- The paper reveals hybrid two-stage pipelines combining coarse restoration and one-step diffusion for efficient, high-quality face synthesis.
- The methodology integrates metric-aware optimizations and semantic region corrections to enhance perceptual quality and identity consistency.
- The challenge underscores a shift towards foundation-model adaptations with modular, degradation-aware control for real-world image restoration.
Summary of the NTIRE 2026 Challenge on Real-World Face Restoration
Introduction and Evaluation Protocol
The NTIRE 2026 Challenge on Real-World Face Restoration targets the recovery of high-quality face images from degraded, real-world inputs, emphasizing both realism and identity consistency. Unlike previous benchmarks that often constrained method size or data, the challenge imposes no limits on computational resources or training data utilization. Evaluation comprises (1) AdaFace-based identity verification and (2) a composite perceptual quality score aggregating CLIPIQA, MANIQA, MUSIQ, Q-Align, NIQE, and FID. Participants must surpass identity thresholds on all test sets with less than 10 failures; ranking is primarily governed by the overall perceptual metric.
Data and Testbed
Training typically uses FFHQ (70,000 HQ faces), with test sets sampled from CelebChild-Test, LFW-Test, WIDER-Test, CelebA, and WebPhoto-Test for broad diversity in degradations (blur, noise, compression, age-related artifacts, color fading).
Methods and Trends
The leading approaches demonstrate the dominance of foundation-model-based diffusion architectures, efficient one-step generation, and metric-oriented adaptive refinements. Key methods fall into the following categories:
1. One-Step and Distilled Diffusion Models:
Top entries (MiPlusCV, HONORAICamera, YuFans) adopt one-step or distilled diffusion models as primary backbones. These methods employ architectures such as OSDFace, Z-Image-Turbo, and SDXL-Turbo, considerably reducing the iterative reconstruction cost typical of vanilla diffusion and enabling direct posterior synthesis.

Figure 1: MiPlusCV adopts a two-stage pipeline that combines OSDFace-based coarse restoration with a Z-Image-based one-step detail enhancement stage.
2. Metric-Aware Refinement:
Several pipelines enhance their backbone with explicit adaptation or optimization targeting the challenge metrics. For example, MiPlusCV incorporates reward-based post-training to maximize CLIPIQA/MANIQA/MUSIQ, while YuFans integrates test-time gradient-ascent using differentiable CLIPIQA, balancing perceptual improvement and fidelity.
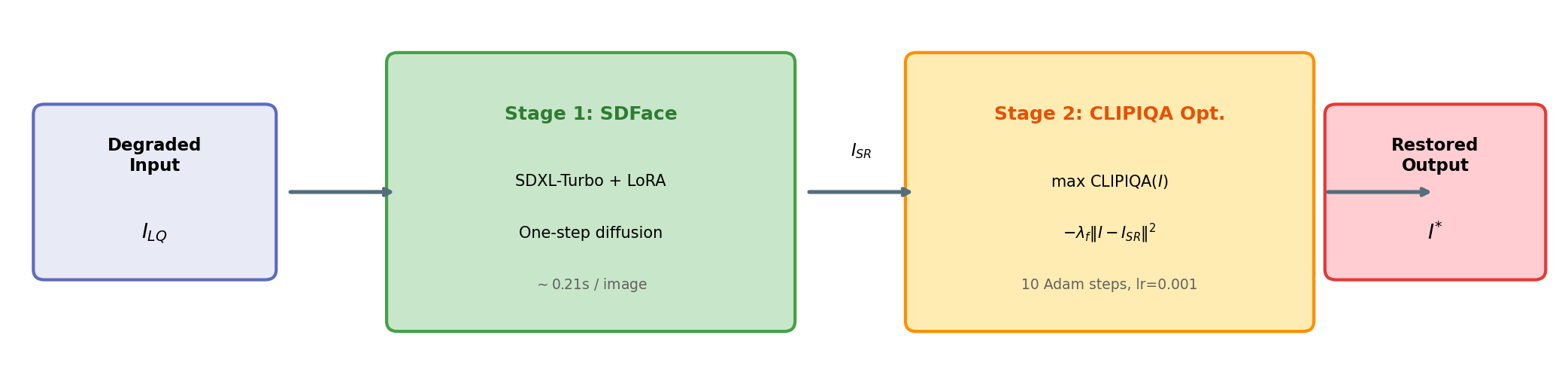
Figure 2: YuFans combines a one-step SDFace restoration stage with CLIPIQA-guided pixel optimization at test time.
3. Structure and Region-Aware Enhancement:
The second-place CEVI-KLETech team introduces a wavelet-based residual correction between diffusion and naturalness stages, guided by semantic face parsing. This spatially adaptive enhancement provides structure-salient refinement while maintaining low-frequency identity cues.
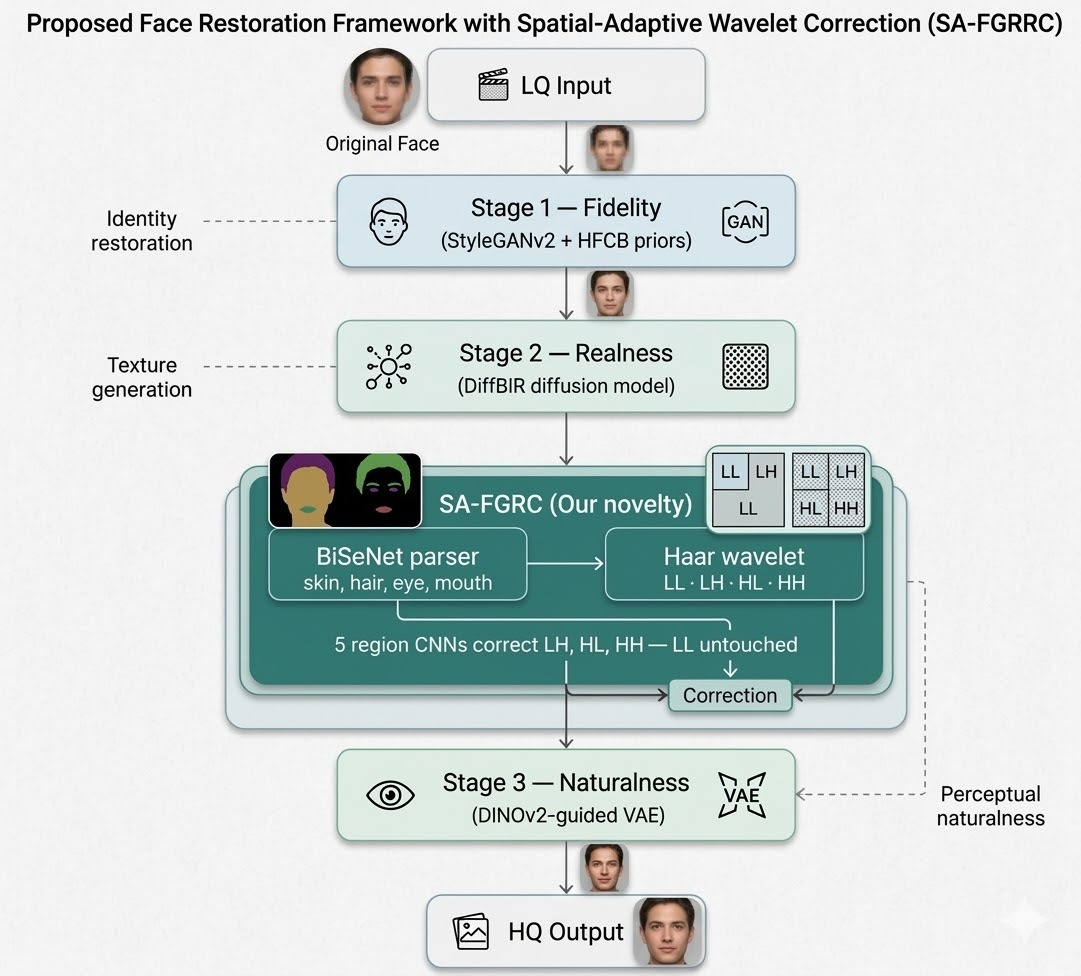
Figure 3: Overview of the CEVI-KLETech pipeline. A semantic-aware wavelet correction block is inserted between the diffusion and naturalness stages.
4. Modular Multi-Stage Designs and Degradation-Aware Control:
Several submissions (e.g., MiPlusCV, guaguagua) rely on modular architectures, separating coarse denoising, perceptual restoration, and post-processing. The guaguagua (DeSC-Face) approach encodes degraded images into latent control representations, adapting the foundation-model restoration via structure/degradation-aware modulation branches.
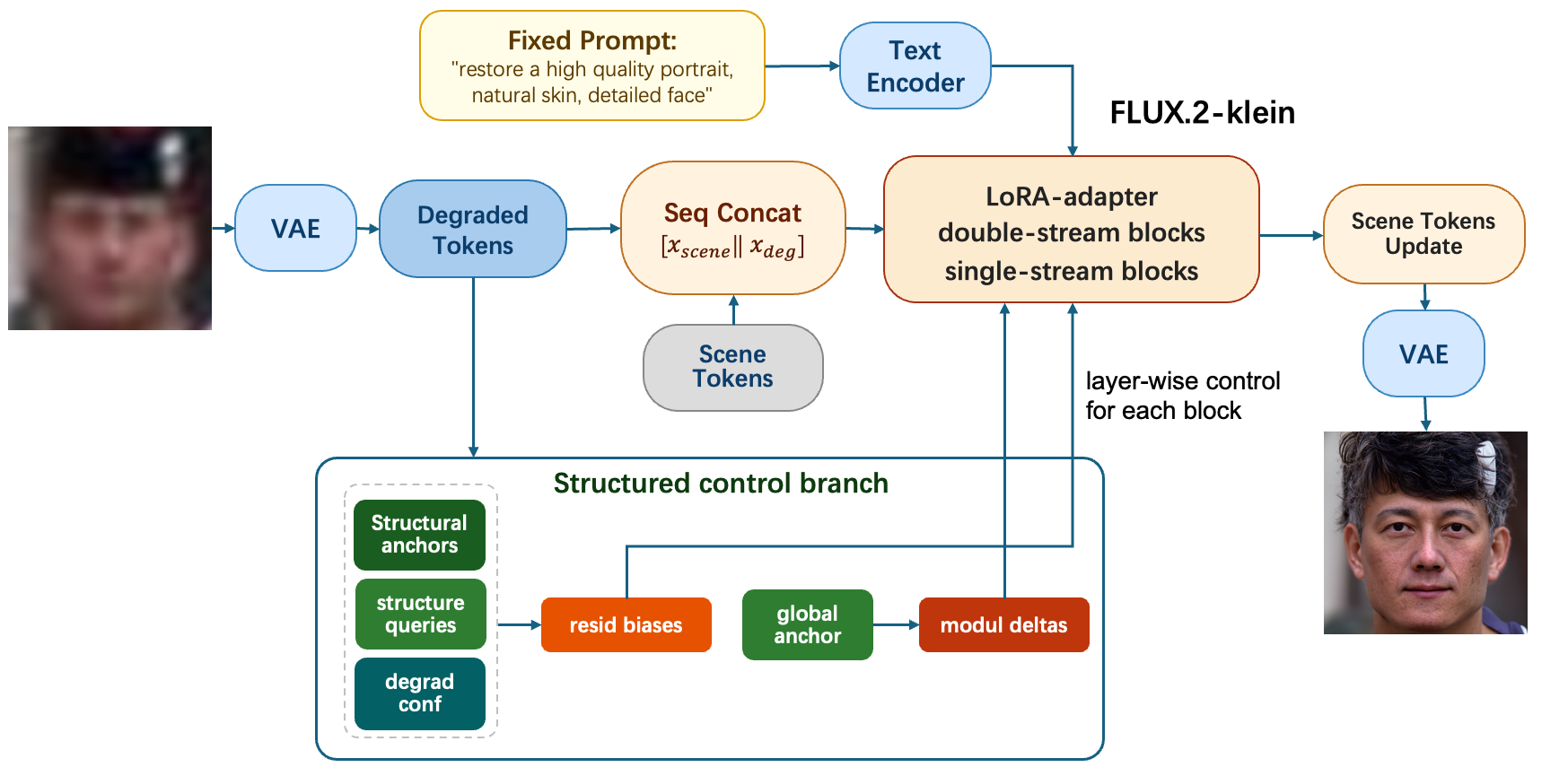
Figure 4: Overview of DeSC-Face. The degraded image is encoded into degraded latent tokens, which are used both as the main condition for the LoRA-adapted FLUX.2 backbone and as the input to the structured control branch.
Notable Architectures and Training Regimes
- MiPlusCV: Employs a two-stage setup with OSDFace for initial coarse denoising and a Z-Image-based one-step diffusion for detail synthesis. Loss functions combine ℓ1 reconstruction, DISTS, ArcFace, and DINOv2-driven adversarial learning. Post-training applies metric-based optimization for leaderboard gains.
- CEVI-KLETech: Implements a frozen StyleGAN2 + DiffBIR backbone, enriching high-frequency content via semantic, region-specific wavelet correction; only the correction module is trained, using band-restricted losses and ArcFace supervision.
- HONORAICamera: Distills generative priors from Z-Image-Turbo, fixed at an optimal mid-timestep, with losses for MSE, GAN, and CLIP-based perceptual signals.
- YuFans: Applies SDFace as the backbone (no further training), enhancing results via direct test-time IQA optimization (differentiable CLIPIQA with pixel-level constraints).
- DeSC-Face: Uses structured latent control inside a LoRA-adapted FLUX.2 transformer, encoding degradations and structure queries for modulation of the generative prior.
- MaDENN: Augments CodeFormer with second-order synthetic degradations, ArcFace, and region-of-interest supervision on critical facial regions (eyes, mouth).
Quantitative and Qualitative Results
MiPlusCV ranked first, demonstrating the empirical strength of hybrid two-stage pipelines leveraging both generative priors and metric-aware adaptation. CEVI-KLETech’s semantic wavelet refiner resulted in the highest CLIPIQA score, while YuFans achieved strong quantitative metrics solely via test-time optimization. All top models preserved identity as enforced by AdaFace, with BVI disqualified for failing the threshold.
Implications and Future Directions
The challenge establishes several core insights:
- Foundation Model Adaptation: The field is shifting toward adapting large, general-purpose generative priors (e.g., Z-Image, SDXL-Turbo, FLUX) with LoRA or modular control, replacing task-specific, architecture-bound design.
- Efficiency-Quality Trade-offs: One-step and distilled diffusion methods now match or surpass traditional iterative pipelines in perceptual scores, dramatically reducing inference latency.
- Metric-Oriented Optimization: Post-training or test-time refinement directly targeting no-reference IQA metrics can yield significant performance uplifts, suggesting hybrid training-inference regimes are emerging as best practice.
- Region and Semantic Consistency: Despite the scale of foundation models, integrating explicit geometric or semantic priors remains necessary for stability in identity and anatomy, especially under severe real-world degradations.
Conclusion
The NTIRE 2026 Real-World Face Restoration Challenge evidences a clear shift toward foundation-model-centric, efficiently distilled architectures, augmented by region-aware and metric-guided refinement. Identity preservation remains a non-negotiable constraint, mandating hybrids of unconditional generation and explicit facial structure encoding. Future systems will likely further integrate adaptive, task-driven fine-tuning and exploit scalable foundation priors, driving real-time, photo-realistic restoration for unconstrained, real-world scenarios.
Reference: "The Second Challenge on Real-World Face Restoration at NTIRE 2026: Methods and Results" (2604.10532)