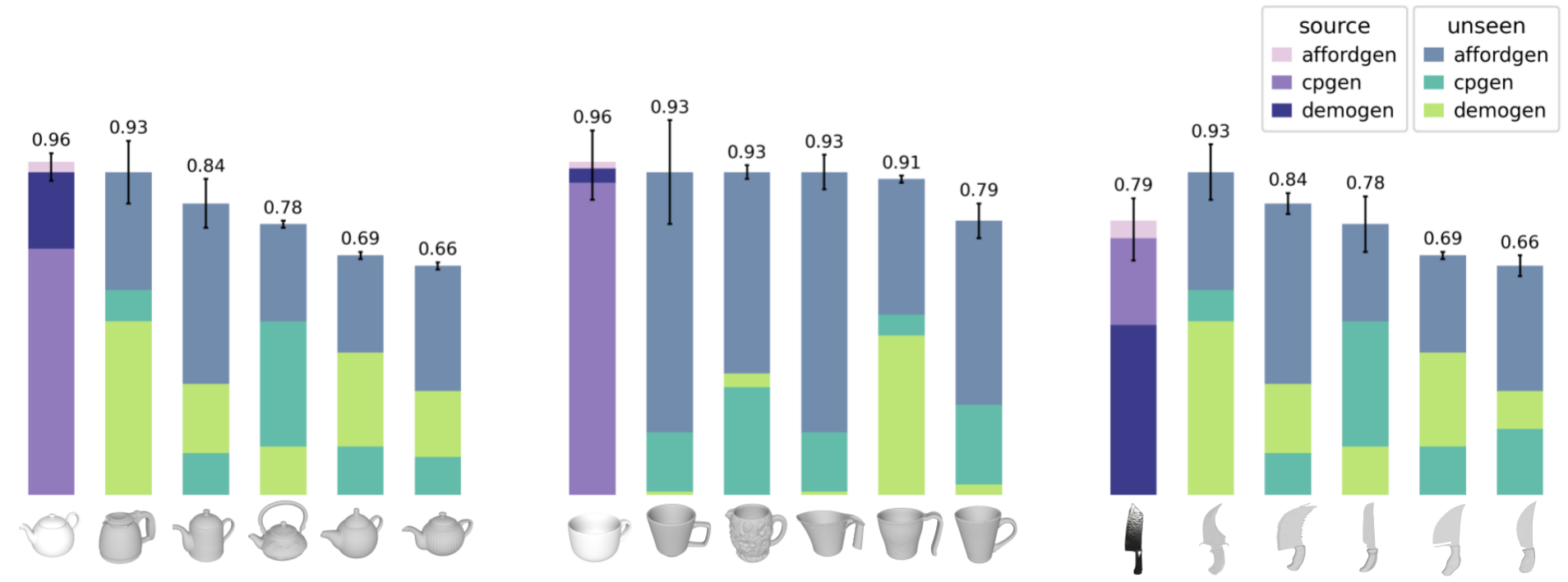
Figure 6: Policy success rates across a spectrum of mesh instances, demonstrating stable generalization even as mesh dissimilarity increases.
Zero-shot Cross-category Generalization
AffordGen uniquely supports zero-shot generalization across functional object categories sharing similar affordance semantics (e.g., transferring teapot pouring to mugs, mug hanging to handbags, or knife cutting to saws). In all cases, AffordGen is the only method to achieve non-trivial policy generalization, whereas baseline methods (DemoGen, CPGen) and open-loop, planner-based methods (e.g., FUNCTO) fail to effectively cross categories.

Figure 7: Visualization of cross-category simulation tasks: (a) mug pouring, (b) handbag hanging, (c) saw cutting.
Real-world Experiments
Real-robot evaluations corroborate the simulation results. Notably, AffordGen-trained policies display strong robustness to occlusion and viewpoint variability—key failure points for planning-centric baselines reliant on keypoint visibility. The closed-loop, end-to-end policies mitigate correspondence noise and adaptation errors, substantially improving real-world task success rates on out-of-distribution objects.




Figure 8: Real-world execution of the teapot pouring manipulation policy, generated solely from synthetic demonstrations.

Figure 9: Real hardware setups for cross-category zero-shot policy generalization—each setting evaluating transfer to a novel object class.
Implications and Future Directions
AffordGen establishes a principled, scalable paradigm for leveraging affordance correspondence as a generative data prior. This bridges the gap between semantic/functional alignment and the requirements of robust, reactive, closed-loop visuomotor control. The implications for real-world scalable robot learning are significant: minimal human supervision can be extrapolated to thousands of objects and configurations without suffering from the inherent brittleness of open-loop or planner-centric systems.
Practically, AffordGen represents a promising direction for expanding the versatility of generalist manipulation policies, supporting rapid deployment to unseen tasks and environments with minimal annotation. The methodology suggests further research avenues in improving semantic correspondence robustness (e.g., better VFM-based 3D keypoint detectors), integration with task planning via LLMs, and merging with generative 3D asset creation pipelines, facilitating large-scale, multi-modal, end-to-end embodied policy training.
Conclusion
AffordGen demonstrates that affordance correspondence, when leveraged as a generator of task-consistent, semantically grounded manipulation data, efficiently scales limited demonstrations to thousands of diverse training trajectories spanning multiple object categories and pose configurations. Closed-loop policies trained on AffordGen’s synthetic data consistently outperform both translation-based and planning-centric baselines in both simulation and real-world generalization, particularly on zero-shot and cross-category transfer experiments. This work marks significant progress towards scalable, robust, and generalizable robot manipulation, laying groundwork for future advances in affordance-driven synthetic data generation and autonomous policy learning.

