- The paper introduces a modular framework that decomposes complex Text-to-SQL queries using agentic views to tackle schema overload and improve precision.
- It employs schema compression, length-based chunking, and multi-agent synthesis with validated CTEs for enhanced context management and error repair.
- Empirical results demonstrate up to 70.38% execution accuracy and improved schema filtering, underscoring the practical benefits of decomposition.
Agentic Decomposition for Complex Text-to-SQL: Overview of AV-SQL
Motivation and Problem Statement
Traditional Text-to-SQL systems are operationally limited when confronting large-scale, real-world databases characterized by wide schemas and deeply compositional queries. Conventional designs rely on providing the entire schema as prompt context, which commonly exceeds LLM context windows and degrades accuracy via attention dilution and insufficient schema grounding. These models also struggle with error localization and semantic debugging, as monolithic SQL generation entangles syntax and schema-linking errors. The Spider2.0 benchmark highlights these failure modes in practical settings featuring intricate, multi-table schemas.
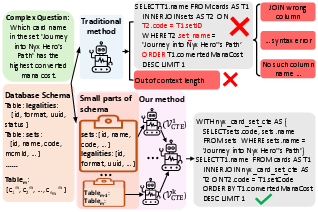
Figure 1: A motivating example from BIRD-dev (sample 501) illustrates how schema overload and context window constraints degrade the reliability of traditional Text-to-SQL models.
AV-SQL systematically addresses these limitations by decomposing the Text-to-SQL pipeline into fine-grained, specialized LLM agents. Its core innovation is the agentic view—a sequence of executable Common Table Expressions (CTEs) generated from schema chunks and validated iteratively, enabling robust, modular intermediate reasoning.
AV-SQL Framework and Decomposition
AV-SQL performs agent-guided query synthesis in three stages:
- Question Rewriting: A dedicated rewriter agent reformulates the user's question (with optional external knowledge) into an explicit, clarified intent. This reduces ambiguity and constrains the downstream search space, especially in enterprise settings where external documentation is verbose and noisy.
- Agent View Generation: The large schema is split into table-centric chunks by token budget, enabling each view generation agent to work in isolation on a manageable context slice. Each agent produces two outputs: (i) validated CTE-based views, encapsulating key reasoning steps (joins, filters, aggregates); and (ii) JSON-based schema selections highlighting relevant tables and columns. Intermediate views undergo multi-iteration execution-guided repair for syntax, schema grounding, value normalization, and consistency between CTEs and JSON selections.
- SQL Generation: Three specialized agents synthesize the final query: (i) a planner that structures join paths and projection logic; (ii) a SQL generator with execution feedback for iterative repair; and (iii) a revision agent for semantic verification and correction, ensuring strict alignment with user intent.
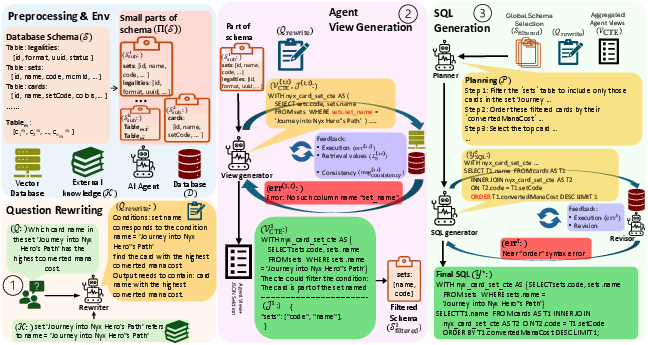
Figure 2: Overview of AV-SQL decomposing Text-to-SQL into preprocessing, question rewriting, schema chunked agent views, and multi-agent SQL synthesis.
Schema Compression and Chunking
To minimize token redundancy and improve context utilization in extreme-scale schemas, AV-SQL employs aggressive schema compression through clustering pattern-differentiated tables and columns. Compression reduces schema prompt length by up to 10×, verified for structural consistency before merging components.
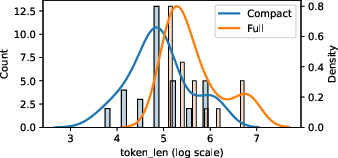
Figure 3: Token-length distribution of large database schemas before and after AV-SQL compression, enabling efficient chunked agent processing.
Length-based chunking then partitions the schema into prompt-sized blocks, ensuring all table/column definitions remain intact within each chunk. This method remains agnostic to the availability of foreign key metadata and maintains granular schema grounding critical for compositional reasoning.
The view generation agents iteratively refine their CTE queries through multi-stage feedback:
- Keyword Extraction and Value Retrieval: Literals from CTEs are matched to normalized database values using MinHash-LSH signatures, edit-distance, and semantic thresholds.
- Execution Validation: Syntax and schema-linking errors are detected via real database executions; errors are looped back for repair.
- Consistency Checking: Redundant and missing schema references between CTEs and JSON selections are systematically identified and corrected.
Aggregation combines agent views and global schema selections, furnishing downstream agents with compact, verifiable context.
Empirical Results and Ablation
AV-SQL delivers robust SQL generation across both standard and large-scale benchmarks:
- Spider2.0-Snow: Achieves up to 70.38% execution accuracy (Gemini-3-Pro), a substantial margin over specialized baselines (ReFoRCE 35.83%, AutoLink 34.92%) while maintaining lower token usage.
- Spider, BIRD, KaggleDBQA: Secures competitive or superior single-candidate EX, especially in complex/hard queries, outperforming multi-candidate methods in latency and efficiency.
On schema filtering, AV-SQL’s CTE-based agentic reasoning yields significantly higher precision (up to 86.34%) and competitive recall compared to prompt-based or learned selector baselines.
Ablation studies confirm that execution feedback is the critical driver of accuracy, with removing agent view validation and SQL repair causing up to 20–40% drops in EX on Spider2.0-Snow. The joint provision of validated CTEs and global schema selections is synergistic—both are necessary for peak performance.
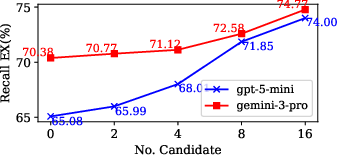
Figure 4: Recall Execution Accuracy on Spider2.0-Snow improves as multi-candidate generation increases candidate count.
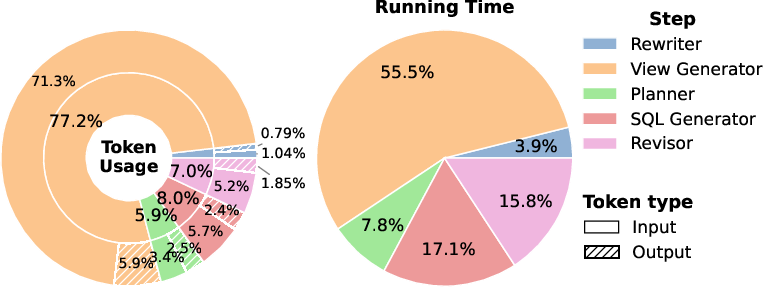
Figure 5: Token usage and runtime breakdown reveals agent view generation dominates computational cost, pinpointing optimization targets.
Error Taxonomy and Component Analysis
Error analysis indicates filtering and aggregation remain the dominant sources of residual failures (70%+), with schema-linking and syntax errors greatly reduced via execution feedback. The view generation agent is the principal cost bottleneck—accounting for up to 77% of tokens and 55% of runtime—highlighting the need for further chunking and parallelization optimizations.
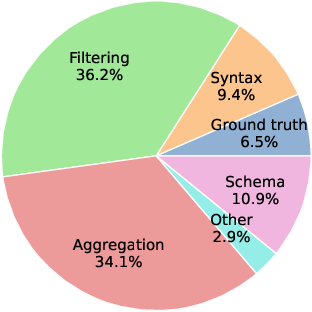
Figure 6: Error taxonomy of AV-SQL with Gemini-3-Pro emphasizes filtering and aggregation as the main error categories.
Hybrid LLM configurations reveal that homogeneous strong backbones across all agents yield the best performance; misalignment between CTE generator and SQL generator may degrade final EX, even when the SQL generator is powerful. Strategic heterogeneity can be cost-efficient if properly aligned with task decomposition.
Implications and Future Directions
AV-SQL demonstrates that robust Text-to-SQL in enterprise settings requires decomposition into agentic view synthesis, explicit chunk-level schema reasoning, and multi-agent iterative repair. Its framework is scalable to both standard benchmarks and extreme long-context schemas where traditional methods collapse.
Practically, AV-SQL’s modular reasoning enables fine-grained debugging and transparent provenance, facilitating deployment in production systems with traceability and partial query guarantees.
Theoretically, the approach motivates new research on chunkwise compositional reasoning, parallel agent orchestration, and heterogeneous LLM interaction for cost-optimal pipelines. The residual challenge in filter and aggregate logic points toward the need for richer intermediate representation and external knowledge integration.
Conclusion
AV-SQL is an agentic decomposition framework for Text-to-SQL that leverages chunk-level schema partitioning and validated CTE-based intermediate reasoning. It achieves strong execution accuracy and schema filtering reliability on both standard and enterprise-scale benchmarks. The methodology highlights modular error detection and repair, transforming SQL synthesis into a sequence of manageable, verifiable subtasks. Future developments should focus on optimizing agent workload distribution, refining filtering and aggregation mechanisms, and dynamically aligning LLM backbones within heterogeneous pipelines to scale further in real-world settings.