- The paper presents a novel evaluation framework for zero-shot isolated sign language recognition, leveraging prompt-based inference with general-purpose vision-language models.
- Experiments reveal that proprietary models reach up to 25.6% synonym-aware Top-1 accuracy, yet still fall short compared to specialized ISLR systems.
- Analysis highlights prompt sensitivity and ordering biases, underscoring the need for domain adaptation and refined prompt engineering for reliable performance.
Zero-Shot Isolated Sign Language Recognition with Vision-LLMs
Introduction
This work presents a thorough investigation into the capability of modern Vision-LLMs (VLMs), including both open-source and proprietary architectures, to perform Isolated Sign Language Recognition (ISLR) in a zero-shot setting. Unlike prior research that focuses heavily on supervised models or sign language translation (SLT), this study examines whether general-purpose VLMs, without any task-specific training or fine-tuning, can directly recognize individual American Sign Language (ASL) signs from video input by leveraging purely prompt-based inference. The evaluation leverages the WLASL300 benchmark, providing a realistic assessment of VLM generalization to structured, fine-grained spatio-temporal recognition tasks.
Problem Motivation and Context
The automation of sign language understanding has significant implications for accessibility and multimodal human-computer interaction. While ISLR—recognition of isolated signs from video—is structurally more controlled than continuous recognition or translation tasks, it poses unique challenges due to the fine-grained, high-dimensional, and highly variable articulatory features of sign languages. Classic ISLR systems employ task-specific architectures and require expansive annotated datasets, fostering generalization difficulties across signers and environments. By contrast, VLMs have demonstrated emergent competencies in multi-modal reasoning across diverse domains, raising the central question: can these generalist architectures serve as zero-shot ISLR models via prompt engineering?
Experimental Setup
Several SOTA open-source (e.g., Qwen3-VL, LLaVA-NeXT-Video, InternVL3.5, BAGEL-7B-MoT, Nemotron-Nano-VL) and proprietary systems (GPT-5, Gemini-2.5) are evaluated directly on the WLASL300 test split under zero-shot conditions. Input formats range from raw videos to sampled frame sequences, aligning evaluation protocols to each model’s interface. All prompt templates are standardized to isolate the effect of the underlying model architecture and training rather than prompt engineering artifacts.
Three evaluation paradigms are systematically explored:
- Standard closed-set multi-class classification: Output is a single English gloss mapped to a test video.
- Zero-shot open-set expert simulation: The model is prompted as an ASL expert to provide unconstrained, open-set gloss categorization.
- Zero-shot binary classification: The model is asked to decide if a given video matches a target gloss (optionally aided by textual gloss descriptions).
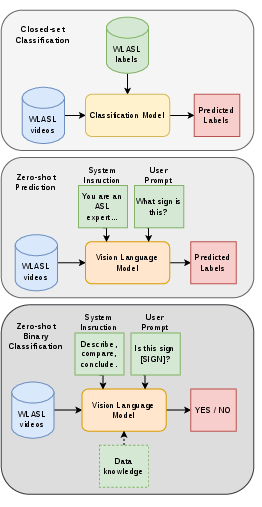
Figure 1: Zero-shot ISLR evaluation paradigms, contrasting closed-set, open-set, and binary classification scenarios for VLMs.
To handle open-ended generative outputs, a synonym-aware scoring is devised; multiple gloss synonyms are assigned to each ground truth label, with both direct and synonym matches considered correct.
Quantitative Results
Across all evaluation settings, open-source VLMs demonstrate markedly limited performance on standard ISLR:
- LLaVA-NeXT-Video and InternVL3.5 yield below 1.5% Top-1 accuracy.
- Qwen3-VL models achieve up to 1.8% synonym-aware Top-1 accuracy in best-case frame rates.
- The best open-source results are orders of magnitude below the specialized DSLNet baseline (89.97% Top-1, closed-set).
- GPT-5 (proprietary) attains 16.3% synonym-aware Top-1, and Gemini-2.5-Pro reaches 25.6%—substantially higher, yet still well below specialized ISLR systems.
Strong order effects are observed when the output gloss set is enumerated in the prompt: models such as Qwen3-VL are highly biased to produce glosses at the start of the alphabetic list, indicating non-trivial prompt sensitivity and positional biases in generative decoding.
In binary matching scenarios—where the output is a yes/no decision to a target gloss or description—performance improves:
- Open-source VLMs (Qwen3-VL-32B) F1 reaches 0.69 in non-skeptical, description-aided prompting.
- Gemini-2.5-Pro achieves an F1 of 0.78 in the no-description setting, signaling internalization of sign-gloss associations.
Adding explicit gloss descriptions mitigates some limitations of open-source models, as their performance rises when semantic context is provided. However, introducing chain-of-thought skeptical reasoning, while improving model cautiousness, depresses F1 due to higher false negatives.
Providing the full candidate gloss list in the prompt increases in-distribution (PID) prediction rates and absolute accuracy (Gemini-2.5-Pro rises to 33.3% Top-1+Synonym). Yet, most open-source models display strong ordering biases under this regime.
Analysis and Interpretation
Public open-source VLMs do not yet provide usable zero-shot ISLR performance under multi-class generative conditions—highlighting both a substantial domain gap between pretraining data and the ASL recognition task and the insufficiency of mere scale (contrasting open with proprietary). However, these architectures already demonstrate partial alignment between visual input and textual semantics, especially evident in binary matching and when the semantic space is tightly constrained.
Proprietary models, plausibly due to greater scale and richer (possibly sign-inclusive) training corpora, show significant but still far-from-useful real-world ISLR recognition. However, due to closed training data, attribution of this improvement to model size or training content remains ambiguous.
The investigation further reveals that prompt construction and explicit task constraints critically shape VLM output distributions—a crucial insight for both model interpretability and practical deployment. The observed ordering bias in open-source models when given a list-style output space indicates that generative VLMs may not be immediately suitable for closed-set recognition tasks, unless further calibrated or adapted.
Implications and Future Directions
Although zero-shot ISLR with VLMs is far from competitive with SOTA supervised ISLR systems, the experiments show that VLMs are beginning to encode compositional hand and facial movement information and can partially leverage gloss descriptions to improve matching. This indicates potential for rapid progress as multimodal pretraining scales and as sign language content is included and curated in future foundation models.
Practically, integrating structured output constraints (matching the output space shape to classic classification), augmenting prompt design with more discriminative task-specific elements, and leveraging light-weight (few-shot or adaptation) fine-tuning protocols represent actionable next steps for boosting VLM performance on fine-grained visual-linguistic tasks such as ISLR. Moreover, the systematic probing protocol introduced in this work will be critical for auditing emergent capabilities in future generalist models and constraining their limitations.
Theoretically, the findings emphasize the non-trivial domain adaptation required when transferring from general visual-language understanding to fine-grained, structured tasks such as sign language. The order bias and output space leakage suggest a need for rethinking generative inference and prompt engineering when applying LLM-based architectures to recognition problems.
Conclusion
This study rigorously assesses the zero-shot ISLR capabilities of contemporary VLMs. It finds that, while modern generalist models exhibit some emergent visual-linguistic alignment and are responsive to structured prompts and output constraints, their practical utility for ISLR remains marginal without domain adaptation. Proprietary models establish a clear performance ceiling but remain opaque regarding data sources and model capacity advantages.
This work establishes a strong baseline for future research in multimodal sign language recognition, motivating continued exploration of model scale, pretraining diversity, prompt engineering, and lightweight adaptation for bridging the gap between language, vision, and highly structured, visually-articulated domains such as sign languages.

