- The paper demonstrates that LoRA adaptation matrices, when analyzed via 2D-DCT, consistently require only ~33% coefficients to recover 90% of spectral energy across tasks.
- The paper shows that low-frequency retention yields minimal accuracy loss, as seen in tasks like SST-2, while reducing storage up to 10-fold.
- The paper reveals task- and layer-dependent spectral sensitivity, suggesting that frequency masking can serve as an effective regularizer for model adaptation.
SpectralLoRA: A DCT-Based Spectral Analysis of LoRA Adaptation
Introduction
This work offers a systematic spectral analysis of LoRA-based parameter-efficient fine-tuning (PEFT) for transformer models, specifically targeting the frequency-domain structure of LoRA weight adaptations. Drawing from the analogy with natural signal processing, the study investigates whether LoRA adaptation matrices are, similarly, dominated by low-frequency components, and if aggressive high-frequency filtering can yield substantial storage compression and potential regularization benefits without substantial accuracy loss. The investigation extends across GLUE benchmark tasks (SST-2, MNLI, CoLA, QQP) and two model architectures (BERT-base, RoBERTa-base), utilizing a 2D Discrete Cosine Transform (DCT) to dissect the spectral energy distribution of trained weight updates.
Methodology
LoRA adapters were trained in a uniform setting: both BERT-base and RoBERTa-base models, with adaptation matrices (query and value projections) decomposed into low-rank forms and subsequently analyzed via DCT. For each trained ΔW, 2D-DCT is applied, and cumulative spectral energy as a function of retained coefficient percentage (k) is computed. The key ablation involves masking the (100−k)% lowest-magnitude coefficients in the DCT domain, reconstructing the weight updates with the inverse DCT, and empirically evaluating model performance on validation data. The core metric is the accuracy/score drop at defined k values, with comparisons drawn against full LoRA and conventional baselines.
Main Results
Spectral Compressibility and Parameter Efficiency
The core finding is the universal compressibility of LoRA updates: on average, retaining only 33% of DCT coefficients recovers 90% of total spectral energy. Notably, even at drastically smaller frequency budgets (k=10%), SST-2 exhibits a minimal accuracy drop, just $1.95$ percentage points, while storage is reduced 10-fold. Strikingly, on three out of eight model-task pairs, frequency-masked SpectralLoRA (k=50%) improves over full LoRA, indicating high-frequency components introduce adaptation noise.
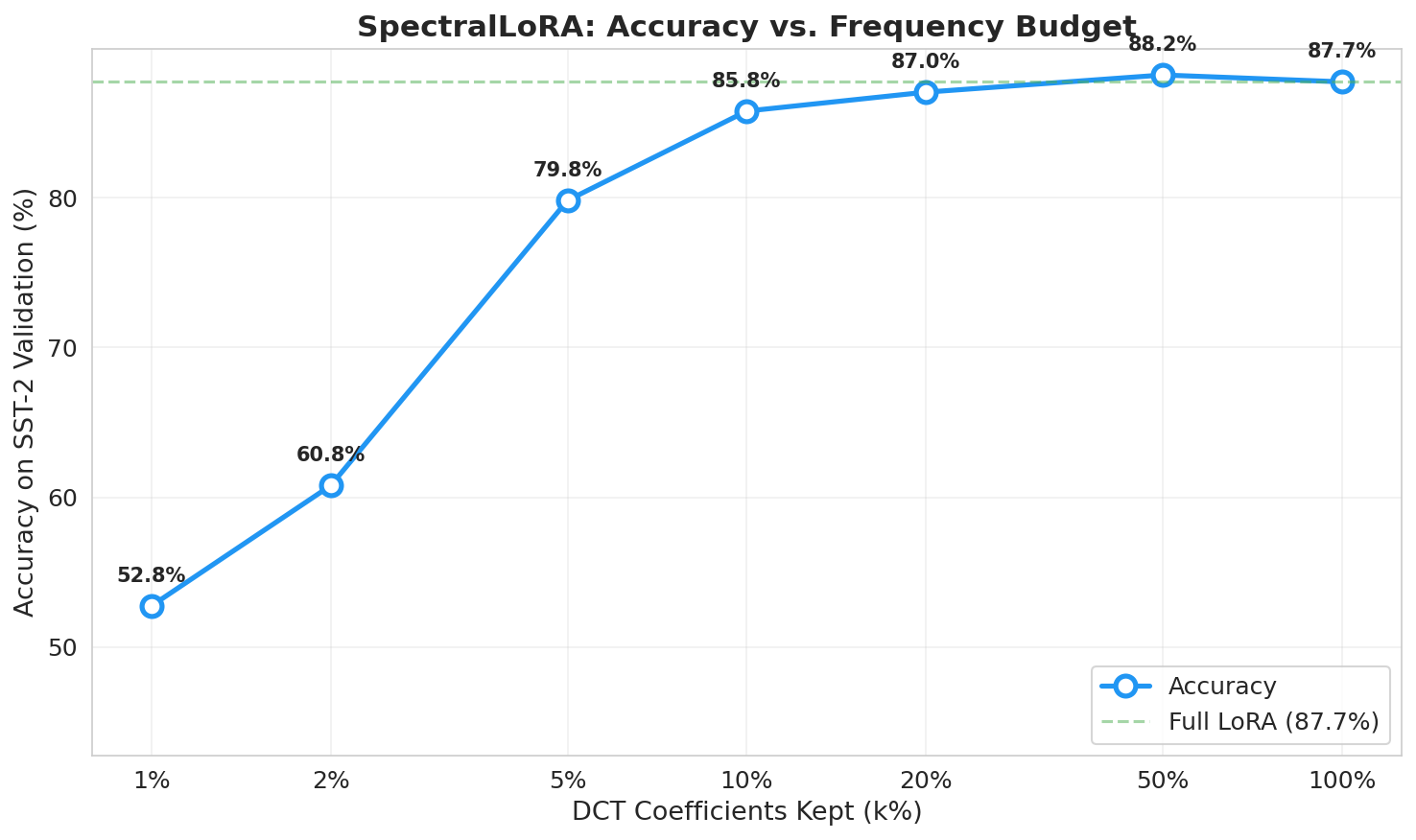
Figure 1: SpectralLoRA outperforms and regularizes LoRA at intermediate frequency budgets on SST-2, achieving greater than baseline accuracy at k=50%.
Cross-Task and Model Differences
The DCT energy budget required for strong downstream accuracy is task dependent. SST-2 (sentiment) and QQP (paraphrase) tasks, which are less complex, are markedly more spectrally compressible than tasks such as MNLI (NLI) and CoLA (linguistic acceptability). This difference is quantifiable, with MNLI requiring over k0 more frequency budget than SST-2 for comparable accuracy retention. RoBERTa-base adapters consistently outperform BERT-base in spectral compressibility by a margin of 1.5--2.5pp, correlating with the hypothesis that pretraining quality (as in RoBERTa) yields smoother adaptation updates.
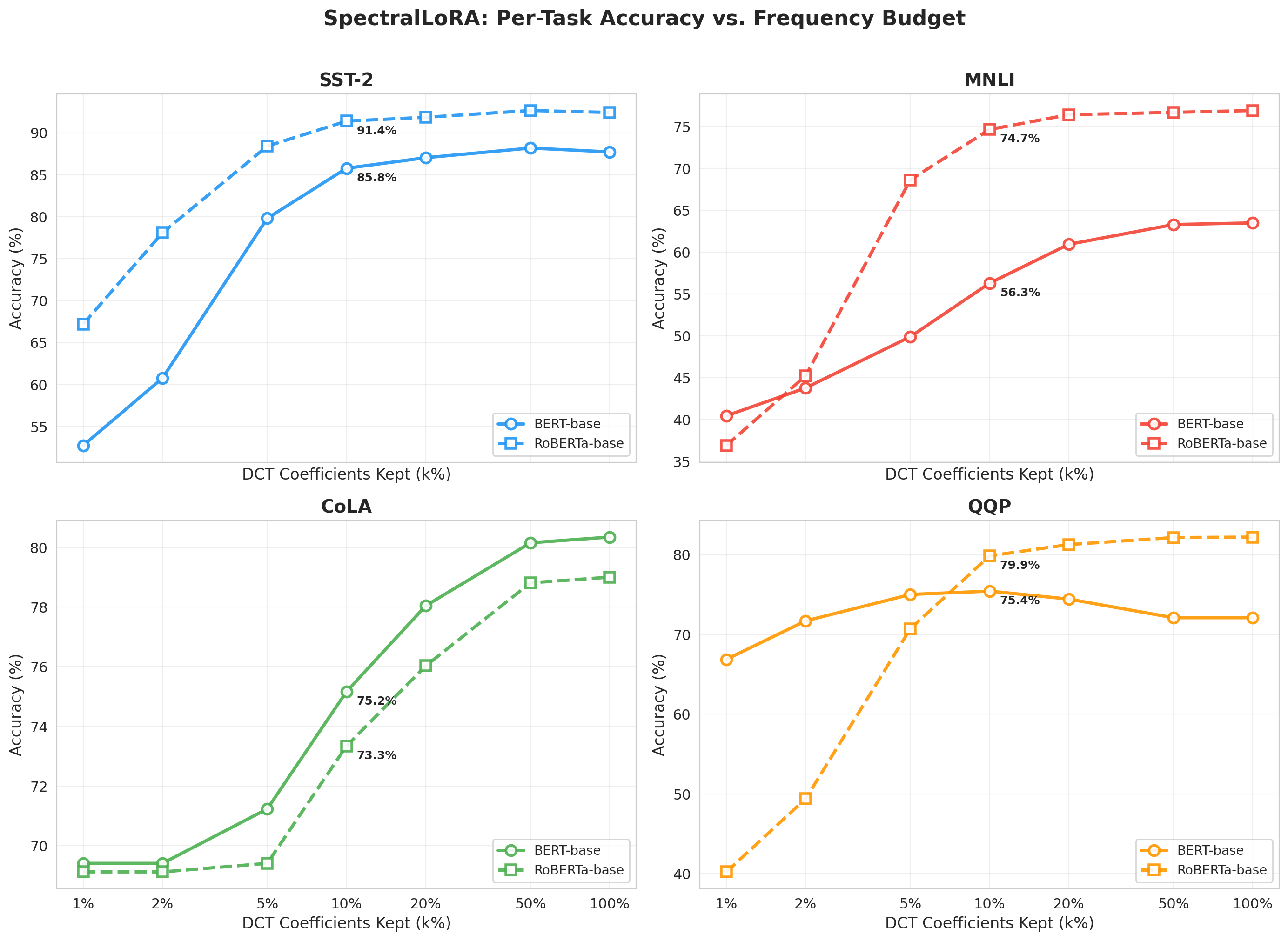
Figure 2: Per-task accuracy plotted against frequency budget evidences that RoBERTa typically requires fewer DCT coefficients across GLUE tasks, affirming its higher spectral compressibility.
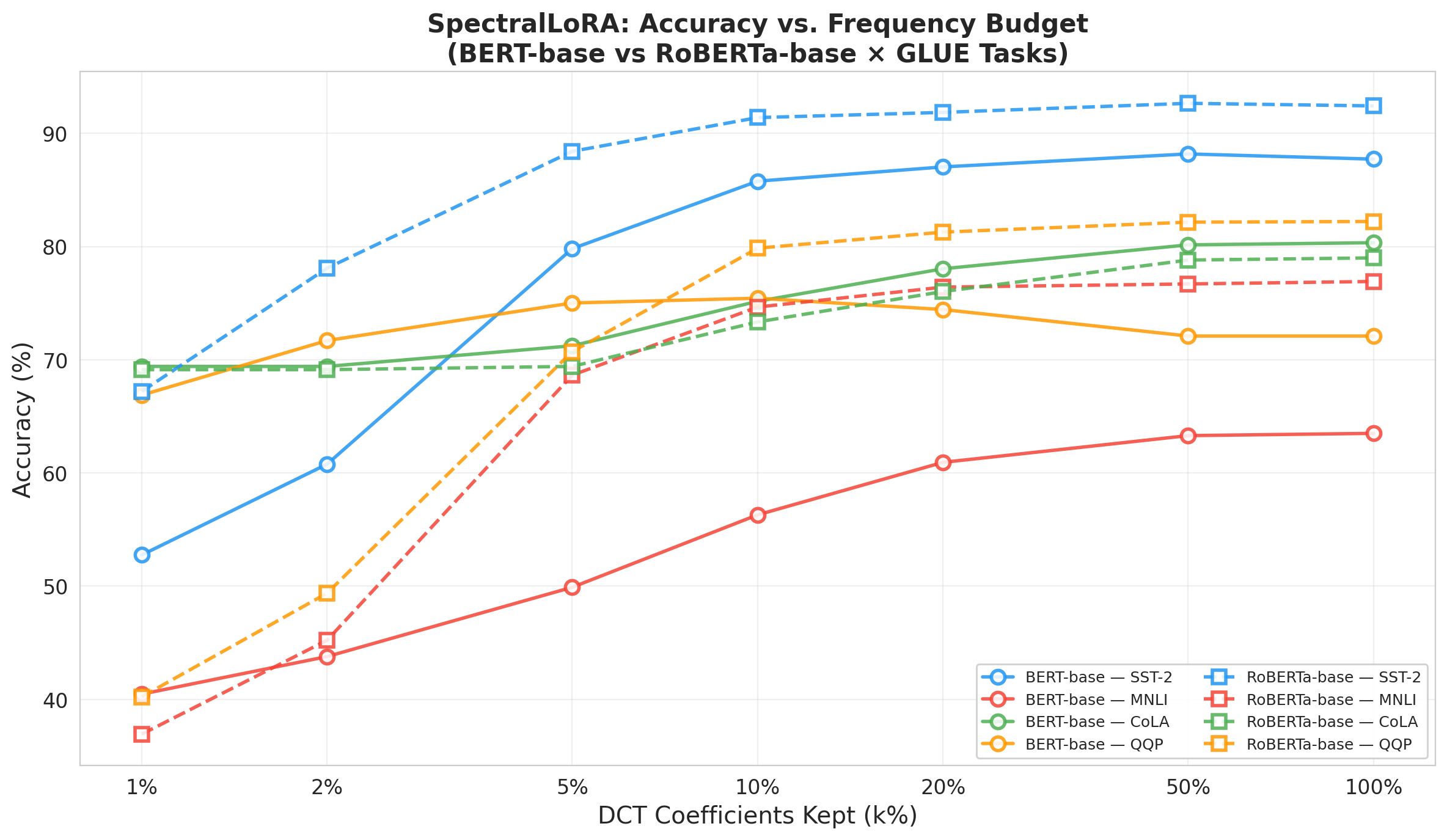
Figure 3: Overlayed task curves highlight the increased spectral sensitivity (i.e., accuracy drop) for more complex tasks (e.g., MNLI red, bottom), further outlining cross-task variability.
The ∼33% Spectral Constant
Across all 2 models, 4 tasks, and 24 layers, the percentage of DCT coefficients required to recover 90% of energy is remarkably stable (31--35%), suggesting a universal empirical constant underlying LoRA's adaptation behavior. This holds regardless of layer depth and task class and suggests fixed k1-budget post-processing may be generically viable for compression.
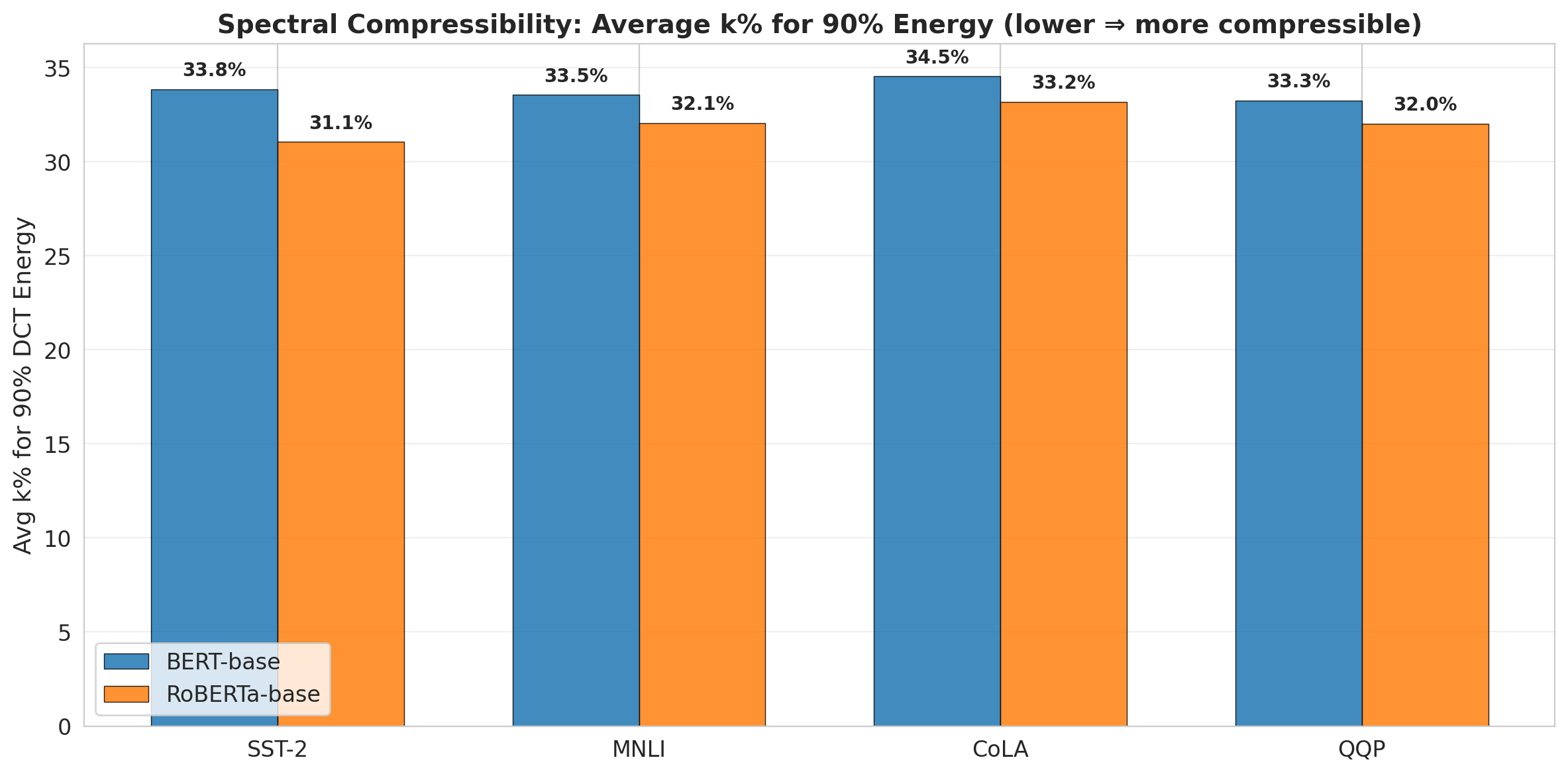
Figure 4: Average k2 at 90% energy visualizes the universal compressibility, with RoBERTa yielding consistently lower k3 across all tasks than BERT.
Layer-wise Spectral Analysis
The analysis reveals that spectral sparsity is not homogeneous across layers. Upper transformer layers (e.g., Layer 11 query) demand lower k4 for 90% energy (26.6%) compared to lower layers (Layer 0, 38.8%). Value projections show non-monotonic patterns of compressibility, indicative of distinct adaptation roles between query and value modules.
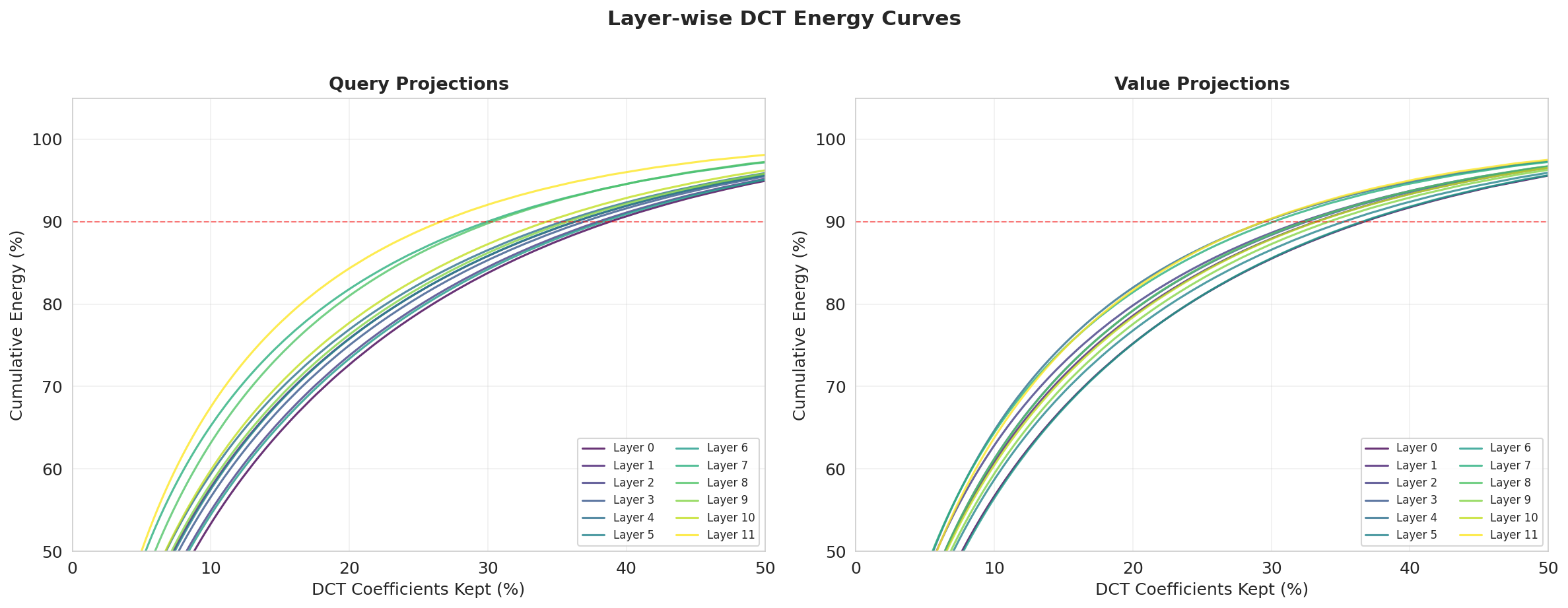
Figure 5: Cumulative DCT energy per layer surfaces depth-dependent spectral adaptation, with late layers compressing more efficiently.
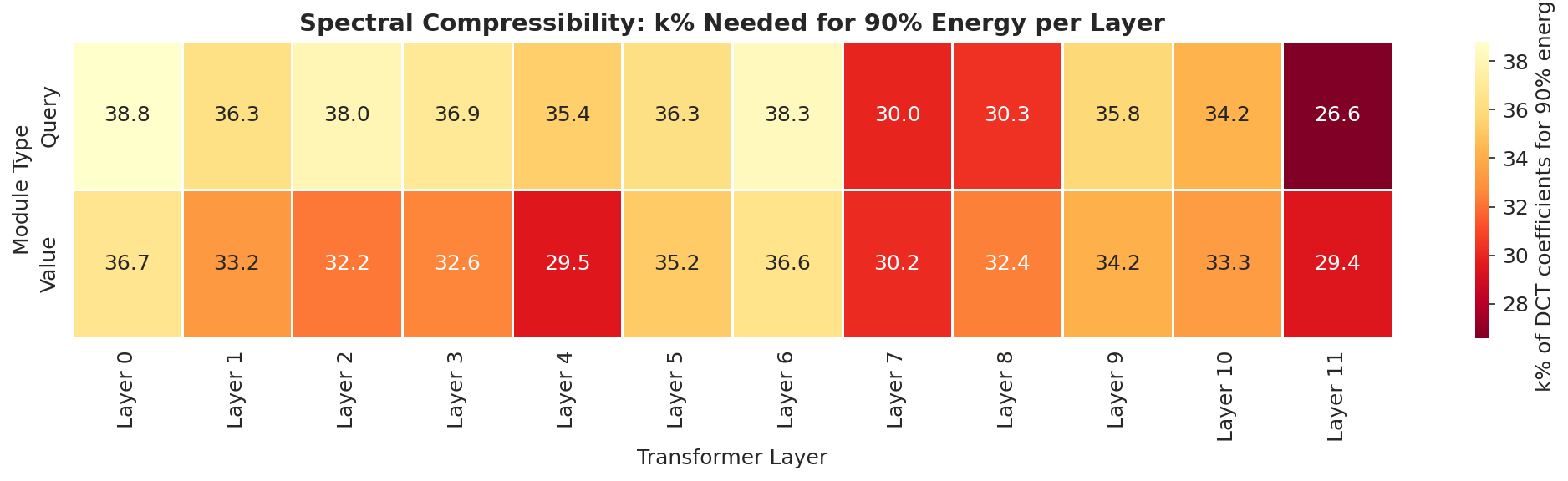
Figure 6: Layer-frequency heatmaps quantify layer and module compressibility, advocating for layer-specific frequency budgets.
Implications and Theoretical Significance
These precise numerical results challenge the sole reliance on spatial-domain or rank-based LoRA tuning. SpectralLoRA introduces frequency budget (k5) as an orthogonal control axis for PEFT, with strong empirical evidence for continuous, post-hoc compression and intrinsic regularization. The correlation between spectral compressibility and pretraining rigor suggests that spectral analysis could serve as a diagnostic for pretrained model quality. Task-dependent spectral sensitivity implies that coarse adaptation (low-frequency) suffices for simple semantic tasks, but complex reasoning demands retention of fine spectral detail.
In practice, aggressive spectral filtering can yield substantial reductions in deployment storage at negligible accuracy cost—and, in low-data regimes, can even act as a regularizer for overparameterized adapters. Adoption of frequency-masked compression offers significant promise for on-device inference or distributed adaptation.
Limitations and Future Directions
All findings pertain to adaptation on 5,000 training samples per task and are restricted to encoder transformer query/value projections. Other architectures (e.g., decoder-only LLMs) and higher data regimes may alter quantitative outcomes. Theoretical characterization of the “spectral constant” remains outstanding, as does the exploration of spectral learning for feedforward and non-attention modules. Future work should investigate native frequency-domain LoRA training (FD-LoRA) and extend the framework to broader model classes and adaptation setups. Layer-adaptive k6-budget assignments, informed by the detailed layer analysis, represent an immediate avenue for improved accuracy/compression tradeoffs.
Conclusion
SpectralLoRA offers an empirically rigorous framework for post-hoc spectral compression of LoRA adapters, anchored by the discovery of a universal k7 DCT spectral constant and task-/architecture-driven spectral variability. The findings motivate rethinking PEFT compression and regularization along a frequency-domain axis, with direct implications for practical adapter deployment and theoretical understanding of task adaptation in deep transformers.