- The paper presents a dual-method debiasing framework, DebiasFirst, that effectively mitigates positional bias in LLM-based reranking through IPS calibration and data augmentation.
- It employs Inverse Propensity Scoring to recalibrate loss terms and reduce the overemphasis on early-ranked passages in standard RoPE-based LLM architectures.
- Empirical results on MS MARCO and BEIR benchmarks show a 2–4% gain in NDCG@10, highlighting improved robustness and fairness in ranking.
LLM-based Listwise Reranking under the Effect of Positional Bias: An Expert Review
Introduction and Motivation
Positional bias in LLM-based listwise passage reranking is a structural and data-driven challenge that degrades model reliability and fairness in IR applications. The paper "LLM-based Listwise Reranking under the Effect of Positional Bias" (2604.03642) addresses the non-trivial dependency of final ranking results on initial item input positions—particularly, the suboptimal treatment of relevant passages that do not appear at the start of the input list. This phenomenon is rooted in both LLM architecture (e.g., RoPE-induced attention decay) and training data distribution, where relevant documents are systematically imbalanced across input positions.
Causal Analysis of Positional Bias
The authors provide a rigorous causal analysis, disentangling architectural and data-induced sources of positional bias. They illustrate, via a directed acyclic graph, how both LLM architecture and input data distribution propagate bias into the model's predictions, affecting the final reranking permutation.
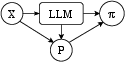
Figure 1: Causal graph outlining how input (X) and LLM architecture interact to generate positional bias (P) and affect the reranked output (π).
Notably, LLMs with standard RoPE-based encodings tend to prioritize content near the query cue, with empirical results showing consistent degradation in ranking performance as relevant passages are moved to later input positions. Data analysis on MS MARCO further reveals the overrepresentation of relevant passages in early ranks, inherently training models to reinforce such position bias.
The DebiasFirst Method
To address positional bias both at the algorithmic and data levels during fine-tuning, the paper introduces DebiasFirst, a two-stage debiasing paradigm:
- Positional Calibration via Inverse Propensity Scoring (IPS): Loss terms are adaptively weighted by the inverse of empirically estimated transition propensities between input and output positions. This explicitly down-weights overrepresented transitions (e.g., passages frequently relevant at early input positions and top reranks) and amplifies rarely observed transitions, ensuring more uniform learning and gradient updates.
- Position-Aware Data Augmentation (Pos-Aug): The training set is systematically augmented so that each passage identifier is observed in every possible input position over different training samples. This regularizes the model, decoupling passage content from positional priors and stabilizing ranking performance across a range of input orders.
The architecture and workflow for positional calibration using IPS are depicted below.
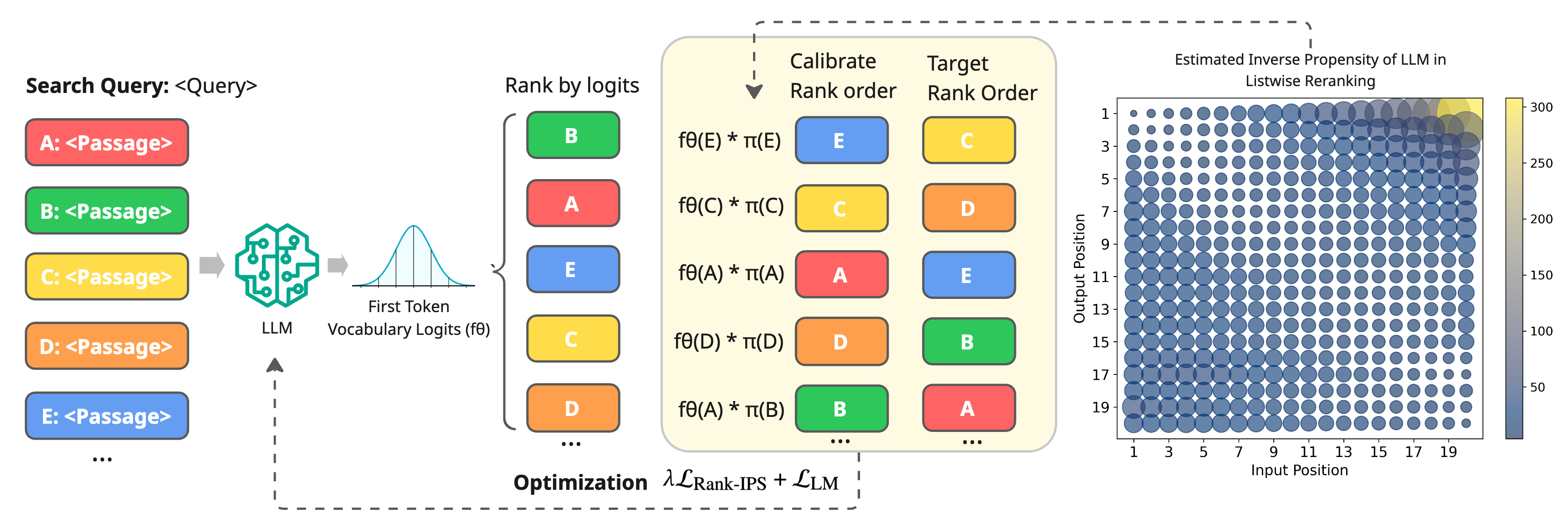
Figure 2: Schematic overview of positional calibration using IPS, including heatmap visualization of estimated propensities across input and output positions.
Position-aware augmentation is further illustrated with the distribution of passages before and after augmentation.
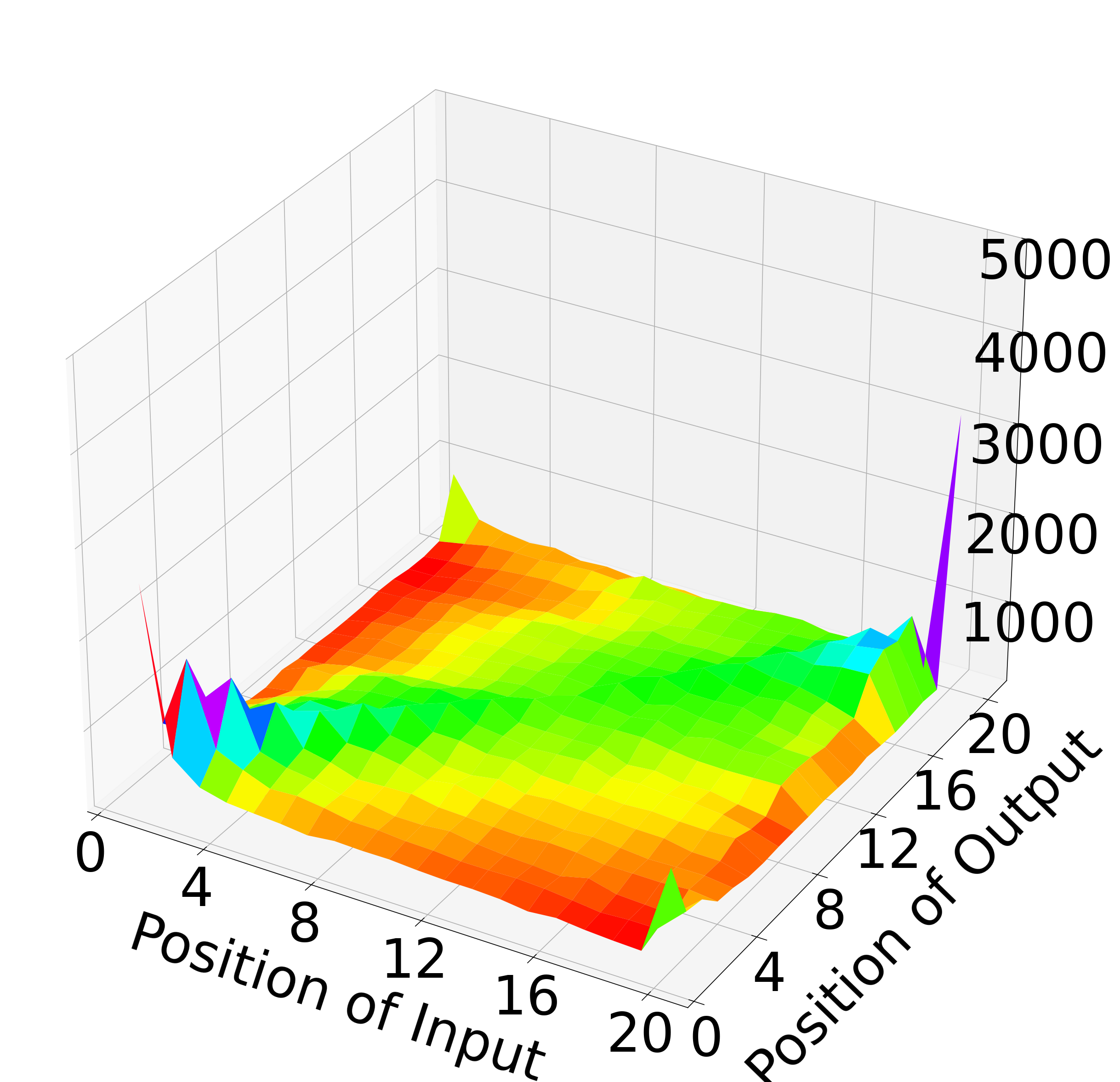
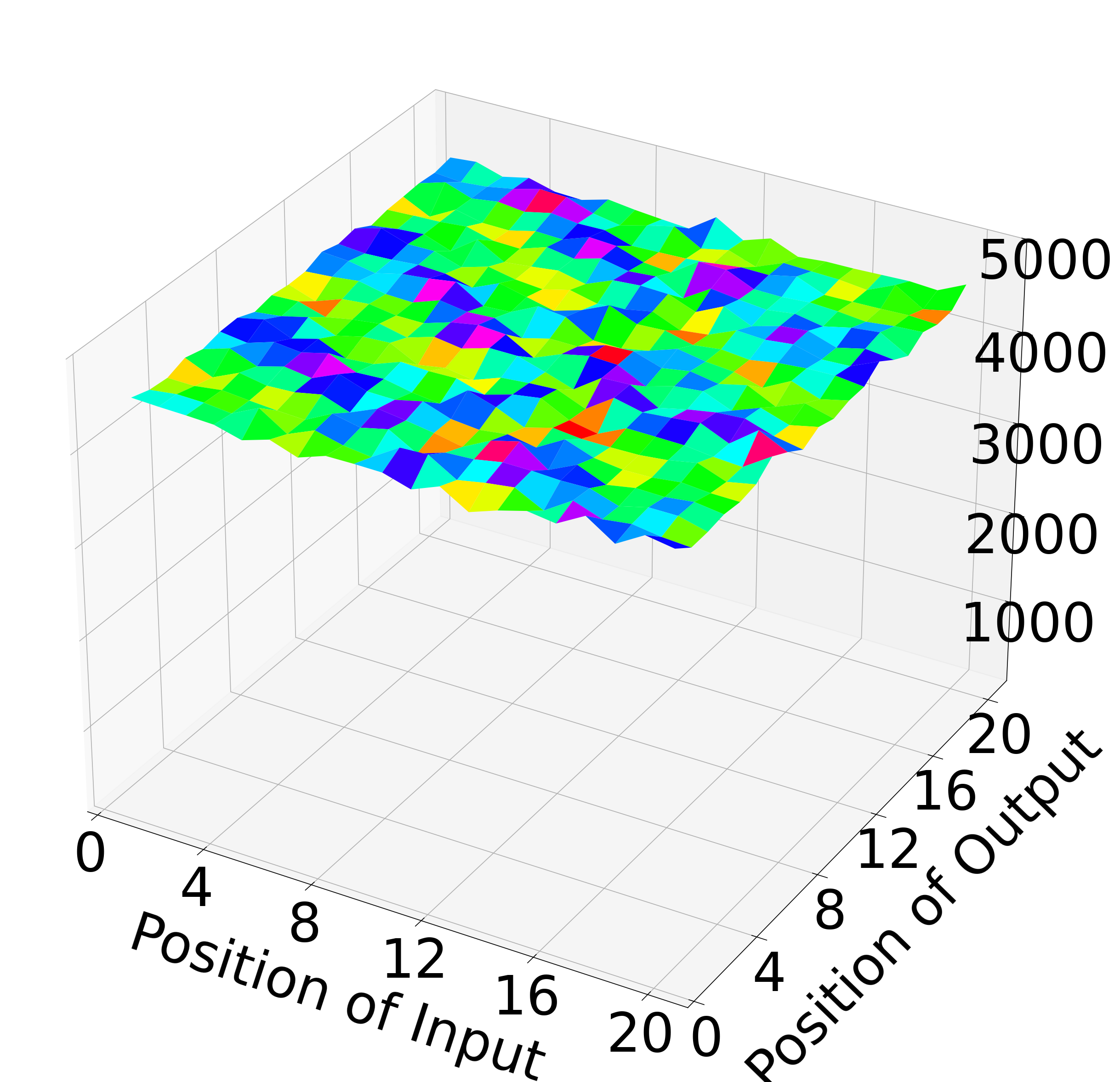
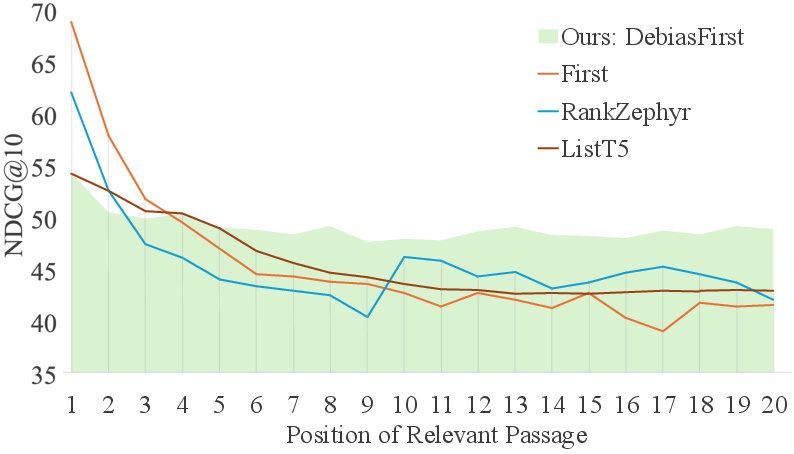
Figure 3: Histogram of passage transitions: the original (left) and augmented (right) training distributions over input and ground-truth reranking positions.
Controlled Experiments and Empirical Results
The controlled evaluation places relevant passages at systematically varied positions, evaluating NDCG@10 to diagnose positional robustness. DebiasFirst offers stable results across all positions, in contrast to a substantial drop observed in non-debiased and randomly augmented models when relevance appears away from the head of the list.
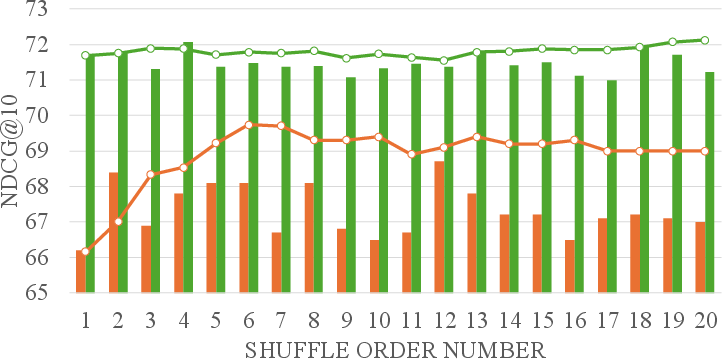
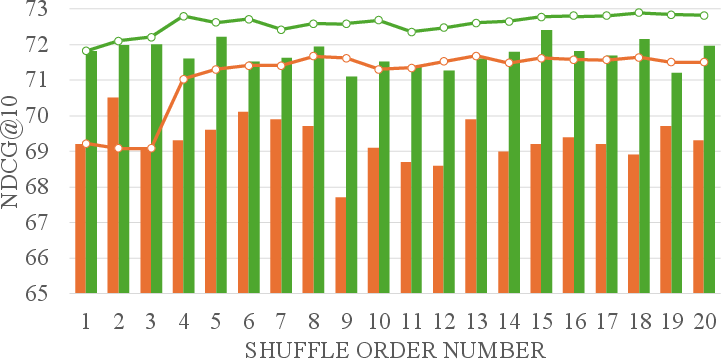
Figure 4: NDCG@10 evaluation curves under systematic position control on MS MARCO Dev.
Numerical Highlights:
- On in-domain (MS MARCO, TREC DL 2019/2020) and out-of-domain (12 BEIR tasks) benchmarks, DebiasFirst delivers consistent average gains (2–4% improvement) in NDCG@10 versus RankZephyr, ListT5, and FIRST baselines.
- Robustness is maintained across variable first-stage retrievers (BM25, Contriever, Splade++, RRF fusion), with DebiasFirst universally outperforming the non-debiased counterpart, especially when passage order is randomized.
The method's efficacy surpasses inference-stage debiasing baselines such as PermSC, with the complementary application of PermSC yielding further (albeit saturated) improvements.
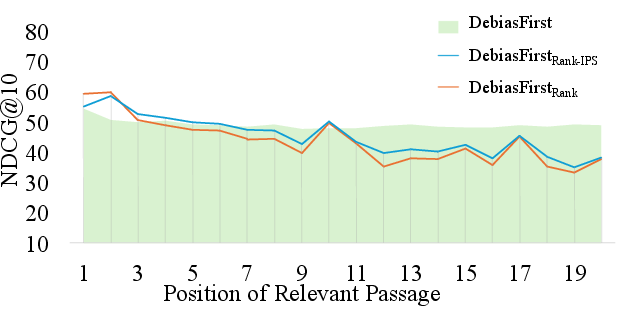
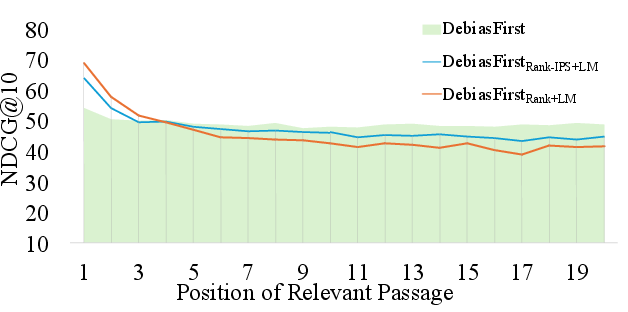
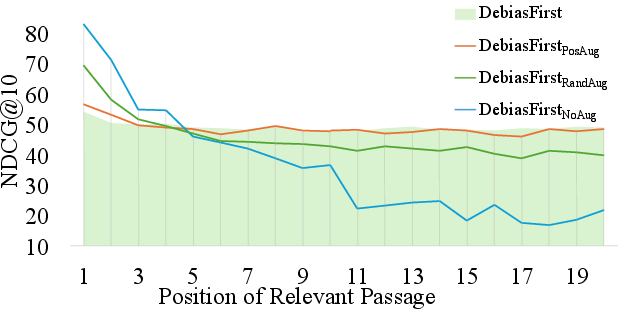
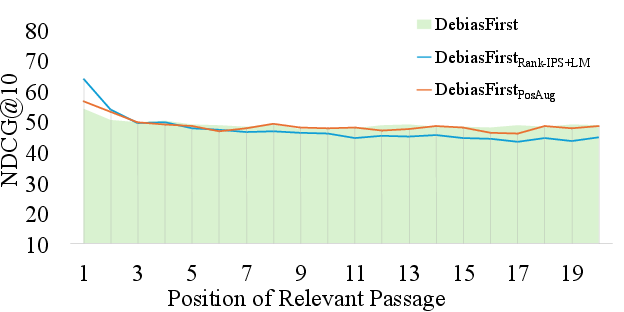
Figure 5: Comparative DL2019 performance of IPS strategies: ablated controls with/without LM loss and with/without data augmentation.
Ablation Analysis
The controlled ablation study establishes:
- IPS calibration alone reduces positional performance variance sharply, but combining with language modeling (LM) objective further stabilizes and enhances NDCG throughout.
- Position-aware augmentation outperforms random augmentation: models without Pos-Aug decline sharply at later positions, whereas Pos-Aug achieves minimal performance drop, evidencing its necessity for robust reranking.
- The synergy of both modules (IPS + Pos-Aug) delivers the lowest variance and maximal average performance, indicating additive benefits.
Implications and Future Directions
The results have implications beyond passage reranking: the demonstration that fine-tuning LLMs with explicit counter-positional calibration yields more order-invariant, fair, and robust rankers generalizes to long-context evaluation, recommendation systems, and federated retrieval, where positional priors are either uncontrolled or mismatched between training and deployment.
A theoretical limitation of the current study is the restriction to 20-passage input windows. Scaling positional debiasing methods (both IPS and Pos-Aug) to long-sequence (100+ items) regimes, as required for full-document or real-time feeds, remains open. Future research should examine the impact of long-context biases, their interaction with advanced positional encoding schemes, and domain-specific adaptation of propensity models.
Conclusion
"LLM-based Listwise Reranking under the Effect of Positional Bias" (2604.03642) provides a concrete algorithmic and empirical framework for mitigating both architectural and data-driven sources of positional bias in LLM-based reranking. By dual application of IPS-based loss calibration and systematic positional data augmentation, the authors demonstrate both substantial gains in average performance and variance reduction across real-world IR benchmarks and retriever backends. This work sets a rigorous standard for future evaluation and debiasing in neural ranking models and highlights the importance of considering input order as a first-class axis of evaluation and model design.