- The paper's main contribution is the Record-Remix-Replay framework, which integrates LLM-powered evolutionary search with Bayesian optimization for GPU kernel tuning.
- It employs a two-level hierarchical search, combining source-level mutations and parameter-level adjustments to efficiently navigate a vast, non-separable optimization space.
- Empirical results demonstrate up to 10x faster candidate evaluations and a 28.4% reduction in aggregate compute time on production-scale applications.
Hierarchical GPU Kernel Optimization via Record-Remix-Replay
Introduction and Motivation
Record-Remix-Replay (R) introduces a hierarchical optimization framework that addresses the challenges in GPU kernel optimization across algorithmic, implementation, compiler, and launch parameter dimensions. Traditional auto-tuners and domain-specific optimization frameworks are effective within constrained subspaces but lack the capability for end-to-end, cross-layer optimization required for modern scientific and AI workflows. The innate interdependence of choices across the implementation stack leads to a search space that is non-separable and combinatorially large, rendering single-layer approaches suboptimal. Furthermore, candidate evaluation in large-scale GPU settings is prohibitively expensive due to extended runtime and measurement noise. R adopts record-replay to decouple candidate evaluation from the full application context, leveraging persistent replay infrastructure and hierarchical search to realize high-throughput tuning across the entire vertical stack.
Methodology: The Record-Remix-Replay Framework
The R framework operates via a two-level optimization: LLM-powered evolutionary search at the source level and Bayesian optimization (BO) over compiler and launch configuration at the lower level. The outer loop uses MAP-Elites to maintain population diversity and promote exploration among kernel variants; this is essential for escaping local minima endemic to structured parameter spaces. The inner loop employs record-replay to evaluate each kernel candidate on isolated GPU kernel invocations, drastically reducing feedback latency and enabling aggressive BO over compiler pass orderings and runtime parameters.
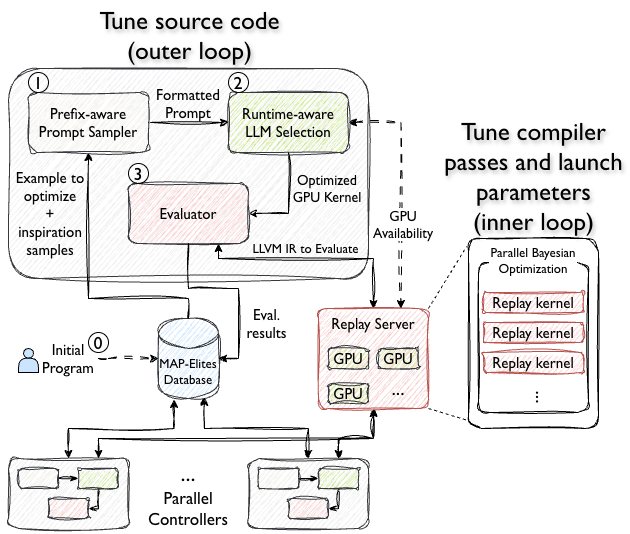
Figure 1: High-level view: LLM selections generate new source candidates, which the record-replay server then evaluates with BO across compiler and launch parameters.
R's optimizations include a persistent replay server that minimizes the cost of initializing and recording GPU state, prefix-aware prompt design for efficient LLM generation leveraging caching, and a runtime-aware scheduling policy for LLM selection to maximize throughput without incurring excessive staleness. The latter is crucial for maintaining convergence rates in parallel evolutionary settings.
Key System and Algorithmic Contributions
Hierarchical Search & Integration of LLMs
The combination of MAP-Elites-guided LLM mutation and BO over compiler/launch parameters enables R to traverse both unstructured (source-level) and structured (parameter-level) regions of the search space. Prior works—e.g. CERE, Kernel RR—either restrict mutation to structured parameters or cannot amortize evaluation costs sufficiently to scale evolutionary strategies with LLMs. R's record-replay allows candidate evaluation at the kernel granularity, breaking the traditional bottleneck of application-level executions in LLM-powered evolutionary schemes.
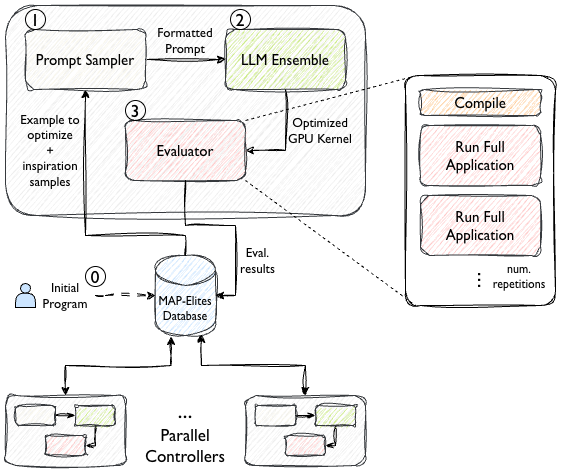
Figure 2: Overview of MAP-Elites evolution: LLM-based candidates are generated, evaluated, and maintained in a feature-divided population database.
Replay Infrastructure
R extends GPU kernel record-replay with support for arbitrary CUDA/HIP kernels, persistent memory state for rapid repeated evaluation, in-memory IR transformations via integration with Proteus, and fine-grained correctness specifications adjustable between bitwise and numerically-relaxed constraints. This underpins both the speed and the robustness required in the inner evaluation loop, directly supporting kernel hot-spot optimization and enabling offline tuning with seamless deployment.
Throughput and Scaling Optimizations
Prefix-cache aware prompt ordering and inference scheduling, which adapts to model latency estimates and device availability, increase the overall utilization of compute resources and reduce effective generation cost. These innovations shift the bottleneck from evaluation to inference, a requirement for enabling the high candidate turnover needed in evolutionary frameworks. The impact is substantiated by improved GPU utilization and evaluation/h in empirical settings.
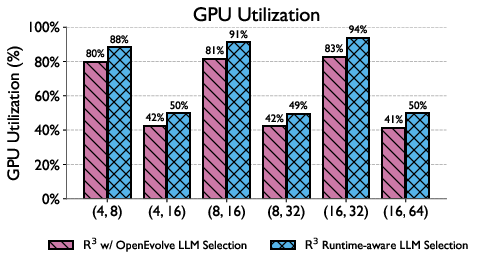
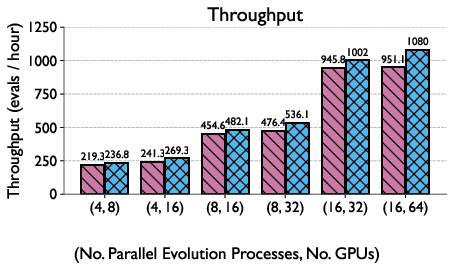
Figure 3: Runtime-aware LLM selection allows higher throughput and utilization versus traditional random selection, critical for scaling evolutionary search with limited island counts.
Experimental Results
R is systematically benchmarked on four production-scale scientific applications—Lulesh, miniFE, S3D, and miniWeather—using both AMD MI300A and NVIDIA H100 GPU environments. Results are compared against baselines: record-replay plus BO (without source mutation) and OpenEvolve (AlphaEvolve-like LLM-based evolutionary search without advanced replay/scaling). All approaches are parallelized across multiple kernels and test configurations are matched for fair GPU allocation.
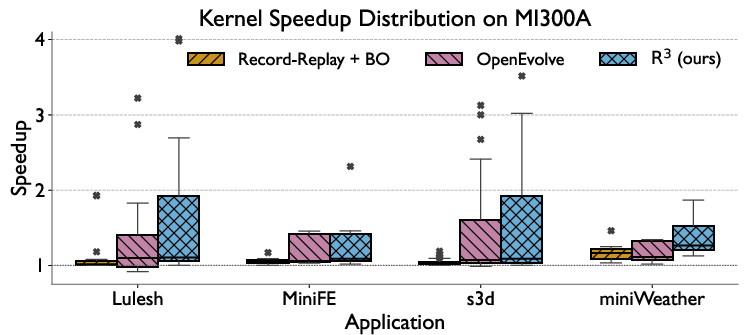
Figure 4: On MI300A, R achieves superior median and maximum kernel speedups compared to both BO-only and OpenEvolve approaches, emphasizing the benefit of hierarchical search.
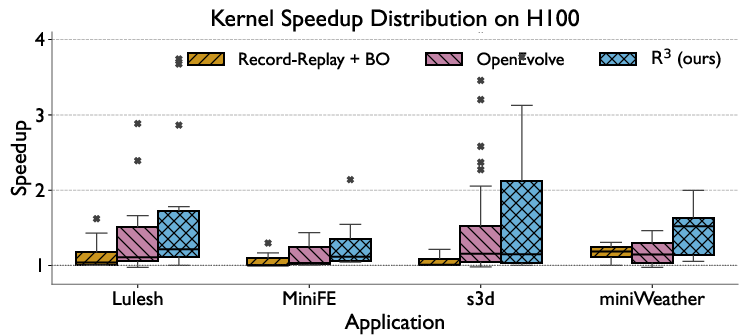
Figure 5: Comparable trends are observed on the H100, further validating the cross-architecture benefit of R.
Strong empirical findings include:
- Kernel-level median and max speedups are universally higher with R over baselines.
- Application-level compute time reduction reaches up to 28.4% in complex, multi-kernel QUDA workloads (see case study).
- Evaluation time per candidate is reduced by up to 10× compared to standard evolutionary search, enabling more aggressive exploration.
- End-to-end optimization time: R achieves both better speedup and faster time-to-solution versus OpenEvolve, the latter by over 8 hours on some benchmarks (MiniFE).
- Per-kernel latency: Speed improvement is consistent for all tuned kernels as visualized for miniWeather.
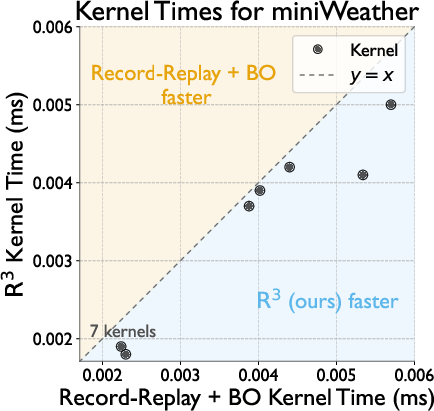
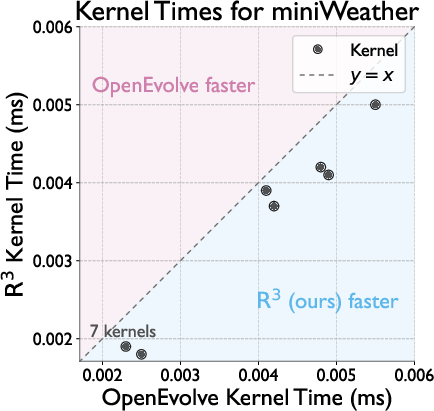
Figure 6: Scatterplot demonstrates that R's optimized kernels consistently outperform alternatives across the full kernel set of miniWeather.
Case Study: Lattice QCD Application (QUDA)
The application of R to QUDA, a production LQCD codebase, demonstrates the practical viability of the approach in an HPC context notorious for complexity and long compilation times. R discovers non-trivial source-level and parameter-level optimizations for the CoarseDslash kernel, including code motion, field reuse, and constant propagation, enabled by its hierarchical search design. This results in a 1.33x kernel-level speedup and a 28.4% reduction in aggregate compute time across 64 MI300A GPUs. Projected runtimes indicate that OpenEvolve would require on the order of 42 hours for comparable optimization, making R the only practical approach among evaluated frameworks.
Implications, Limitations, and Future Directions
Practically, R enables production GPU workloads to be tuned end-to-end without recourse to laborious, expert-driven interventions across compiler, implementation, and launch layers. The ability to efficiently integrate source-level LLM evolution with parameter search strongly amplifies the quality of discovered optimizations, especially in heterogeneous multi-kernel environments. Theoretically, the work demonstrates that record-replay coupled with hierarchical search can effectively decompose and tractably address non-separable search spaces in system optimization.
Potential future directions include (a) automatic determination of relaxation predicates for correctness in non-bitwise stable kernels, (b) extension to additional programming models and multi-GPU collectives, and (c) generalization of replay-enabled LLM-driven optimization to non-GPU accelerator domains.
Conclusion
Record-Remix-Replay constitutes a significant advancement in hierarchical GPU kernel optimization by closing the performance, scaling, and usability gaps inherent in prior art. The framework's architectural and algorithmic choices yield strong, reproducible empirical performance—higher speedup, reduced time-to-solution, and lower evaluation cost—across diverse scientific workloads. Its release as part of the Mneme framework positions it as a practical tool for both research and applied autotuning in heterogeneous HPC environments.

