- The paper introduces VidAudio-Bench, a novel multidimensional evaluation framework targeting fine-grained video-to-audio (V2A) and video-text-to-audio (VT2A) generation.
- It segments audio tasks into SFX, music, speech, and singing, employing specialized metrics for audio fidelity, synchronization, and semantic alignment.
- Experimental results highlight robust performance in SFX and instrumental music generation while revealing significant challenges in speech and singing generation due to trade-offs between visual grounding and instruction following.
VidAudio-Bench: A Comprehensive Benchmark for Fine-Grained Evaluation of Video-to-Audio and Video-Text-to-Audio Generation
Benchmark Scope and Motivation
The VidAudio-Bench framework addresses a persistent evaluation deficit in multimodal audio generation, particularly in the video-to-audio (V2A) and video-text-to-audio (VT2A) paradigms. Existing benchmarks have predominantly applied monolithic, distribution-level metrics that disregard the heterogeneity of audio tasks — notably the distinct requirements posed by sound effects (SFX), music, speech, and singing. Current practices inadequately capture fine-grained attributes such as lip synchronization, semantic alignment, and task-specific generative fidelity. VidAudio-Bench is constructed to enable a multi-perspective, category-aware analysis, reflecting recent advances and necessities in modeling frameworks, including unified multimodal diffusion transformers and chain-of-thought guided LLM-based generation.
Dataset Organization and Task Taxonomy
VidAudio-Bench comprises 1,634 carefully curated, high-resolution, and audio-stripped video clips, distributed across four primary audio generation tasks: SFX, music (with Instrumental Performance and Background Music as subtypes), speech, and singing. The dataset leverages large-scale, publicly available sources (e.g., VGGSounder for SFX/instruments, HarmonySet for BGM, AVSpeech for speech, and Acappella for singing), filtered via strict criteria to ensure clear visual grounding and unambiguous audio-visual correlation.
The SFX subset spans 10 major categories and 29 subcategories, presenting diverse and balanced audit-visual event coverage.
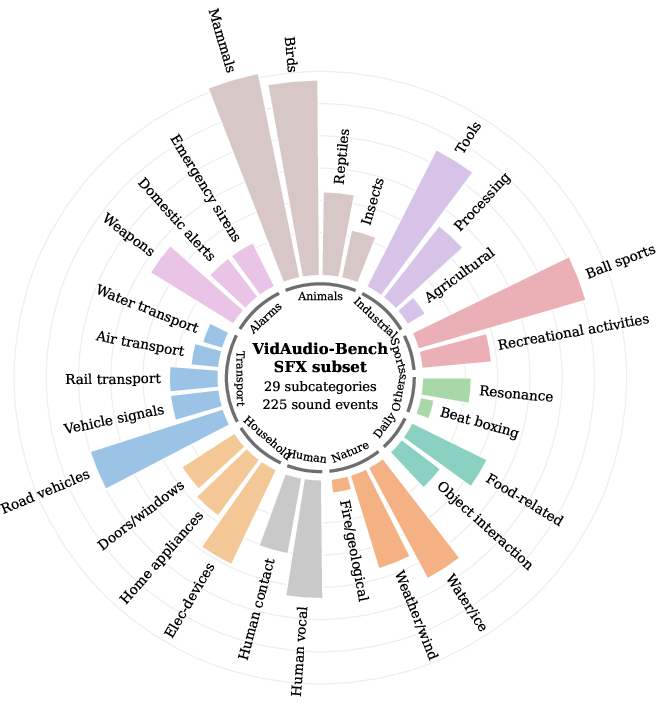
Figure 1: Distribution of sound effects data, highlighting the categorical and subcategorical diversity utilized for evaluation.
Instrumental music is further stratified by instrument classes, and a detailed demographic analysis is performed for speech and singing (e.g., age and gender distributions).
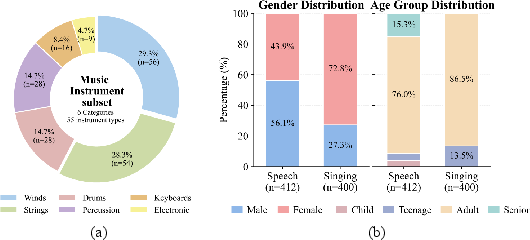
Figure 2: (a) Category breakdown of the Instrument Performance subset; (b) demographics for Speech and Singing categories.
V2A vs. VT2A Paradigms
A salient contribution is the explicit contrast between V2A (video-only, with minimal task-level instructions) and VT2A (video and dense visual caption input) generation paradigms. The VT2A setup employs a zero-information-leak protocol, utilizing vision-LLMs (Qwen3-VL) to generate fine-grained, audio-agnostic scene descriptors, thereby disentangling visual understanding from explicit acoustic label leakage. Human/LLM validation confirms high semantic retention in VT2A-generated prompts for SFX, BGM, and speech, while singing remains more challenging.
Multi-Dimensional, Reference-Free Evaluation Framework
VidAudio-Bench introduces a comprehensive evaluation suite distributed over 13 dimensions, organized along three principal axes: Audio Quality (AQ), Video-Audio Consistency (VAC), and Text-Audio Consistency (TAC). The suite integrates both signal-level and semantic metrics:
- AQ: Audio-MAE-based Fréchet Distance for fidelity, Audiobox-Aesthetics for production quality, STOI-Net for (non-intrusive) intelligibility, a normalized Musicality Score (integrating Pitch Class Histogram Entropy, Grooving Pattern Similarity, Empty Beat Rate), and DNSMOS-Pro/SingMOS-Pro for neural MOS estimation.
- VAC: Event-level (DeSync) and lip-level (LatentSync) synchronization, rhythmic alignment for music/BGM, semantic correspondence in a FreeBind-augmented embedding space, and demographic/affective (emotion, intensity) alignment via MLLM-judged prompts.
- TAC: CLAP-based audio-text embedding alignment and instruction-following verification through LLM-judge protocols.
The framework is realized via an MLLM-as-a-Judge model for advanced dimensions, employing multi-step reasoning for cross-modal interpretability.
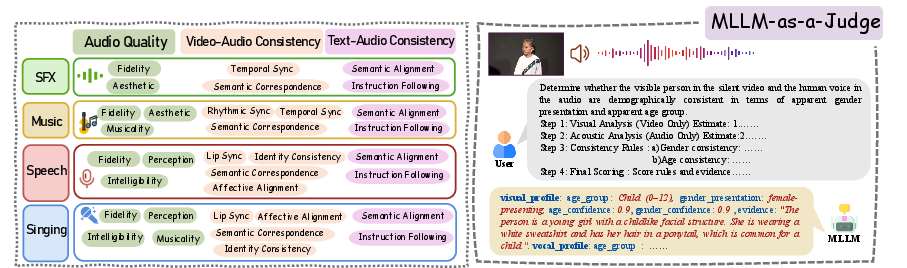
Figure 3: System-level overview of the VidAudio-Bench evaluation architecture, outlining task-specific metric groupings and LLM-judged alignment dimensions.
Experimental Results and Diagnostic Insights
A comprehensive benchmarking campaign covers eight SOTA V2A/VT2A models (AudioX, FoleyCrafter, HunyuanVideo-Foley, Kling-Foley, MMAudio, ReWaS, ThinkSound, UniFlow-Audio) and three specialized V2M models. VidAudio-Bench results decisively demonstrate task-domain difficulty stratification: models display robust SFX and (to a lesser extent) instrumental music generation, while speech and singing generation remain substantially underperforming — reflected both in objective metrics (e.g., low intelligibility and sync) and human-aligned perceptual scores.
Task-wise radar plots further elucidate the divergent strengths and trade-offs among models: for example, Kling achieves maximal video-audio semantic alignment, while AudioX and ThinkSound lead in aesthetic and perceptual quality. No model presents Pareto-optimality; models with improved visual consistency do not necessarily retain high fidelities or category-level instruction compliance.
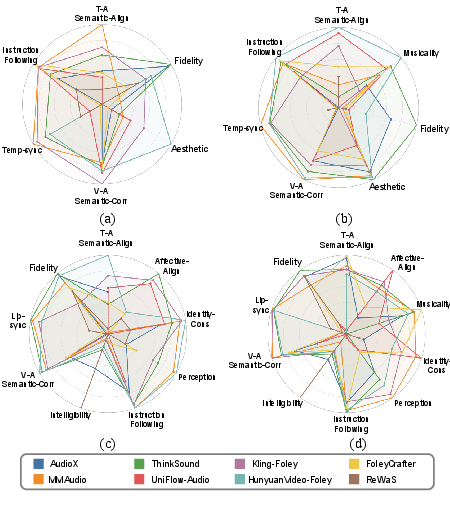
Figure 4: Task-specific performance distributions (radar plots) for SFX, music, speech, and singing across representative models.
Tension Between Visual Grounding and Instruction Following
A critical empirical observation is the antagonistic relationship between visual grounding and instruction following under VT2A evaluation. As shown quantitatively, providing dense visual descriptions often increases V-A semantic correspondence scores but degrades the probability of the model generating audio of the intended target category (especially for BGM and singing). This is directly attributed to the distraction or semantic bias induced by detailed, but non-categorical, visual cues. For instance, in BGM, action-centric captions lead to event-driven SFX generation, not musical background, violating the task condition.
Human Alignment Validation
VidAudio-Bench is rigorously validated with human subjective studies, employing controlled groupwise annotation. Correlative analyses demonstrate high Pearson coefficients between benchmark metric values and human win rates across semantic, realism, and sync dimensions, demonstrating robust perceptual validity.
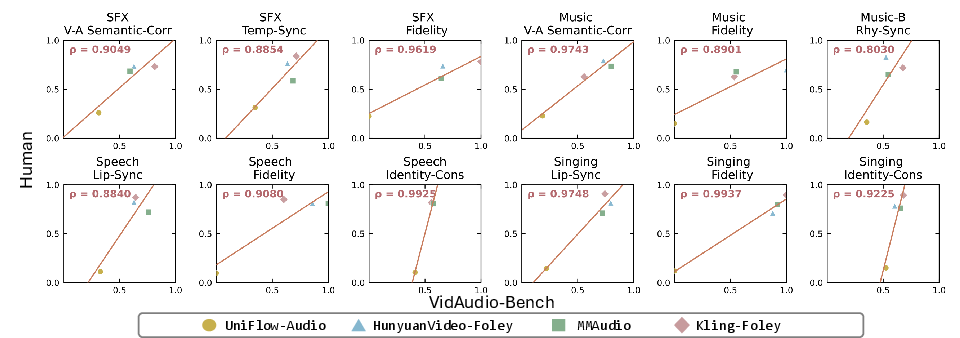
Figure 5: Pearson correlation between human preference rates and VidAudio-Bench metric scores, confirming perceptual and instructional alignment.
Instruction-following is further verified via binary classification against human-labeled categories, achieving ≥0.8 F1-scores across all classes.
Practical and Theoretical Implications
The benchmark provides the first large-scale, multidimensional, category-stratified testbed for V2A/VT2A system design and validation. The results indicate that unified V2A or multimodal generation systems are fundamentally limited by the intersectional challenge of optimizing audio fidelity, cross-modal grounding, and robust instruction compliance, especially in voice-based and highly structured musical tasks. The observed breakdowns in VT2A reinforce the need for advanced alignment objectives and the integration of targeted negative prompting or adaptive input representations. Future work may leverage these findings to develop compositional bridging architectures, advanced regularization schemes, or user-in-the-loop fine-tuning mechanisms that better arbitrate the trade-offs between category control and semantic grounding.
Conclusion
VidAudio-Bench establishes a new standard for benchmarking multimodal audio generation tasks. By systematically unifying data construction, input paradigms, and automated/human-aligned metric design, it exposes the measurable limitations of current V2A/VT2A models and provides actionable diagnostics for future research and model improvement. This framework is instrumental for the community focus on nuanced, perceptually aligned, and category-specific audio generation, especially as multimodal content synthesis systems continue to expand in both scope and application.
Reference: "VidAudio-Bench: Benchmarking V2A and VT2A Generation across Four Audio Categories" (2604.10542)