Zero-shot World Models Are Developmentally Efficient Learners
Abstract: Young children demonstrate early abilities to understand their physical world, estimating depth, motion, object coherence, interactions, and many other aspects of physical scene understanding. Children are both data-efficient and flexible cognitive systems, creating competence despite extremely limited training data, while generalizing to myriad untrained tasks -- a major challenge even for today's best AI systems. Here we introduce a novel computational hypothesis for these abilities, the Zero-shot Visual World Model (ZWM). ZWM is based on three principles: a sparse temporally-factored predictor that decouples appearance from dynamics; zero-shot estimation through approximate causal inference; and composition of inferences to build more complex abilities. We show that ZWM can be learned from the first-person experience of a single child, rapidly generating competence across multiple physical understanding benchmarks. It also broadly recapitulates behavioral signatures of child development and builds brain-like internal representations. Our work presents a blueprint for efficient and flexible learning from human-scale data, advancing both a computational account for children's early physical understanding and a path toward data-efficient AI systems.
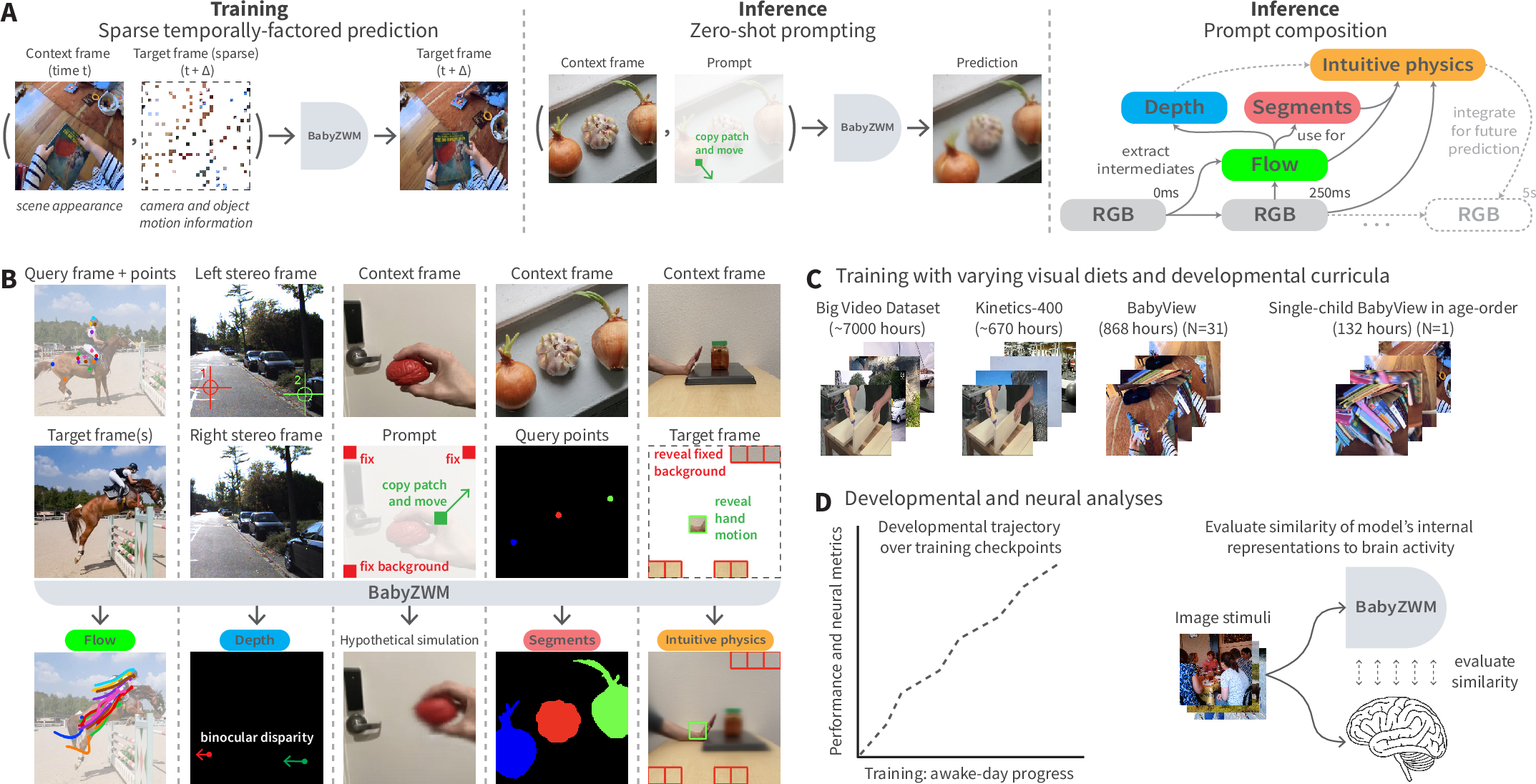



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper introduces a new kind of AI vision system called a Zero‑shot World Model (ZWM). It learns by watching videos (like a baby does) and can do lots of vision tasks right away—without extra training for each task. The authors show it can learn surprisingly well from a small, natural video diet: hundreds of hours of videos recorded from babies’ point of view. They call the child‑trained version BabyZWM.
What big questions the paper asks
The paper tries to answer two kid‑friendly questions about learning:
- How can a learner get so good with so little practice? (data efficiency)
- How can a learner try brand‑new tasks without being taught each one separately? (zero‑shot flexibility)
Humans do both. Can a computer model do the same from everyday, messy videos?
How the model learns and works (with simple analogies)
The model has three main ideas. Think of it as a “what‑if” video forecaster that you can poke to see how the world reacts.
1) Temporally‑factored prediction: learning appearance vs. motion
- Imagine you have two frames from a video: a “before” picture and an “after” picture.
- The model sees the whole “before” frame and only tiny scattered pieces of the “after” frame (like a jigsaw puzzle with most pieces missing).
- Its job is to reconstruct the entire “after” frame.
- To succeed, it has to:
- Use the first frame to learn what things look like (appearance).
- Use the few revealed pieces from the second frame to infer how things moved (motion).
- This setup nudges the model to separate “what things are” from “how they move”—a very useful habit for understanding the world.
2) Zero‑shot extraction by “what‑if” nudges (approximate causal inference)
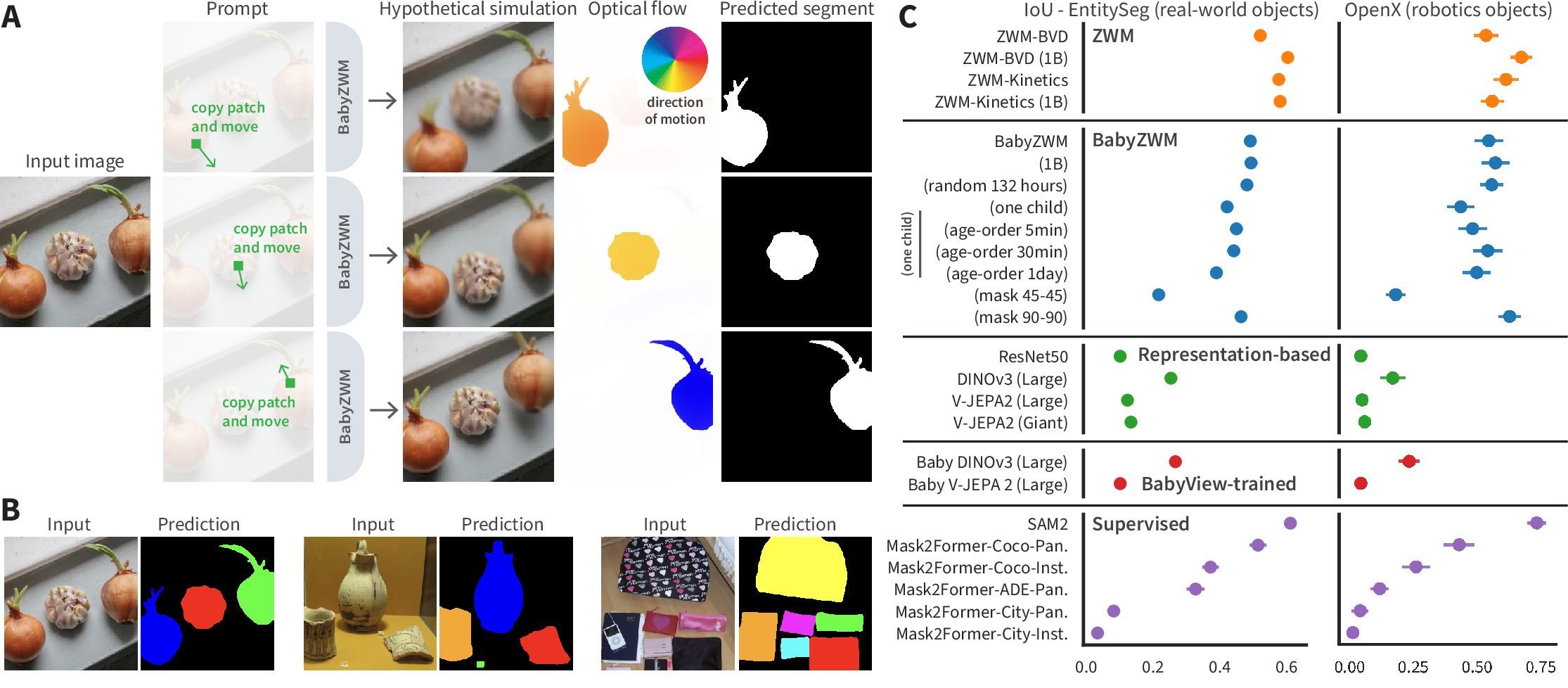
- After training, you can ask the model questions without new labels by making tiny “what‑if” changes.
- Example: To find an object, “nudge” one small patch as if it moved a bit and see where the model’s predicted motion spreads. Pixels that move together likely belong to the same object.
- This is like gently tugging on a sticker on a page: if the whole sticker moves, you’ve found its outline.
- By comparing the original prediction to the “nudged” prediction, the model exposes hidden structure (like motion, objects, or depth).
3) Compositional prompting: chaining simple steps into bigger skills
- The model chains easy operations to answer harder questions:
- From frames → estimate motion (optical flow).
- Use motion in two eyes’ views → estimate which things are closer or farther (stereo depth).
- Simulate a tiny motion → segment objects that move together.
- Use motion and objects → reason about simple physics (support, pushing, collisions).
Put together, ZWM becomes a data‑driven “world model”: it predicts what would happen if something in the scene changed.
What the researchers did (their approach)
- Training videos: They used BabyView—868 hours of head‑mounted videos from infants and toddlers (about three months of waking life). They also tested training on smaller or more/less diverse video sets, including just 132 hours from a single child, once through in the child’s actual age order.
- Architecture: A vision transformer (a modern neural network) trained to predict the next frame from the current frame plus a few “puzzle pieces” from the future frame.
- No labels: The model never sees task‑specific answers during training. All task results are zero‑shot, extracted by the “what‑if” prompting tricks above.
- Comparisons: They compared ZWM to popular self‑supervised models (like DINOv3 and V‑JEPA) and to specialized, supervised models trained directly for tasks (like optical flow, depth, and segmentation).
What the model can do and why it matters
Here are the main tasks BabyZWM performs zero‑shot, and what the results mean:
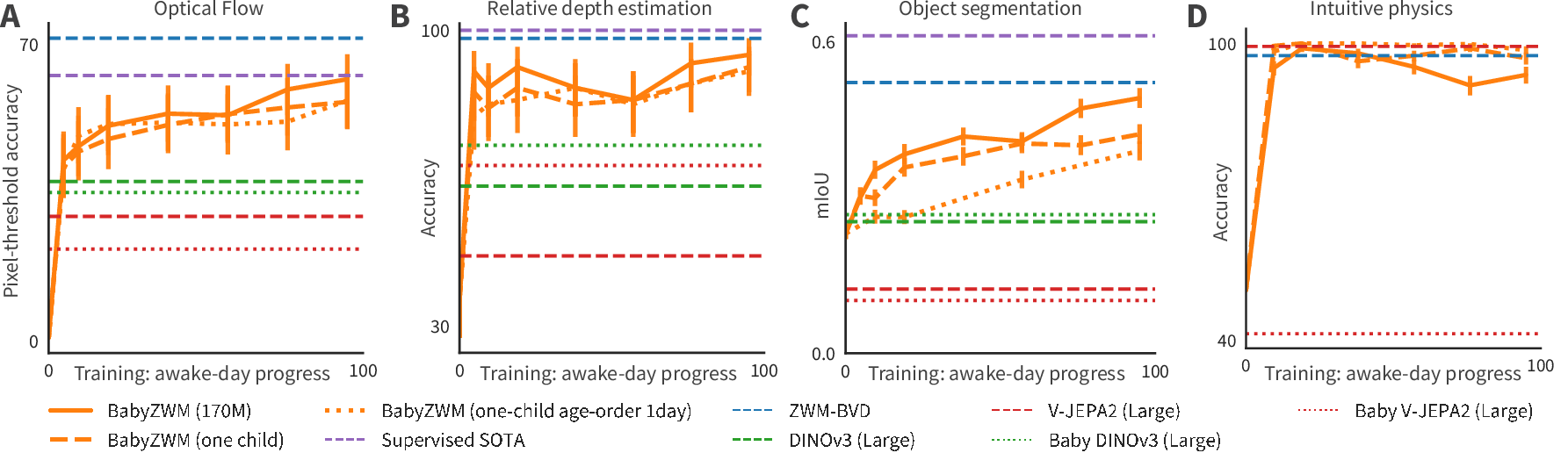
Optical flow (tracking how pixels move)
- Task: Track how points move across frames in real videos (including occlusions and tricky lighting).
- Result: BabyZWM is competitive with top supervised models trained with labeled data, and better than strong self‑supervised baselines when tested zero‑shot.
- Why it matters: Motion understanding is a foundation for many vision skills (like tracking, predicting, and interacting).
Relative depth (which point is closer)
- Task: Given stereo (two‑eye) images, decide which of two points is nearer.
- Result: BabyZWM achieves over 90% accuracy, beating some large vision‑LLMs and matching or surpassing monocular depth systems (it trails only a supervised stereo model).
- Why it matters: Depth from two eyes mimics how humans use binocular vision.
Object segmentation (finding full object shapes)
- Task: Outline objects without knowing their categories.
- Trick: Gently “move” a small patch and see which pixels move together—those belong to the same object.
- Result: BabyZWM rivals strong supervised segmenters trained on large labeled datasets, coming close to top tools that rely on lots of human annotations.
- Why it matters: Understanding “what is one object” is basic to perception and action.
Intuitive physics (short‑timescale cause‑and‑effect)
- Task: Predict simple interactions like pushing, stacking, supporting, and transferring force between 1–2 objects and a hand.
- Result: BabyZWM and the larger ZWM perform near ceiling.
- Why it matters: It shows the model has learned practical rules of how objects behave, not just image patterns.
Data efficiency and “developmental” learning
- Strong performance from BabyView (natural, messy videos) is notable because many AI systems need cleaner, huge internet datasets.
- Single child, single pass: Even with only 132 hours from one child, watched once in age order, the model stays strong—suggesting robustness to how real life unfolds.
- Motion‑focused training helps: The “asymmetric masking” (see whole first frame, tiny bits of second) is important; symmetric masking performs worse. Prioritizing motion made learning more efficient.
How the model’s growth mirrors kids’ development
As BabyZWM trains, its skills improve in a way that roughly echoes known patterns in child development:
- Motion tracking rises early and then plateaus (similar to improving object tracking).
- Stereo depth gets good quickly and stays strong.
- Object segmentation improves steadily over time.
- Intuitive physics becomes richer with training (from simple expectations like cohesion to more precise support and force reasoning).
These are broad parallels, not exact matches, but they suggest the learning recipe is on the right track.
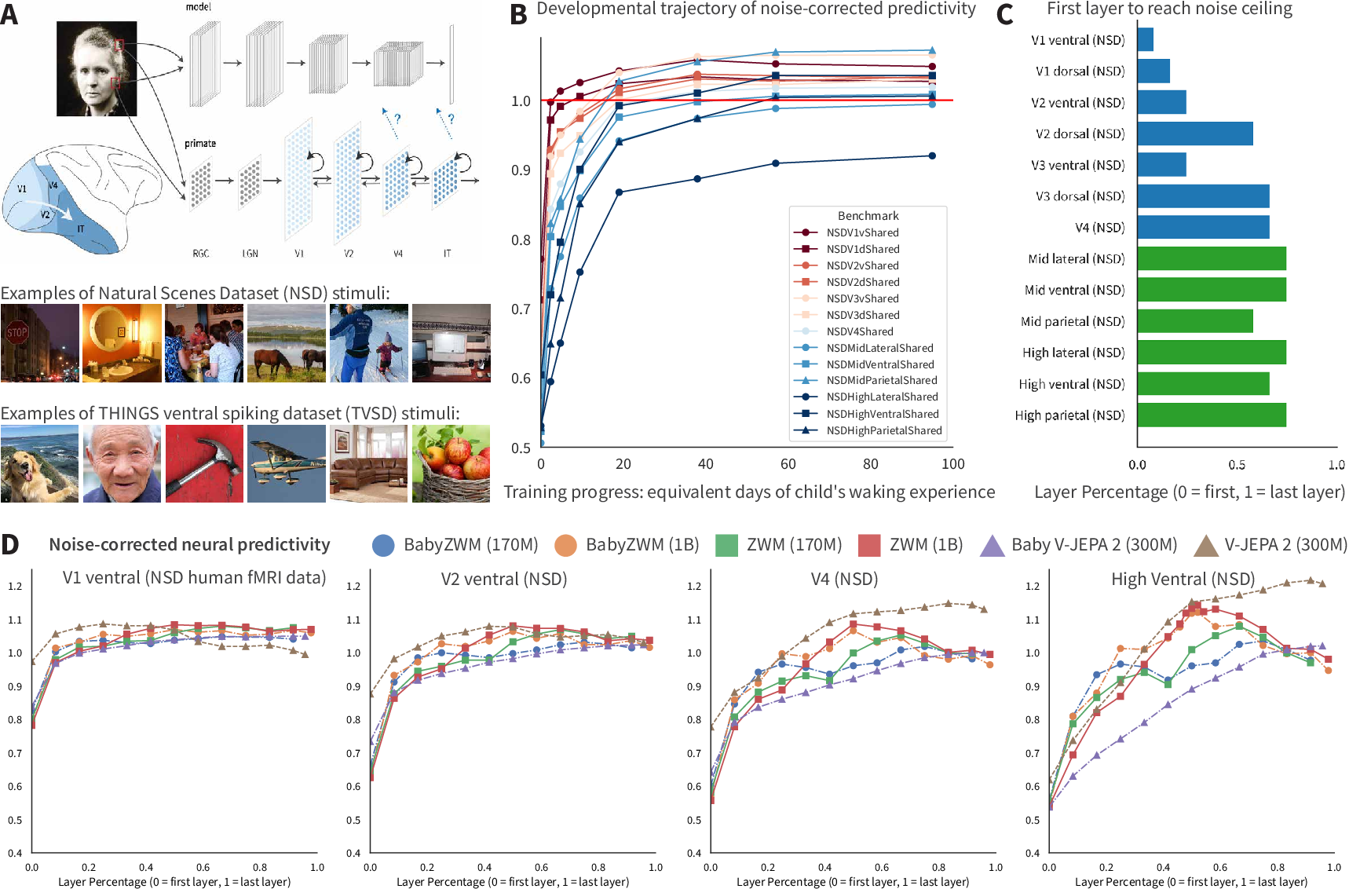
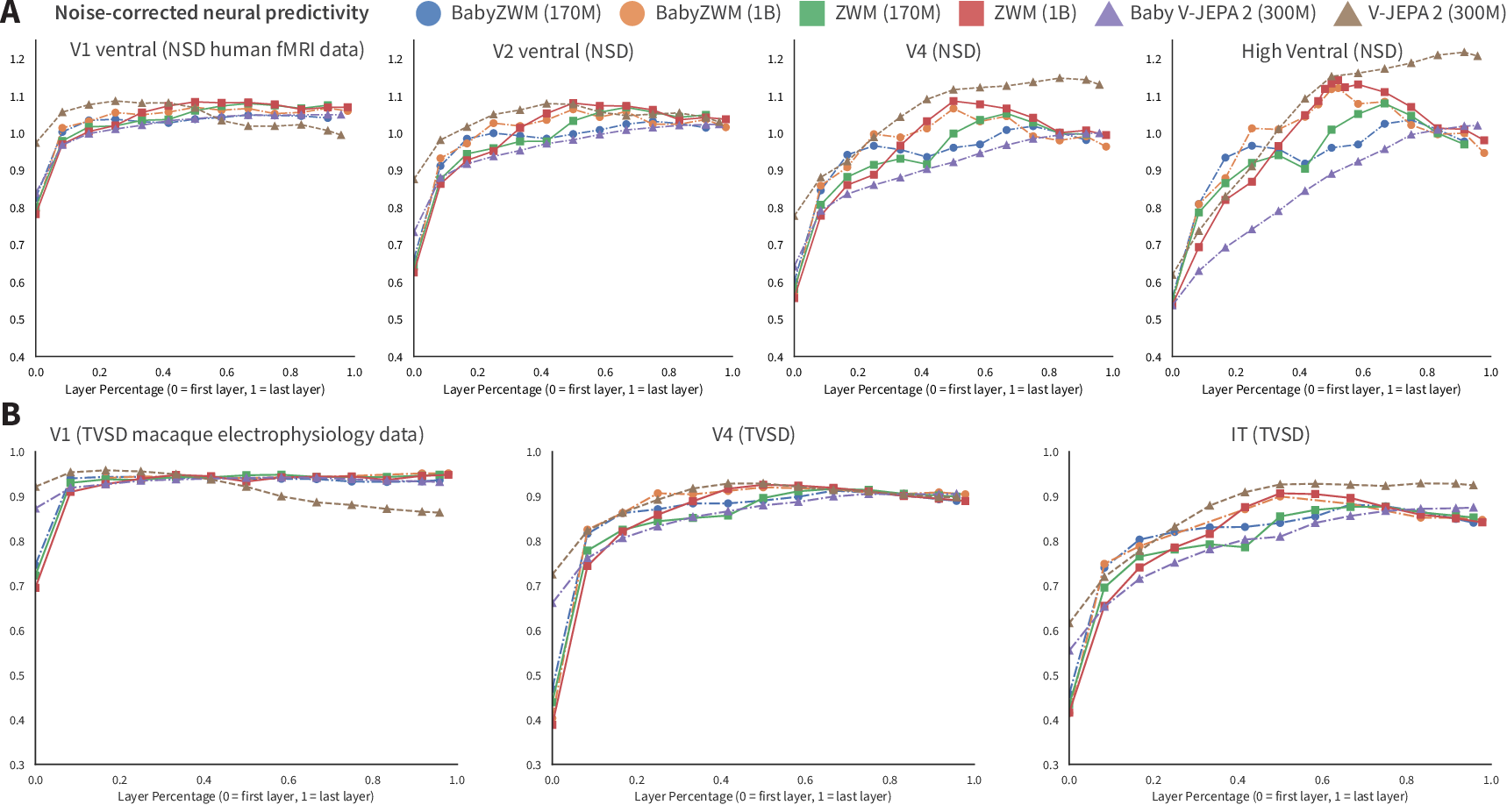
Brain alignment: model internals resemble visual cortex patterns
- The authors tested whether features inside the model predict brain responses (human fMRI and macaque neuron spikes).
- Results show:
- Early visual areas (like V1) align earlier and more strongly at first—an “early‑first” trajectory.
- Deeper model layers align with higher‑level visual areas, matching the brain’s hierarchical organization.
- Takeaway: The model’s internal representations are brain‑like in how they’re organized and how they develop.
Why this is important
- For science: It offers a concrete middle ground in the “nature vs. nurture” debate. The idea is that a small amount of built‑in structure (how the model is trained and how we query it) can combine with real‑world experience to produce broad visual understanding—without needing lots of built‑in concepts.
- For AI: It shows a path beyond “train a model, then train a separate head for every task.” Here, one learned predictor can answer many tasks zero‑shot via a universal, simple prompting interface. That’s cheaper, more flexible, and closer to how humans reuse one brain for many jobs.
- For applications: Robotics, medical imaging, and embodied AI could benefit where labeled data is scarce, since the model learns from raw videos and needs no task‑specific labeling.
Limits and next steps
- Semantics are missing: The model is great at physics‑like perception, but it doesn’t yet learn named categories or language‑level meaning. Future work could connect it with speech/text.
- Uncertainty and longer futures: The predictor is deterministic, so it can blur when the future is uncertain. Extending to longer videos and richer memory is a next step.
- Better developmental comparisons: We need more detailed human datasets to make tighter science claims.
- Bootstrapping: A promising idea is to feed the zero‑shot outputs (like flow or segments) back into training as targets, creating a virtuous cycle that makes learning even more efficient.
Bottom line
This paper shows that a carefully designed “what‑if” video predictor can learn a lot from a little—much like a young child. With simple nudges and comparisons, the same model can do motion, depth, object segmentation, and basic physics, all without extra training for each task. It grows in a way that roughly matches children’s learning and even mirrors patterns in the visual brain. This suggests a powerful recipe for building flexible, data‑efficient AI—and a fresh way to think about how humans learn so much, so quickly.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open problems that remain unresolved by the paper and could guide future research:
- Causal validity of “approximate interventions”: the perturb–compare–aggregate interface is motivated as causal, but lacks formal identifiability guarantees or tests (e.g., invariance, counterfactual faithfulness) in environments with known causal structure.
- Hand-engineered zero-shot prompts: dependence on manually designed perturb/compare/aggregate operators and thresholds is unquantified; there is no method to automatically learn, search, or adapt prompts and hyperparameters across scenes/tasks.
- Sensitivity analysis: robustness of zero-shot readouts to perturbation magnitude, patch size/location, noise, and camera motion is not characterized; failure modes and sensitivity curves are missing.
- Two-frame, short-gap training: the predictor is trained on pairs with 150–450 ms gaps; it is unknown how performance scales to multi-frame, long-horizon prediction, occlusion persistence, and temporally extended reasoning.
- Deterministic regression and mode collapse: the L2-trained predictor cannot represent uncertainty or multimodality; there is no probabilistic output, calibration assessment, or evaluation with multi-hypothesis metrics (e.g., NLL, ECE, diversity scores).
- From proxy to real actions: pixel-patch “proxy actions” are not validated against action-conditioned prediction and control; it remains open whether the model enables closed-loop planning in embodied settings or robotics.
- Depth limitations: zero-shot depth is evaluated as relative, stereo-based disparity; there is no zero-shot monocular absolute/metric depth, no handling of uncalibrated stereo, and no camera intrinsics/pose estimation.
- Object segmentation assumptions: segmentation relies on propagating hypothetical motion; performance on static scenes, severe non-rigid/articulated deformations (cloth, humans), thin structures, and tiny objects is untested.
- Optical flow robustness gaps: robustness to rolling shutter, heavy blur, extreme illumination changes, low-texture regions, and rapid ego-motion is not reported; underperformance on Kubric suggests synthetic-to-real gaps remain unexplained.
- Compositional prompting scalability: computational cost, latency, and memory of composing multiple zero-shot queries (e.g., flow → depth → segments → physics) are unreported; real-time feasibility on edge devices is unknown.
- Data diversity vs quantity: beyond a small single-child vs random-hours comparison, there is no controlled study disentangling the roles of visual diversity, scene complexity, and total hours on learning efficiency.
- Continual learning and forgetting: age-ordered single-epoch training is explored but catastrophic forgetting and retention are not quantified; no explicit memory/replay/regularization mechanisms are tested.
- Architectural ablations: only mask symmetry is ablated; effects of patch size, backbone variants, positional encodings, sparsity level, prediction targets (pixels vs features), and alternative losses (perceptual, diffusion) remain unknown.
- Scaling laws: there is no analysis of parameter-, data-, and compute-scaling laws or the diversity–quantity trade-off that predicts when zero-shot abilities emerge.
- Neural alignment scope: neural predictivity is measured with adult human fMRI and macaque electrophysiology; infant neural data, temporal dynamics (e.g., time-resolved encoding), and causal tests (e.g., lesion/prediction under perturbations) are missing.
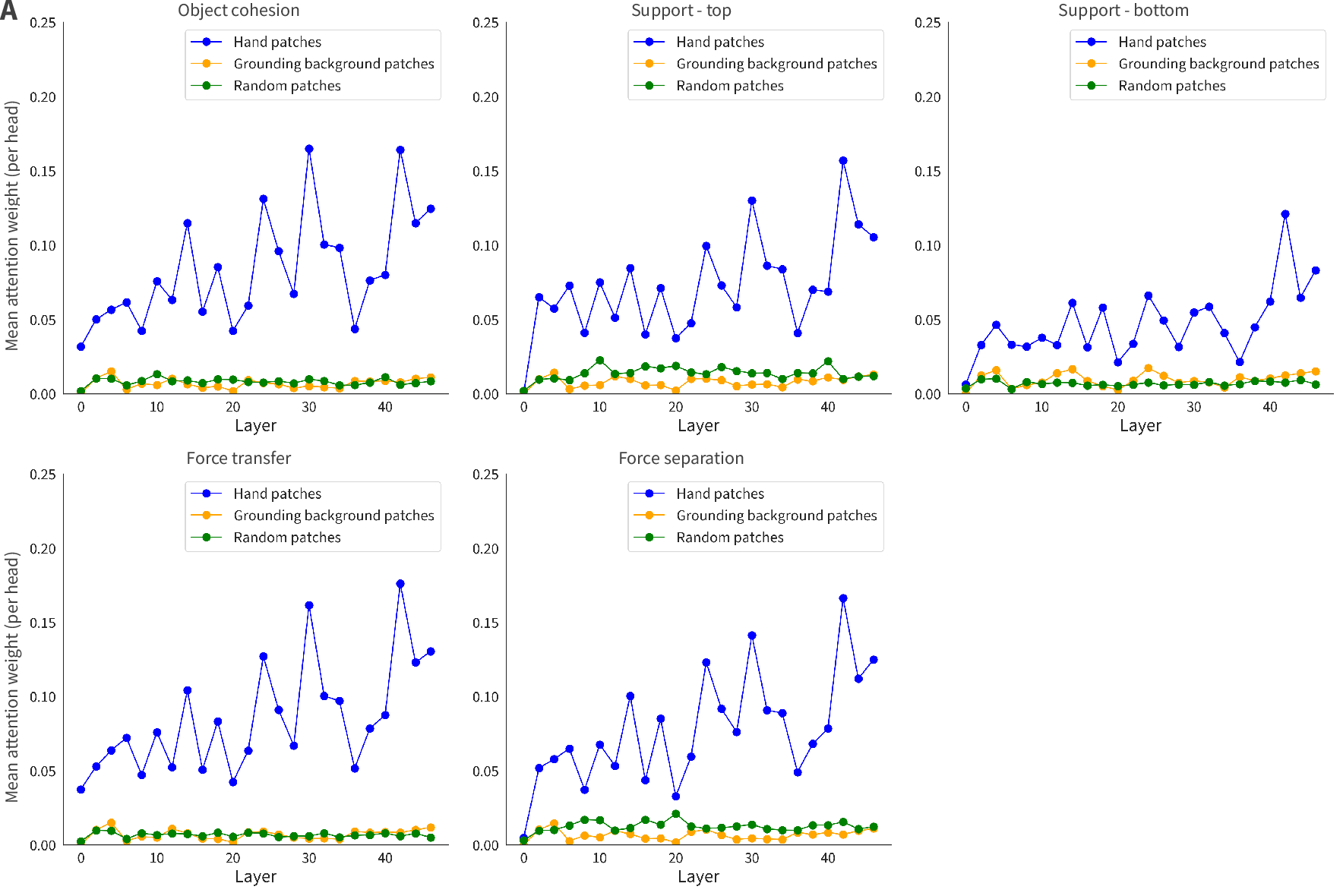
- Interpretability beyond anecdotes: attention-head “hand tracking” is shown qualitatively; systematic interpretability (network dissection, causal ablations, probing for object/physics variables) is not performed.
- Error analysis: detailed breakdowns of failure cases across tasks (scene types, object scale, texture, lighting, occlusion) are absent, limiting targeted progress.
- 3D scene representation: the model does not produce explicit 3D structure (shape, pose, camera parameters) or novel view synthesis; how to recover metric 3D from the learned predictor is unexplored.
- Semantics and language grounding: the approach does not address category/attribute/relation learning or language–vision grounding; how to integrate linguistic input and evaluate semantic zero-shot abilities remains open.
- Compositional generalization: it is unclear whether the system can systematically compose zero-shot primitives to solve novel/harder tasks (e.g., multi-step hypothetical chains) without manual design.
- Automatic thresholding/calibration: aggregators use heuristic thresholds; there is no self-calibrating mechanism or uncertainty-aware decision rule for zero-shot outputs across varied scenes.
- Physical reasoning breadth and horizon: the physics benchmark targets short-timescale, simple interactions; longer-horizon, multi-object, and parameterized phenomena (friction, elasticity, torque, center-of-mass) and VoE-style tests are not evaluated.
- Domain transfer: generalization to domains like robotics, driving, medical imaging, aerial footage, and third-person videos is untested; domain adaptation strategies for zero-shot readouts are unknown.
- Reproducibility details: core training/evaluation details are deferred to supplementary materials and code release; seeds, data preprocessing, augmentation policies, and prompt hyperparameters needed for exact replication are not yet available.
- Resolution and multi-scale limits: training at 256×256 with 8×8 patches may constrain small-object fidelity; scaling to higher resolutions and multi-scale architectures is unexamined.
- Occlusion representation: although occlusion detection is scored, the model’s explicit encoding of occlusion states and its ability for long-term re-identification behind occluders are not probed.
- Safety and adversarial robustness: susceptibility of zero-shot prompts to adversarial or spurious perturbations (in inputs or queries) is unknown, especially given the perturbation-based interface.
Practical Applications
Practical Applications of Zero-shot World Models (ZWM)
This paper introduces a self-supervised, temporally-factored visual world model that can extract optical flow, relative depth, object segmentation, and short-timescale physical reasoning zero-shot via a universal “perturb–compare–aggregate” prompting interface. Because ZWM achieves competitive performance with supervised baselines using only hundreds of hours of uncurated video (including single-child data), it opens immediate and longer-term applications across sectors where labeled data are scarce or expensive.
Immediate Applications
- Zero-shot perception modules for robots and drones
- Sectors: robotics, logistics, warehousing, agriculture, inspection.
- What: Drop-in optical flow, relative depth, and class-agnostic object segmentation for navigation, obstacle avoidance, grasping pre-shaping, and tracking without task-specific labels.
- Tools/products/workflows: ROS/ROS2 nodes wrapping ZWM’s predictor and zero-shot prompts; on-robot inference for flow and segmentation; fleet-wide self-supervised updates from in-situ video.
- Assumptions/dependencies: Domain shift from BabyView videos to robot camera streams must be evaluated; short-timeframe prediction is strong but long-horizon forecasting remains limited; embedded compute must handle ViT-based inference; safety testing needed for deployment.
- Real-time AR/VR occlusion and interaction effects
- Sectors: AR/VR, gaming, creative software.
- What: Zero-shot depth and segmentation to support realistic occlusion, hand-object interactions, background matting, and scene relighting.
- Tools/products/workflows: AR SDK plugins that call the perturb–compare–aggregate interface for per-frame depth/seg in headsets or phones; rotoscoping tools for video editors.
- Assumptions/dependencies: Frame-rate and latency constraints require optimized inference; very dynamic or low-light scenes may degrade accuracy; SAM2 currently outperforms in some segmentation cases.
- Label-free video analytics for retail and sports
- Sectors: retail analytics, smart buildings, sports analytics, security.
- What: Zero-shot tracking, motion flow patterns, occlusion detection for footfall counting, crowd flow, player movement analysis.
- Tools/products/workflows: CCTV analytics dashboards powered by ZWM flow/segment outputs; no per-site labeling; plug-ins for existing VMS (video management systems).
- Assumptions/dependencies: Privacy regulations and consent; robustness to diverse camera viewpoints; calibration for camera-specific artifacts.
- Industrial monitoring and quality control
- Sectors: manufacturing, energy, utilities.
- What: Detect motion anomalies, object misalignments, or unexpected dynamics on lines or in plants via flow/segment cues without labeled defect sets.
- Tools/products/workflows: Edge devices running ZWM for conveyor monitoring; alerting pipelines that flag deviations in computed optical flow fields and object cohesion.
- Assumptions/dependencies: Domain adaptation from natural scenes to industrial imagery; lighting variability; integration with existing SCADA/MES systems.
- Assistive mobile vision for obstacle awareness
- Sectors: accessibility, consumer mobile.
- What: On-device zero-shot depth and motion cues to warn about obstacles and moving objects for low-vision users.
- Tools/products/workflows: Smartphone apps that use device cameras for relative depth and flow; haptic/audio feedback based on ZWM outputs.
- Assumptions/dependencies: Must meet strict reliability and latency requirements; energy constraints on mobile; rigorous user testing and safety evaluation.
- Academic toolkit for developmental and cognitive science
- Sectors: academia (psychology, neuroscience, cognitive science).
- What: Use BabyZWM’s developmental trajectories and brain-alignment analyses to design/model infant-like benchmarks and test hypotheses about hierarchical visual development.
- Tools/products/workflows: Open-source release of ZWM training/eval code; standardized benchmark suites (optical flow, depth, object knowledge, short-timescale physics).
- Assumptions/dependencies: Pending public code/data release; careful interpretation to avoid overclaiming equivalence between model and human development.
- Brain-alignment probes for neuroscience datasets
- Sectors: neuroscience, neuro-AI.
- What: Rapidly screen model layers for predictivity against fMRI/electrophysiology datasets, exploring early-first developmental signatures and layer–area correspondences.
- Tools/products/workflows: Reproducible pipelines to fit linear probes from ZWM features to neural data (e.g., NSD, TVSD).
- Assumptions/dependencies: Access to neural datasets; controlling for measurement noise and data splits; interpretability limits of linear mappings.
- Software library for “world-model prompting”
- Sectors: software/ML tooling, MLOps.
- What: Provide a general API to compose perturb–compare–aggregate routines for new zero-shot visual tasks (e.g., motion saliency, parts segmentation, support relations).
- Tools/products/workflows: Python library with composable modules (perturbations, comparators, aggregators) and task templates; integration with PyTorch/ONNX runtimes.
- Assumptions/dependencies: Performance engineering for production; careful UX to prevent misuse in out-of-scope tasks; license compliance when training on new data.
- Privacy-lean data strategies for vision projects
- Sectors: enterprise AI, startups, public sector.
- What: Reduce dependence on large curated labeled datasets by adopting ZWM-style self-supervision on small, owned video corpora to unlock key perception functions.
- Tools/products/workflows: Internal pipelines to collect short, consented video streams; training schedules patterned on single-pass/age-ordered curricula; validation against public benchmarks.
- Assumptions/dependencies: Legal/ethical data collection; compute budget for pretraining; robust internal evaluation to manage generalization risks.
Long-Term Applications
- Foundation “world model” for general-purpose vision
- Sectors: cloud AI, platform providers, software.
- What: A cloud API that delivers zero-shot flow, depth, segmentation, and short-horizon physical reasoning across domains—analogous to LLMs in NLP but for visual cognition.
- Tools/products/workflows: Managed service with compositional prompting; task graphs configurable via API; billing per inference/graph.
- Assumptions/dependencies: Robustness across domains; scaling model sizes and training data beyond BabyView; strong monitoring and red-teaming for failure modes.
- In-home robots that learn from a single household
- Sectors: consumer robotics, eldercare, domestic automation.
- What: Robots trained on a few hundred hours of the target home’s video to personalize perception (layout, objects) with minimal/no labels.
- Tools/products/workflows: On-prem self-supervised pretraining; continual learning that respects privacy; plug-in MPC that uses ZWM’s predictions for planning.
- Assumptions/dependencies: Safe continual learning (mitigate catastrophic forgetting); action-conditioned extensions to move from proxy perturbations to real control; robust human–robot interaction protocols.
- Model-predictive control with data-driven world models
- Sectors: robotics, autonomous systems.
- What: Integrate ZWM into MPC/MBRL loops, using its short-horizon predictions and causal hypotheticals to evaluate action sequences.
- Tools/products/workflows: Controllers that query ZWM with counterfactuals; hybrid pipelines that combine ZWM with proprioception and dynamics models.
- Assumptions/dependencies: Extend predictor from “proxy actions” (pixel patch perturbations) to action-conditioned inputs; address mode collapse and uncertainty with stochastic/ensembled predictors; real-time constraints.
- Self-supervised medical imaging workflows
- Sectors: healthcare (ultrasound, endoscopy, surgical video).
- What: Adapt temporally-factored masked prediction and causal prompting to dynamic medical modalities for zero-/few-shot segmentation, motion tracking (e.g., cardiac wall motion).
- Tools/products/workflows: Domain-trained ZWM variants on anonymized clinical sequences; interactive tools where clinicians “probe” structures via hypotheticals.
- Assumptions/dependencies: Extensive domain retraining; regulatory approval; clinical validation; strict privacy and data-governance compliance.
- Unified embodied AI stacks in simulation-to-real
- Sectors: robotics, autonomy R&D.
- What: Use compositional prompting over learned dynamics to build higher-level physical concepts (support, cohesion) that can guide policy learning and reduce sim2real gaps.
- Tools/products/workflows: RL agents that query ZWM for affordances; curriculum learning that mirrors age-ordered single-pass training.
- Assumptions/dependencies: Longer-horizon modeling; uncertainty-aware predictions; robust transfer from synthetic to real-world videos.
- Education and developmental assessment tools
- Sectors: education, developmental science, pediatrics (research).
- What: Automated analysis of infant/child video (with consent) to study developmental milestones in object tracking, depth cues, and physical reasoning, aiding research and screening.
- Tools/products/workflows: Research platforms that quantify visual-cognitive behaviors from home/clinic videos; longitudinal analytics.
- Assumptions/dependencies: Strong ethical oversight; bias and fairness analysis across demographics; clinical-grade validation before any screening use.
- Neuro-inspired benchmarking and co-design
- Sectors: neuroscience, AI research.
- What: Co-develop models and experiments that align layer-wise representations with cortical areas, using ZWM’s early-first trajectories to guide dataset design.
- Tools/products/workflows: New public benchmarks that tie behavior and neural data; “mechanistic mapping” toolkits for model–brain comparison.
- Assumptions/dependencies: Availability of high-quality neural datasets; agreement on standardized metrics and noise ceilings; interdisciplinary collaboration.
- On-device privacy-preserving training for vision
- Sectors: mobile, IoT, smart home.
- What: Train ZWM variants locally on-device using owners’ video for personalized perception without uploading data.
- Tools/products/workflows: Federated/self-supervised training; energy-aware schedules (e.g., during charging); distillation to smaller edge models.
- Assumptions/dependencies: Hardware acceleration; model compression; lifecycle management to prevent drift and maintain safety.
- Urban mobility and infrastructure analytics
- Sectors: transportation, city planning, public safety.
- What: Zero-/few-shot traffic flow estimation, occlusion-aware tracking, and near-miss detection from public cameras without massive labeling efforts.
- Tools/products/workflows: Municipal dashboards; incident detection and congestion prediction using flow/segment outputs.
- Assumptions/dependencies: Public consent and governance; camera diversity; rigorous evaluation under adverse weather/night conditions.
- Multimodal semantic–physical foundation models
- Sectors: AI platforms, robotics, education.
- What: Combine ZWM’s physical world modeling with language to support semantic queries over physical reasoning (e.g., “Is the mug supported?”).
- Tools/products/workflows: Vision–language–world model stacks that respond to textual prompts by composing visual hypotheticals.
- Assumptions/dependencies: Integration with strong LLMs; joint training objectives; careful control to prevent hallucination in safety-critical contexts.
Notes on feasibility across applications:
- ZWM excels at short-timescale, physically grounded perception; longer-horizon prediction and uncertainty modeling are future work.
- Current model sizes (≈170M–1B parameters) require performance engineering for edge deployment.
- Domain adaptation is essential when moving from natural egocentric videos to specialized domains (industrial, medical).
- The universal zero-shot interface reduces labeling needs but does not eliminate the need for rigorous validation, monitoring, and safety assurance in production.
Glossary
- approximate causal inference: Estimating causal effects by contrasting outcomes under minimal input perturbations rather than through explicit interventions. "ZWM's approach to zero-shot extraction is a form of approximate causal inference."
- bootstrap 95% intervals: Resampling-based confidence intervals that estimate uncertainty by drawing many samples with replacement. "Error bars indicate bootstrap 95% intervals throughout the paper."
- compositional prompting: Combining simple prompts or queries to build more complex inferences from a model. "Compositional prompting."
- computational graph: A structured composition of intermediate computations or representations that a model uses to solve tasks. "this composition builds a computational graph of visual intermediates."
- egocentric video: First-person viewpoint recordings captured from the subject’s perspective. "a set of egocentric video recordings from young children aged ∼5 months to 5 years."
- hierarchical visual organization: The arrangement of visual processing stages from low-level to high-level areas in the visual cortex. "This exhibits neuroanatomical consistency with several accounts of hierarchical visual organization."
- inter-frame gap: The time interval between two adjacent frames used by a model. "with an inter-frame gap sampled uniformly between 150ms and 450ms."
- intuitive physics: Human- or model-like reasoning about object dynamics and physical interactions without explicit equations. "BabyZWM exhibits object knowledge and intuitive physics."
- linear probe: A linear mapping trained atop fixed model features to predict target variables (e.g., neural responses). "fit a cross-validated linear probe from model features to neural responses"
- LPIPS: Learned Perceptual Image Patch Similarity; a metric that approximates human perceptual judgments of image similarity. "using mean squared error and LPIPS perceptual similarity"
- masked autoencoder: A model trained to reconstruct missing parts of its input from the visible parts. "Ψ is a type of masked autoencoder"
- mode collapse: A failure mode where a model outputs limited or averaged predictions, losing diversity or sharpness. "ZWM's Ψ predictor is subject to mode collapse, leading to blurry predictions"
- model-based reinforcement learning: RL that uses a learned or known model of the environment’s dynamics to plan actions. "within model-based reinforcement learning"
- model-predictive control: A control strategy that plans actions by predicting future states and optimizing over a receding horizon. "and model-predictive control"
- motion tokens: Compact latent variables encoding motion information that can be manipulated for downstream inference. "the highly compressed but interpretable motion tokens that the training process creates"
- neural predictivity: The extent to which model features can predict brain responses to the same stimuli. "by computing neural predictivity"
- noise ceiling: The maximum achievable prediction performance given the inherent noise in the measured data. "reaching V1's noise ceiling at an earlier checkpoint."
- noise-corrected correlations: Correlation measures adjusted to account for measurement noise in the target signals. "then report noise-corrected correlations"
- object segmentation: Partitioning an image into regions corresponding to distinct objects. "We evaluate object segmentation on SpelkeBench"
- occlusion: The visual phenomenon where one object blocks the view of another. "real-world motion, occlusions, and lighting changes"
- optical flow: The pixel-wise apparent motion between two frames of a video. "the compare function computes the optical flow between the perturbed and unperturbed cases"
- out-of-distribution generalization: Performing well on data that differ from the training distribution. "ZWM achieves zero-shot, out-of-distribution generalization to challenging real-world scenes, synthetic simulations, and flipped images."
- patchified: The process of dividing an image into small, fixed-size patches for model input. "and then patchified into 8x8-pixel patches."
- perceptual similarity: A similarity measure aligned with human perception rather than raw pixel differences. "LPIPS perceptual similarity"
- proxy actions: Synthetic or surrogate input perturbations used to mimic actions for causal probing of a model. "forecast the effect of proxy actions on the visual scene."
- readout (task-specific readout): A supervised mapping from general-purpose features to specific task outputs. "In representation learning, each downstream task needs its own labeled readout"
- relative depth estimation: Determining which of two points is closer or farther in depth. "Relative depth method (built on optical flow)."
- self-supervised learning: Learning representations from unlabeled data via pretext or predictive objectives. "These issues motivated a shift to self-supervised models"
- stereopsis: Depth perception arising from binocular disparity between the two eyes. "echoing early stereopsis"
- stochastic gradient descent: An iterative optimization algorithm that updates parameters using mini-batches of data. "perform learning via stochastic gradient descent on its parameters."
- structural equation: A functional relationship in a causal model that maps causes to effects. "the Ψ function acts as a learned structural equation for the world's dynamics"
- temporally-factored prediction: A modeling approach that separates appearance from dynamics across time for prediction. "temporally-factored prediction to flexibly separate appearance from dynamics"
- ventral stream: The visual pathway associated with object recognition and form representation. "noise-corrected neural predictivity for the ventral stream for NSD human fMRI."
- Vision Transformer (ViT): A transformer-based neural architecture adapted for images by operating on patch tokens. "The base network architecture is a Vision Transformer (ViT) backbone"
- world model: A model that captures environmental dynamics to predict consequences of (real or proxy) actions. "form a kind of data-driven 'world model'"
- zero-shot: Performing a task without any task-specific training or examples. "perform diverse visual-cognitive tasks zero-shot"
- zero-shot prompting interface: A standardized way to query a model zero-shot via minimal input perturbations. "a universal zero-shot prompting interface"
Collections
Sign up for free to add this paper to one or more collections.

