- The paper presents DDO-RM, a method for LLM preference optimization that reframes binary comparisons as a decision distribution problem guided by explicit reward-model scores.
- The methodology integrates policy predictions with centered rewards using a softmax over perturbed scores, optimized through cross-entropy minimization.
- Empirical results show DDO-RM achieves higher pair accuracy and mean margin than DPO across multiple seeds, despite exhibiting increased variance.
DDO-RM as Reward-Guided Decision Distribution Optimization for LLM Preference Alignment
Algorithmic Foundations
The paper introduces DDO-RM (Decision Distribution Optimization with Reward Model) as an alternative to Direct Preference Optimization (DPO) in the context of aligning LLMs to human preferences via pairwise comparisons. DDO-RM reframes the standard binary chosen-vs-rejected preference as a finite decision problem, constructing a target distribution over all candidate responses using explicit reward-model (RM) scores. The update aggregates both the current policy's probabilistic predictions and reward values, centering rewards to emphasize deviation from the mean under the policy's distribution. The learning step then distills this updated, reward-guided distribution into the model via cross-entropy minimization.
This algorithmic design contrasts with DPO’s strict binary objective, which encodes preference alignment as a one-dimensional comparison update (maximizing preference margin between a chosen and rejected sample). In contrast, DDO-RM’s approach, which supports generalization to arbitrary candidate sets, computes a softmax over perturbed scores (policy plus centered reward), then matches this distribution.
Experimental Protocol and Metrics
Experiments employ EleutherAI/pythia-410m as the base model and HuggingFaceH4/ultrafeedback_binarized as the preference dataset. Both DPO and DDO-RM are benchmarked on the held-out test_prefs split. Only minimal changes to standard RLHF-style tuning pipelines are introduced, focusing on direct reproducibility and transparency. The evaluation centers on:
- Pair accuracy: Fraction where the model correctly assigns higher probability to the preferred response.
- AUC (ROC-AUC): Quantifies overall ranking quality of outputs.
- Mean margin: Measures average logit separation between chosen and rejected responses.
Results are reported over three distinct random seeds to test the consistency of each method.
Empirical Results
DDO-RM achieves strong improvements over DPO on all core metrics. On average across seeds:
- Pair accuracy: Increases from 0.5238 (DPO) to 0.5602 (DDO-RM), indicating more reliable selection of the preferred response.
- AUC: Improves from 0.5315 (DPO) to 0.5382 (DDO-RM).
- Mean margin: Experiences a substantial increase from 0.1377 (DPO) to 0.5353 (DDO-RM)—a notable enhancement in the model’s preference separation.
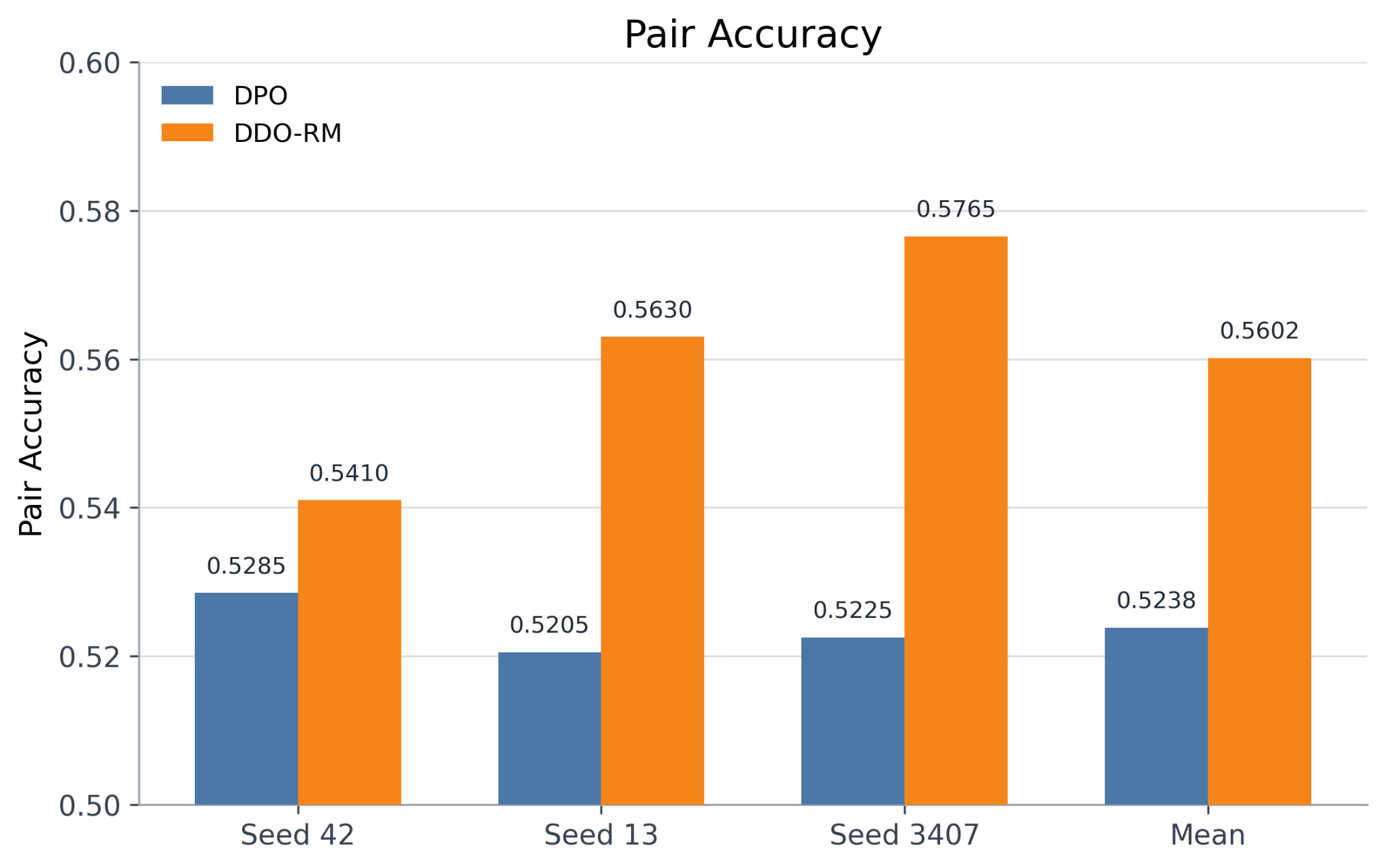
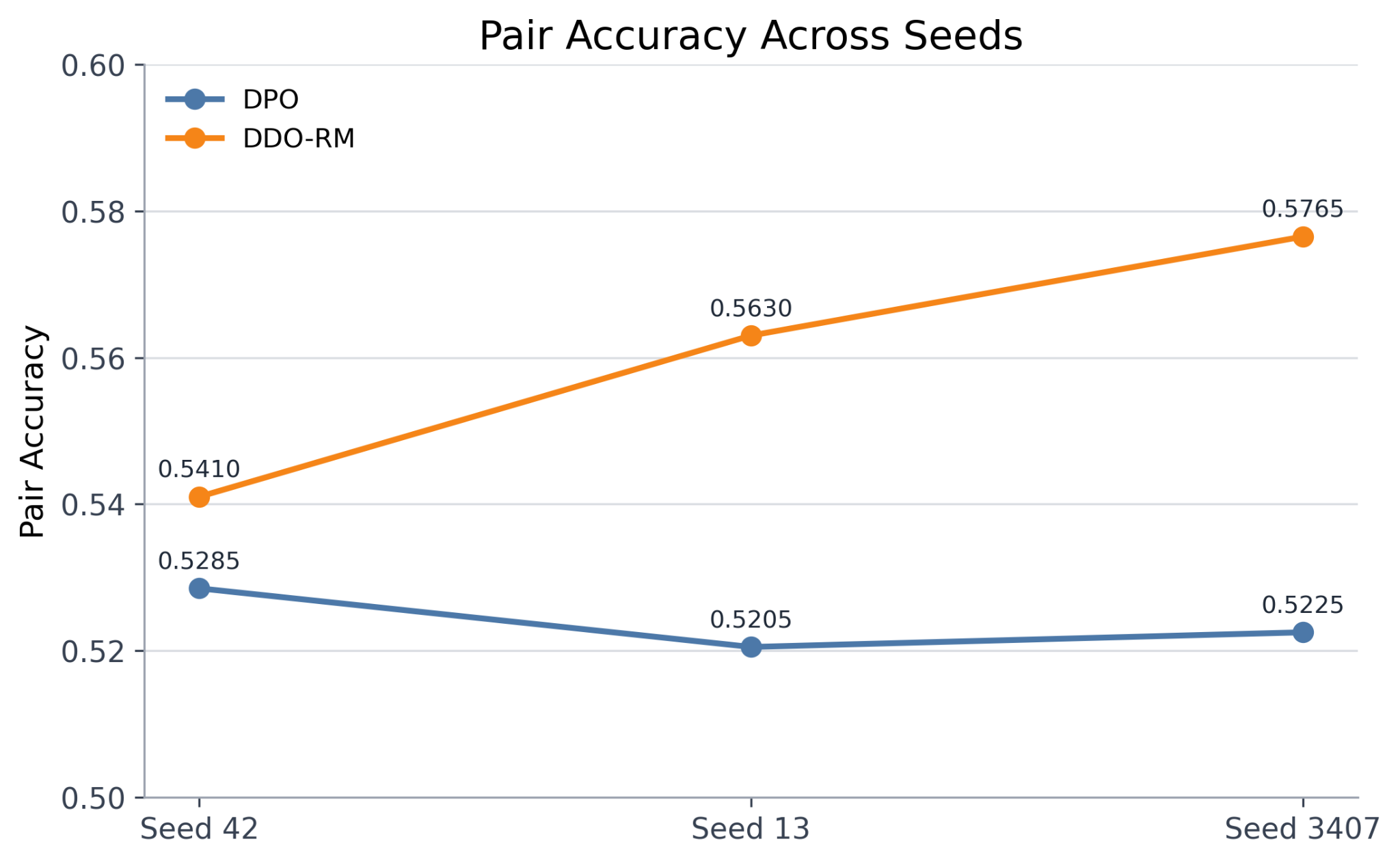
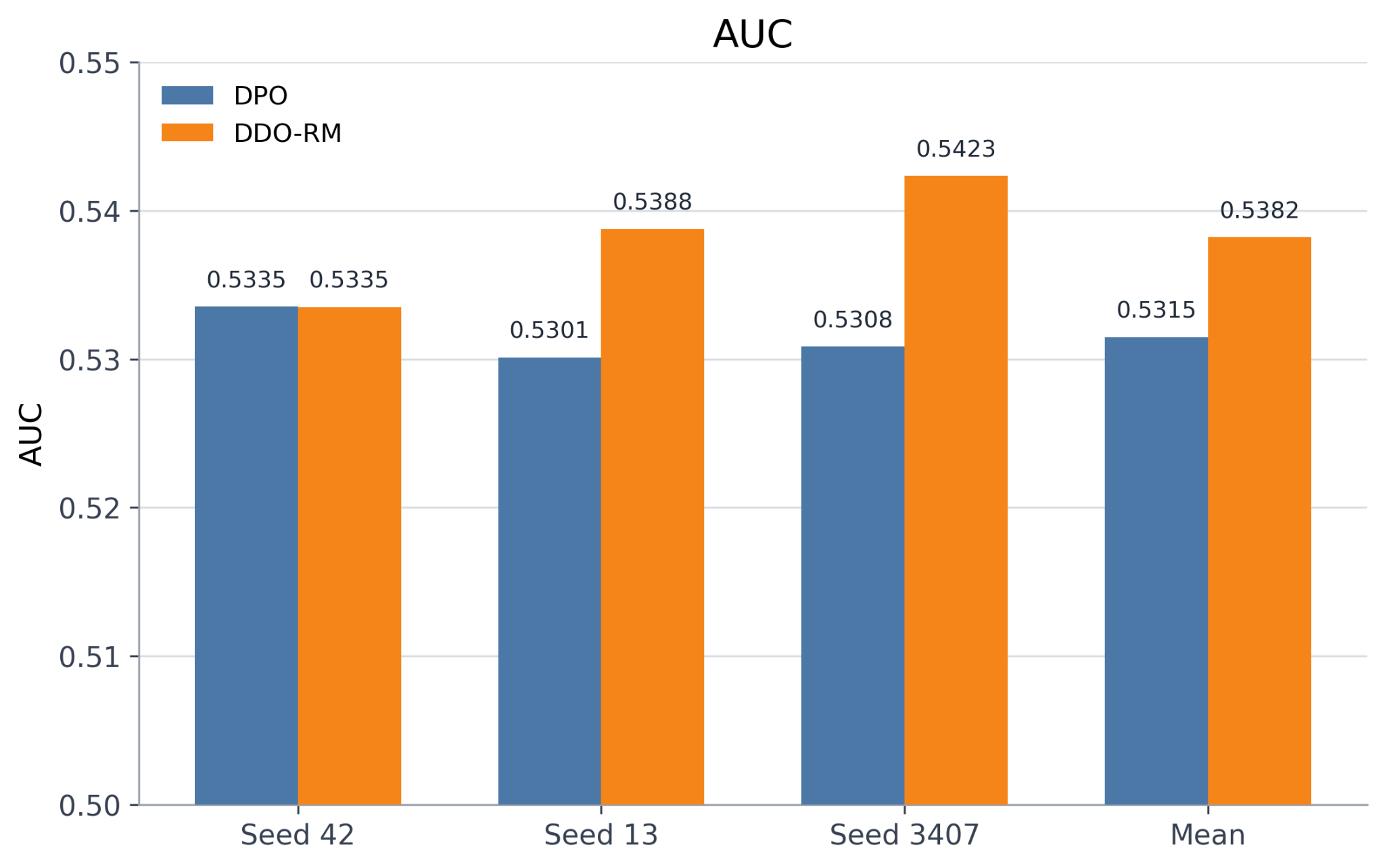
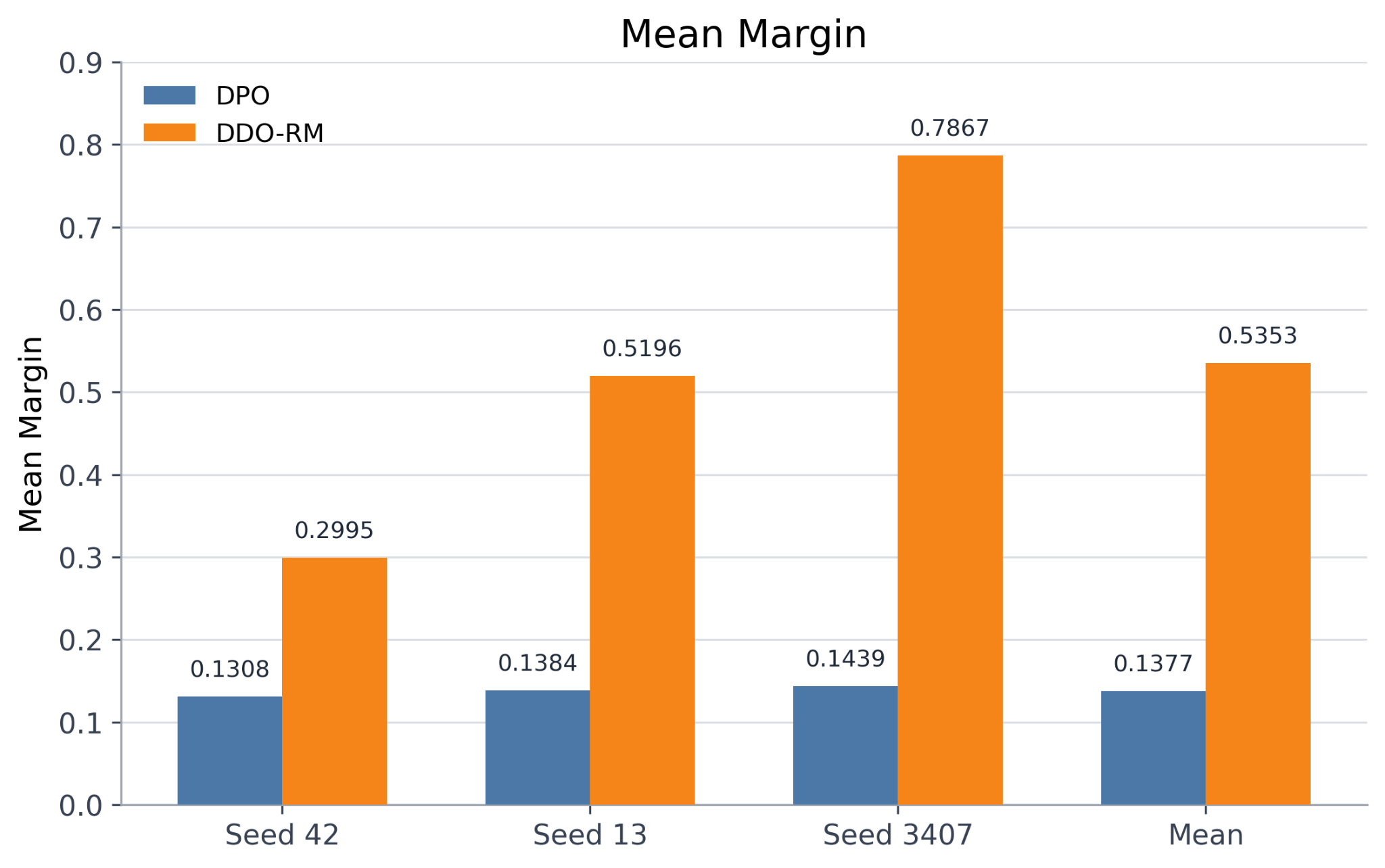
Figure 1: Comparative results between DPO and DDO-RM: pair accuracy by seed and overall mean (top-left), per-seed accuracy trajectories (top-right), AUC (bottom-left), and mean margin (bottom-right).
Across all seeds, DDO-RM consistently outperforms DPO in pair accuracy and mean margin, with a smaller but consistent edge in AUC except for a tie on one seed. However, DDO-RM demonstrates greater cross-seed variance, especially in the mean margin metric. This result suggests that while the method is empirically promising, further investigation into the variance and broader generalizability is warranted.
Theoretical and Practical Implications
The adoption of a reward-guided distributional update (as instantiated in DDO-RM) introduces several theoretical advantages. By optimizing a soft target that is reward-centered and policy-aware, DDO-RM is inherently suited to extend beyond binary supervision to listwise ranking and reranking regimes where the optimization objective must consider inter-candidate relationships. The use of per-candidate reward signals allows the method to capture finer-grained distinctions in RM output, potentially leading to richer alignment than binary-only formulations can capture.
Practically, the approach retains the benefits of stable, supervised (non-RL) objectives, facilitating easier implementation, tuning, and integration into existing LLM preference-optimization pipelines. The method’s current instantiation in a binary setting nonetheless foreshadows its applicability to broader and more granular candidate sets.
Despite these advantages, DDO-RM’s dependence on reward-model quality remains a critical limitation: inaccuracies or miscalibrations in RM output may propagate through the preference-distillation process more strongly than in binary-only setups. Further, sensitivity to initialization and stochasticity (as indicated by higher cross-seed variance) needs to be addressed for robust large-scale deployment.
Limitations and Future Directions
The current study incorporates several constraints:
- Only one model architecture and family is used.
- Evaluation is limited to a single dataset and split.
- Assessment is confined to pairwise preferences; listwise or more complex ranking is untested.
- No formal statistical significance testing or uncertainty quantification is performed.
These limitations restrict the generality of the empirical findings. Key directions for future work include:
- Scaling to listwise candidate sets and evaluating ranking metrics such as NDCG.
- Broadening to diverse base models and alignment tasks.
- Longitudinal analysis of variance and ablation of RM properties.
- Exploring the effect of reward-model misspecification.
Conclusion
This work reframes pairwise preference optimization in LLM alignment as a decision distribution problem, introducing DDO-RM as a reward-guided, policy-informed instantiation that outperforms the direct pairwise DPO baseline across multiple metrics under controlled conditions. Notably, DDO-RM yields higher pairwise accuracy and more decisively separates preferred from dispreferred responses, indicating a competitive alternative approach for preference-based alignment. While the scope is intentionally minimal, these findings motivate broader evaluation of reward-guided distributional objectives, especially in more complex ranking and selection contexts central to next-generation LLM preference optimization.

