- The paper proposes a forensic pipeline with cryptographic steganographic watermarking to embed verifiable identifiers into AI-generated images.
- It evaluates multiple watermarking techniques, showing that wavelet-domain spread spectrum methods deliver optimal imperceptibility and robustness under attacks.
- A CLIP-based multimodal classifier achieves 95% validation accuracy and a 0.99 AUC-ROC, enabling precise detection of harmful image-text combinations.
Steganographic Attribution and Multimodal Harm Detection for Accountable AI-Generated Content
Introduction and Motivation
The widespread adoption of generative AI, particularly diffusion-based models, has resulted in an unprecedented volume of synthetic imagery being disseminated on social platforms. This paradigm shift has introduced new threats to digital forensics, moderation, and accountability pipelines, especially due to the contextual harm introduced when benign AI-generated images are paired with misleading or malicious text. Traditional moderation approaches that evaluate only unimodal content are no longer tenable, as toxic or deceptive intent frequently emerges at the intersection of modalities.
In response to this, the paper presents a comprehensive forensic framework targeting the forensic attribution of AI-generated content on social platforms, addressing the lack of persistent metadata and device signatures in such content. The core concept is to embed cryptographically verifiable steganographic identifiers into AI-generated images at creation, enabling reliable post hoc attribution when multimodal harmful deployments are detected. The framework integrates a robust steganographic gateway with a state-of-the-art CLIP-based multimodal harm detection model for accountability-driven content tracing.
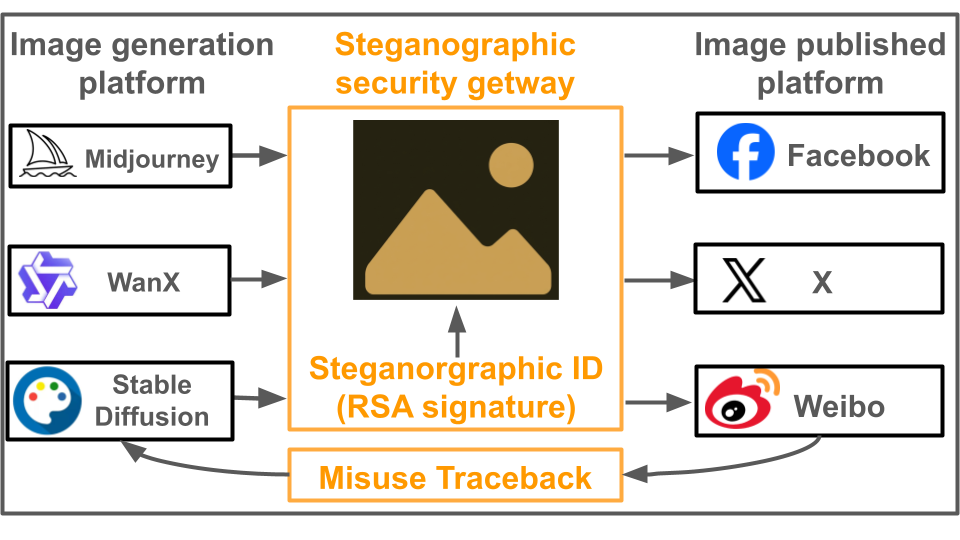
Figure 1: Overview of the Steganographic Security Gateway—a two-stage system integrating cryptographic marking with multimodal harm detection.
Technical Framework
The method formalizes an end-to-end attribution pipeline instantiated as a Steganographic Security Gateway. The entire flow comprises cryptographic identifier embedding at image generation, post-distribution multimodal harm detection, and (when triggered) cryptographic extraction and verification for user-level attribution.
Steganographic Embedding Methodology
The paper evaluates five watermarking techniques distinguished by embedding domains:
- LSB (Least Significant Bit) spatial-domain embedding
- DCT (Discrete Cosine Transform) domain embedding
- DWT (Discrete Wavelet Transform) domain embedding
- Spatial spread spectrum watermarking
- DWT-domain spread spectrum watermarking (DWT-SS)
These methods are unified by a cryptographic layer: identifiers are encoded as RSA signatures, with compact SHA-256-derived fingerprints adapted for domains with lower capacity or where correlation-based detection is preferable.
The embedding process is designed to optimize for robust recoverability post-distribution, prioritizing resistance to typical operations such as compression, resizing, geometric transforms, and blurring, which are pervasive on social platforms.
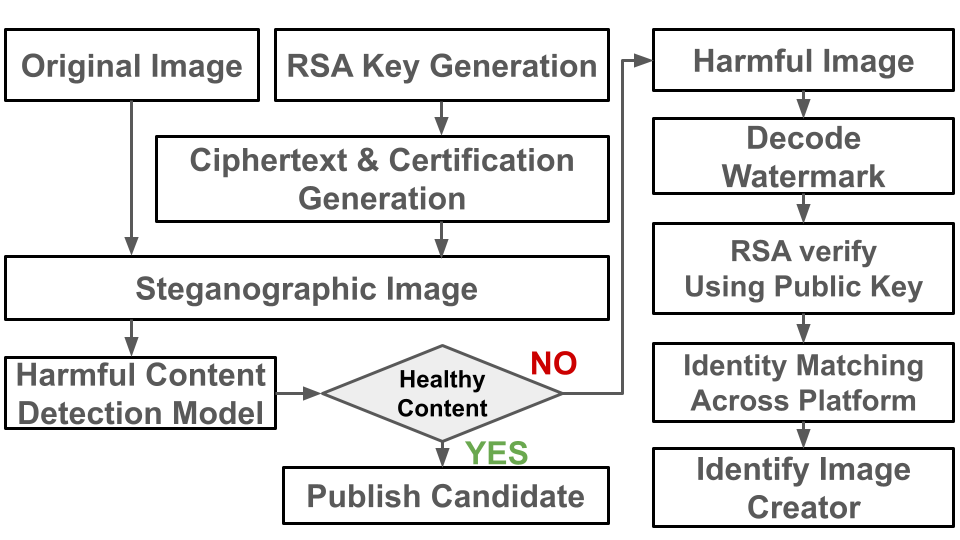
Figure 2: Flowchart of the Steganographic Enabled Image Tracing Pipeline, showing data flow from embedding to multimodal analysis and attribution.
Multimodal Harm Detection
Harmful deployment detection is operationalized via a two-layer MLP classifier built on a frozen pre-trained CLIP encoder. Image-text pairs are mapped into a fused semantic embedding incorporating modality-specific vectors, element-wise differences, element-wise products, and overall cosine similarity, forming a R4d+1 fusion. Classification uses binary cross-entropy loss, with only the classifier being trainable to ensure deployment efficiency.
This fusion enables detection of harmfulness that emerges only in context (image-text union), supporting precise attribution triggers.
Experimental Results
Watermark Robustness
Empirical evaluation on diverse PNG, JPEG, and BMP corpora quantifies both perceptual imperceptibility and recovery rates under post-processing attacks. Robustness benchmarks include:
- No Attack: LSB achieves 100% fidelity but is catastrophically fragile to minor perturbations. Spread spectrum methods (Spatial SS and DWT-SS) maintain 98.8% and 98.3% robustness, respectively.
- Gaussian Blur: LSB, DCT, and DWT exhibit complete collapse (0% verification success). Spread spectrum methods show only minor degradation (Spatial SS: ~98.8%, DWT-SS: ~98.3% success).
- JPEG Compression (Q=50): Bit-wise approaches are nonfunctional. Spatial SS maintains 96.8% robustness; DWT-SS degrades to 77.4%.
- Resizing/Center Crop: Spatial SS and DWT-SS retain over 98% recovery rates.
TrustMark baselines are also evaluated, showing notable degradation under blur and resize but superior to bit-wise methods under attack conditions.






















Figure 3: Visual comparison of watermarking methods on a natural color image under no attack and common perturbation scenarios, highlighting the imperceptibility/robustness tradeoff.
Qualitatively, LSB is visually lossless; DCT introduces faint block artifacts, DWT creates mild grain/brightness shifts, and spread spectrum methods superimpose minimal noise—DWT-SS yields the best balance between imperceptibility and robustness.
Multimodal Classifier
Training and validation on the benchmark dataset (from [wang-etal-2025-cant]) demonstrates:
- Near-zero generalization gap with validation accuracy converging to 95%
- AUC-ROC of 0.99 for harmfulness classification, outperforming canonical baselines
The model shows strong separation between harmful and benign multimodal inputs, accurately reflecting contextual harm not detectable in isolated modalities.
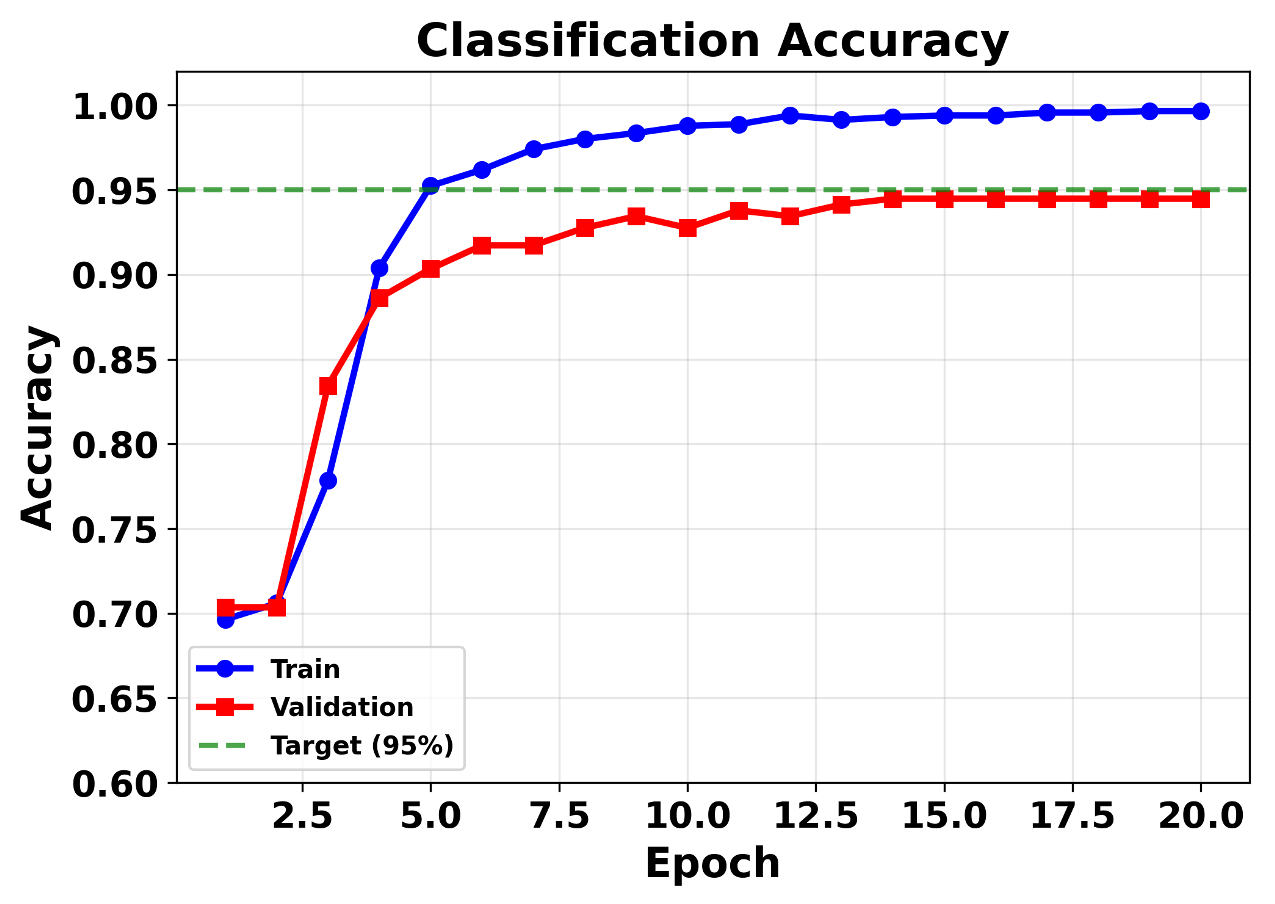
Figure 4: Training and validation curves for the CLIP-based multimodal harm detector, indicating stable convergence and minimal overfitting.
Implications and Future Directions
The integration of robust watermark-based steganographic attribution with high-performance multimodal harm detection yields a practical pipeline for platform-level accountability. Key implications:
- Forensic utility: Investigators can trace harmful synthetic imagery back to originators even when conventional metadata/device evidence is absent.
- Deterrence: The presence of user-level attribution may inhibit malicious use, complementing reactive moderation processes.
- Deployment feasibility: The system is model-agnostic and can be incorporated during AI image generation, scaling to existing multimedia platforms.
Several critical limitations and future research vectors are highlighted:
- The bit-exactness requirement for cryptographic signature verification in transform-domain embedding is a bottleneck, especially under lossy workflows. Error-tolerant signature schemes and soft-decision decoding are proposed as potential mitigations.
- Cross-platform identity resolution remains nontrivial; better integration with account linkage/graph analytics could further augment attribution accuracy and adversarial resilience.
- The scheme’s resilience against advanced removal attacks (e.g., adversarial erasure, adversarial harmonization) and adaptability to video/audio modalities remains open for extension.
Conclusion
This paper advances the state of accountable AI-generated content moderation by coupling asymmetric cryptographically verifiable steganographic marking with robust multimodal harm detection. The framework empirically demonstrates that wavelet-domain spread spectrum watermarking delivers high resilience against post-processing attacks, while a CLIP-based multimodal classifier achieves near-optimal separation of contextually harmful deployments. This system provides a quantifiable advance towards forensic-grade attribution and provenance tracking in social media ecosystems, with direct applications for regulatory compliance, forensic investigation, and platform integrity initiatives (2604.10460).

