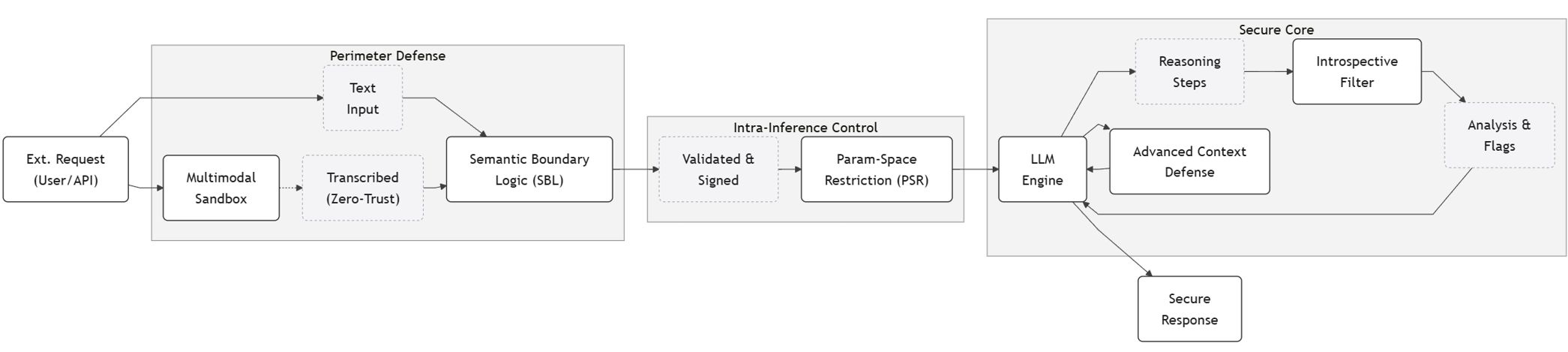
- The paper introduces a mechanism-centered taxonomy identifying 41 risk patterns and cross-stage vulnerabilities in LLM architectures.
- It empirically evaluates failure modes using metrics like IEO and POB, revealing significant capacity–safety scaling mismatches.
- The proposed countermeasures enforce provenance tagging and mandatory revalidation to mitigate privilege escalation and state-based attacks.
Cross-Stage Semantic Vulnerabilities in LLM Architectures: Mechanisms, Empirical Mapping, and Architectural Countermeasures
Introduction
The integration of LLMs into increasingly complex, multimodal, tool-enabled, and agentic architectures has introduced advanced security risks that surpass traditional input-output filtering paradigms. The paper “Unvalidated Trust: Cross-Stage Vulnerabilities in LLM Architectures” (2510.27190) presents a comprehensive empirical and architectural analysis of vulnerabilities arising from systemic trust inheritance, latent intent propagation, and interpretation-induced escalation within the LLM pipeline. Employing a mechanism-centered taxonomy spanning 41 risk patterns, the work disentangles inference-time failure modes using black-box benchmarks across commercial stacks, exposing capability-safety scaling mismatches and motivating zero-trust system design.
Mechanism-Centered Risk Taxonomy and Attack Graph
A key contribution is the formal taxonomy of semantic, structural, and state-based attack vectors, grouped by seven principal mechanism classes: (1) Obfuscation-based, (2) Modality bridging, (3) Interpretive and structural manipulation, (4) State and memory effects, (5) Architectural/ecosystem interactions, (6) Social and reflective steering, and (7) Agentic system risks. Subclasses formalize practical techniques such as base64/leet encoding, visual channel instruction via OCR, morphological/steganographic triggers, non-executable context cues, conditional block seeding, and session-scoped rule injection.
Relationships among these classes, their escalation pathways, and potential for cross-component amplification are represented in the Attack Graph, which systematically captures composition and intersection of mechanisms in deployed pipelines.
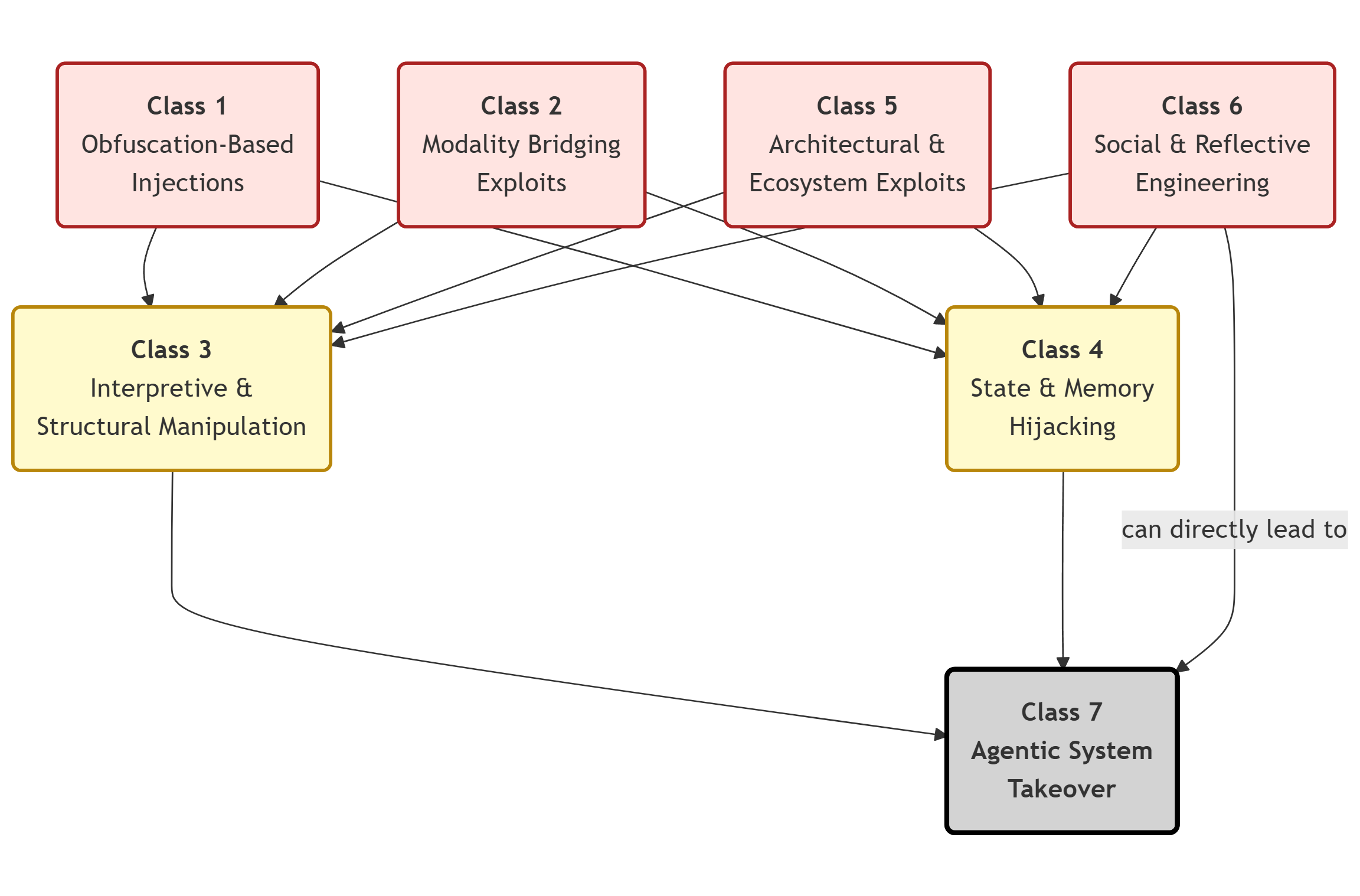
Figure 1: Attack Graph illustrating mechanism and escalation relationships across risk pattern classes in LLM-based architectures.
The empirical mapping links each risk pattern to quantitative benchmarks and evidence of cross-model variance, allowing reproducible evaluation regardless of specific provider alignment strategies.
Empirical Findings: Failure Modes and Capability–Safety Scaling
Using standardized, text-only black-box benchmarks under provider-default settings, the study measures each pattern’s incidence according to metrics such as Decode Success (DS), Interpretation Escalation Output (IEO), Policy Override Behavior (POB), Policy Deviation/Inconsistency (PDI), and Refusal/Redirect (RR). Notable findings include:
Architectural Failure Syndromes and Cross-Model Variance
A cross-sectional analysis reveals that architectural vulnerabilities are not a function solely of specific attack strings but of processing mechanisms and context governance. While certain prompt classes universally bypassed naive filters, empirical IEO/POB rates exhibited significant inter-model variance even under identical conditions—implying provider-side alignment and guardrails can moderate but not eliminate root architectural risk.
Capability–Safety Scaling Mismatch: Systems exhibiting higher semantic reconstruction abilities (decode, interpretation) often see correspondingly higher rates of unsafe escalation outputs unless explicit gating is applied after interpretation but before action, underscoring a persistent gap between representational capacity and alignment policy.
Defense Architecture and Zero-Trust Principles
To counter these recurrent architectural failure modes, the paper synthesizes a set of architectural defense principles:
These principles collectively constrain unvalidated trust propagation, curb interpretation-driven escalation, and harden stateful surfaces against delayed activation. The companion “Countermind” architecture [Schwarz2025Countermind] is posited as an instantiation of these patterns.
Implications and Prospects
The demonstrated architectural failures and systemic trust inheritance patterns necessitate a shift in LLM security from surface-string filtering to mechanism-aware, stateful, and provenance-governed design. Practical implications include:
- Evaluation and Benchmarking: Security benchmarking must move to mechanism-composition coverage, including stateful, cross-stage attacks and contrived modality-bridging probes. Reporting should emphasize confidence intervals, inter-model variance, and rubrics that separate interpretive from execution escalation.
- Ecosystem and Agent Security: Tool- and agent-enabled systems must enforce plan provenance and verification not only for external user input but also for contextually inferred, decoded, or inherited directives, especially when agent policy reprogramming or physical-world actuation is in scope.
- Alignment and Training: Training RLHF or preference optimization pipelines must be inoculated against false-flag feedback and internal reward for inferred but unsafe policy escalation; feedback auditing and consensus/fact separation are mandatory [wang2023rlhfpoison].
- Future Development: As model capacity scales, architectural controls must trigger at, or ahead of, inference milestones where new semantic material is internalized, not merely at input boundaries or output emission.
Conclusion
The paper provides substantial empirical and architectural evidence that LLM-centric AI stacks, as currently deployed, exhibit cross-stage vulnerabilities rooted in systemic trust inheritance, interpretive plan elevation, and privilege escalation through state/memory effects. The demonstrated residual risk—even under diverse provider guardrails and alignment—mandates a paradigm of zero-trust context management, explicit provenance enforcement, mandatory plan/tool gating, and ensemble introspective defense (2510.27190). The resulting design patterns should serve as foundational reference for both red-teaming and the engineering of secure LLM-integrated systems, with implications extending to multimodal, tool-enabled, and agentic AI.
References:
All literature references, method comparisons, and empirical results cited are directly from the primary source (2510.27190) and its extensive reference list.