- The paper presents Relax as an asynchronous reinforcement learning engine that scales omni-modal post-training via service decoupling and staleness control.
- It leverages a three-layered architecture—control, computation, and data planes—to ensure fault isolation, low latency, and independent scaling across diverse modalities.
- Experimental results demonstrate up to 2.00× speedup in training while maintaining reward convergence and reducing overhead compared to existing RL systems.
Relax: An Asynchronous RL Engine for Omni-Modal Post-Training at Scale
Motivation and Design Challenges
Reinforcement learning (RL) post-training has become central to unlocking advanced reasoning, self-reflection, and tool-use capabilities in large foundation models, especially as these models transition from unimodal (text) to omni-modal inputs and from single-turn to multi-turn agentic workflows. Current RL training systems encounter three interdependent challenges:
- Heterogeneous Modality Pipelines: Training samples can now include text, images, audio, and video, each exhibiting disparate data representations, preprocessing latencies, and computational requirements. Existing text-centric RL frameworks, with ad hoc multimodal support, suffer from brittle designs and inefficiencies.
- Operational Robustness at Scale: Broader modality support leads to increased long-tail latency variance and higher risk of hardware/resource failures. This demands system-level fault isolation, elastic scaling, and rapid recovery beyond the traditional checkpoint-restart paradigm.
- Execution Decoupling and Policy Freshness: Synchronizing across the RL pipeline (e.g., rollout generation, reward computation, policy update) can result in severe throughput degradation due to straggler phenomena, especially as rollout steps become longer and more variable.
System Architecture
Relax introduces a co-designed, three-layered architecture comprising:
- Control Plane: A central Controller issues coordination directives but remains stateless regarding execution.
- Computation Plane: RL “roles” (e.g., actor, critic, rollout, reward model) execute as independent, Ray Serve-deployed services with dedicated resource quotas and health checks.
- Data Plane: All inter-role communication is mediated exclusively by TransferQueue, an asynchronous distributed data bus supporting field-level, modality-aware data exchange.
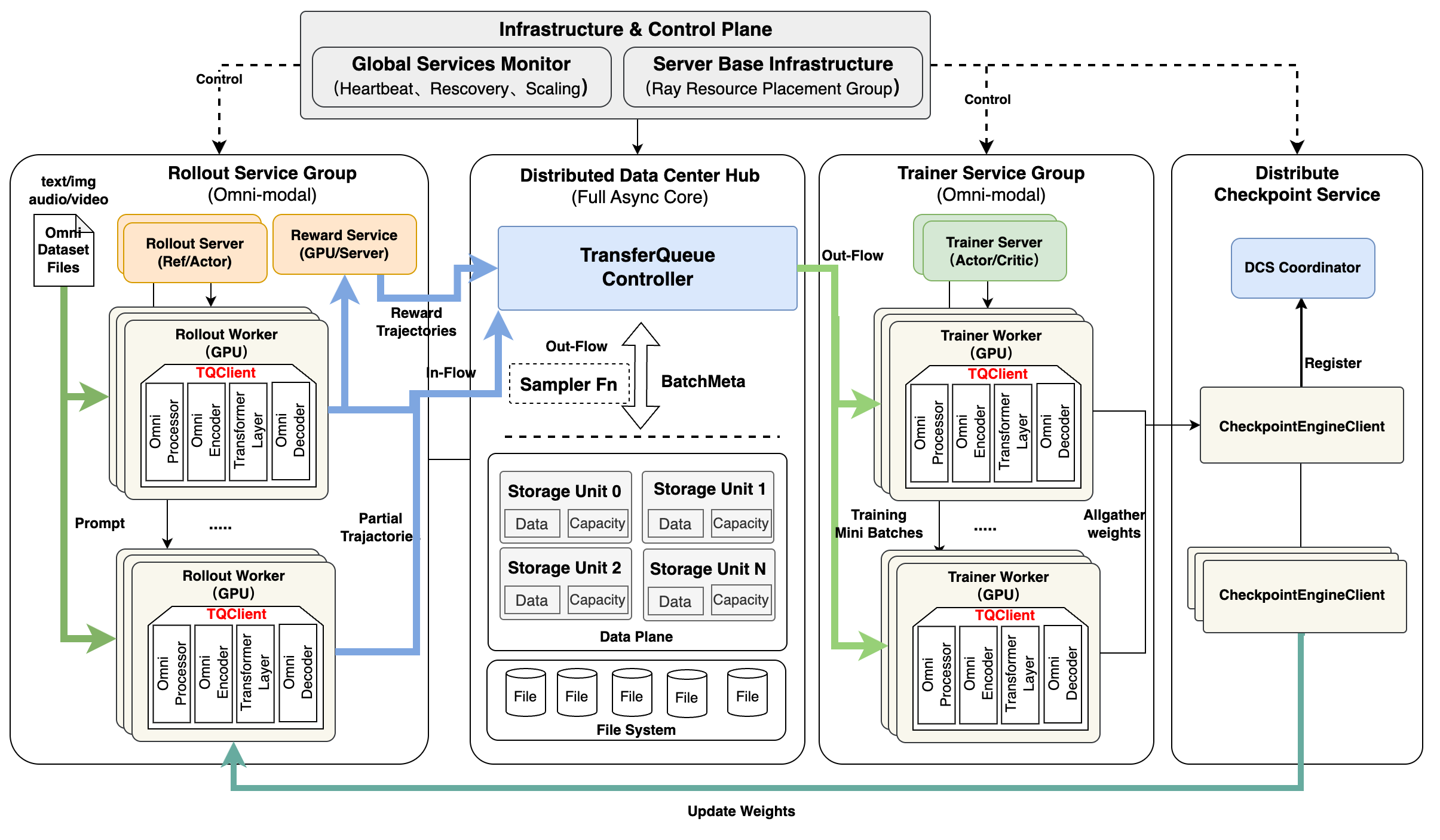
Figure 1: The system decomposes RL training into control, computation, and data planes, decoupling concerns and enabling independent evolution and scaling.
Operational robustness is achieved through per-role fault isolation with a Distributed Checkpoint Service (DCS), supporting both intra- and inter-cluster model weight synchronization for scaling and recovery.
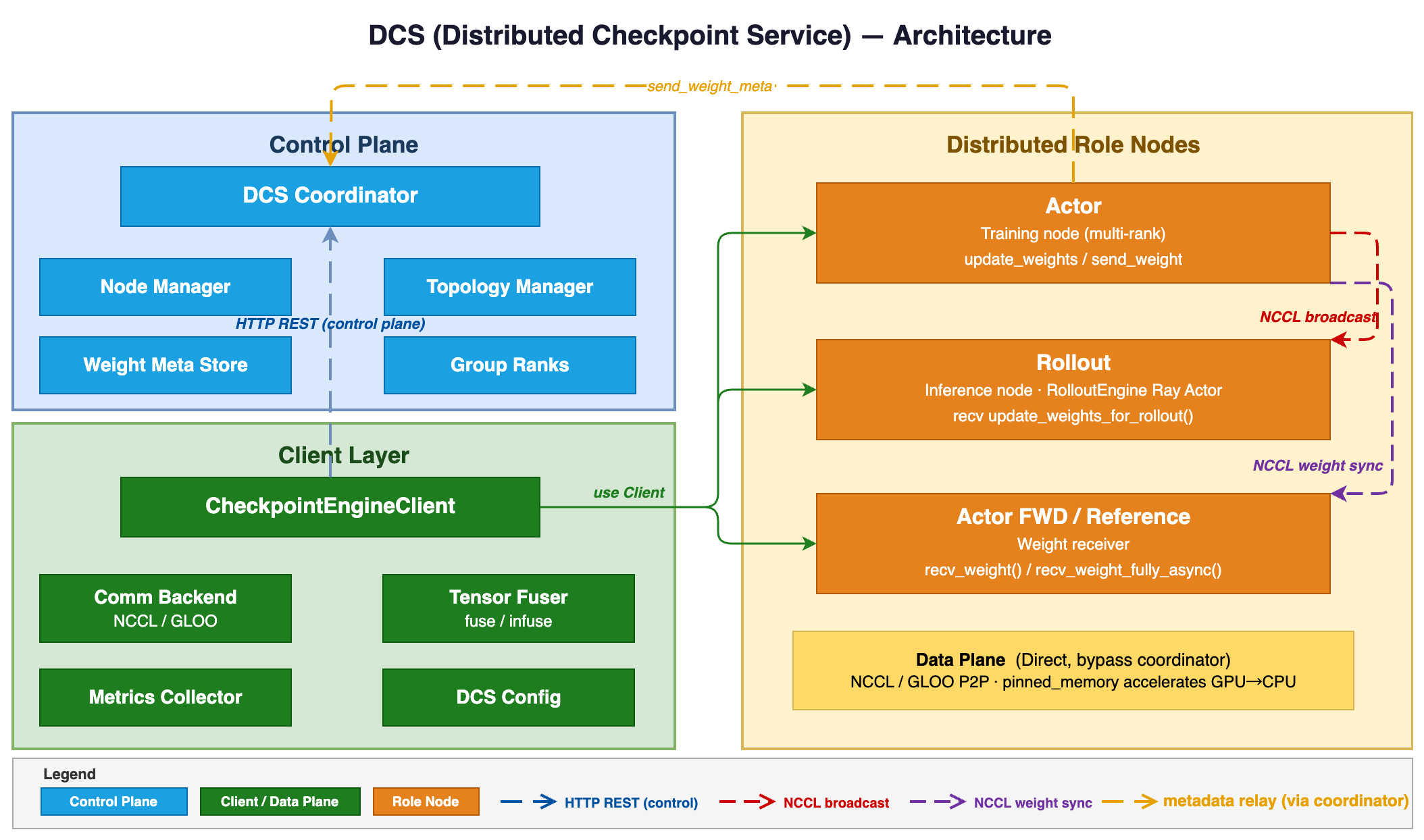
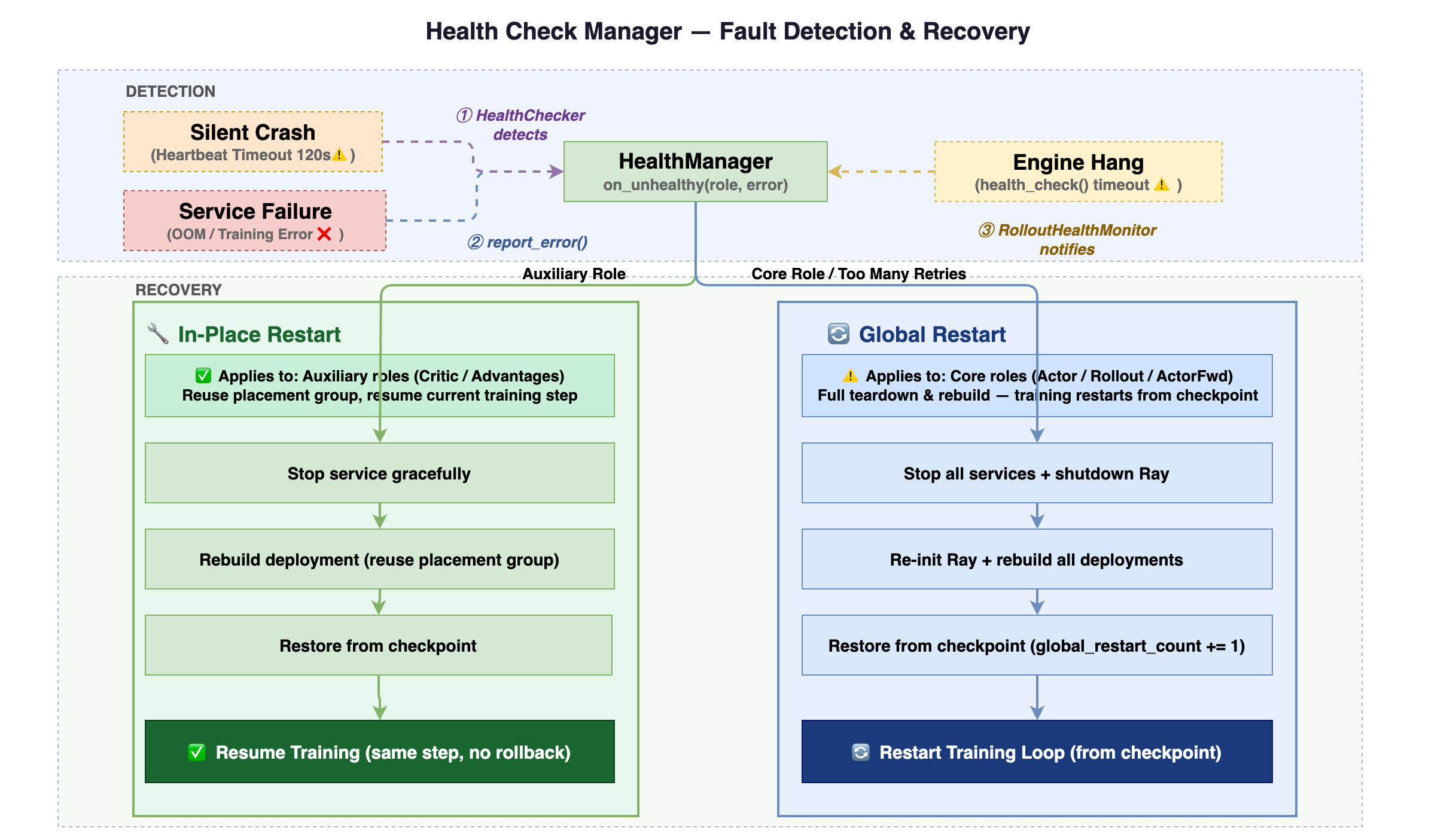
Figure 2: DCS architecture enables efficient and low-latency distribution of model weights to inference backends across heterogeneous clusters.
Asynchronous and Flexible Training Execution
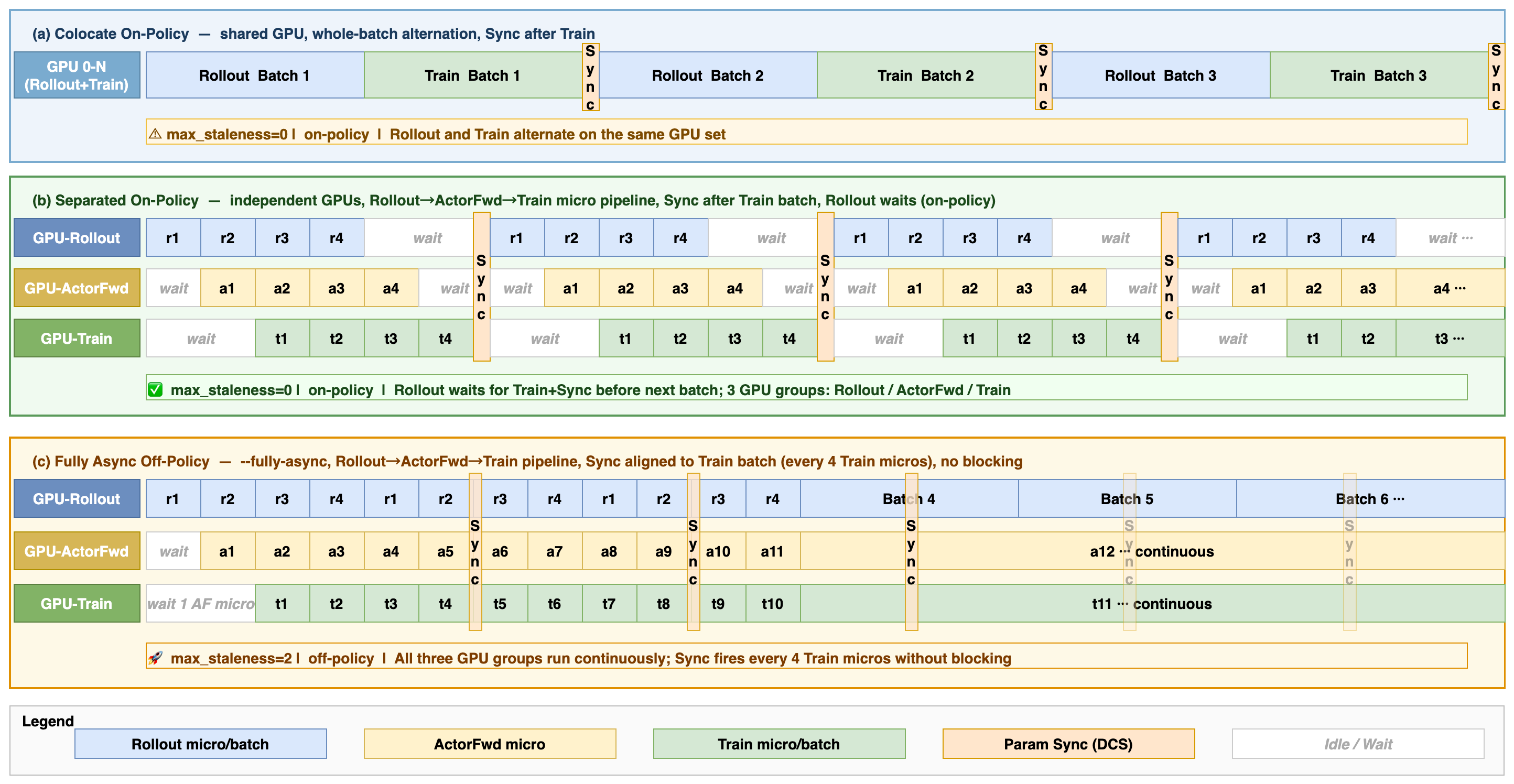
Relax’s design cleanly separates deployment from execution, enabling two primary modes unified by a staleness parameter:
Data flow further becomes micro-batched and streaming: sub-batches are dispatched to downstream roles immediately upon readiness, eliminating global batch-level tail latency bottlenecks.
Omni-Modal and Agentic RL Support
A central innovation is the omni-native design—multimodal support permeates all layers of the system, not as an afterthought. The data pipeline handles arbitrary interleavings of text, images, audio, and video, with turn-level binary masks necessary for correct RL loss computation when assistant outputs are conditioned on user inputs spanning multiple modalities. The pipeline is dynamically configured via partial application, accommodating different model architectures (e.g., Qwen-VL, Qwen-Omni) with minimal code change.
Relax supports vision-LLMs and general multi-modal architectures with:
- Modality-aware parallelism (e.g., all TP ranks replicate ViTs, while raw multimodal encoders are kept stage-local via encoder-aware pipeline parallelism).
- Megatron Bridge integration for seamless HuggingFace ↔ Megatron checkpoint translation.
- Field-level decoupling in TransferQueue, allowing, for example, image fields to be consumed before latent video fields are ready, supporting pipelines with cross-modal and variable-latency characteristics.
Additionally, extensible agentic workflows are supported: multi-turn rollouts, pluggable reward functions (both rule-based and LLM-judged), and sandboxed tool execution are all handled as services with standardized interfaces.
Experimental Validation
Omni-Modal and Agentic Convergence
Comprehensive experiments demonstrate stable and monotonic RL reward convergence across vision-language and general multi-modal models. Qwen3-Omni-30B, on the Echo Ink and NextQA benchmarks, reaches and sustains high reward plateaus across thousands of RL steps for image+audio+text and video tasks with low variance and no degradation, validating the system’s robust modal orchestration.
Relax yields 1.20× end-to-end speedup over veRL in on-policy scenarios on Qwen3-4B. Under off-policy, fully async training, the speedup increases to 1.76× over colocate for Qwen3-4B and 2.00× for Qwen3-Omni-30B, with all modes converging to the same reward, indicating that throughput gains do not incur a statistical efficiency penalty.
Mode and Overhead Analysis
Due to streaming and modal-field decoupling, Relax achieves nearly zero idle time in async mode, while colocate suffers increasing per-step overhead as model size grows. The staleness parameter allows seamless control between modes, making the system robust to different operational settings.
MoE Stabilization with R3
MoE architectures are susceptible to rollout/ training route mismatch, degrading RL stability. Relax integrates Rollout Routing Replay (R3) and achieves near-zero additional overhead—only 1.9% on step time—whereas veRL incurs 32% slowdown under the same configuration. R3 sharply reduces routing mismatch without harming convergence.
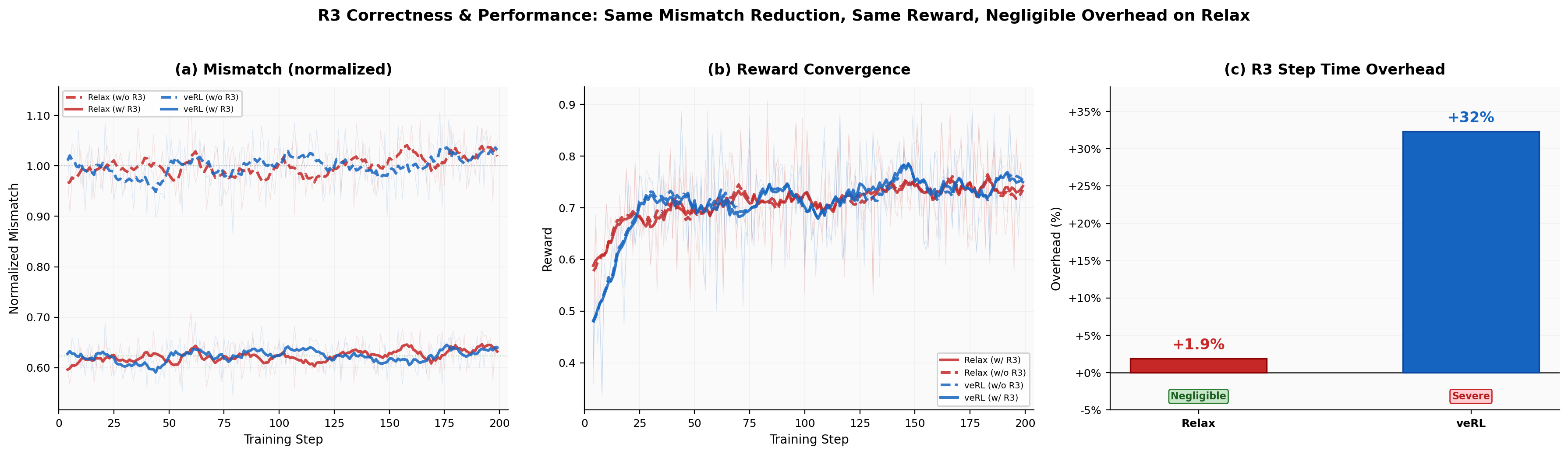
Figure 4: R3 ablation: Relax achieves a 1.9% time overhead enabling R3, versus 32% for veRL, with both systems showing improved log-probability consistency and reward convergence.
Practical and Theoretical Implications
From a practical standpoint, Relax’s causal co-design—integrating omni-modality, service-level isolation, and asynchronous execution—provides a foundation for robust, scalable RL post-training suitable for research and industrial deployment. The field-level and service-based abstractions enable rapid algorithmic innovation and straightforward adoption of emerging RL techniques or new modalities.
Theoretically, the capacity to tightly couple system-level throughput (via asynchrony) and statistical policy freshness (via modulated staleness) challenges prior RL design dichotomies, indicating the potential for more general and efficient RL training frameworks. The ability to maintain reward convergence despite high degrees of asynchrony and modal heterogeneity suggests that RL algorithms can be robust in much more flexible systems, provided proper staleness and routing management.
Future Directions
The architecture is readily extensible to agentic RL tasks involving complex tool use, extended multi-turn interaction, or integration of generative, non-text modalities (e.g., image/video generation via RL). Richer support for large-scale elastic resource scaling and autoscaling, as well as even larger models (100B+), is under active development. Extending the framework to support RL for generative output modalities presents an open and promising direction.
Conclusion
Relax demonstrates that tight systems–algorithms co-design is required to scale RL post-training to the demands of contemporary and future omni-modal, agentic models. Its field-level asynchronous architecture achieves high throughput, operational robustness, and strong convergence across a range of modalities and training configurations, while remaining open, extensible, and statistically efficient. The system represents a new standard in RL post-training infrastructure, supporting next-generation foundation model capabilities.
Relax is available at https://github.com/redai-infra/Relax.