- The paper introduces an agentic execution-grounded framework that verifies exploitability before patch synthesis, ensuring trustworthy repairs.
- It employs a hybrid of graph and LLM embeddings fused with a universal AST to achieve 89.84–92.02% accuracy and a 23.42% cross-language gain.
- The system’s validation step reduces false positives by over 61%, and its repair module reaches up to an 87.27% success rate within five iterations.
Agentic Execution Grounding for Cross-Language, Trustworthy Code Vulnerability Analysis
Framework Overview and Architectural Contributions
"Verify Before You Fix: Agentic Execution Grounding for Trustworthy Cross-Language Code Analysis" (2604.10800) presents a lifecycle architecture for automated vulnerability detection and repair that enforces execution-grounded confirmation as a prerequisite for any remediation action. The pipeline comprises three stages: hybrid structural-semantic detection, agentic execution-grounded validation, and validation-aware iterative repair, unified by a strict invariant that no fix proceeds unless exploitability is verified via controlled execution.
Figure 1: Three-stage lifecycle architecture. The Fusion Detector combines graph and LLM embeddings via two-way gating for binary detection. The Validation Agent confirms exploitability through sandboxed execution. The Remediation module generates minimal patches, outputting a detection flag, validation trace, and fixed code.
At its core, the framework is built around two key architectural features. First, it employs a Universal Abstract Syntax Tree (uAST) to abstract Java, Python, and C++ into a common, lossless structural schema. This normalization enables structural learning and transfer not achievable by token-based or even AST-based models tied to single languages. Second, it fuses GraphSAGE-based graph embeddings of uASTs with Qwen2.5-Coder-1.5B LLM-based semantic embeddings through a two-way gating mechanism. The learned per-sample gating weights provide intrinsic, contextual interpretability, quantifying each prediction's dependence on surface structure or deep semantics.
Detection: Cross-Language Generalization via Hybrid Reasoning
The hybrid detector leverages structural regularities and semantic context. Empirical results demonstrate 89.84--92.02% intra-language accuracy ($0.8837$--$0.9109$ F1), with hybrid models outperforming structure-only and semantic-only baselines by 8--15 percentage points. Notably, C++ achieves the best scores, attributable to the explicit structural signatures of memory unsafety in its code.
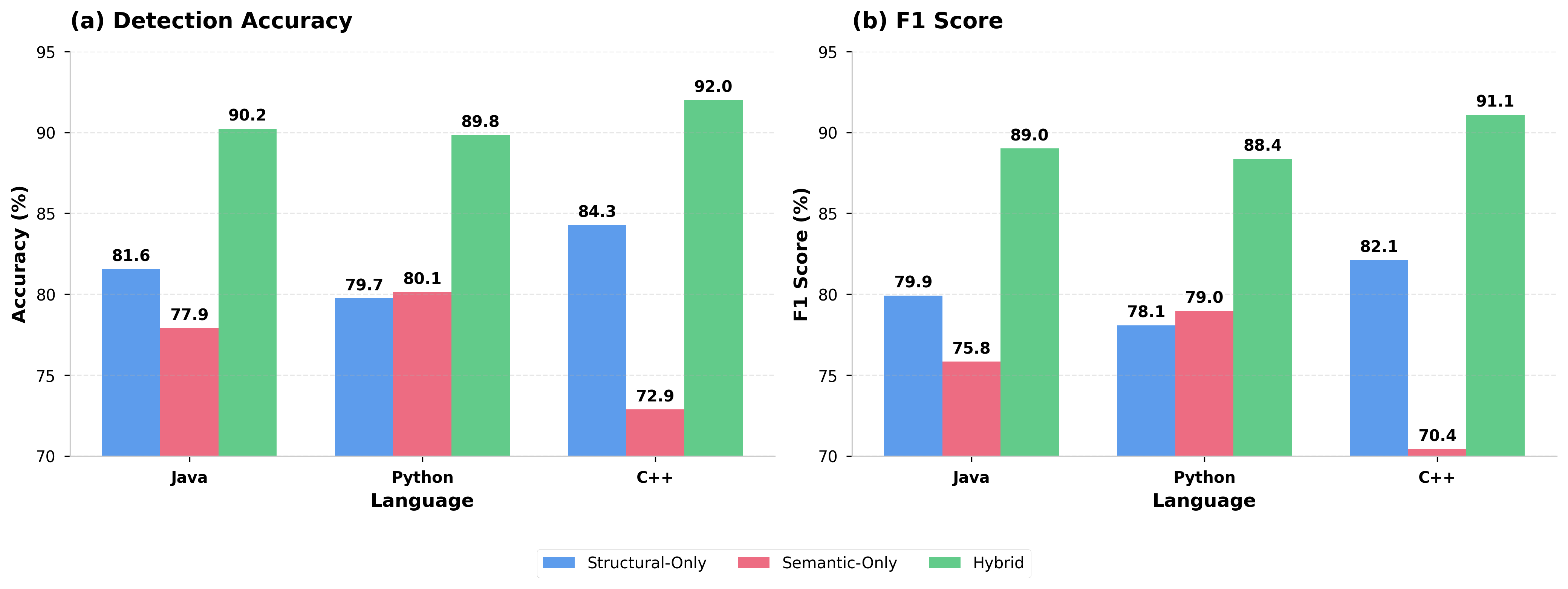
Figure 2: Intra-language detection performance. The hybrid model achieves 89.84--92.02% accuracy and 0.8837--0.9109 F1, outperforming both baselines by 8–15 percentage points; C++ achieves the highest accuracy.
Zero-shot cross-language transfer attains 74.43--80.12% F1—-a 23.42% gain over language-specific representations. Ablation confirms that uAST normalization, not mere model scaling, is the principal driver enabling this generalization. The hybrid detector's two-way gating not only improves detection but aligns its behavior with explainability requirements, as gating weights directly indicate whether a finding is structurally or semantically determined.
Validation: Execution-Grounded Agentic Confirmation
Unlike previous pipelines that execute repairs on unverified detector output, this framework adopts an LLM-powered validation agent. It generates explicit exploit hypotheses, constructs tailored payloads, and invokes language-specific (Python/Java/C++) harnesses with strict OS-level isolation.
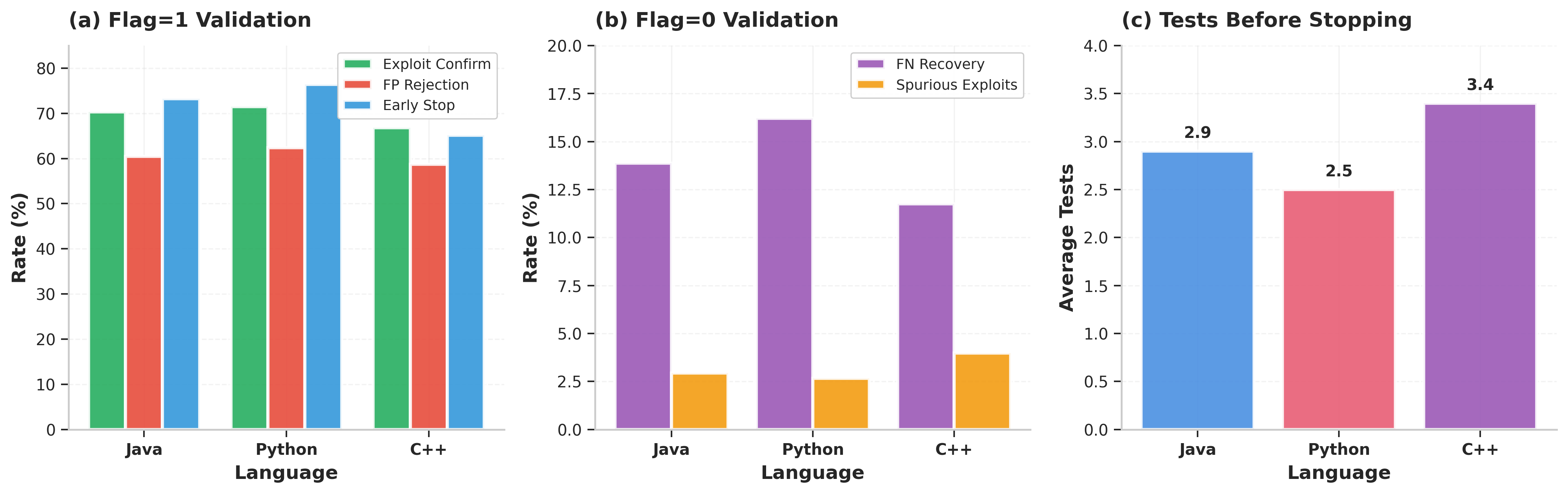
Figure 3: Validation performance across languages, showing exploit confirmation, false positive rejection, missed vulnerability recovery, and average tests before early stopping.
Empirical metrics show that, for flagged positives, the agent confirms exploitability in 66.84--71.49% of cases, while rejecting 58.72--62.37% of false positives. For negatives, limited probing recovers 11.76--16.21% of missed vulnerabilities at a spurious discovery rate below 4%. Early stopping and multi-payload probing enable a tradeoff between thoroughness and runtime.
The validation step is essential: when disabled, unnecessary repairs increase by 131.7% and end-to-end success drops by 9.56 percentage points. These findings establish execution grounding as a necessary element in high-stakes agentic pipelines.
Repair: Validation-Aware Patch Synthesis and Human-AI Collaboration
Remediation is strictly gated on confirmed exploitability. The system fine-tunes Qwen2.5-Coder-1.5B via LoRA for patch generation, using rich prompts containing vulnerability context, exploit payloads, and behavioral traces. Patch application is AST-based and localized to vulnerable regions, and each candidate patch must lead to clean post-patch detection and pass revalidation.
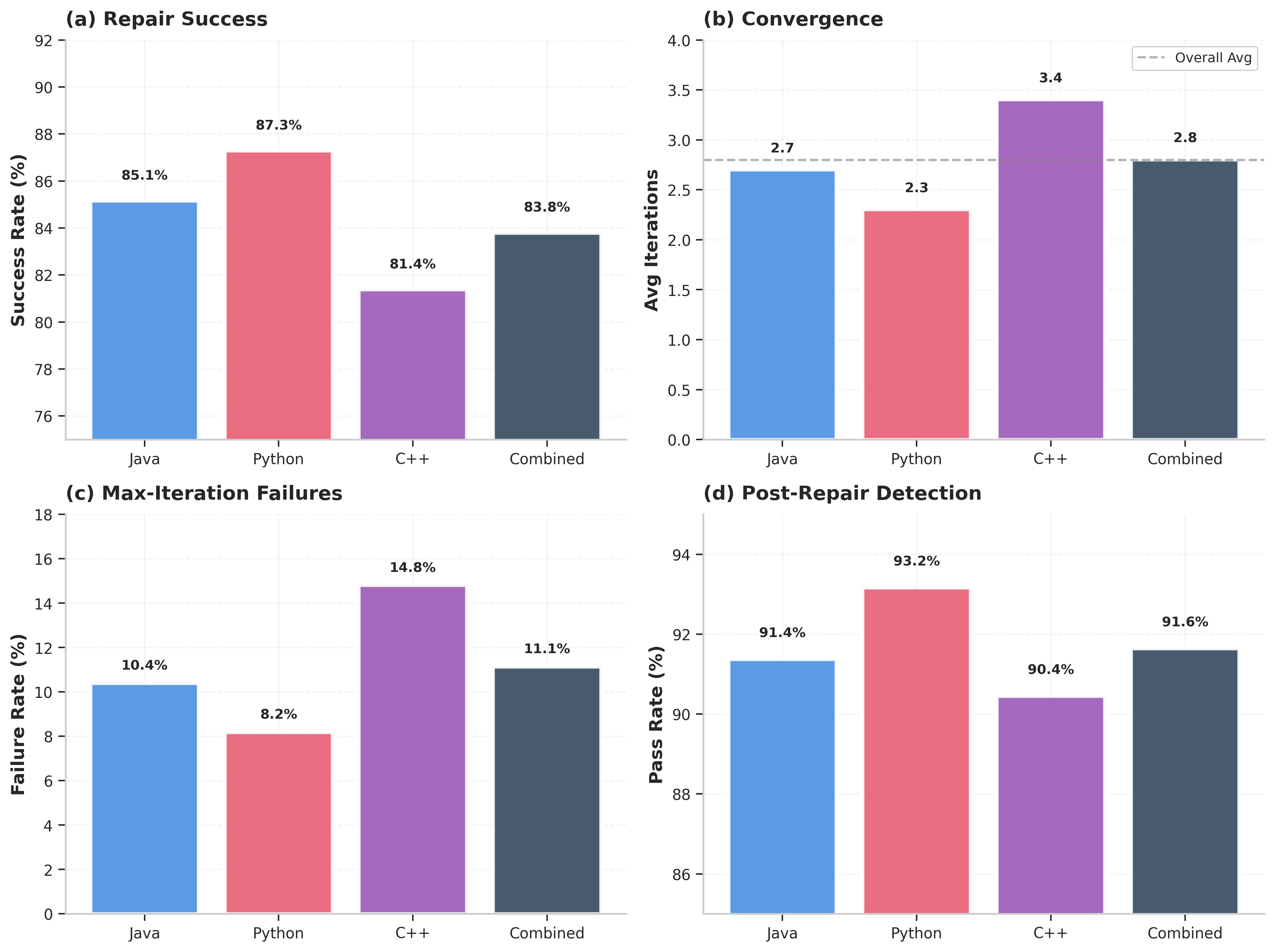
Figure 4: Repair performance metrics across languages, including success rates, convergence iterations, failure rate, and post-repair detection pass rates.
Success rates reach 81.37--87.27% within five iterations, with convergence typically after 2.3--3.4 cycles. Patches restore safety, as verified by post-repair detection rates of 90.44--93.15%. Non-convergent samples are flagged for human review with diagnostic traces, codifying a collaborative workflow at the human-AI boundary.
The full pipeline resolves 69.74% of vulnerabilities end-to-end at a 12.27% failure rate. The execution-grounded validation eliminates 61.24% of detector false positives before the repair phase and prevents 73.13% of unnecessary repair attempts, yielding substantial computational and practical savings.
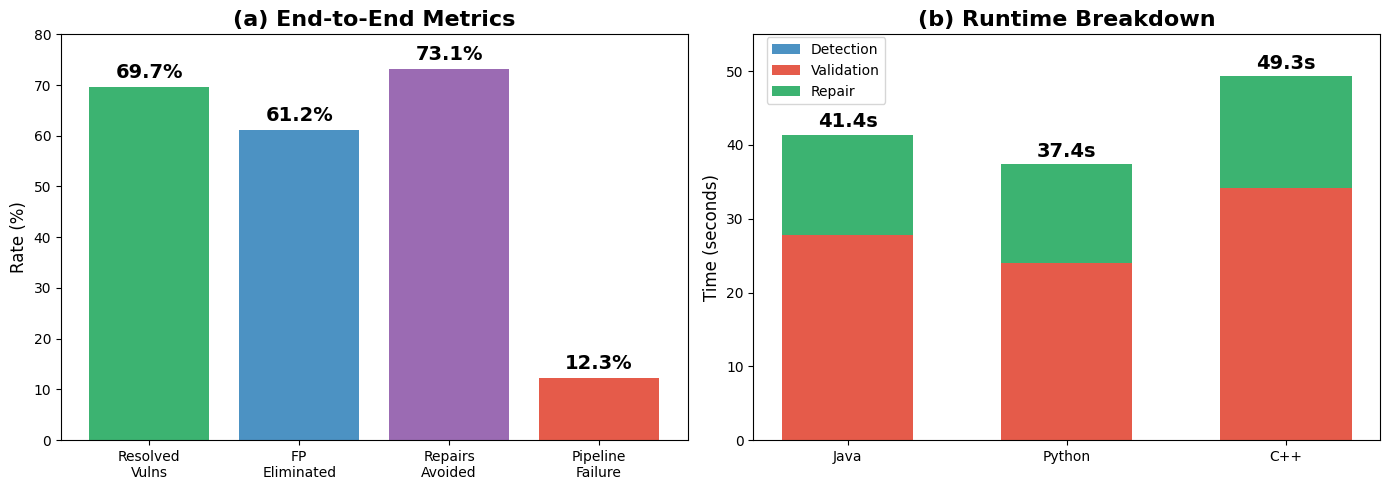
Figure 5: End-to-end pipeline metrics demonstrating high-resolution rates, false positive filtering, unnecessary repair avoidance, and failure rates.
Through architecture selection experiments, GraphSAGE + Qwen2.5-Coder-1.5B emerges as the best-performing fusion (90.21% F1), outperforming both GCN and GAT-based alternatives.
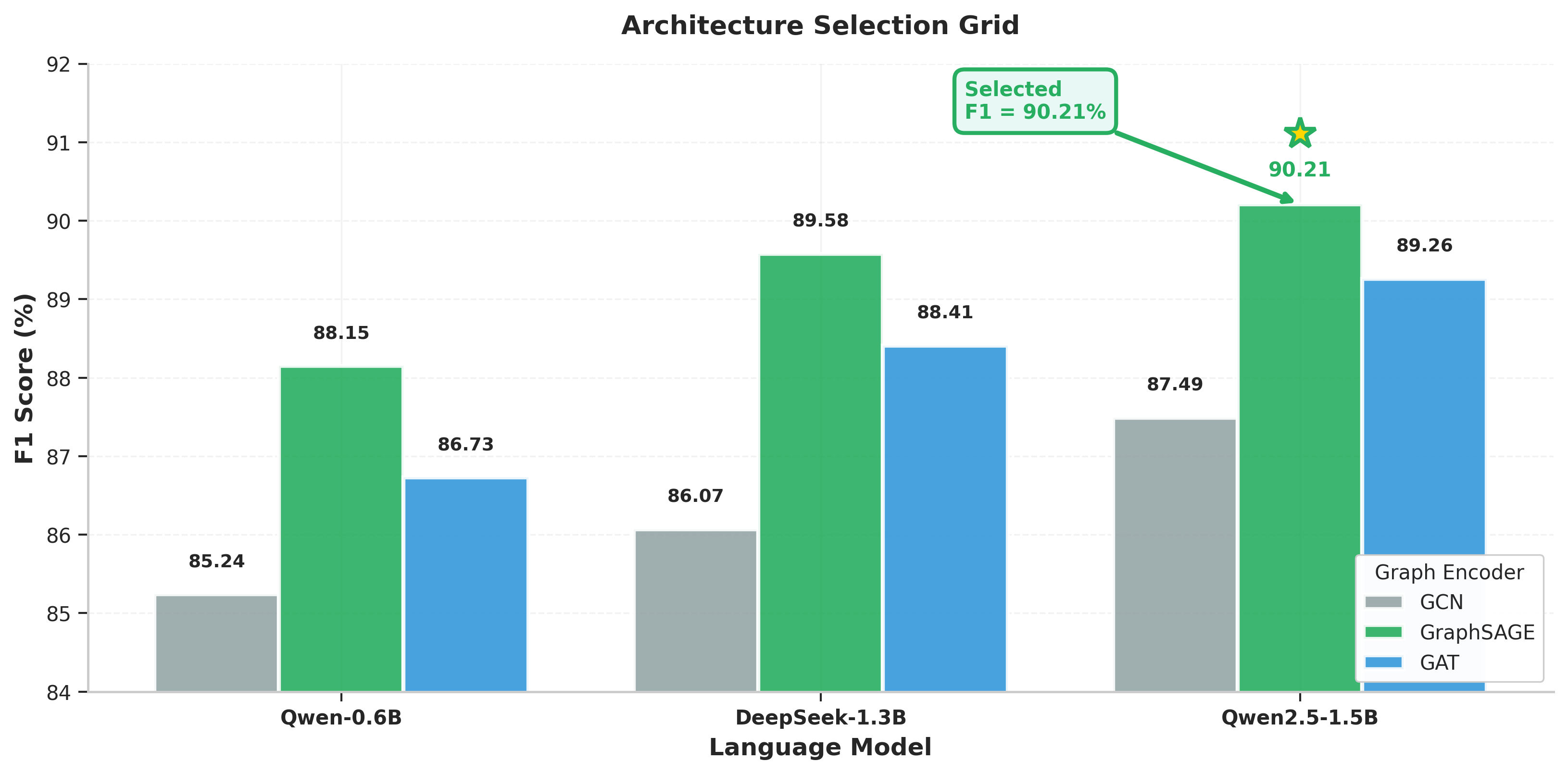
Figure 6: Architecture comparison grid illustrating the superiority of the GraphSAGE + Qwen2.5-Coder-1.5B combination.
Implications, Limitations, and Future Directions
This work operationalizes a generalizable principle for trustworthy agentic AI: always verify via external feedback before acting on LLM-driven predictions. The empirical ablations quantify the costs—-in false positives, wasted labor, and diminished reliability—-of skipping this agentic checkpoint.
The intrinsic explainability resulting from per-sample fusion weights offers an improved paradigm over post-hoc XAI methods, opening pathways to more verifiable operation in security and safety-critical domains. The use of uAST points to a recurring lesson for multi-domain AI: robust structural abstraction is necessary for reliable out-of-distribution generalization.
Limitations include bounded reasoning horizon (the 2-hop GraphSAGE restricts multi-hop flow analysis), incomplete support for concurrency or business logic flaws, and missing formal patch correctness guarantees. Future directions include reward-driven refinement of the validation agent, expansion to additional languages (already supported structurally via Tree-sitter grammars), and integration with program synthesis and formal verification to provide not only exploit-blocking but provably correct repairs.
Conclusion
This paper establishes that execution-grounded, closed-loop reasoning is both necessary and effective for deploying trustworthy LLM-driven agentic AI in software vulnerability detection and repair. Structural-semantic fusion with uAST enables robust cross-language generalization, intrinsic interpretability, and human-collaborative workflows. These principles are broadly applicable to other AI systems in high-stakes settings where predictions must be externally verified before automated action.