- The paper introduces TorchUMM, a unified multimodal model codebase that standardizes evaluation protocols, benchmark integration, and post-training methods.
- It demonstrates that post-training techniques can induce trade-offs between generation and understanding, challenging assumptions about model scale and unification.
- Empirical findings underline the importance of architecture, data composition, and controlled cross-task evaluation for achieving reliable multimodal performance.
TorchUMM: Unified Infrastructure for Multimodal Model Evaluation, Analysis, and Post-training
Introduction and Motivation
TorchUMM addresses a significant gap in unified multimodal model (UMM) evaluation and development. While recent advances in UMMs have yielded models capable of understanding, generating, and editing across textual and visual modalities, the heterogeneity of architectures and benchmarks has stymied systematic and reproducible cross-model comparisons. Existing evaluation practices are frequently benchmark-dependent, task-isolated, and inconsistent across model backbones. Critically, strong post-training gains on one dimension often induce unmeasured trade-offs elsewhere, resulting in a fragmented understanding of model capabilities. TorchUMM is introduced as a modular codebase and evaluation framework designed to unify interfaces for models, benchmarks, and post-training paradigms, substantially lowering the barrier for holistic, comparable, and reproducible multimodal modeling research.
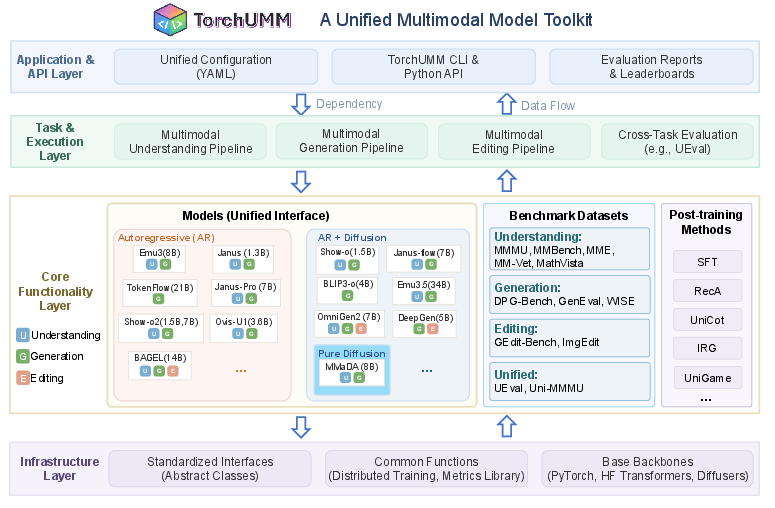
Figure 1: Overview of TorchUMM’s architecture, showcasing unified abstraction layers for backbones, tasks, benchmarking, and extensibility.
System Design and Model Support
TorchUMM is architected around four decoupled layers, facilitating extension and rigorous reproducibility:
- Infrastructure layer: Provides extension utilities and integration points with external libraries.
- Core Functionality: Wraps UMM backbones, datasets, and post-training methods in standardized abstract interfaces.
- Task and Execution: Implements unified pipelines for multimodal understanding, generation, editing, and cross-task workflows.
- Application and API: Offers unified configuration, CLI/Python APIs, and automatic evaluation reporting.
The codebase supports 14 diverse model families, including autoregressive, autoregressive+diffusion hybrids, and fully diffusion-based models, with backbones such as Bagel, OmniGen2, Emu3/3.5, Janus and variants, Show-o/Show-o2, BLIP3-o, TokenFlow, DeepGen, and MMaDA. The adapter-based architecture enables drop-in extension to new backbones with minimal engineering investment.
Benchmark and Dataset Integration
TorchUMM’s benchmark coverage is notably comprehensive. For generation, it integrates DPG-Bench (evaluating visual detail fidelity), GenEval (testing compositional generalization), and WISE (world knowledge-aware semantic alignment). Understanding is probed via MMMU, MMBench, MME, MM-Vet, and MathVista, spanning high-level cognition and low-level perception. Editing is assessed through GEdit-Bench and ImgEdit, both supporting fine-grained semantic manipulation and multi-turn dynamics. Unified and cross-task evaluation is enabled through benchmarks such as UEval and Uni-MMMU, which tightly couple understanding with instruction-conditioned generation. The framework supports both single- and multi-stage pipelines, facilitating controlled post-training and immediate evaluation with standardized scoring protocols.
Empirical Findings: Comparative Model Analysis
Generation
Model performance varies substantially by metric. DeepGen achieves the highest compositional generation scores (GenEval 86.59), whereas Emu3.5 leads on knowledge-intensive prompts (WISE 0.633), albeit with a distinct generation pipeline. OmniGen2 and Bagel demonstrate competitive performance on DPG-Bench (84.5, 84.1), while BLIP3-o provides a strong GenEval showing regardless of its compact 4B parameter regime. Importantly, model scale is not predictive of performance; smaller backbones occasionally outscore larger models on complex metrics, highlighting the primacy of architecture and data over mere size.
Understanding
Bagel outperforms all baselines across cognitive and perceptual understanding, consistently achieving the highest marks across MME perception/cognition, MMMU, MMBench, MM-Vet, and MathVista. However, a major finding is the persistence of a perception-cognition gap and a trade-off between generation and fine-tuned understanding. For example, Emu3.5, a leader in generation, produces the weakest visual perception scores among understanding-enabled models, demonstrating a fundamental tension in current UMM architectures between generative and cognitive capabilities.
Instruction-based Image Editing
Among editing-capable models, Emu3.5 and DeepGen dominate both GEdit-Bench and ImgEdit, especially in multi-step, instruction-based settings. A systematic gap is observed between semantic correctness and perceptual quality—most models maintain realism but fail precise semantic edits, particularly in multi-turn scenarios. Only Emu3.5 and DeepGen approach human-desired alignment between structure and task adherence. Cross-lingual consistency is also shown to be model-dependent, with notable variance across English and Chinese editing tasks.
Unified and Cross-task Evaluation
Current UMMs demonstrate marked deficiencies on tightly integrated understanding--generation tasks. Even top models achieve near-zero on complex visual synthesis tasks requiring iterative state transitions (e.g., Maze image generation, Sliding Puzzle), revealing architectural limitations in explicit state tracking and controllable, progressive generation.

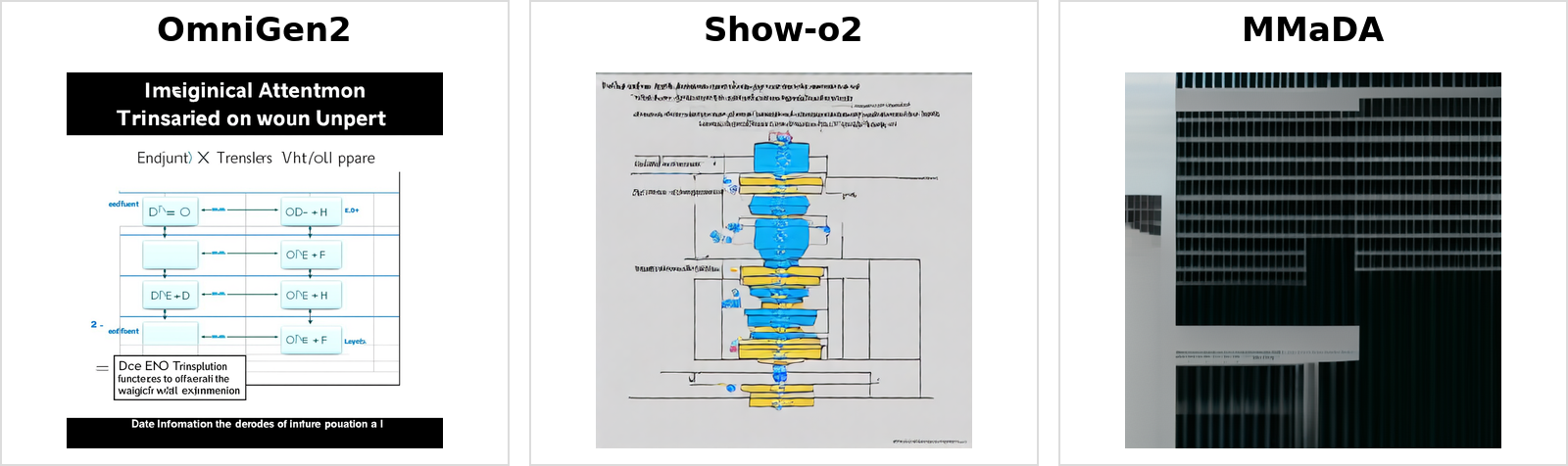
Figure 2: Complex UEval prompts reveal that even highly unified architectures often fail on procedural decomposition or technical diagram synthesis, with only OmniGen2 consistently showing approximate structural alignment.
Holistic Analysis of Post-training Effects
A unifying contribution of TorchUMM is the capacity for systematic, cross-model post-training analysis. The authors demonstrate that supervised fine-tuning (SFT) and other post-training techniques frequently induce nontrivial negative transfer between tasks, with strong gains in one area often coinciding with degradation in others (e.g., SFT drives Bagel's WISE score from 0.399 to 0.227 and degrades DPG performance, while TokenFlow's DPG plummets after SFT). IRG and UniGame display high variance and sometimes catastrophic interference, whereas RecA and UniCoT offer more controlled adaptation. Task-specific post-training gains are thus non-robust and rarely generalize, emphasizing the need for unified, cross-domain evaluation in model deployment and optimization.
Architectural Unification and Consistency
The effect of architectural unification is investigated through controlled paired comparisons and prompt variation robustness studies. Notably, the degree of unification does not correlate directly with downstream capability: the least unified system (OmniGen2) outperforms more "unified" baselines (Show-o2, MMaDA) on demanding procedural/technical benchmarks. Further, strong unification recipes can induce increased inconsistency relative to their base backbones, as observed in embedding- and latent-level analysis.
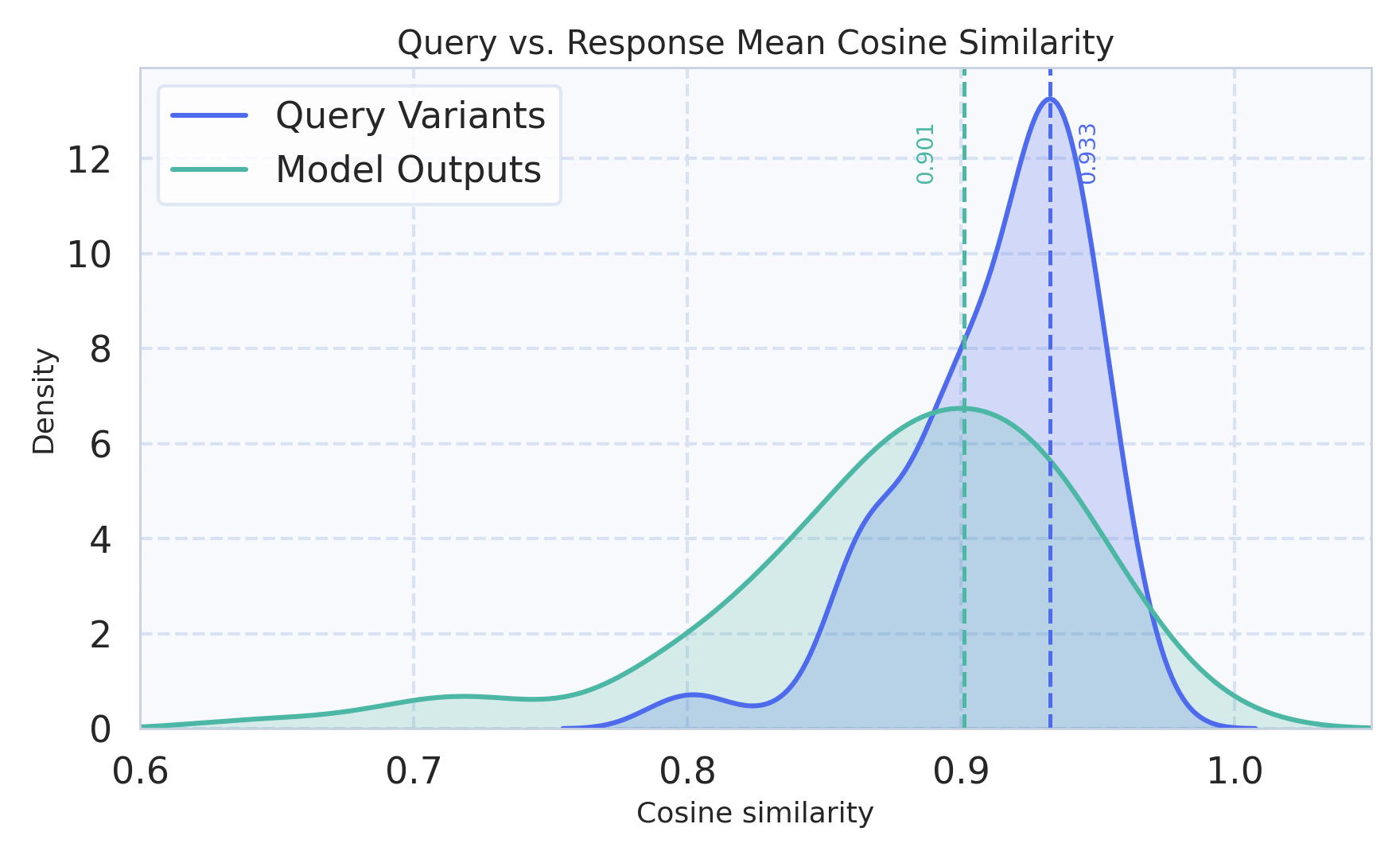
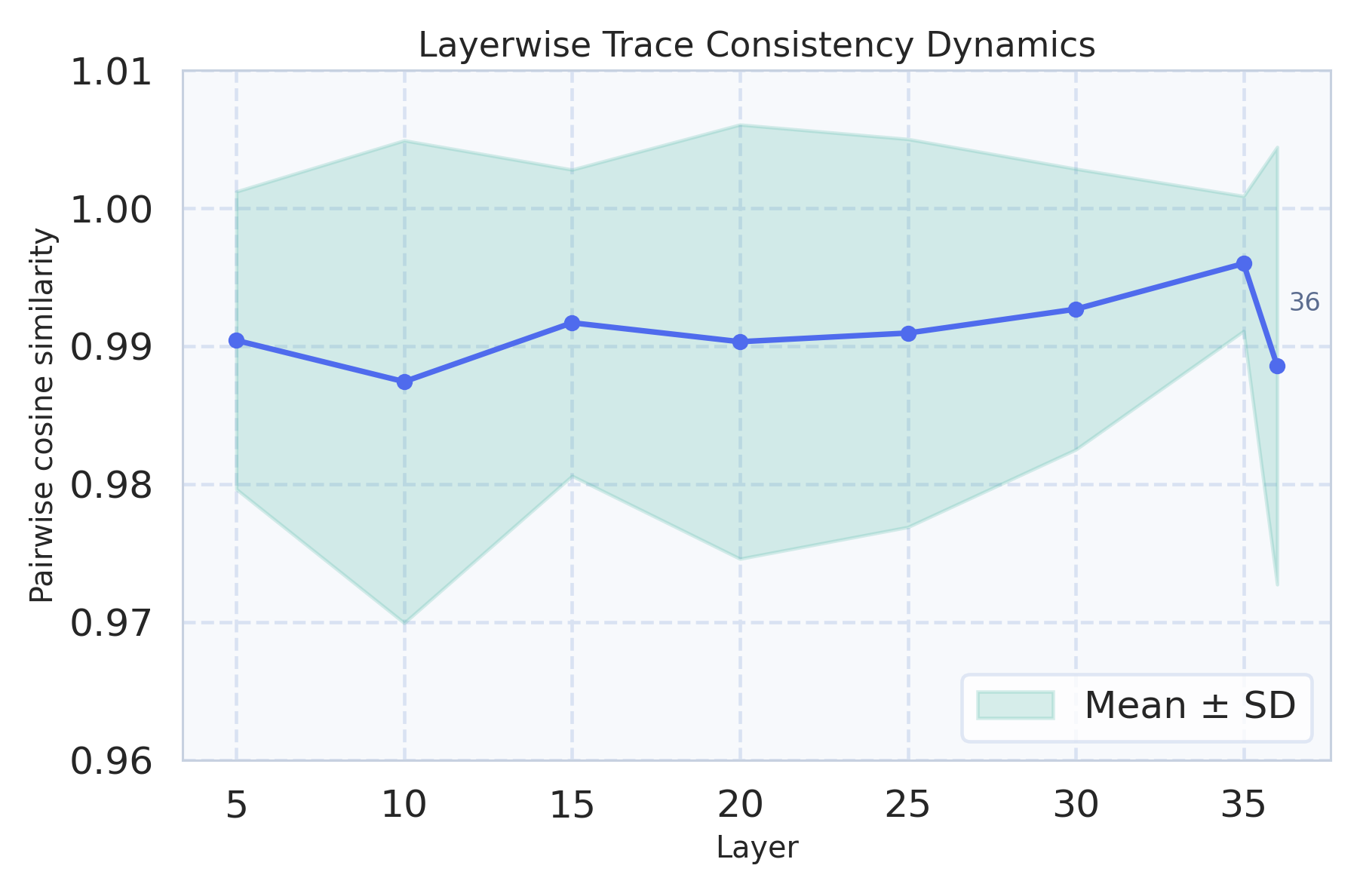
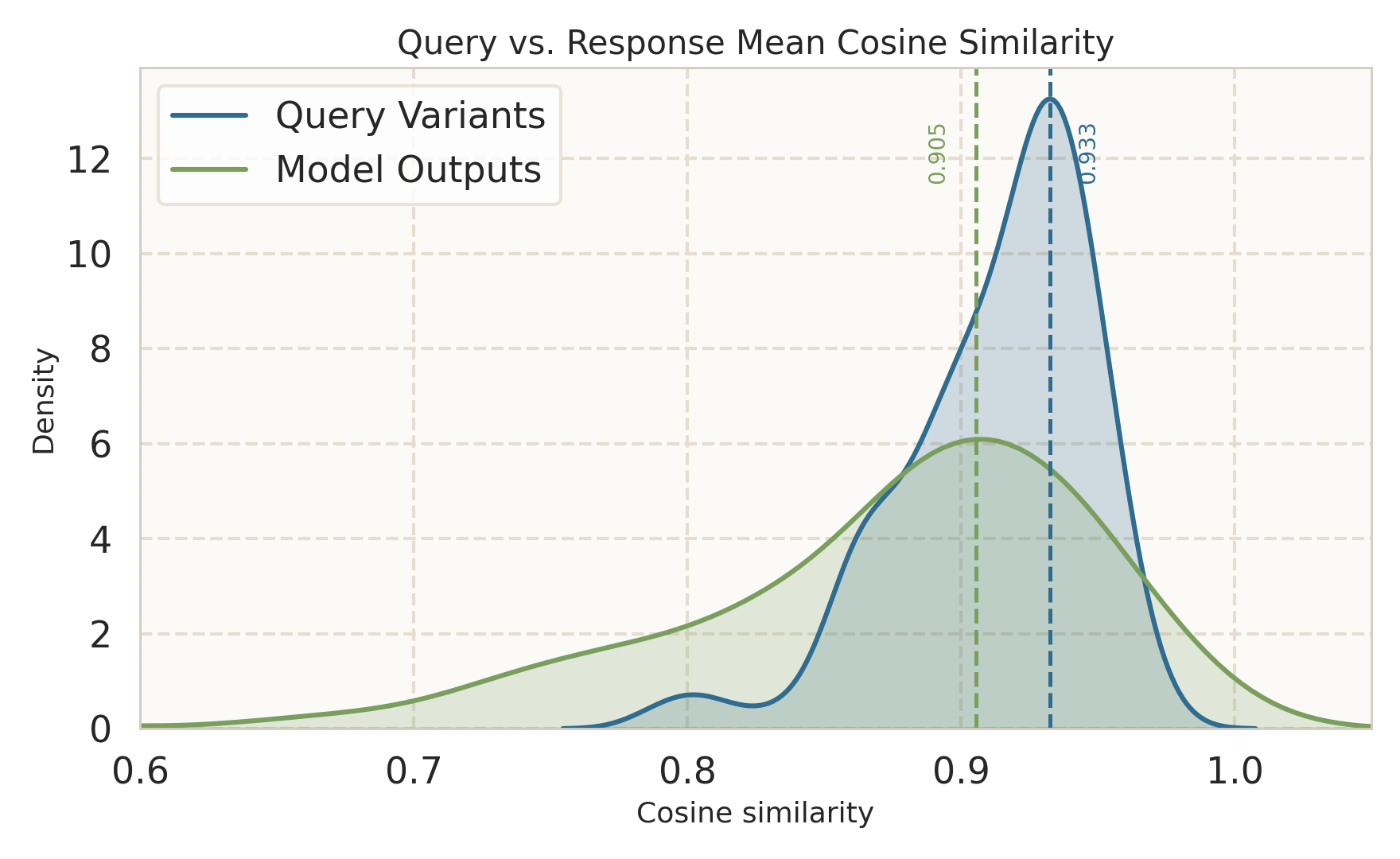
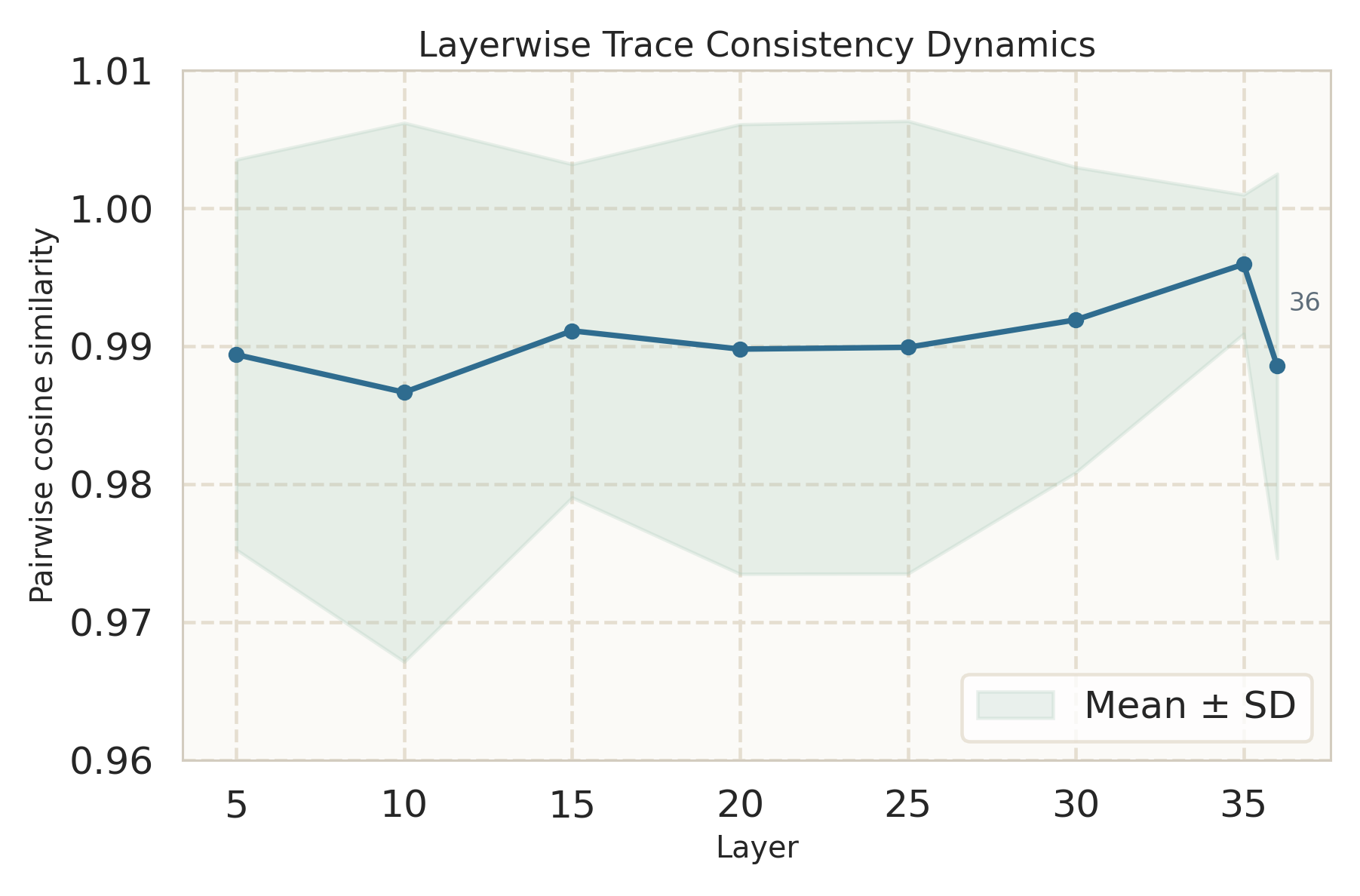
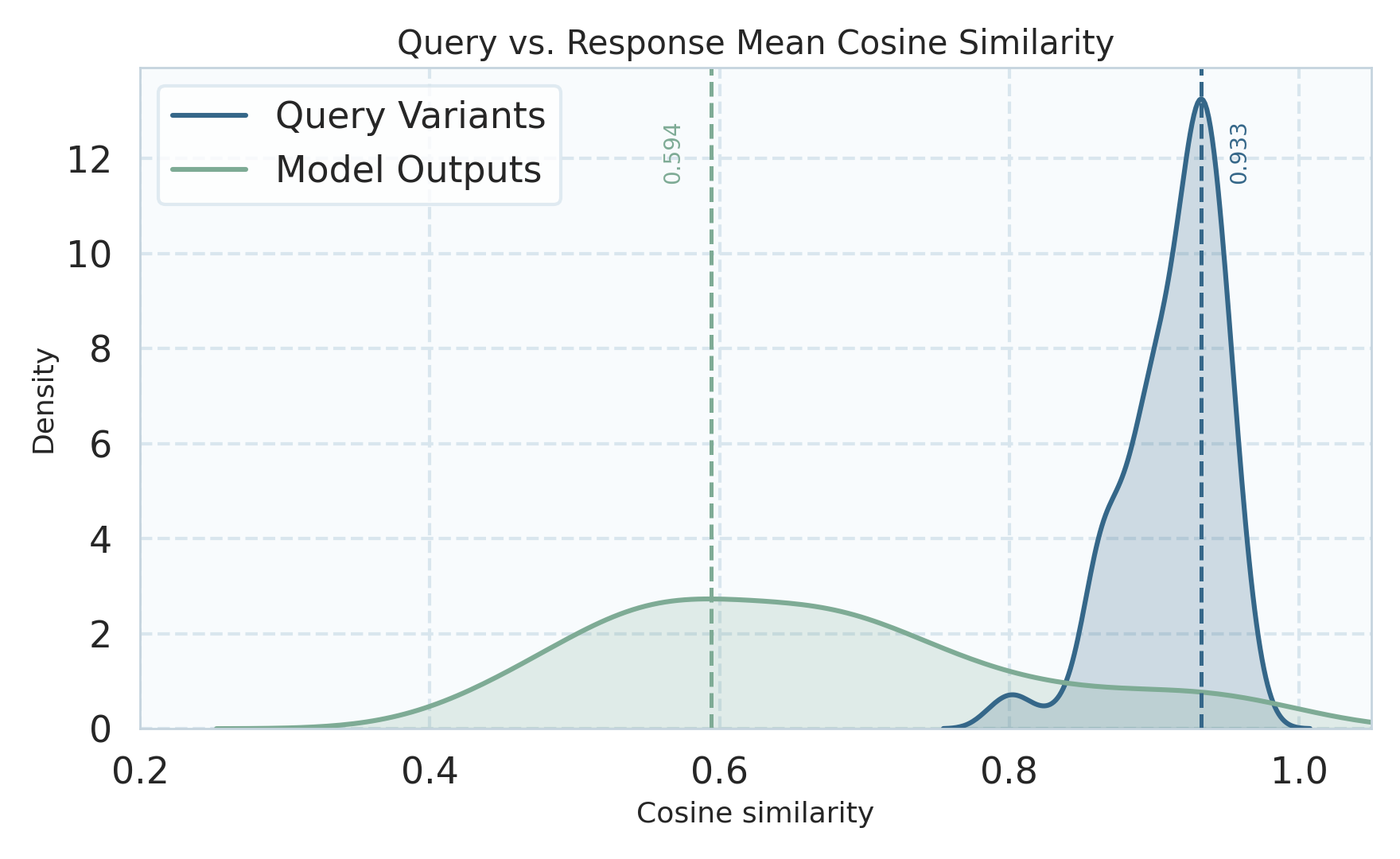
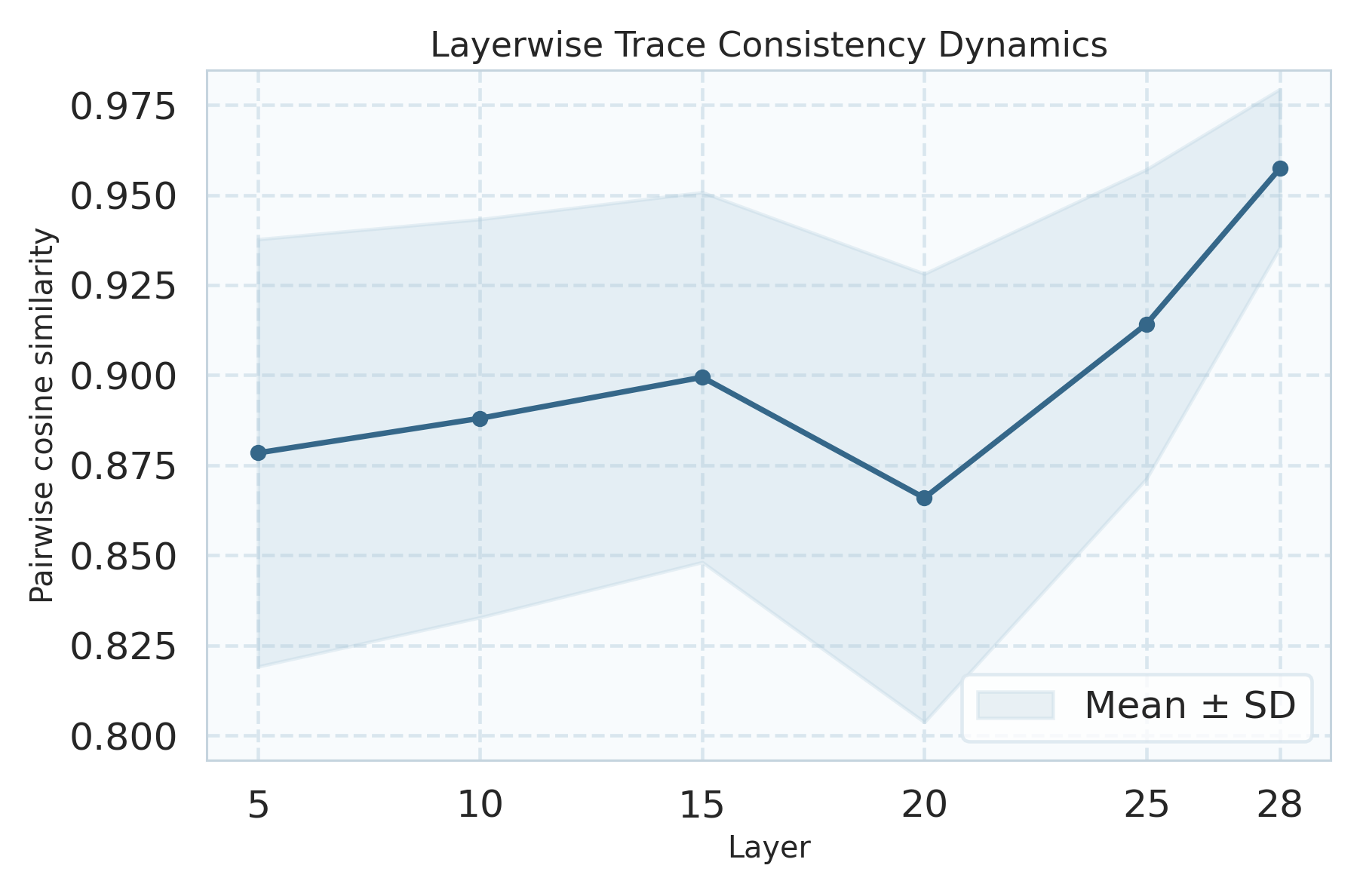
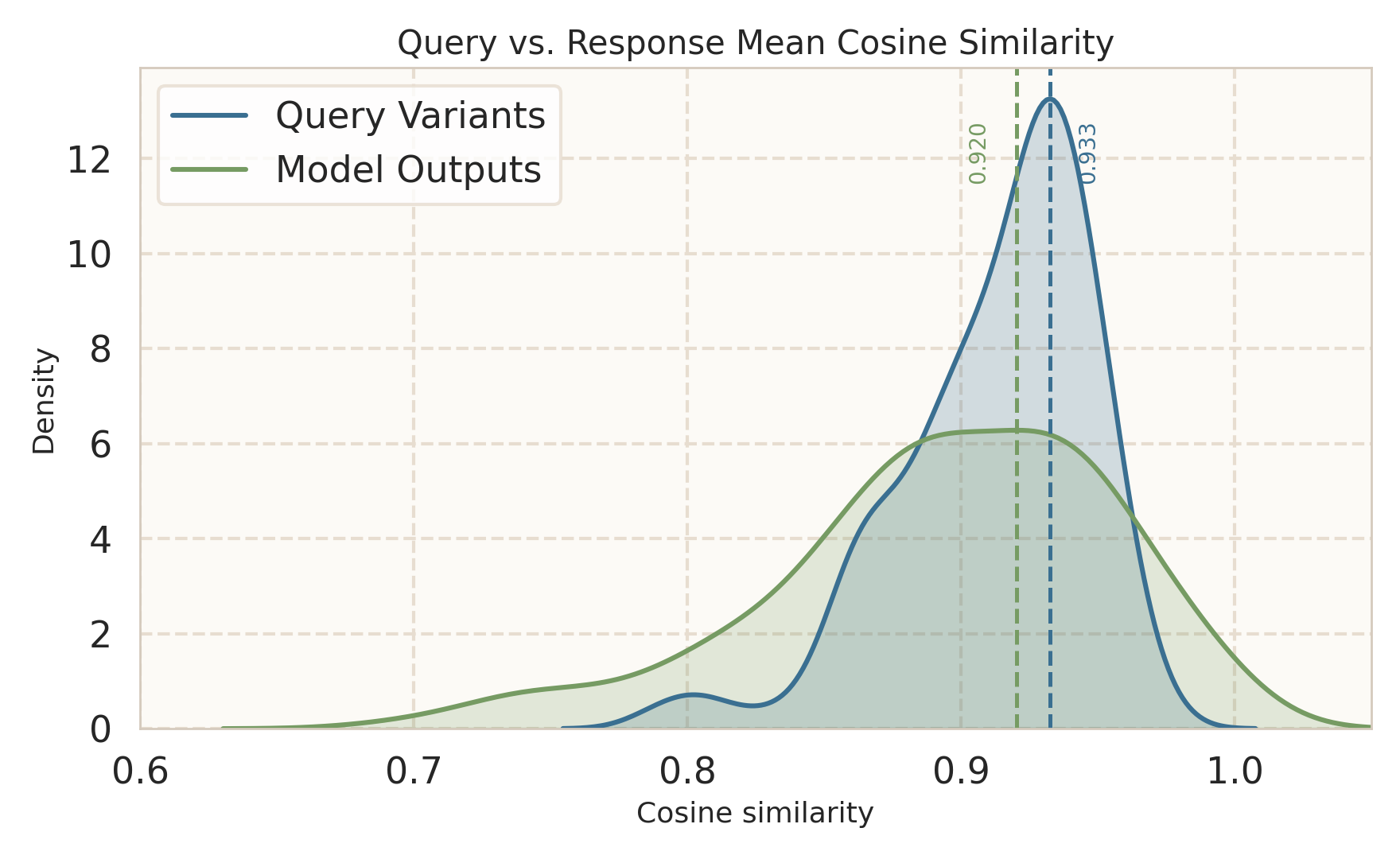
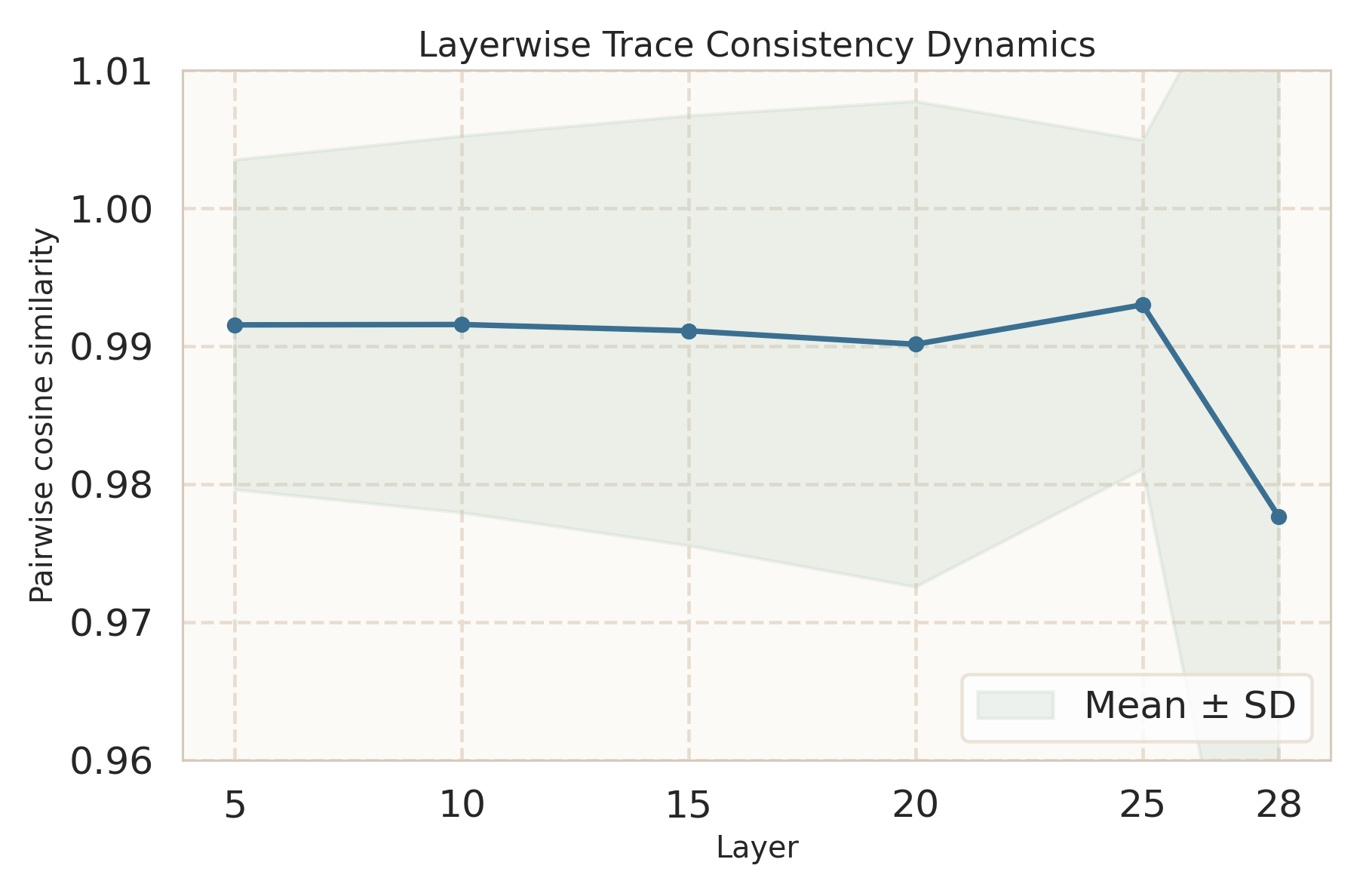
Figure 3: Query-variation consistency analysis shows that aggressively unified models (e.g., Show-o2) diverge more from their initial backbone's latent and behavioral stability compared to more modular designs.
The implications are two-fold: (1) naive increases in architectural sharing do not guarantee improved multimodal coupling—interference and optimization instability are pervasive; (2) the effect of unification is highly sensitive to backbone quality, data, and training protocol, demanding carefully controlled studies to isolate architectural causal impact rather than drawing conclusions from confounded global differences.
Codebase Extensibility and Practical Impact
TorchUMM is designed for scalable extension, with new models or benchmarks requiring only minimal addition of backbone adapter subclasses or handler scripts and appropriate configuration files. Training logic is decoupled from evaluation, enabling rapid iteration and thorough ablation. This reduces the engineering cost of large-scale, holistic model assessment and accelerates reproducibility and model deployment in research and applied settings.
Theoretical and Practical Implications, Future Directions
TorchUMM’s findings systematically challenge the hypothesis that increased unification or parameter scale alone will solve cross-modal integration or controllable post-training. Instead, its evidence suggests that cross-task interference, backbone selection, and data composition are first-order determinants of real-world UMM performance. The field must thus move toward explicit disentanglement of architectural choices, more rigorous benchmark diversity, and optimization procedures robust to interference. TorchUMM’s unified framework enables such controlled studies and will be consequential as the community pushes toward more reliable and maintainable world models for downstream deployment, AI alignment, and complex multimodal reasoning tasks.
Conclusion
TorchUMM constitutes a rigorous, extensible infrastructure for the evaluation, analysis, and post-training of UMMs. Its empirical results and architectural analyses provide essential context for interpreting performance trade-offs in modern multimodal modeling. Key takeaways include the unreliable benefit of naive post-training, the disconnect between unification and performance, and the value of cross-benchmark, cross-task evaluation. TorchUMM is positioned to catalyze future research at the intersection of multimodal pretraining, unified reasoning, and robust, controllable model deployment.

