- The paper introduces a novel benchmark and challenge for restoring videos corrupted by bitstream errors using a large-scale dataset and precise binary masks.
- It evaluates multi-stage restoration pipelines that combine deep-learning architectures with foundation models and PEFT, quantified by PSNR, SSIM, and LPIPS.
- Methods leveraging visual priors and modular fusion demonstrate effective artifact suppression, yet challenges remain in recovering semantic details and temporal consistency.
NTIRE 2026 Challenge on Bitstream-Corrupted Video Restoration: Summary and Technical Analysis
Problem Definition and Benchmark Setup
Bitstream-corrupted video restoration (BSCVR) presents a distinct and highly challenging regime compared to conventional restoration tasks such as denoising, deblurring, or artifact reduction. Real-world video corruption arises from packet loss, bit errors, or segment damage during transmission, storage, or decoding. The resulting spatial-temporal artifacts are irregular, non-stationary, and strongly codec-dependent (Figure 1). The NTIRE 2026 Challenge establishes a standardized benchmark with a large-scale dataset (BSCV), offering corrupted sequences, ground truth frames, and binary masks precisely indicating degraded regions. Evaluation employs PSNR and SSIM for fidelity, alongside LPIPS for perceptual quality.

Figure 1: Realistic bitstream corruption patterns include block, color, duplication, misalignment, texture loss, and trailing artifacts, diverging from conventional simulated masks.
Methods: Architectural Trends and Innovations
The seven finalist teams converge on several prominent architectural trends, notably the widespread adoption of B2SCVR [liu2025towards] as the baseline, integration of visual foundation models for semantic priors, and deployment of parameter-efficient fine-tuning (PEFT) to manage computational overhead.
- MGTV-AI implements a three-stage pipeline: local inpainting using an optimized BSCVR-P (with ProPainter), temporal refinement via BasicVSR++, and spatial enhancement using NAFNet. The ensemble and multi-resolution strategy improve fine-grained structure recovery and edge sharpness (Figure 2).
- RedMediaTech leverages the Wan2.1 Diffusion Transformer, replacing its native VAE with Qwen-Image VAE, and utilizes a two-stage loss function (MSE+LPIPS, then MSE-only) to optimize perceptual and distortion metrics. The approach demonstrates the efficacy of generative priors and high-capacity latent representations in extreme corruption cases (Figure 3).
- bighit proposes a two-stage architecture with a semantic memory retrieval branch and a router-guided mixture-of-LoRA-experts (MoE-LoRA), enabling dynamic adaptation to heterogeneous corruption. Structural fusions (SAM2, DINOv3) and boundary refinement (NAFNet-style enhancer) ensure spatial-temporal consistency and artifact suppression (Figure 4).
- Vroom integrates frozen SAM2 with LoRA adaptation for spatio-temporal attention refinement. Boundary refinement heads (morphological, residual) mitigate seam effects, while a bi-directional reverse TTA further enhances temporal stability (Figure 5).
- weichow employs a mask-guided multi-resolution compositing pipeline, preserving lossless uncorrupted pixels and restoring degraded regions with B2SCVR. Frozen foundation model priors ensure robust feature extraction and computational efficiency (Figure weichow).
- holding introduces three lightweight modules: mask-aware gated suppression (M1), target-centric cross-frame attention (CA), and boundary-aware seam refinement (M2), directly targeting feature leakage and temporal inconsistency at mask boundaries (Figure 6).
- NTR uses sliding window processing, morphological mask dilation, bidirectional optical flow (SPyNet), and SwinIR-guided feature fusion. Multi-stage GAN training (with PSNR refinement) ensures robust artifact elimination and preserves structural details.
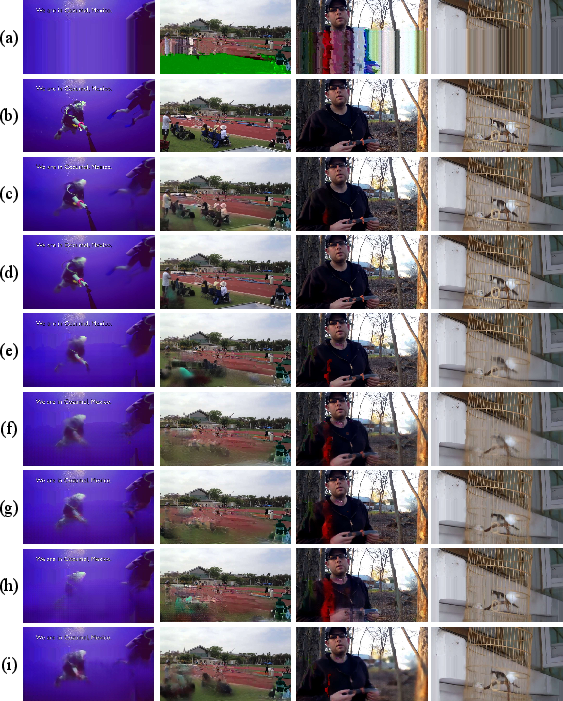
Figure 7: Comparative results across teams reveal sharpness and artifact suppression; MGTV-AI and RedMediaTech exhibit superior semantic detail recovery, mid-tier teams reduce blockiness but often miss fine textures and temporal consistency.
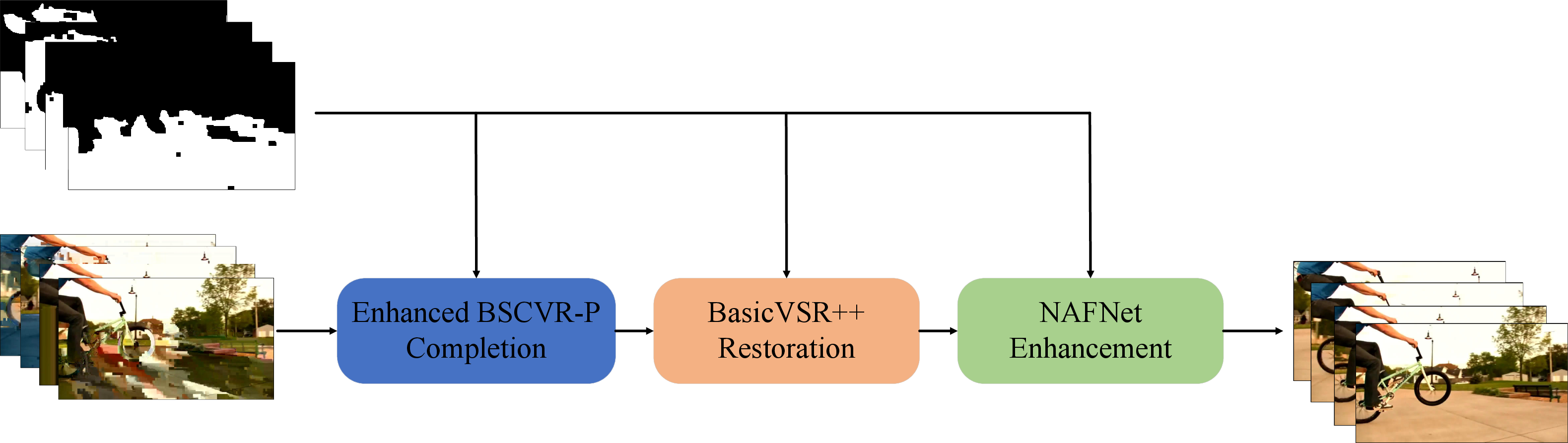
Figure 2: MGTV-AI’s three-stage framework: local completion (BSCVR-P), global refinement (BasicVSR++), spatial enhancement (NAFNet), ensemble for structural fidelity.
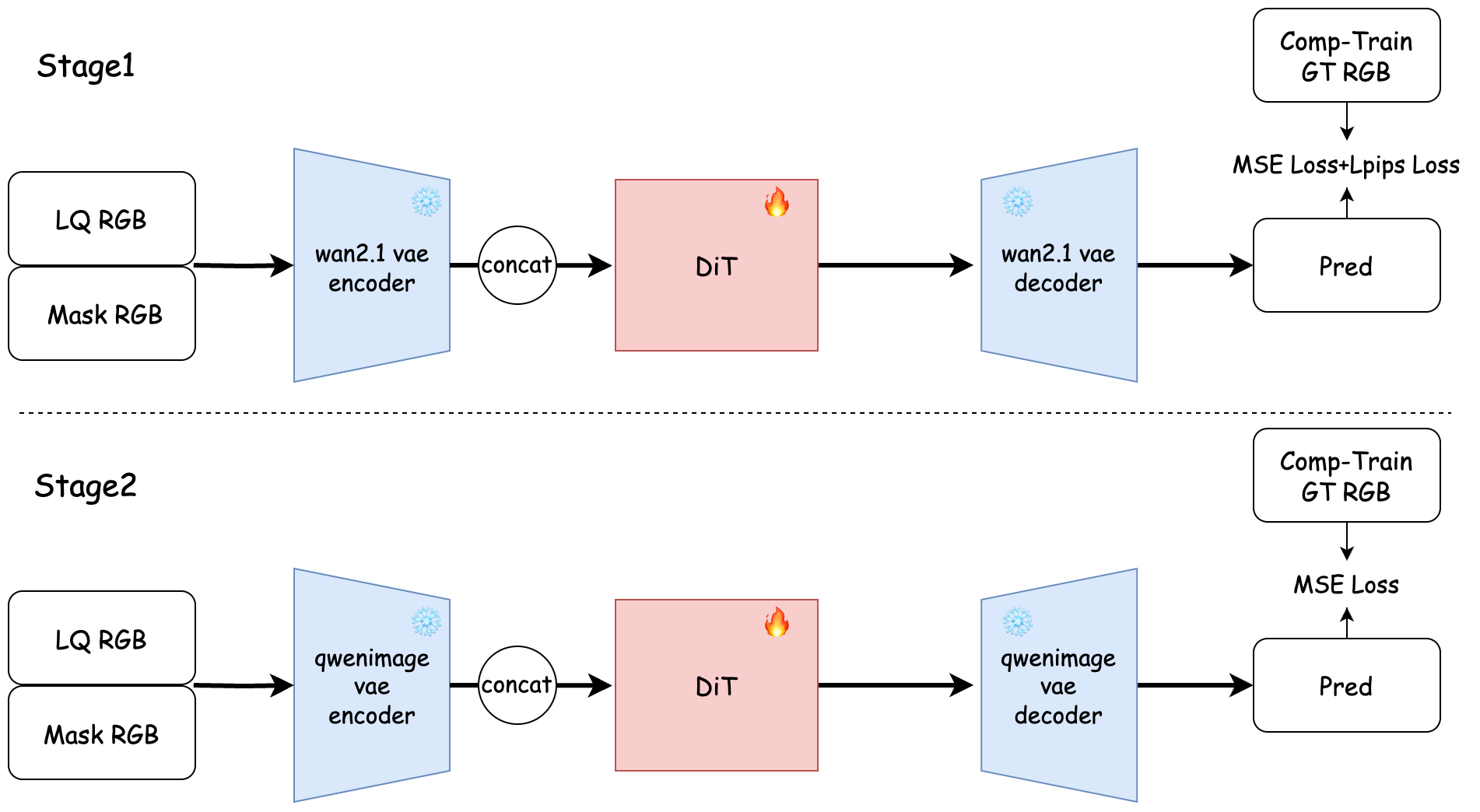
Figure 3: RedMediaTech: single-step Wan2.1 DiT with two-stage training and Qwen-Image VAE swap, enhancing motion robustness and artifact resilience.
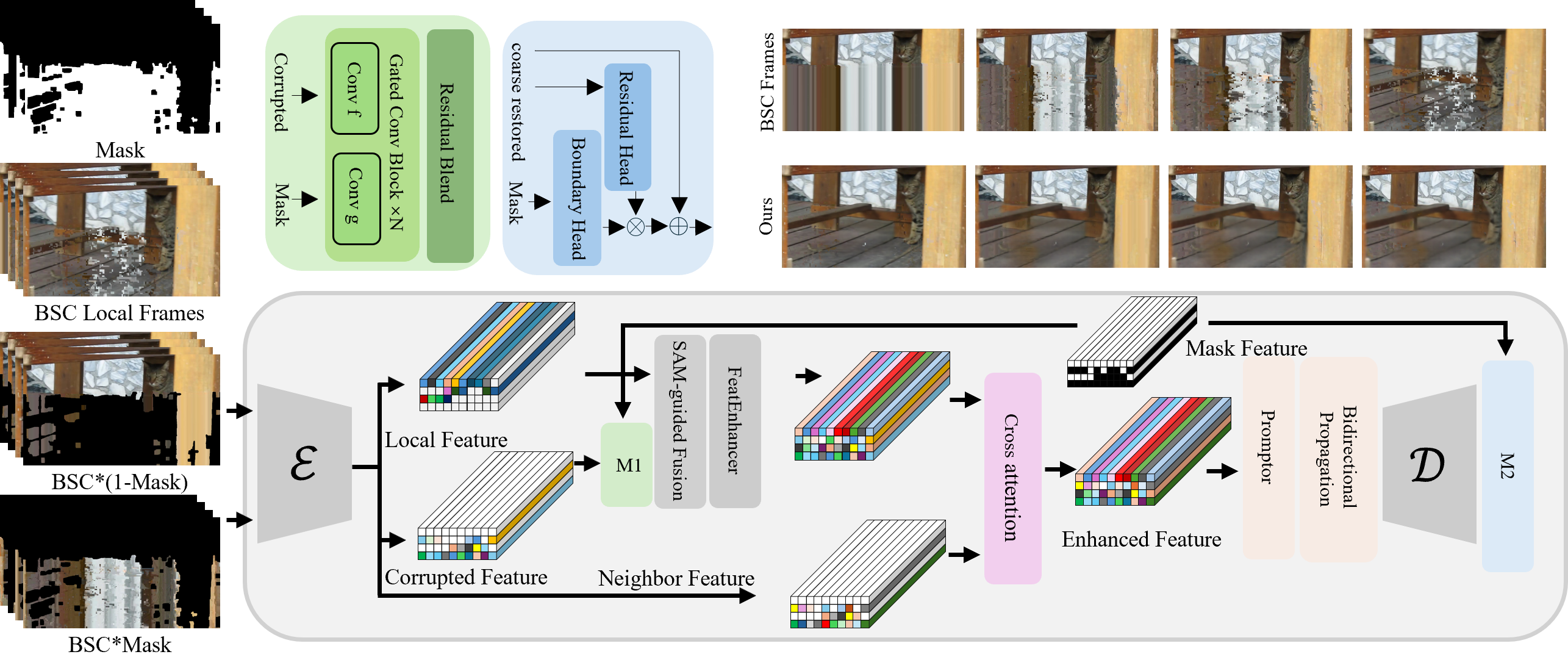
Figure 4: bighit: semantic memory retrieval and MoE-LoRA adaptation jointly handle diverse corruption, followed by boundary-artifact refinement.
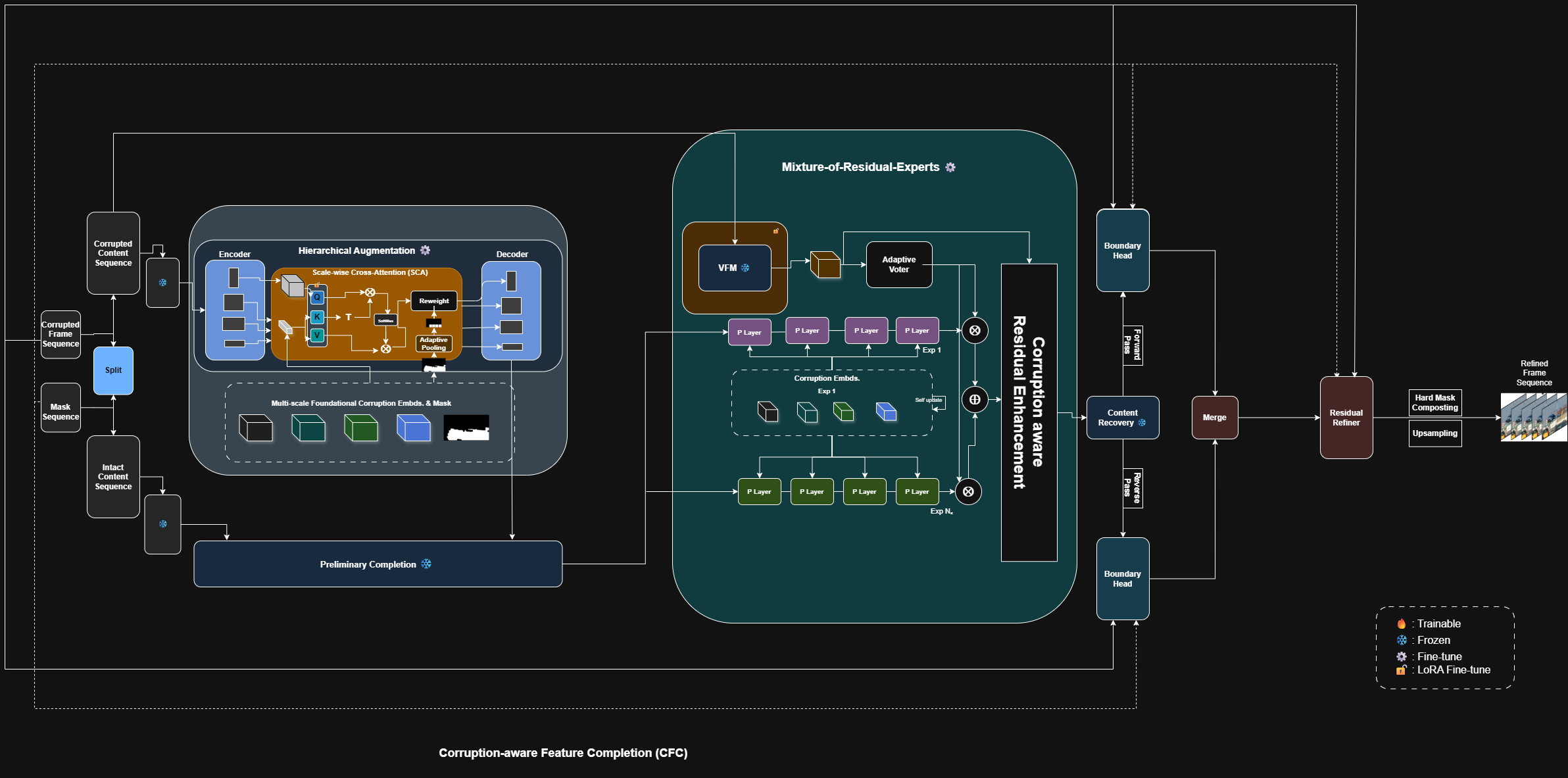
Figure 5: Vroom: B2SCVR backbone with SAM2 prior, LoRA for attention, and specialized boundary refinement modules.
(Figure weichow)
Figure weichow: weichow pipeline: lossless mask-guided compositing preserves original pixels, B2SCVR restores corrupted regions via semantic priors.
Figure 6: holding: B2SCVR backbone with M1 (corruption suppression), CA (cross-frame aggregation), and M2 (boundary seam refinement) modules.
Quantitative Results and Comparative Evaluation
Among the seven entries, MGTV-AI achieves the highest quantitative scores: PSNR 33.642 dB and SSIM 0.9334, outperforming others in structural fidelity. RedMediaTech attains the best perceptual quality (LPIPS 0.0852), illustrating the benefit of diffusion-based generative priors. Mid-tier solutions (bighit, Vroom, weichow, holding) successfully suppress block-level artifacts, but commonly exhibit softness and incomplete recovery of semantic details, especially under severe corruption or rapid motion. Temporal stability and precise text/face restoration remain unsolved bottlenecks for all contenders.
Theoretical and Practical Implications
The challenge demonstrates the inadequacy of conventional restoration and inpainting methods under realistic bitstream corruption—residual information, non-uniform masks, and misleading artifacts necessitate task-specific pipelines. Visual foundation models (SAM2, DINOv3, Qwen-Image VAE) and PEFT approaches (LoRA, MoE-LoRA) significantly enhance generalization and efficiency. Multistage fusion and compositing strategies enable modular design, separating lossless content from synthesized restoration. Diffusion models and transformer-based architectures provide robust generative priors for hallucinating missing data, but the accurate recovery of semantic content and maintenance of long-range temporal coherence are unsolved, suggesting further research is needed in spatial-temporal semantic modeling, advanced compositing strategies, and codec-aware restoration.
Future Directions
Advancements in foundation model integration, parameter-efficient tuning, and generative pipelines will drive further progress. Robustness across codecs, scalability to high-resolution and long-form content, and real-time deployment must be targeted. Approaches combining foundation models’ semantic segmentation with temporal transformers, or hybrid diffusion-transformer pipelines, may offer increased fidelity and stability. Addressing domain transfer, uncertainty quantification, and human-in-the-loop restoration will be critical for practical adoption in streaming and surveillance.
Conclusion
The NTIRE 2026 Challenge on Bitstream-Corrupted Video Restoration (2604.06945) establishes a rigorous benchmark and technical baseline for tackling real-world severe video degradation. Leading methods demonstrate the importance of multi-stage modular pipelines, foundation model priors, and PEFT strategies. While state-of-the-art solutions effectively suppress structural artifacts and hallucinate missing regions, semantic detail recovery and temporal stability remain open problems. Further developments are expected in foundation-model-driven, codec-aware restoration architectures, accelerating the deployment of robust AI systems in video communication, surveillance, and content creation domains.