- The paper introduces a three-stage hierarchical autoregressive model that directly generates instrumental accompaniments from isolated vocal inputs.
- It employs a dual-rate tokenization pipeline with HuBERT and EnCodec to align semantic and acoustic features effectively.
- Empirical results show competitive performance with a low Fréchet Audio Distance, demonstrating its efficiency and scalability.
HAFM: Hierarchical Autoregressive Foundation Model for Music Accompaniment Generation
HAFM introduces a hierarchical autoregressive methodology for generating instrumental accompaniments conditioned on isolated singing vocals. Unlike previous symbolic or monolithic encoder-decoder-based approaches, HAFM circumvents the intermediate transcription bottleneck and directly models high-fidelity, temporally aligned musical accompaniments in the audio domain. The core innovations include a dual-rate discrete tokenization pipeline, a three-stage hierarchical decoder-only architecture, and the integration of recent Transformer advancements, all targeted toward robust temporal and musical conditioning from vocal inputs to instrumentals. The system directly addresses temporal misalignment, cross-modal translation, and generative coherence for vocal-driven music generation.
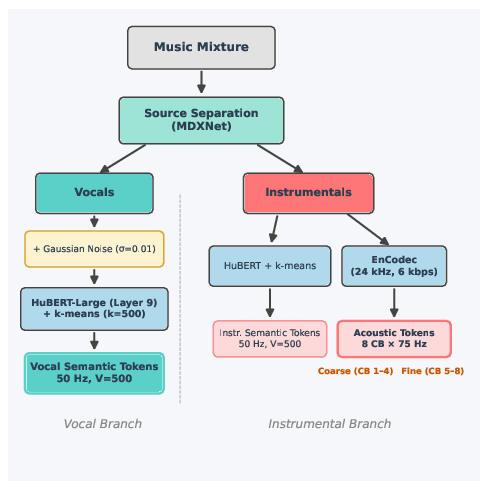
Figure 1: The data preprocessing pipeline leverages MDXNet source separation, HuBERT-based semantic tokenization for vocals (50 Hz), and a dual semantic/acoustic tokenization (via HuBERT + EnCodec at 75 Hz) for instrumentals, with augmentation and codebook partitioning.
Dual-Rate Codec Tokenization Pipeline
Central to HAFM is the dual-tokenization strategy: vocals are encoded as semantic tokens using HuBERT-Large (extracted at layer 9, k-means quantized, 50 Hz), whereas instrumentals are tokenized via EnCodec (8 codebooks, 75 Hz, 6.0 kbps bandwidth), which are subdivided into 4 coarse and 4 fine codebooks. This enables rate-independent yet time-aligned modeling. Semantic tokens facilitate high-level correspondence, while fine-grained acoustic tokens preserve timbral and temporal subtleties. Gaussian noise augmentation (σ = 0.01) is optionally applied to the vocals prior to encoding, which ensures generalization robustness and simulates realistic source separation artifacts observed in practical scenarios.
Three-Stage Hierarchical Autoregressive Model
The backbone of HAFM comprises three independent yet sequentially executed decoder-only Transformer stages:
- Stage 1 (Semantic): Autoregressively predicts instrumental semantic tokens conditioned solely on vocal semantic tokens (both at 50 Hz, V=500). This stage establishes high-level musical structure transformation.
- Stage 2 (Coarse Acoustic): Predicts interleaved coarse EnCodec RVQ codes (4 codebooks at 75 Hz), conditioned on both sets of semantic tokens. Multi-source segment embeddings and per-quantizer identities are encoded to resolve codebook and modality alignment.
- Stage 3 (Fine Acoustic): Refines coarse sequences by predicting the remaining four fine codebook tokens (75 Hz), conditioned exclusively on the generated coarse codes.
Each stage is trained independently with teacher forcing and classifier-free guidance (CFG) dropout (pdrop=0.1), facilitating both conditioned and unconditional training regimes as required by CFG-driven inference.
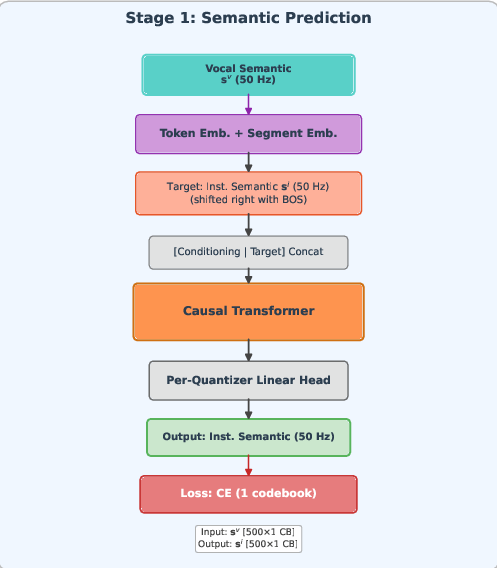
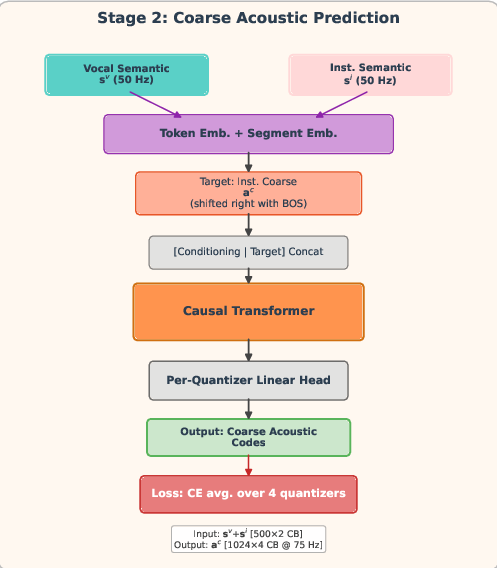
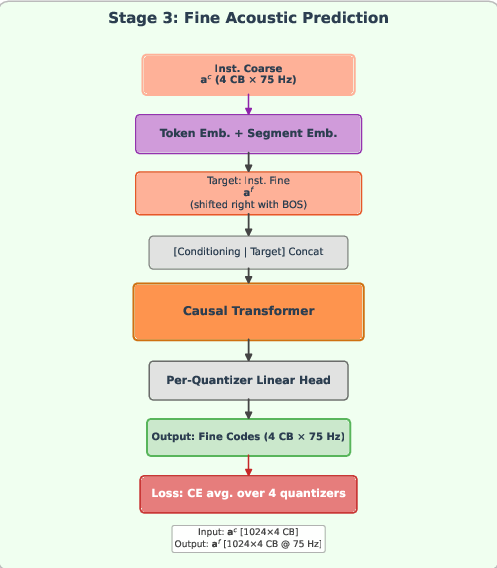
Figure 2: HAFM's three-stage hierarchical autoregressive training pipeline, illustrating the independent conditioning and prediction mechanisms in each causal Transformer.
Inference Pipeline
At inference, a vocal input is sequenced through the HuBERT-Large encoder, Stage 1 for instrumental semantics, Stage 2 for coarse acoustic codes, then Stage 3 for fine acoustic refinement. The resulting discrete EnCodec tokens are synthesized via the EnCodec decoder to generate the final instrumental waveform, which can be mixed directly with the original vocals, establishing a coherent, musically aligned result.
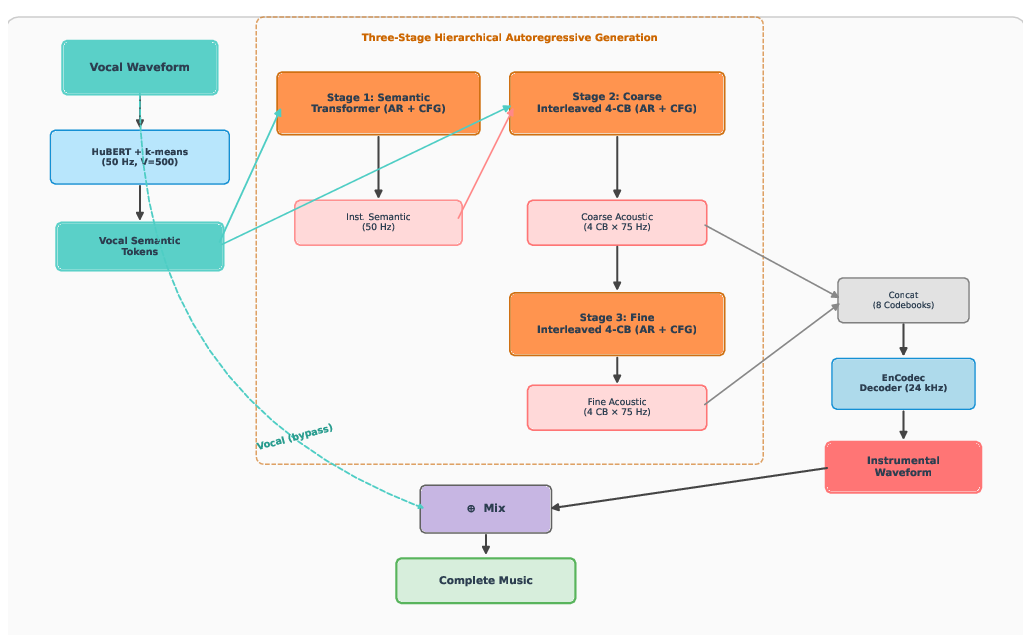
Figure 3: The autoregressive inference process; HuBERT extracts semantic tokens, hierarchical Transformers generate instrumental codes, and EnCodec reconstructs the waveform for seamless vocal-instrumental mixing.
All stages employ a shared, modernized causal Transformer with 12 layers, dmodel=512, 8 heads. Architectural refinements include:
- RMSNorm: Both in pre-attention and pre-FFN normalization, promoting robust, depth-scalable learning dynamics.
- QK-Norm: Independent normalization of attention queries and keys, suppressing attention logit instability and improving training stability on long sequences.
- GEGLU Activations: Replacing ReLU with Gated GELU in FFN improves parameter efficiency and gradient flow.
- T5-style Relative Position Bias: Causal, log-bucketed bias encoding substitutes for sinusoidal or learned absolute embeddings, preserving sequence generalization.
- Per-Quantizer Linear Heads: Modular output design enables efficient handling of multi-codebook token predictions, critical in the coarse/fine EnCodec stages.
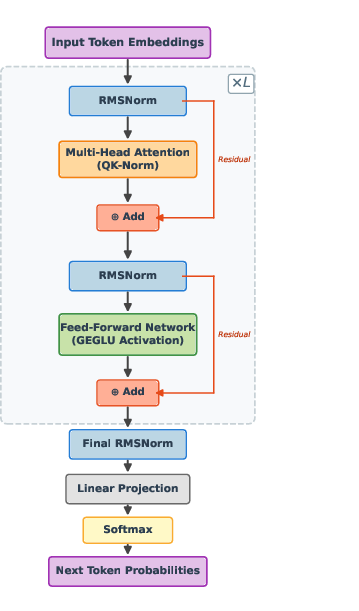
Figure 4: The Transformer block design utilizes pre-norm RMSNorm, QK-Norm, GEGLU FFN layers, and T5-inspired relative positional biases to optimize training stability and sequence modeling.
Dataset, Training, and Evaluation
HAFM is trained on source-separated (MDXNet) vocal-instrumental pairs extracted from FMA-Large and evaluated on MUSDB18. Training employs standard AdamW optimization with extensive hyperparameter tuning for stage batch, clip, and sequence length. Data cleaning involves energetic and SNR-based filtering to maintain balanced, musically meaningful accompaniment material.
The principal evaluation metric is Fréchet Audio Distance (FAD), utilizing VGGish embedding space to assess audio fidelity and distributional closeness between generated and ground-truth instrumentals. HAFM demonstrates a test-set FAD of 2.08 (isolated vocal input), competitive with or surpassing parameter-heavy contemporaries such as SingSong-XL, but with significantly fewer parameters (250M vs 3B).
Empirical results show HAFM's FAD performance on isolated vocals closely matches or outperforms prior autoregressive and retrieval-based systems. Notably, it achieves superior generalization to clean vocal inputs compared to retrieval baselines, while maintaining a moderate guidance gap Δ between separated and ideal vocal conditions. This validates the role of both the hierarchical token decomposition and the architectural ablations in regularizing performance across upstream separation and downstream inference.
Practical and Theoretical Implications
Practically, HAFM enables robust, plug-and-play audio-domain accompaniment generation from arbitrary vocals, facilitating assistive music creation for non-musicians and scalable, controllable audio synthesis applications. The dual-rate hierarchical pipeline generalizes beyond vocals-instrumental, suggesting immediate extensibility to multi-track (e.g., drums, bass, piano) conditional generation. Theoretically, HAFM's results reinforce the efficacy of discrete token-based hierarchical modeling for high-rate audio and highlight the continued gains from fusing advanced Transformer stabilization strategies in autoregressive audio modeling.
Future Directions
Future work may target upscaling the sample rate and EnCodec bandwidth for higher-fidelity outputs, decomposing instrumental tracks by role or instrument for finer-grained conditional control, and exploring richer, multi-attribute conditioning schemes (genre, arrangement, emotional context). More generally, this paradigm motivates further exploration into cross-modal generative modeling between speech, singing, and music using domain-agnostic Transformer architectures.
Conclusion
HAFM demonstrates that a three-stage hierarchical, dual-tokenization, autoregressive Transformer stack, augmented with recent normalization, attention, and positional advances, suffices to generate temporally coherent, musically meaningful instrumental accompaniments to isolated singing inputs. Its architectural efficiency and competitive empirical performance pave the way for scalable, interactive music generation solutions and further research in multi-modal foundation models for music and audio tasks.