- The paper introduces a multi-agent pipeline that decomposes SVA generation into specialized subtasks, achieving a 33.3pp improvement in functional correctness and over 11× gain in coverage.
- It leverages AgentBridge, a hybrid data synthesis platform that enforces ground-truth provenance and output verifiability to produce high-purity datasets.
- Experimental results on 24 RTL designs show significant gains, with an average of 139.5 SVAs per design and balanced detection across nearly all critical bug classes.
ChatSVA: Multi-Agent SVA Generation for Hardware Verification via Task-Specific LLMs
Introduction: Bottlenecks in IC Verification and the Need for Automation
Functional verification is a dominant time and cost factor in IC development, accounting for over half of the design lifecycle. SystemVerilog Assertions (SVAs) are standard for both formal property checking and simulation-based debugging, but manual SVA creation remains a labor-intensive and error-prone process, significantly impeding verification productivity.
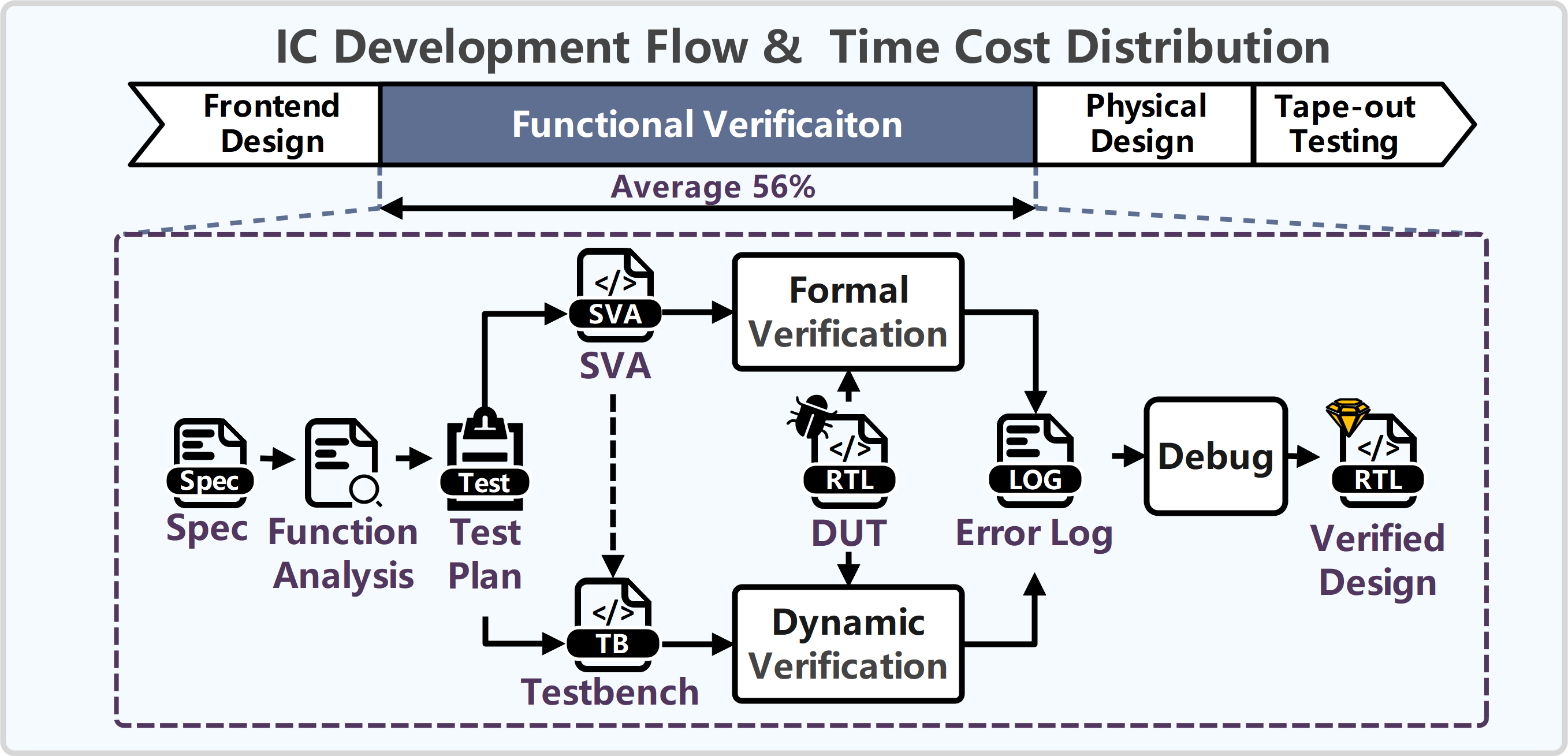
Figure 1: IC development flow time cost distribution, highlighting functional verification as 56% of total development time.
Traditional SVA automation relied on either dynamic mining from simulation traces (problematically dependent on buggy DUTs and forfeiting formal coverage) or static NLP-based translation from specifications, both failing to scale due to shallow semantic modeling. The introduction of LLMs shifted research focus, yet most recent methods treat SVA generation as a monolithic task—directly mapping Spec to code—with resulting functional accuracy bottlenecks and chronic data scarcity for domain-specific learning.
ChatSVA and AgentBridge: Long-Chain Reasoning with Data Synthesis
ChatSVA introduces a principled multi-agent framework, explicitly decomposing SVA generation into four modular stages: from functional Spec, through Verification Plan and Feature List, then Checkpoint selection, and finally SVA code emission. This stepwise decomposition mitigates functional hallucinations by enforcing reasoning and anchoring the process in domain intent rather than superficial syntactic correctness.
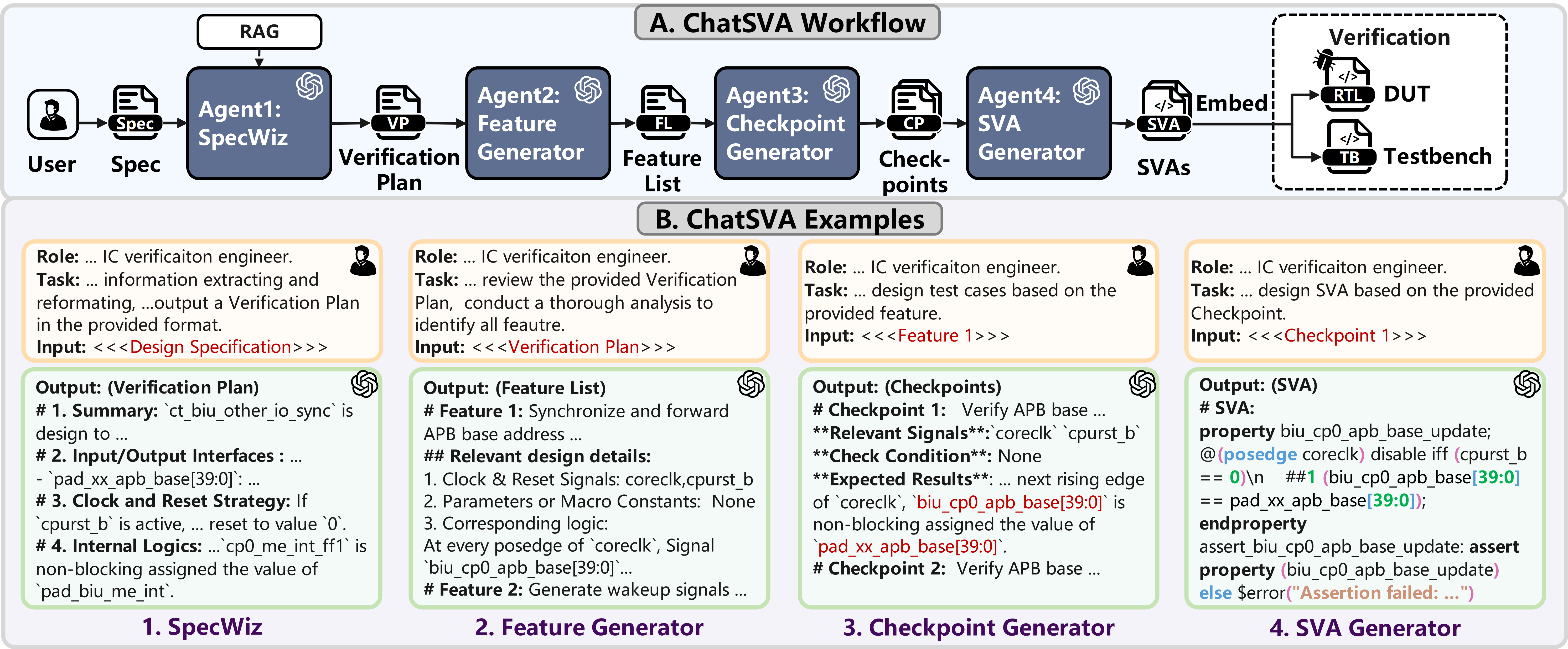
Figure 2: ChatSVA workflow, illustrating structured decomposition from Spec to SVA via intermediate representations.
To address the few-shot training dilemma, ChatSVA leverages AgentBridge—a unified platform for dataset synthesis, augmentation, and validation. AgentBridge operates under three foundational principles: directional information constraints (outputs as functional subsets of verified sources), golden ground truth provenance, and explicit verifiability via hybrid validation protocols. The platform instantiates closed-loop self-improvement for dataset quality, coupling reverse-generation checks with expert review and formal equivalence testing, especially for $1:1$ mappings such as Checkpoint-to-SVA.
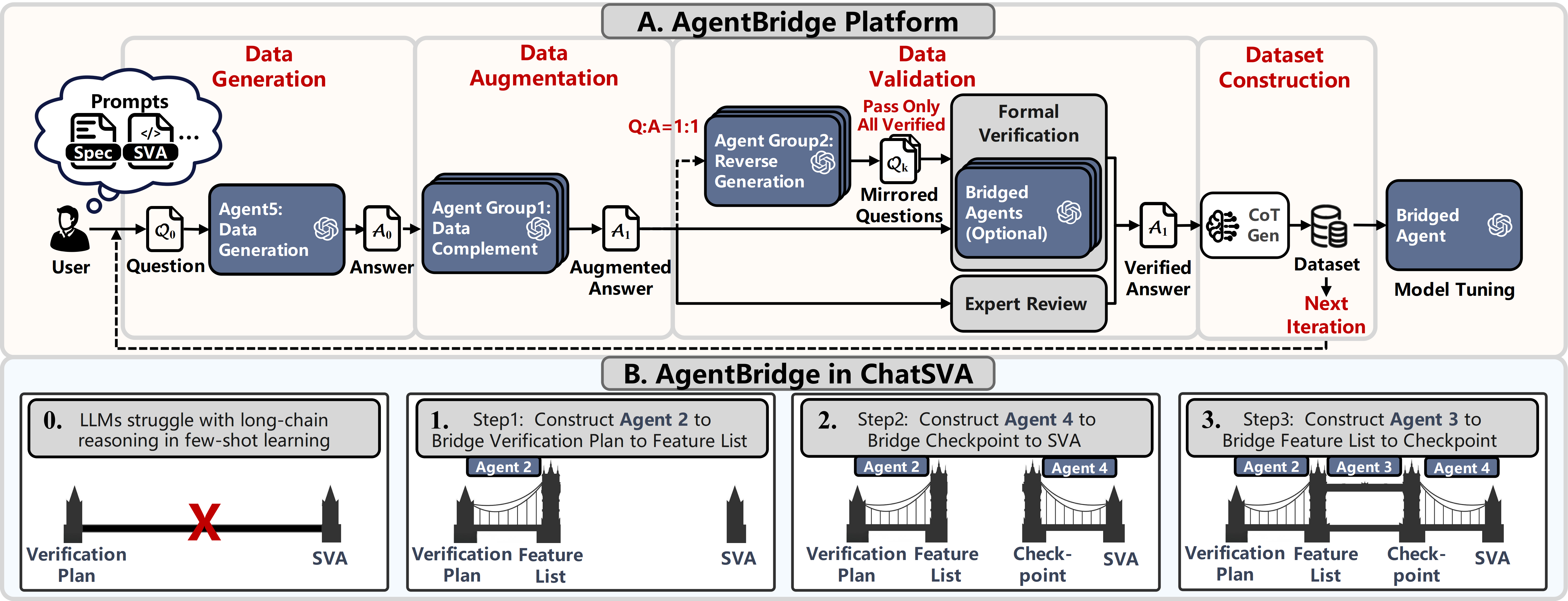
Figure 3: AgentBridge platform architecture embedded within ChatSVA, supporting data synthesis and verification for each pipeline stage.
Evaluation: Quantitative Advancements over Baselines
Experiments on 24 industrial-grade RTL designs demonstrate ChatSVA's advancements across all principal metrics: Syntax Pass Rate (SPR), Function Pass Rate (FPR), and Function Coverage. ChatSVA generates an average of 139.5 SVAs per design with a 98.66% SPR and 96.12% FPR, achieving 82.50% Function Coverage. These results surpass general-purpose LLMs (GPT-4o, DeepSeek-R1) by more than 11× and outperform SOTA multi-agent frameworks such as AssertLLM, whose function coverage remains at 7.5%.
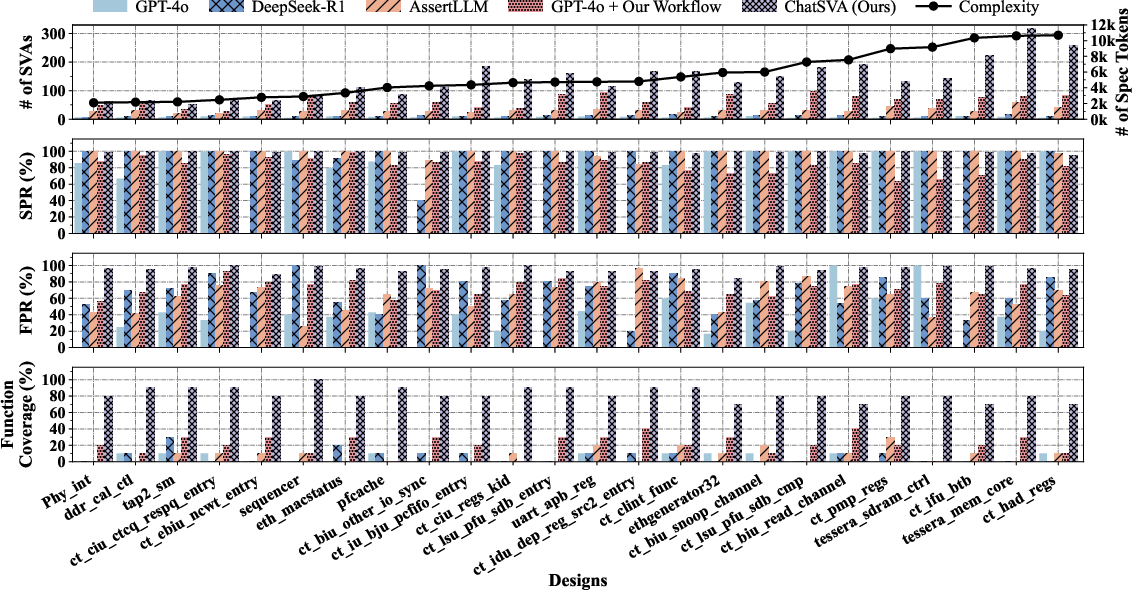
Figure 4: Comparative performance metrics for ChatSVA and baselines on SVA generation quality and efficacy.
Ablation studies confirm that the performance gains originate from both the long-chain reasoning decomposition and domain-specific data synthesis. Applying only the ChatSVA pipeline as structured guidance to GPT-4o increases its FPR by 30 percentage points and multiplies function coverage by five, indicating the decomposition is a primary factor. Integrating high-purity AgentBridge training datasets elevates efficacy further, with function coverage rising to 82.50%.
Analysis of bug detection distributions reveals ChatSVA's coverage of 15 out of 16 bug categories, a breadth unmatched by baseline systems. General-purpose and prior multi-agent systems exhibit sporadic or narrow bug coverage, lacking systematic detection.

Figure 5: Distribution of detected bugs per model, with ChatSVA providing comprehensive and evenly distributed coverage.
AgentBridge Dataset Precision and Purity
Rigorous validation of AgentBridge confirms its filtering mechanism's efficacy. Using reverse-generation and multi-agent consensus, false positives are reduced from nearly 30% to 0.05% as agent count increases, pushing dataset precision to 99.9% at the cost of recall. This prioritization of purity ensures SFT models are trained on verifiable, domain-correct data, directly preventing semantic contamination.
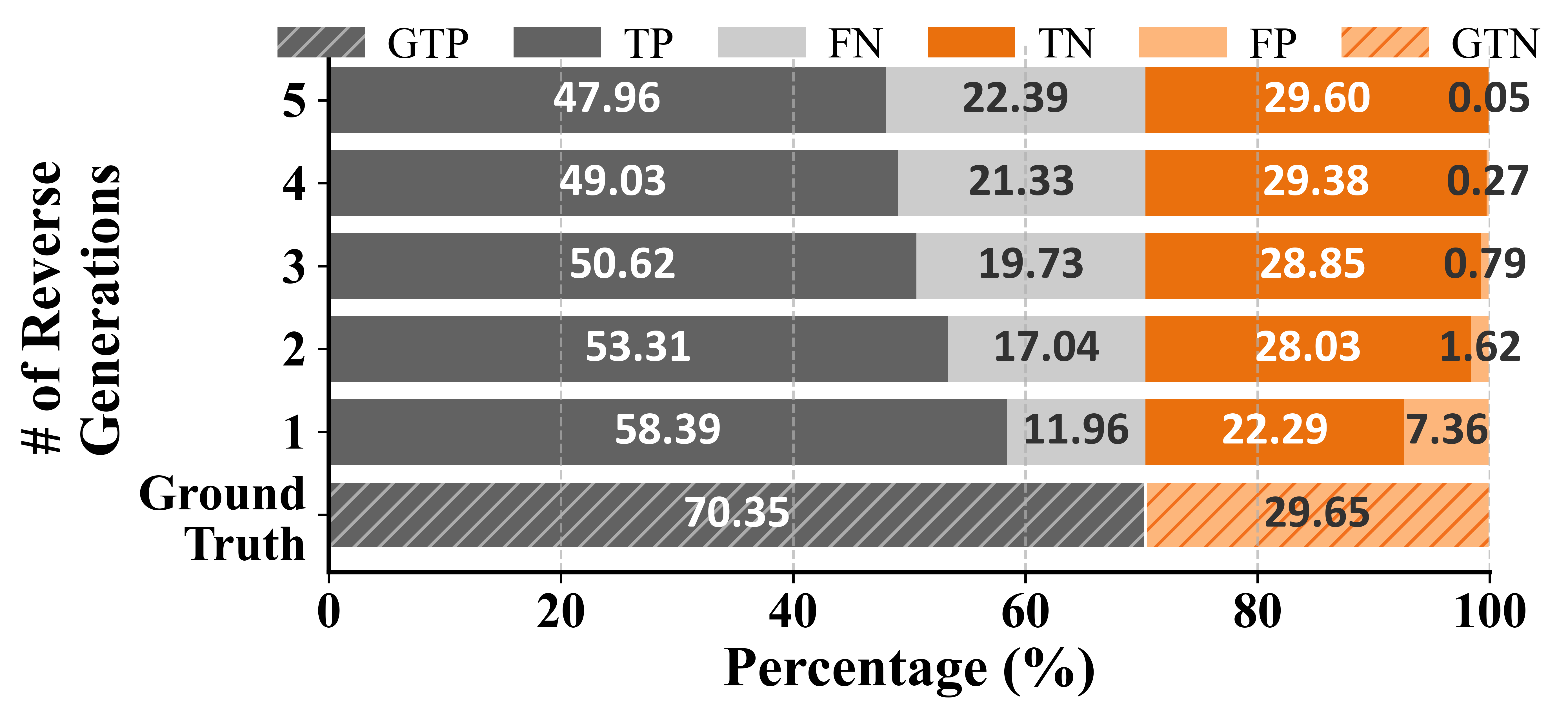
Figure 6: Stackbar visualization showing data distribution and reduction of false positives in AgentBridge’s reverse-generation validation.
Implications and Future Directions
The ChatSVA framework advances automated verification workflows by providing functionally robust SVA generation, supporting coverage-based debugging and formal property analysis. Practical implications include substantial reductions in time-to-market, improved assurance against post-silicon bugs, and scalability across domain-specific architectures.
AgentBridge's methodology for dataset synthesis and validation generalizes to other few-shot EDA tasks, where data abstraction and rigorous provenance are critical. The explicit decomposition of reasoning steps sets a precedent for tackling long-chain tasks in LLM-aided design automation.
Prospective research could integrate adaptive multi-modal LLMs for extracting design intent from broader artifact types (block diagrams, protocol docs), further expand reverse-generation protocols for formal equivalence checking, and apply the framework to emerging domains such as security assertion mining and agile DevOps in hardware design.
Conclusion
ChatSVA establishes a new methodology for domain-specific automated assertion generation, combining explicit reasoning decomposition with high-purity dataset synthesis via AgentBridge. Systematic evaluation demonstrates substantial improvements in functional correctness and coverage over prior approaches. The work has significant implications for advancing agile hardware verification and provides a scalable foundation for long-chain reasoning tasks in AI-aided EDA.