- The paper shows that VLMs encode multi-level aesthetic attributes using layer-wise linear probing, underpinning personalized aesthetics assessment.
- It introduces a methodology that leverages user-specific linear regressors over frozen hidden states to predict subjective image scores without fine-tuning.
- Experiments reveal that VLM representations yield superior cross-domain transfer and personalization, outperforming traditional text-based and fine-tuning methods.
Aesthetic Attribute Encoding and Personalization in Vision-LLMs
Introduction
This paper addresses the central question of what aesthetic information is internally encoded by vision–LLMs (VLMs) and whether such representations can be effectively leveraged for personalized image aesthetics assessment (PIAA) without model fine-tuning (2604.11374). The motivation stems from the practical requirements of user-level aesthetics modeling and the limitations associated with current methods, which often require domain-specific adaptation, large-scale additional training, and are empirically restricted in their transferability across image styles and domains.
Methodology
The proposed framework systematically examines the internal hidden representations across both vision and language components of modern VLM architectures, with a particular focus on Qwen3-VL and Gemma 3, to assess the linearly accessible encoding of multi-level aesthetic attributes. The primary approach is to employ layer-wise linear probing: for each transformer layer in the VLMs, hidden states are extracted (via average pooling) and regressed to known image-level aesthetic attribute scores from established datasets (AADB for fine-grained attributes, PARA and LAPIS for personalized scores). The analysis distinguishes representations coming from vision encoders, language decoder vision tokens, and language decoder text tokens.
A distinguishing aspect of this work is the rigorous evaluation of personalization. Instead of direct model tuning or parameter-efficient adaptation (e.g., LoRA), the method constructs per-user linear regressors atop pooled hidden VLM representations, predicting subjective user scores in a lightweight manner. This pipeline explicitly separates general (GIAA) and personalized (PIAA) performance and is evaluated under both photographic and artwork domains.
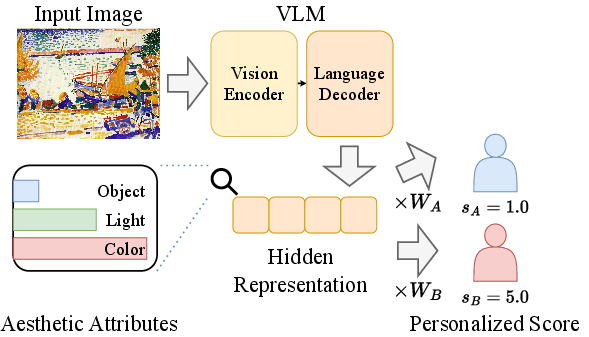
Figure 1: Overview of PIAA using VLM representations. Aesthetic attributes encoded in VLM hidden states are mapped to user-specific scores via linear regression without fine-tuning.
Probing Results: Layer-wise Aesthetic Attribute Encoding
Layer-wise linear probing exposes that state-of-the-art VLMs encode a diverse set of aesthetic attributes—including color harmony, content, object placement, and vivid color—in their hidden representations with statistically significant, attribute-dependent Spearman correlation coefficients (many exceeding 0.5).
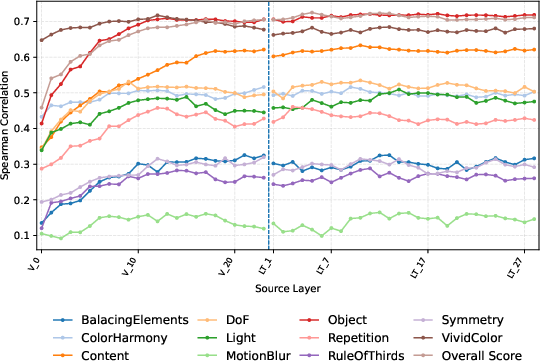
Figure 2: Layer-wise probing performance in Qwen3-VL 2B reveals the propagation of aesthetic signals from early vision encoder layers into mid-layer language decoder states.
A notable result is the propagation and localization of aesthetic attribute information:
- For Qwen3-VL, attribute probing performance is comparably strong in both vision encoder and language decoder layers, consistent across several attributes.
- For Gemma 3, the transfer and concentration of attribute-relevant information is maximal in early-to-middle language decoder layers for text tokens, aligning with prior findings on cross-modal information transfer in transformer-based VLMs.
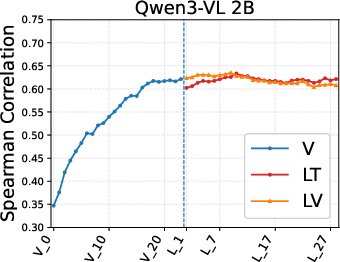
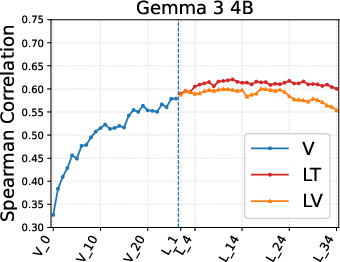
Figure 3: Fine-grained analysis of the Content attribute demonstrates disparate layer-wise encoding across Qwen3-VL and Gemma 3, supporting the claim of architecture-dependent attribute encoding.
Model scaling trends are nontrivial: smaller VLMs sometimes match or surpass larger ones in attribute prediction, contradicting the expectation that increased size monotonically increases all forms of interpretability or alignment.
Personalized Image Aesthetics Assessment: Efficacy and Domain Behavior
The core PIAA method—Linear-Hidden, employing user-specific regression atop language decoder states—achieves strong user-level Spearman correlation on both PARA (photographs) and LAPIS (artworks). Linear-Hidden consistently outperforms all text-based alternatives, including few-shot prompting, LoRA, and bias-adjusted textual GIAA prediction, often by wide margins (e.g., 0.611 vs. 0.570 in PARA, 0.568 vs. 0.176 in LAPIS for Qwen3-VL 4B).
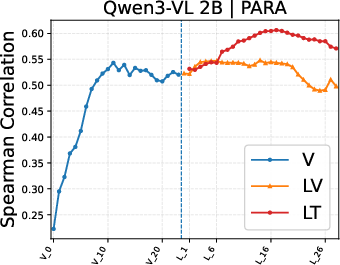
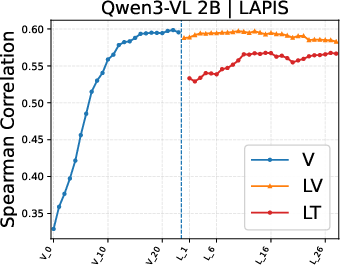
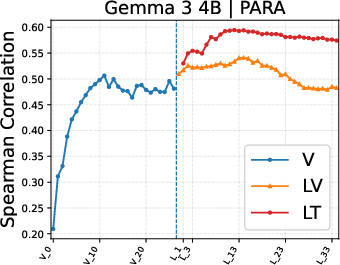
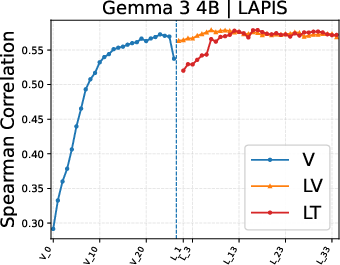
Figure 4: Layer-wise analysis demonstrates highest PIAA performance in mid-layer language decoder representations; vision encoder features are inferior, especially for artistic images.
Layer-wise experiments reinforce the centrality of language decoder mediators for PIAA in photos, shifting toward vision encoder or vision token representations for artworks, suggesting that domain and supervision diversity modulate where in the architecture subjectivity manifests.
Qualitative results confirm that personalized regressor outputs match nuanced user preferences across image types, accurately demarcating, for instance, user disinterest in realistic portraits and preference for abstract, color-rich images.



Figure 5: For a representative user, Linear-Hidden assigns high scores to colorful, abstract images and low scores to realistic portraits, outstripping GIAA-based methods.
Analyses: Attribute Sufficiency and Domain Generalization
A critical ablation examines whether low-dimensional, manually enumerated aesthetic attributes (e.g., the 11 attributes in AADB) suffice for personalization. On PARA, linear regressors operating in this reduced attribute space perform on par with full VLM representations. In contrast, substantial gaps emerge on LAPIS—demonstrating that for complex or less-codified image domains (artworks), significant idiosyncratic information exists in VLM embeddings not captured by basic attributes.
Head-to-head comparisons with dedicated, domain-specific PIAA systems (e.g., PIAA-ICI) reveal parity on in-domain tasks, but Linear-Hidden is far superior in cross-domain transfer to artworks. This indicates that heavy attribute- and domain-specific pretraining constrains generalization, while large VLM representations are inherently robust under moderate domain shift.
Additional analysis of "hard" users (those whose scores are uncorrelated with GIAA) confirms that genuine personalization is feasible in photographs when inter-user variance is substantial. For users whose rankings diverge from the average, Linear-Hidden provides clear gains in ranking correlation over GIAA-only baselines.
Implications, Limitations, and Future Directions
The findings establish that VLMs pretrained on large, mixed-modal corpora encode multi-level subjective attributes that are linearly accessible, with the representations suitable for lightweight, user-level personalization without further model adaptation. There are important implications for the design of future aesthetic alignment systems on user-facing platforms:
- Model developers can achieve individual-level adaption at inference time by learning regressors over frozen hidden states, reducing the need for prohibitive fine-tuning cycles per user.
- For practical deployment in personalized content selection or recommendation, results stress the need for expanded attribute coverage, particularly for domains inadequately described by canonical image aesthetics taxonomies.
From the theoretical viewpoint, the work underscores that cross-modal co-training (vision–language) does not dissipate fine-grained visual attribute information in the course of transformer processing; rather, language decoder intermediaries may enhance downstream linear accessibility for subjective attributes.
There remain, however, substantial limitations:
- The attribute sets used, while richer than those in prior studies, may still be insufficient to capture the breadth of subjective visual experience, especially in abstract or hybrid domains.
- The presence of linearly accessible signals does not guarantee they are efficiently deployed by the model during text generation; output modulation likely requires additional intervention.
- Deployment of such personalization raises fairness and bias concerns, as personal and demographic information could be leveraged maladroitly.
Conclusion
This work rigorously clarifies the existence, locus, and leverageability of personalized aesthetic encoding in large VLMs. The results provide both practical and conceptual foundations for future research in interpretable, user-adaptive aesthetic judgment, particularly regarding how further supervision or architectural modifications can expose and harness deeper strata of user-specific visual preference within multimodal LLMs.