- The paper introduces a benchmark to evaluate VLMs on dynamic sign language form-meaning mapping using NGT sign videos.
- It leverages a dataset of 96 videos annotated for phonological features, iconicity types, and human ratings, establishing both human baselines and zero-/few-shot evaluations.
- Findings reveal that while models capture phonological patterns, they struggle with robust meaning inference and display non-human biases in iconicity ratings.
Evaluating Vision-LLMs on Sign Language Iconicity: The Visual Iconicity Challenge
Introduction and Motivation
The Visual Iconicity Challenge establishes a rigorous benchmark for evaluating vision-LLMs (VLMs) on their ability to map visual form to meaning in signed languages, specifically the Sign Language of the Netherlands (NGT). Iconicity—the resemblance between linguistic form and meaning—is a pervasive property in signed languages, providing a natural testbed for probing the symbol grounding problem in multimodal AI. Unlike static image-text tasks, sign language understanding requires models to process dynamic, temporally extended human motion and extract structured articulatory features. The challenge comprises three diagnostic tasks: phonological form prediction, transparency (inferring meaning from form), and graded iconicity rating, each operationalized with human-annotated ground truth and baselines.

Figure 1: Overview of the Visual Iconicity Challenge: evaluation pipeline of the sign to-cut in NGT for phonological form prediction, transparency, and iconicity tasks.
Dataset and Annotation Protocol
The dataset consists of 96 NGT sign videos (64 iconic, 32 arbitrary), each annotated for five phonological features (handshape, location, path shape, path repetition, handedness), iconicity type (object-based, action-based, combined), and human iconicity ratings (1–7 scale). Annotation reliability is high (inter-annotator agreement κ up to 0.98). Human baselines are established using both deaf signers and hearing sign-naïve participants for all tasks. The dataset design enables fine-grained evaluation of VLMs from sub-lexical perception to analogical reasoning.

Figure 2: Examples of an iconic vs. an arbitrary sign, with their annotated phonological form features. The sign telephone is iconic as its form resembles a telephone’s shape, whereas sugar is arbitrary with no clear visual link to its meaning.
Model Selection and Evaluation Protocol
Thirteen state-of-the-art VLMs are evaluated, including open-source (Qwen2.5-VL, VideoLLaMA2, LLaVA variants, Gemma-3) and proprietary (GPT-4o, GPT-5, Gemini 2.5 Pro) models. Inference is performed in zero-shot and few-shot settings, with standardized prompts for each task. For video input, models are provided with either full clips or frame sequences, depending on model capabilities. Evaluation metrics include multi-class accuracy for phonological features, open-set and multiple-choice accuracy for transparency, and Spearman’s ρ for iconicity rating correlation.
VLMs exhibit clear stratification in phonological feature recognition. Location and handedness are comparatively easy, with several models exceeding 0.70 accuracy (Gemini 2.5 Pro: 0.865 for location, 0.927 for handedness). Handshape and path shape are most challenging; only GPT-5 and Gemini 2.5 Pro exceed 0.50 accuracy. The best open-source model (Qwen2.5-VL-72B) achieves a mean accuracy of 0.598, while human non-experts reach 0.794. Few-shot prompting yields modest gains, primarily for models with lower zero-shot performance.
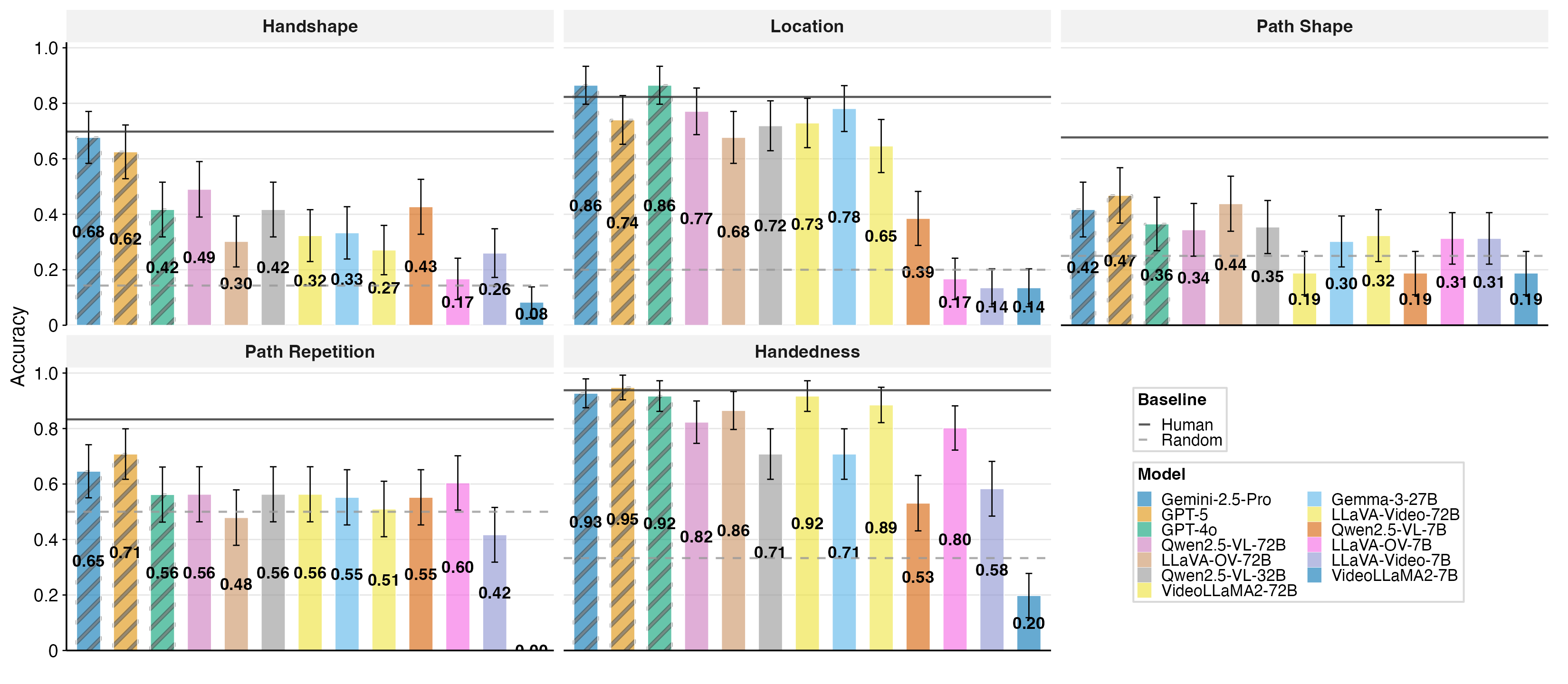
Figure 3: Zero-shot accuracy per form feature. Solid black lines indicate the human baseline, and dashed grey lines refer to random. Bars show VLMs. Across models, location and handedness are comparatively easy; handshape and path shape are hardest; path repetition is intermediate.
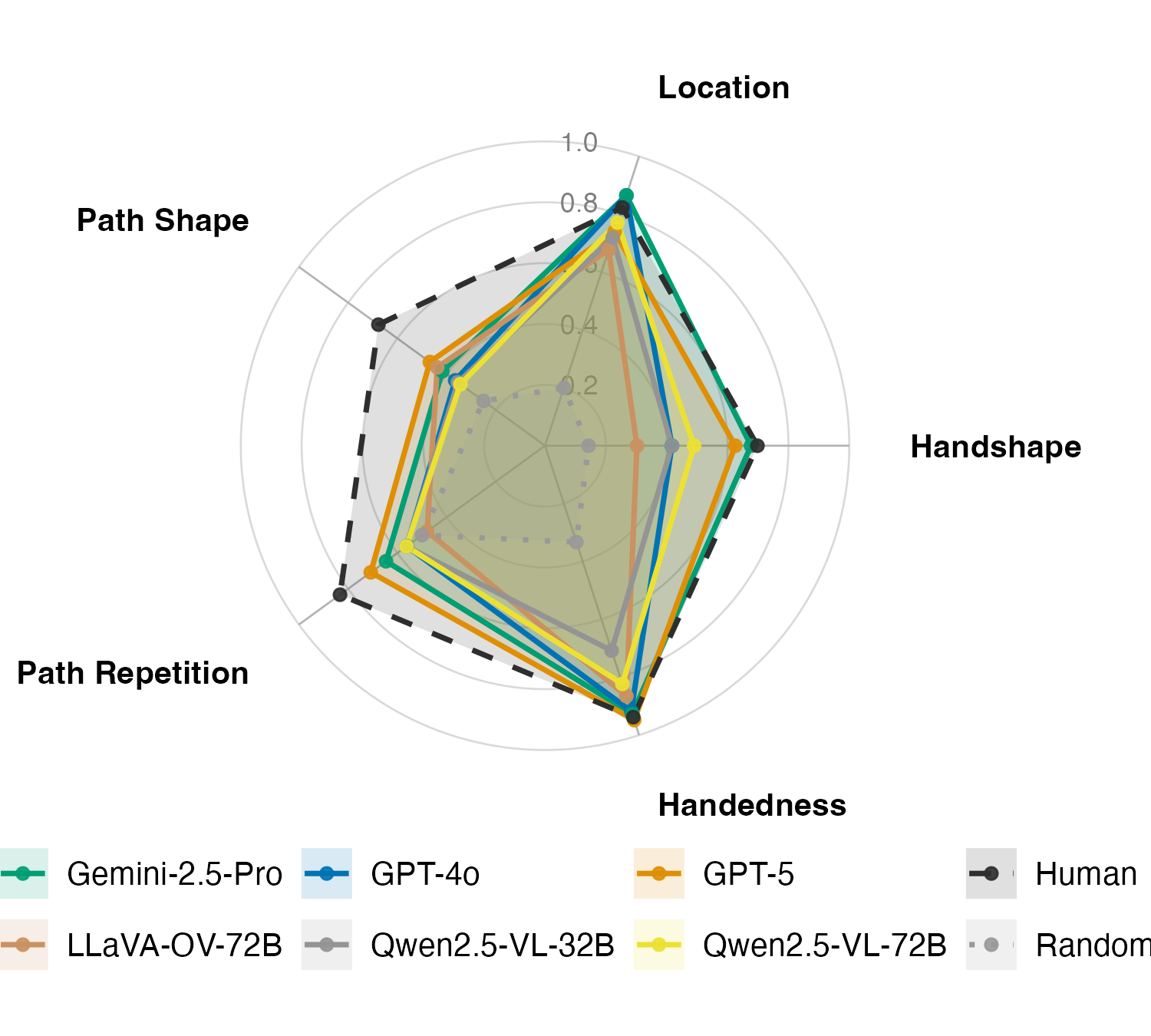
Figure 4: Zero-shot accuracy of the top 6 performing models (3 open, 3 closed) across five phonological features, averaged over 96 signs. Solid colored lines are models; black dashed and grey dotted are the human non-expert and random baselines, respectively.
Open-set gloss identification is highly challenging for all models. The best closed-source models (Gemini 2.5 Pro, GPT-5) achieve only 17–18% accuracy, far below human baselines (deaf signer: 59%, hearing non-experts: 42%). Restricting to 10-choice multiple-choice format improves scores (GPT-5: 43.8%, Gemini 2.5 Pro: 42.7%), but open-source models remain near chance. Correct predictions cluster on visually salient signs (e.g., telephone, to-wring, to-cut, pistol), indicating reliance on surface resemblance. Few-shot prompting does not yield meaningful improvement, suggesting a fundamental limitation in visual-semantic grounding.
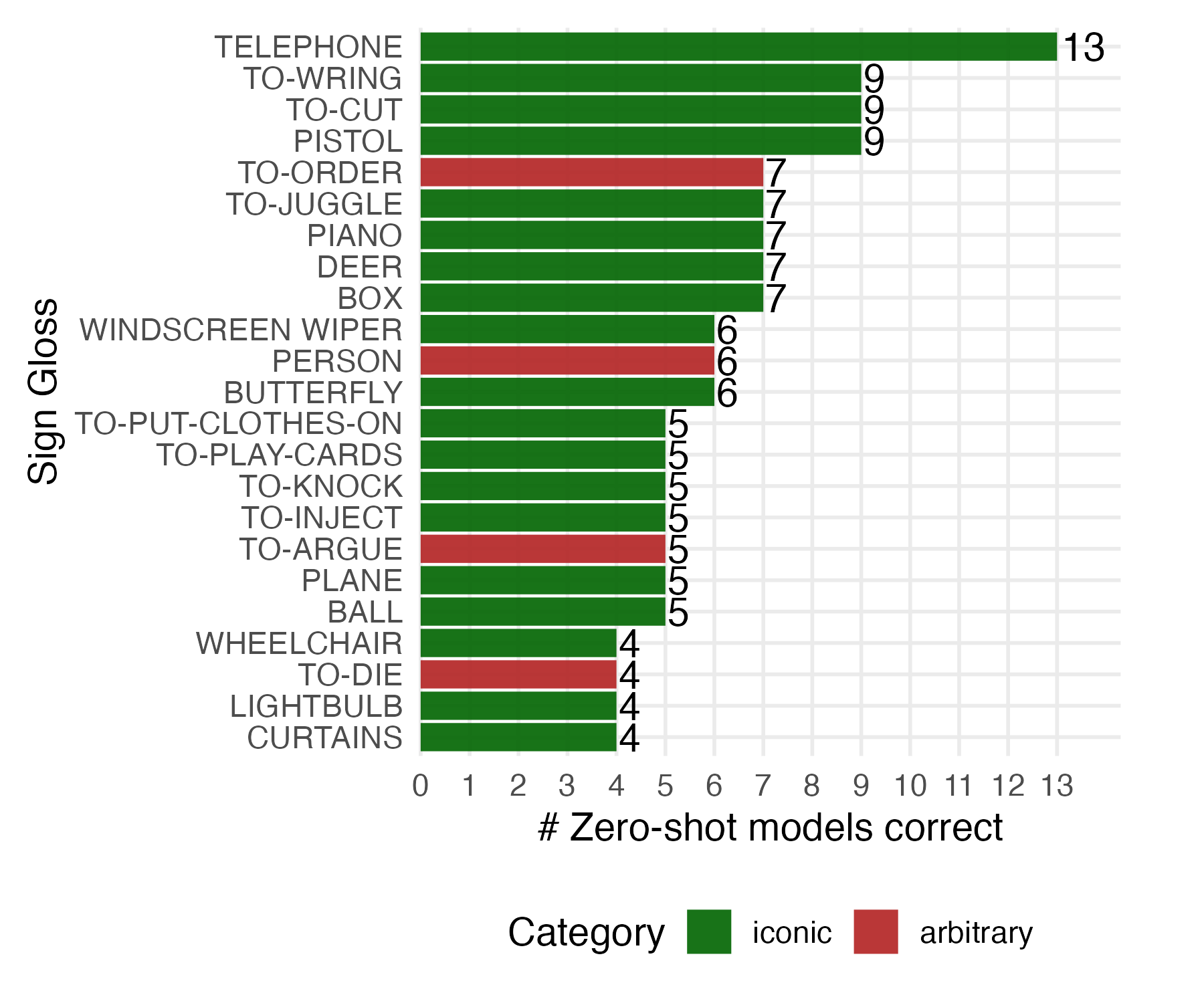
Figure 5: Correctly guessed signs from sign video only (>3 models) in the Transparency_2 Task.
Graded Iconicity Ratings
Several models show moderate positive correlation with human iconicity ratings (GPT-5: ρ=0.607, Gemini 2.5 Pro: ρ=0.577, Qwen2.5-VL-72B: ρ=0.501). However, most models compress the rating scale and systematically over-rate arbitrary signs, reducing contrast. Gemma-3-27B achieves the best categorical separation (Cohen’s d=1.216). Few-shot prompting benefits larger open models, with Qwen2.5-VL-32B improving from ρ=0.344 to ρ=0.510. Notably, models with stronger phonological form prediction also align better with human iconicity judgments, indicating shared sensitivity to visually grounded structure.
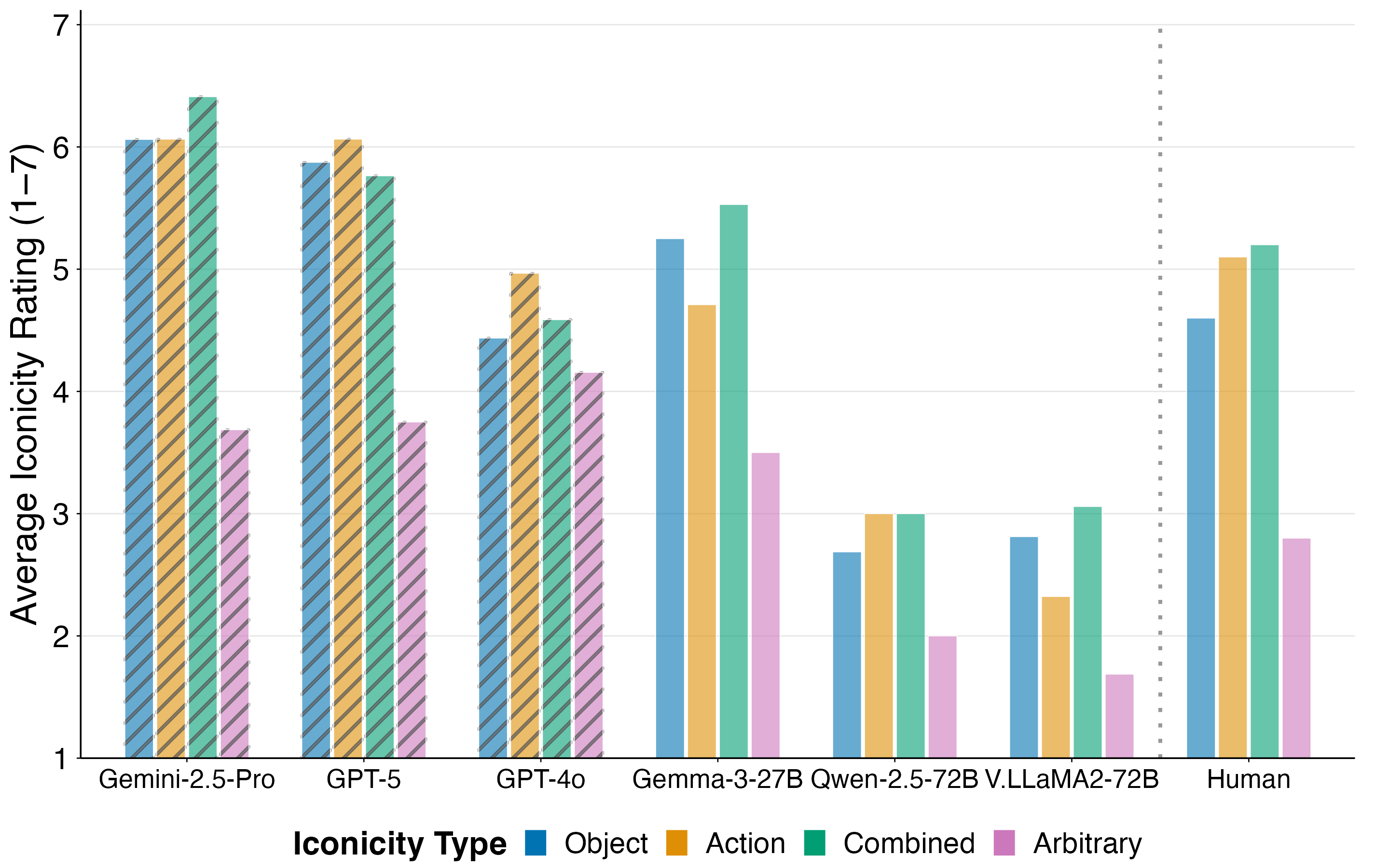
Figure 6: Average iconicity ratings by iconicity type (higher = more iconic).
Iconicity Type Biases
Humans exhibit a robust action bias, rating action-based signs as more iconic than object-based ones. Most open-source models display the reverse pattern, favoring object-based signs, while closed-source models show little preference. This inversion suggests that models rely more on static visual resemblance than dynamic mappings, lacking embodied grounding. The gap between visual pattern recognition and human-like conceptual mapping remains substantial.
Interaction of Iconicity and Phonology
A positive association is observed between phonological form prediction accuracy and iconicity rating alignment. Models with higher phonological accuracy (Gemma-3, GPT-5, Gemini 2.5 Pro) also achieve closer alignment with human iconicity ratings. However, phonological sensitivity alone does not reproduce human embodied biases, as models overvalue object-based resemblance.
(Figure 7)
Figure 7: Overall model landscape by zero-shot phonological form prediction accuracy and iconicity scores. Top-right are best; dot size encodes model size.
Implications and Future Directions
The results demonstrate that current VLMs encode some phonologically relevant structure and can distinguish iconic from arbitrary signs, but they fail to infer lexical meaning and exhibit divergent iconicity-type biases. These findings highlight the need for richer gesture/sign pretraining, dynamic pose encoding, and integration of structured pose information (e.g., MediaPipe, VideoPrism) to improve geometric grounding. Fine-tuning with auto-generated phonological descriptors may further enhance model sensitivity to dynamic human motion. The challenge also motivates the development of embodied learning methods and human-centric evaluation protocols for multimodal AI.
Limitations
The evaluation is constrained by dataset size (96 isolated signs), limited phonological annotation granularity, and lack of sign-specific fine-tuning. The results may not generalize to other sign languages or continuous discourse. Further research should explore fine-tuning, robustness to visual perturbations, stratified analyses by iconicity type, and qualitative error analysis to disentangle perceptual, analogical, and semantic deficits.
Conclusion
The Visual Iconicity Challenge provides a diagnostic framework for probing VLMs on sign language form-meaning mapping. While larger models partially mirror human phonological difficulty patterns and correlate with graded iconicity ratings, they remain far from human performance in meaning inference and exhibit non-human biases in iconicity type. Bridging this gap will require advances in multimodal representation learning, embodied grounding, and sign-specific pretraining. The benchmark sets a foundation for future work in evaluating and improving the visual grounding capabilities of multimodal AI systems.