- The paper introduces a data-centric LLM framework that automates SVA synthesis using an iterative, syntax-aware refinement loop and AST-grounded dataset construction.
- It achieves high Syntax Pass Rates and substantial improvements in Semantic Equivalence Rates across increasing temporal complexity tiers.
- The framework minimizes manual errors and scales hardware verification by leveraging fine-tuning, formal property checking, and a stratified benchmark protocol.
Automated SVA Generation with LLMs: A Data-Centric Framework
Introduction and Context
The increasing complexity of integrated circuits, driven by architectural innovation and heterogeneous integration, has rendered functional verification a principal bottleneck in modern IC development. Assertion-Based Verification (ABV), and in particular, the use of SystemVerilog Assertions (SVAs), is fundamental for both simulation-based monitoring and formal property checking. However, the manual development of SVAs is highly labor-intensive and error-prone, owing to the nuanced interplay of concurrent semantics, linear temporal logic, and strict syntax constraints.
The surge in LLM capabilities for code generation has not resolved the challenges of SVA synthesis. General-purpose LLMs often produce SVAs that, while syntactically valid, lack semantic correctness due to the absence of domain-aligned, high-quality training data and evaluation protocols that fail to capture the fine-grained semantics of temporal assertions. Existing approaches are further encumbered by the scarcity of aligned SVA-Description (SVAD)--SVA pairs and the prevalence of superficial evaluation metrics.
Methodological Innovations
The SVA Generator framework introduces a data-centric pipeline rigorously aligned with the specific requirements of SVA synthesis. The framework is driven by the following core components: (A) an iterative LLM-based SVA generation and syntax-aware refinement loop, (B) an AST-grounded dataset construction pipeline, and (C) a depth-stratified benchmark with formal property equivalence checking as the evaluation protocol.
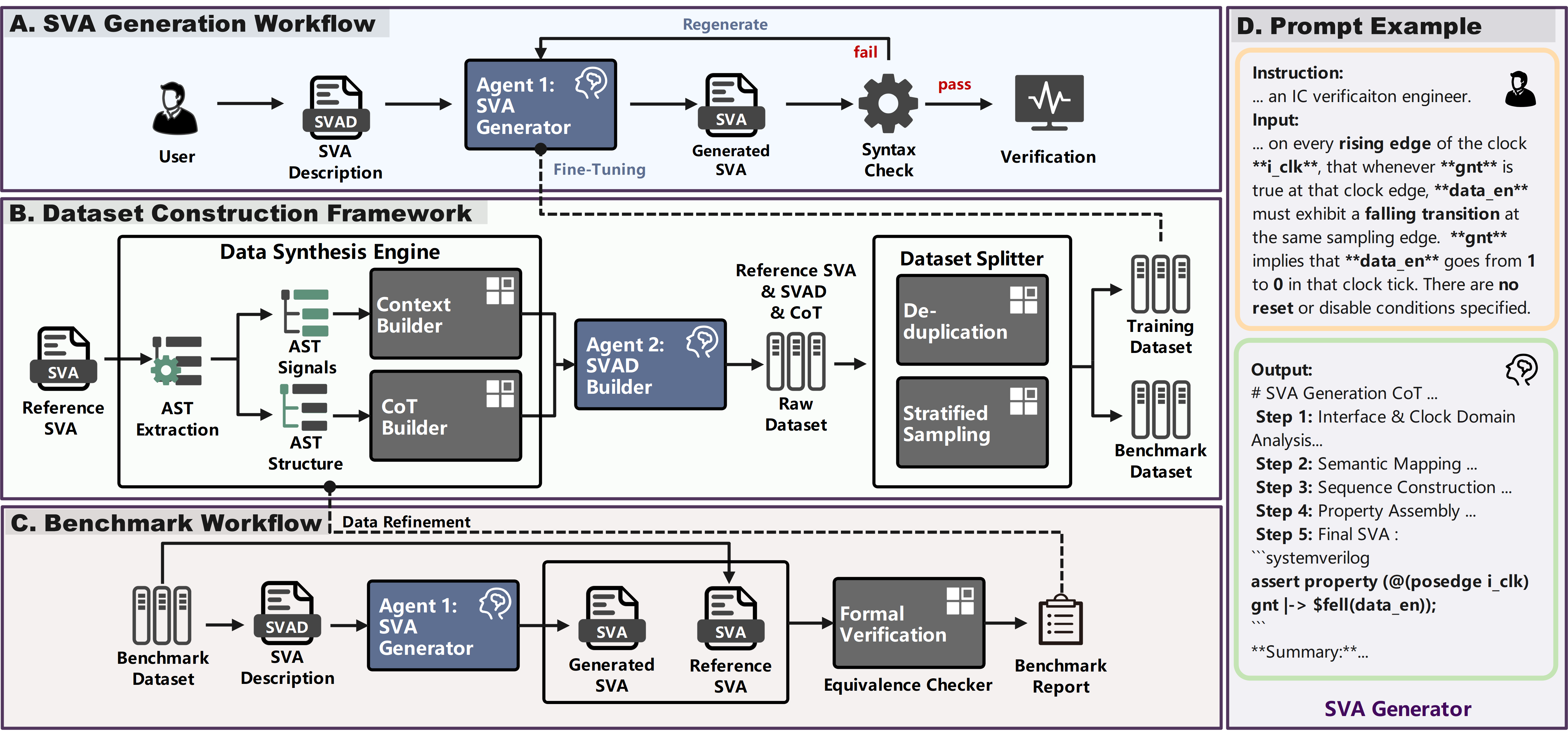
Figure 1: The system comprises (A) a syntax-aware LLM generation and refinement workflow, (B) an AST-grounded pipeline for high-quality aligned data generation, (C) a formal benchmark suite with property equivalence checking, and (D) an illustration of prompt and output formats for SVAD and SVA.
The SVA Generator employs two primary agents. Agent1 (SVA Generator) performs inference by translating SVADs—concise natural-language expressions of temporal intent—into SVAs, leveraging a supervised fine-tuned (SFT) LLM specialized on AST-grounded data. To enforce syntax correctness, a syntax checker validates each output; failures are used to prompt automated regeneration, significantly reducing the rate of invalid outputs without manual intervention.
Dataset quality is preserved by a construction framework that parses reference SVAs into AST representations, from which it extracts both signal-level interfaces and temporal logic structure. This enables the design of constraint-injected annotation prompts that strictly align the SVAD and SVA through AST-grounded signal and operator consistency, and the automatic synthesis of chain-of-thought traces (CoT) that serve as deterministic reasoning scaffolds throughout the annotation process.
To ensure robust performance measurement, a novel benchmark protocol stratifies SVAs by AST depth D, forming four difficulty tiers (D1–D4). This stratification precisely quantifies the model's ability as temporal and structural complexity escalate, decoupling operator coverage from reasoning chain length. Semantic Equivalence Rate (SER) is then reported based on mutual implication between generated and reference SVAs, as established by an industrial-scale property equivalence checker.
Experimental Protocol and Quantitative Evaluation
The evaluation deploys Agent1 using Llama-3.1-8B as base, with SFT on a proprietary, AST-grounded dataset comprising approximately 8×104 entries. Agent2 (SVAD Builder) utilizes GPT-5.2 for high-fidelity SVAD generation under structural constraints. All experimentation is carried out on an A800 cluster with comprehensive toolchain integration for static analysis, syntax normalization, and benchmark equivalence checking.
Two key metrics are reported: the Syntax Pass Rate (SPR), reflecting the proportion of outputs evaluable by syntax checkers, and the Semantic Equivalence Rate (SER), quantifying the fraction of syntax-passing SVAs that are semantically identical to the reference.
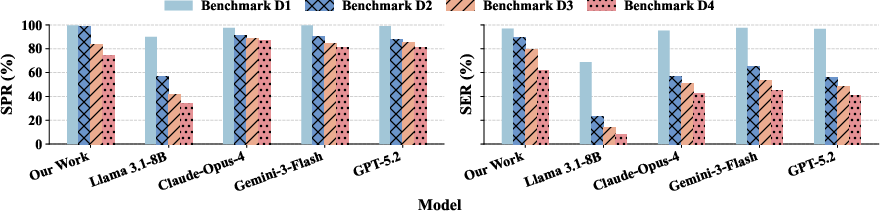
Figure 2: Comparative SPR (left) and SER (right) for the proposed method against strong general LLMs (GPT-5.2, Gemini-3-Flash, Claude-Opus-4, base Llama-3.1-8B), stratified from D1 (shallow) to D4 (deeply nested properties).
SPR remains high across all models for shallow tiers (D1--D2), but declines as AST depth increases, reflecting the rising syntactic burden of temporal operator nesting. The SVA Generator attains 99.6%, 98.5%, 83.8%, and 74.2% SPR across tiers D1--D4, rivaling or slightly trailing the strongest general LLMs for deep nesting. However, the model delivers substantial improvements in SER for complex properties: 96.9% (D1), 89.2% (D2), 79.1% (D3), and 62.1% (D4), consistently outperforming general baselines.
Relative to the best general LLM, the framework achieves a +24.5 percentage point SER improvement on D2, +26.0 pp on D3, and +17.5 pp on D4, averaging +22.7 pp over D2--D4. This demonstrates the necessity of domain-aligned fine-tuning and AST-grounded supervision for preserving semantics under long-chain temporal reasoning.
Error Attribution and Failure Mode Analysis
Detailed error attribution is conducted to dissect the sources of failure. Syntax errors in deep tiers are predominantly attributed to structural errors, timing operators, and type mismatches. The syntax-aware refinement loop mitigates many of these, but they become increasingly challenging at higher depths.
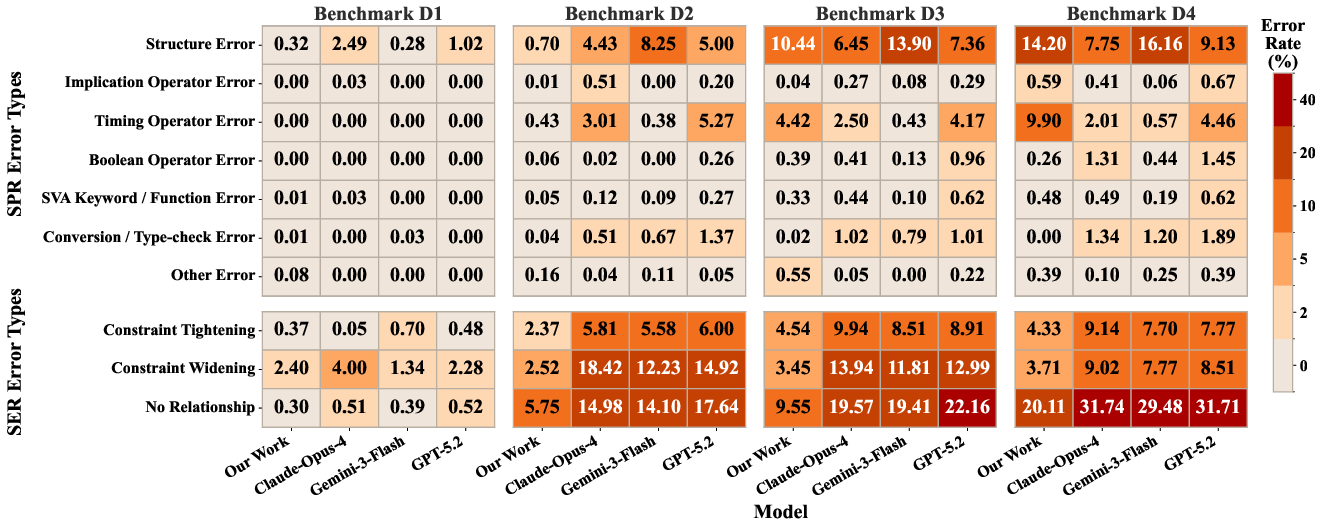
Figure 3: Upper: Distribution of syntactic error types contributing to SPR failures; Lower: Taxonomy of SER outcomes, including equivalence, strict constraint mismatch, and no formal relationship, across models and depths.
Semantic failures are scrutinized using implication relationships: non-equivalent outputs are classified as weaker (constraint widening), stronger (constraint tightening), or unrelated to the reference. As depth rises, the share of outputs with "no relationship" surges for general LLMs, whereas the SFT-based SVA Generator maintains lower rates, emphasizing its superior intent preservation. Directional implication errors provide actionable feedback for ongoing refinement of dataset composition and constraint rules.
Implications, Future Directions, and Theoretical Significance
This work isolates SVA generation from broader document-level understanding, enabling controlled, reproducible, and semantically robust evaluation. It demonstrates that AST-grounded, structurally constrained dataset construction is instrumental in overcoming both data scarcity and semantic drift—challenges unaddressed by previous LLM approaches in ABV.
Practically, the outlined framework enables scalable, reliable SVA synthesis directly from natural language, reducing manual verification overhead and lowering the expertise threshold for ABV adoption in industrial flows. The benchmark methodology—publicly releasing a depth-stratified suite with formal equivalence checking—sets a new standard for evaluation protocols in the field.
Theoretically, results support the hypothesis that temporal logic code generation, especially under strict semantic constraints, demands domain-structured supervision and fine-grained evaluation. The synthetic alignment of signals and operator structure through AST analysis provides a foundation for future extension to more complex verification languages and broader property synthesis tasks.
Anticipated future developments include expansion of the benchmark suite for broader language coverage, integration with retrieval-augmented LLMs for larger-context specification conditioning, and multi-agent protocols for end-to-end automation of ABV flows, encompassing coverage enhancement and automatic debugging. The findings advocate for increased emphasis on structurally constrained data construction and formal correctness in all LLM-augmented hardware verification research.
Conclusion
Automated SVA generation with LLMs is greatly advanced by the integration of AST-grounded dataset synthesis, SFT-based model specialization, and rigorously stratified semantic benchmarking. The demonstrated gains in SER, without trade-off in SPR, validate the necessity of formal property checking and constraint-driven annotation for high-assurance assertion generation. The proposed framework provides both a practical toolchain and a research platform for future study at the intersection of formal verification and LLM-driven code synthesis (2604.11044).

