- The paper introduces LaDA-Band, a zero-shot vocal-to-accompaniment framework using discrete masked diffusion to bypass autoregressive limitations.
- It employs a dual-track prefix-conditioning architecture and auxiliary replaced token detection to ensure robust temporal alignment and acoustic fidelity.
- LaDA-Band outperforms baselines with state-of-the-art FAD, Onset F1, and CLaMP metrics, establishing its scalability and reliability in full-song arrangement.
Language Diffusion Models for Zero-Shot Vocal-to-Accompaniment Generation: An Analysis of LaDA-Band
Introduction
Vocal-to-accompaniment (V2A) generation is a demanding generative task, requiring the synthesis of a fully arranged, temporally aligned instrumental backing from dry vocal input. The essential operational trilemma in V2A—acoustic authenticity, global coherence, and dynamic orchestration—remains unsolved by prior open-source methods due to architectural and representational constraints. "LaDA-Band: Language Diffusion Models for Vocal-to-Accompaniment Generation" (2604.11052) proposes a framework that bypasses the pitfall trade-offs of discrete autoregressive and continuous-latent paradigms by leveraging Discrete Masked Diffusion on audio codec tokens, backed by a dual-track prefix-conditioning architecture and auxiliary objectives. The authors assert that LaDA-Band achieves true zero-shot, end-to-end full-song arrangement at scale without reference audio.
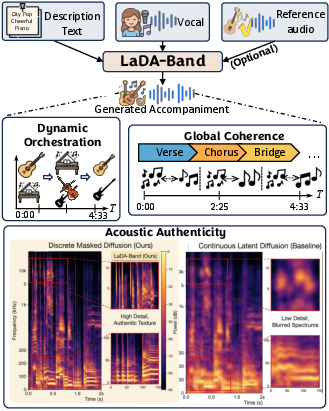
Figure 1: LaDA-Band enables true zero-shot generation (i.e., generating full arrangements from only vocals and text, without needing reference audio).
LaDA-Band fundamentally redefines the V2A task as a discrete, non-autoregressive denoising problem over jointly tokenized vocal and accompaniment streams. The framework operates in three key dimensions:
- Discrete Masked Diffusion is introduced as a global denoising process over MuCodec tokens, decoupled from unidirectional AR constraints, enabling bidirectional, context-aware iterative generation. This allows long-range structural reasoning without the compounding token-level error accumulation endemic to AR decoders or the fidelity degradation from continuous latent collapse.
- Dual-Track Prefix-Conditioned Representation merges the vocal and accompaniment inputs along the feature axis, maintaining temporal integrity at the frame level while incorporating weak global conditioning via text/audio-derived prefix vectors. This structure encourages robust arrangement evolution while preserving high granularity vocal alignment.
- Auxiliary Replaced Token Detection (RTD) Objective addresses weakly anchored segments (intros/interludes) through dense contextual plausibility supervision, supplementing exact sequence reconstruction and stabilizing instrumental texture in the absence of vocal anchors.
A staged curriculum is employed, scaled from local temporal context (Stage 1) to full-song long-form optimization (Stage 2), with explicit data filtering and augmentation designed to maximize genre and arrangement generalization.
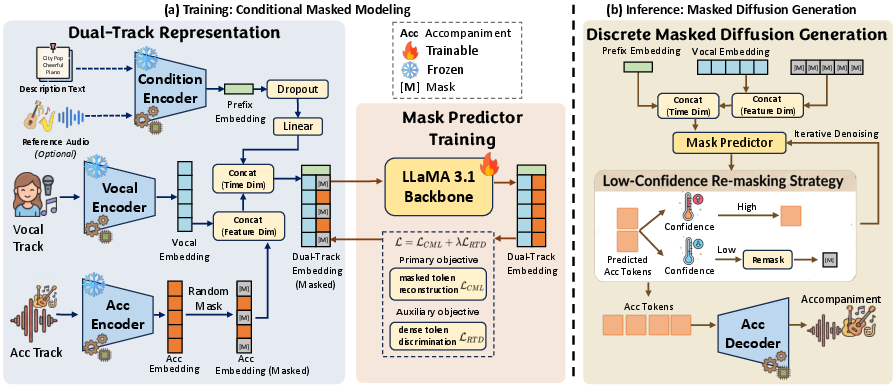
Figure 2: Overview of the LaDA-Band framework, illustrating (a) the training of LLaMA backbone on dual-track representations, and (b) the inference of full-song accompaniments via a masked diffusion process.
Experimental Analysis
LaDA-Band is benchmarked against both discrete AR (SongEditor) and continuous-latent baselines (AnyAccomp, MuseControlLite, ACE-Step, SongEcho). Notably, SongEditor is OOM on full-song input, underscoring NAR viability for real deployment. On the Suno70k benchmark, LaDA-Band delivers state-of-the-art FAD (14.8 vs. 45.9 for SongEcho), Onset F1 (82.0 vs. 67.0), and CLaMP (22.7 vs. 10.2) metrics, reflecting dominance across timbral fidelity, micro-temporal precision, and dynamic alignment.
Subjective MOS evaluations corroborate objective gains, with LaDA-Band achieving overall scores of 3.40 (±0.15) versus 2.91 for ACE-Step. Notably, failure cases concentrate in jazz/funk, genres demanding complex, non-formulaic orchestration.
Zero-Shot Robustness
A salient property is LaDA-Band’s resilience to minimal conditioning. Under text-only zero-shot settings, core metrics (e.g., Onset F1, FAD) remain stable, and in real-world IHP data evaluation, it matches or surpasses fully conditioned baselines, substantiating its claim of reference-free generalization.
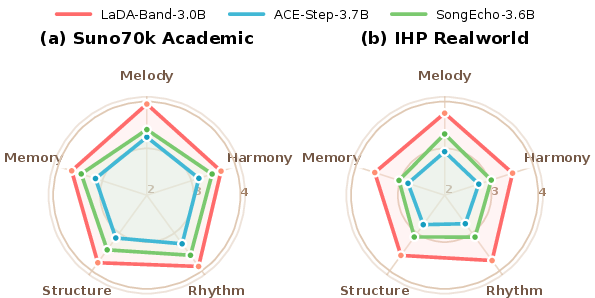
Figure 3: Comparison of LaDA-Band and continuous-latent baselines on the five SongEval dimensions under the restricted Zero-shot (Text-Only) conditioning scenario.
Architecture Ablations
Ablation studies verify the contribution of each architectural element:
Systemic Implications and Theoretical Significance
This work establishes the effectiveness of discrete diffusion in large-scale sequence alignment settings beyond text and vision, validating that iterative denoising over discrete audio representations unifies global temporal coordination with local acoustic resolution. The dual-track strategy generalizes to any highly correlated input-output time series pair, enabling future extensions in multimodal music synthesis, editing, and beyond.
The fully parallel, non-autoregressive nature of LaDA-Band paves the way for both inference efficiency and stable scaling, circumventing OOM and autoregressive compute bottlenecks. This property could catalyze the adoption of full-length, real-time, reference-free arrangement generation in commercial music AI workflows.
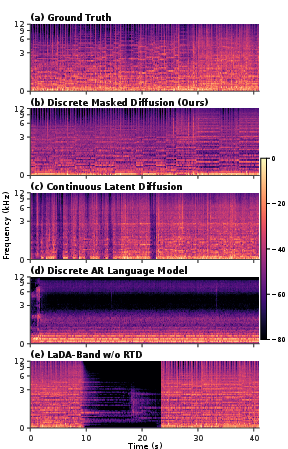
Figure 5: General-purpose cover generation is not directly suitable for V2A accompaniment generation, as timing and structure drift in unconstrained systems highlight task-specific requirements for alignment.
Practical Perspectives and Limitations
LaDA-Band’s reliance on high-quality source separation and codec pipelines renders it sensitive to upstream errors. Instrument-level editability is not directly addressed; fine-grained control at arrangement or stylistic axes is limited by the weak prefix conditioning paradigm. Performance degradation is observed for genres where standard temporal/harmonic alignment is not the idiomatic norm (e.g., jazz).
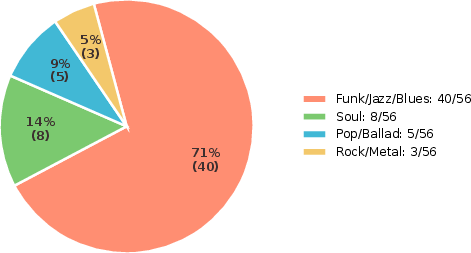
Figure 6: Style distribution of 56 negative cases on Suno70k with mean MOS below 3.0, with funk/jazz/blues accounting for the majority.
Future Directions
Enhancements may manifest via multimodal fine-grained conditioning (e.g., explicit instrument tags, arrangement sketches), improved separation codecs, or compositional guidance architectures (cross-attention, diffusion-editing). Data-centric improvements targeting low-resource or complex genres are essential for completeness.
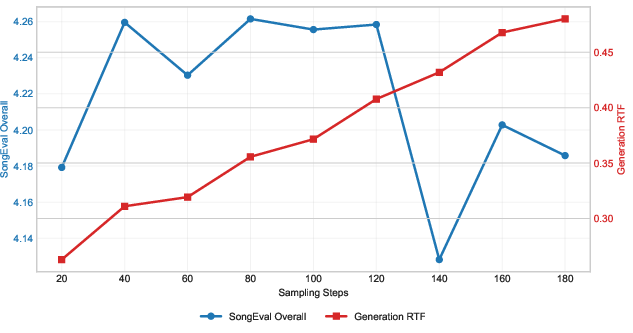
Figure 7: Effect of sampling steps on generation RTF and SongEval under the cosine schedule, indicating optimal trade-off at moderate denoising iterations.
Conclusion
The LaDA-Band framework demonstrates that discrete, non-autoregressive diffusion can resolve the central V2A trilemma, achieving robust, reference-free, full-song arrangement with significant margins over state-of-the-art baselines. Its integration of dual-track representations, auxiliary discrimination, and sequential curriculum training is empirically validated by strong results in both objective and subjective assessments, while remaining extensible toward broader AI-powered music generation domains.