- The paper's main contribution is the development of DualEngage, a dual-stream architecture that fuses person-centric motion features with scene context using attention-guided transformers and adaptive gating.
- It leverages dense optical flow for individual motion capturing and a 3D ResNet backbone for scene-level analysis to overcome challenges like occlusions and multi-person interactions.
- Experiments on the OUC-CGE dataset demonstrate high accuracy (0.9621) and macro-F1 (0.9530), outperforming single-stream approaches and validating the model’s robustness.
Attention-Guided Dual-Stream Learning for Group Engagement Recognition
Introduction and Motivation
Recognition of student engagement at the group level, especially in in-situ classroom settings, remains a challenging task due to the complex interplay of individual behavior and collective dynamics. While most automated engagement recognition approaches have focused on individual-level analysis or online learning contexts, classroom environments present unique hurdles, such as occlusions, multi-person interactions, and highly variable group behaviors. The paper "Attention-Guided Dual-Stream Learning for Group Engagement Recognition: Fusing Transformer-Encoded Motion Dynamics with Scene Context via Adaptive Gating" (2604.10078) proposes DualEngage, a dual-stream deep neural architecture that addresses this gap using a synergistic combination of person-centric motion features and global scene context.
The study positions group engagement as a multimodal construct, influenced by both the fine-grained temporal evolution of individual behaviors and the macro-scale coordination observed at the group level. To this end, the proposed system operationalizes engagement recognition as a joint inference problem over both modalities, leveraging recent advances in dense optical flow estimation, transformer-based temporal modeling, and adaptive feature fusion.
Methodology
Data Processing and Preliminaries
The evaluation leverages the OUC-CGE dataset, which comprises thousands of annotated classroom video clips across variable layouts (round-table, chessboard). Each clip is meticulously preprocessed: frame rates are normalized to 30 fps, durations aligned to 10 seconds, and faulty samples discarded to ensure data integrity. The dataset annotations emphasize observable behavioral engagement, consistent with ICAP-aligned criteria.
Dual-Stream Architecture
Person-Level Motion Stream
The primary stream is dedicated to individual behavioral dynamics:
- Detection and Tracking: Student bounding boxes and identity tracks are extracted using OpenMMLab frameworks, specifically Faster R-CNN for detection and Deep SORT for identity tracking. This handles frequent occlusions and interruptions in student visibility.

Figure 1: Robust multi-layout detection and identity tracking are required for downstream motion modeling.
- Motion Feature Extraction: For every detected student, dense optical flow is estimated frame-to-frame using RAFT, providing per-student "motion tubes" that encode subtle movements, posture shifts, and gestures—particularly effective when pose estimation is unreliable in crowded classroom scenes.
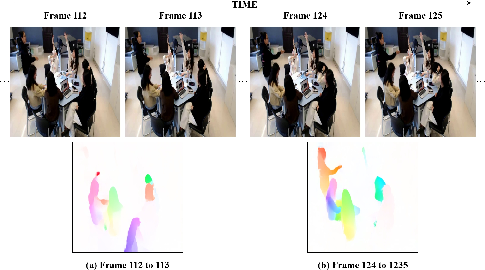
Figure 2: Example of dense optical flow capturing subtle temporal dynamics between frames.
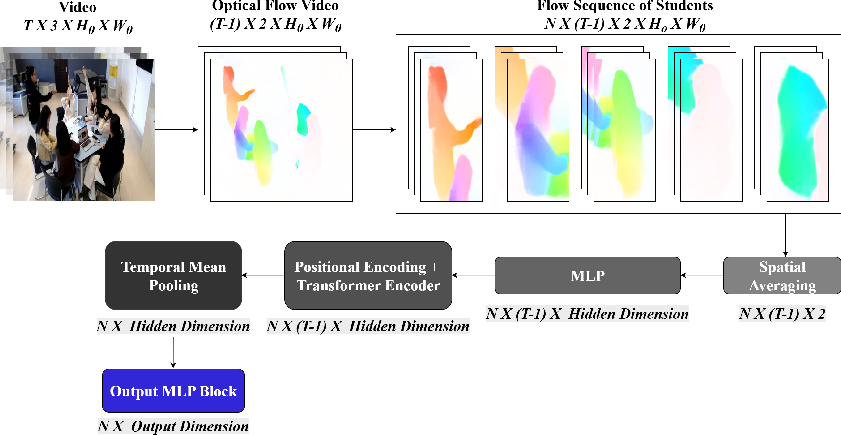
Figure 3: Pipeline from raw clip to per-student motion tubes, transformer modeling, and stacked feature construction.
- Temporal Encoding: A transformer encoder processes the student motion tubes, capturing long-term dependencies in behavioral transitions. Instead of naive pooling, an attention mechanism weights the temporal embeddings of students, increasing salience for those exhibiting clear engagement cues.
Scene-Level Stream
The secondary, scene-level stream captures the full spatiotemporal context unavailable in local motion cues:
- 3D Convolutional Backbone: A 3D ResNet-18, pretrained on Kinetics, ingests the full classroom scene, extracting features representing spatial configuration, group synchrony, and global activity context.
Adaptive Fusion
To reconcile the variable informativeness of each modality, the two feature streams are combined using softmax-gated adaptive fusion. This gating mechanism learns to weight the motion and scene representations per sample, thus downweighting unreliable motion features in low-movement frames while emphasizing scene context, and vice versa.
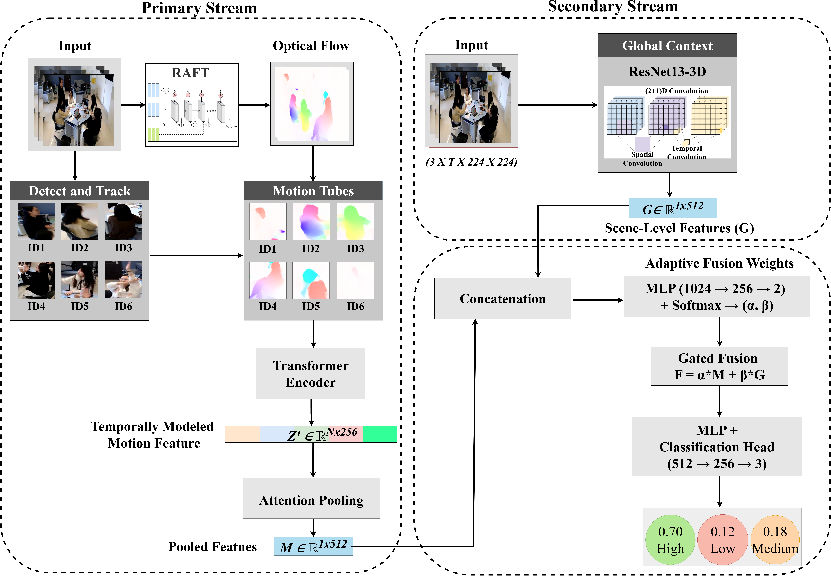
Figure 4: End-to-end schema of DualEngage, illustrating stream-wise feature extraction, attention aggregation, and gated fusion.
Experimental Results
Evaluation Protocol
Experiments involve stratified five-fold cross-validation on the OUC-CGE dataset. Metrics include accuracy and macro-averaged F1, reflecting performance across the three engagement classes (low, medium, high) under class imbalance. Training utilizes Adam optimization, class-balanced cross-entropy, and careful hyperparameter control.
DualEngage attains a mean accuracy of 0.9621±0.0161 and macro-F1 of 0.9530±0.0204, demonstrating stable generalizability across all engagement classes. The confusion matrices (Figure 5) show high per-class recovery, particularly for difficult mid-range and minority classes.
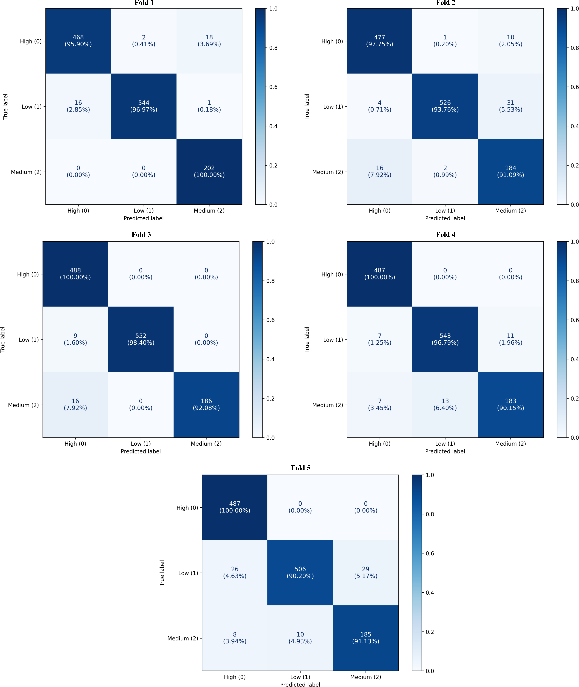
Figure 5: Five-fold confusion matrices highlighting fine-grained classification stability and residual inter-class ambiguity.
Notably, the macro-recall of $0.9561$ indicates reliable class resolution, and standard deviations across folds remain low, underscoring architectural robustness to split variability. DualEngage thus outperforms both scene-only and motion-only baselines by wide margins. The ablation study finds the dual-stream design, transform-based temporal modeling, attention pooling, and adaptive fusion all contribute major, independent performance improvements.
Qualitative Insights
Analysis of misclassifications reveals that confusion arises primarily in clips where static, high-engagement groups (e.g., attentive posture with little movement) are visually similar to low-engagement, low-motion cases. Visualizations (Figure 6) provide representative frames illustrating these ambiguous settings.

Figure 6: Visual samples underlining challenging cases—high engagement with static posture versus classic low engagement.
Theoretical and Practical Implications
The DualEngage design offers clear theoretical value: it empirically validates the necessity of multi-granular modeling—fusing explicit motion dynamics and global context—over simple, single-stream approaches for group social inference in real-world settings. The use of attention mechanisms allows the model to learn nuanced weighting across both students and modalities, effectively capturing the compositional nature of group engagement.
Practically, the approach is well-suited to real classroom deployments where crowded scenes, occlusions, or partial observations confound simpler vision-based cues. By relying on dense optical flow, the model circumvents the brittleness of pose estimation in such contexts. The adaptive fusion strategy increases interpretability and potential for domain adaptation to other group activity inference tasks.
Limitations and Future Directions
While DualEngage achieves strong performance, it is computationally demanding due to per-student RAFT inference and extensive tracking requirements. Failure cases typically involve heavy occlusion, persistent tracking loss, or ambiguous low-motion scenes, suggesting that future work should incorporate multimodal cues (e.g., gaze, teacher motion, audio) and more robust tracking primitives. Model efficiency could be improved by exploring lightweight flow estimation and self-supervised temporal modeling. Extensions might also investigate real-time architectures and privacy-preserving deployment in educational settings.
Conclusion
DualEngage demonstrates that joint modeling of person-level motion dynamics and holistic scene context, combined with attention-pooling and adaptive gating, is critical for accurate and reliable group engagement recognition in classroom videos. The architecture consistently outperforms single-stream alternatives and ablation variants, confirming the hypothesis that engagement dynamics are best understood as an interplay of individual and group processes. This work contributes a scalable, generalizable paradigm for group behavior analysis, providing a foundation for future research in automated educational analytics and beyond.
Paper Reference: "Attention-Guided Dual-Stream Learning for Group Engagement Recognition: Fusing Transformer-Encoded Motion Dynamics with Scene Context via Adaptive Gating" (2604.10078)