- The paper introduces a plug-and-play Wavelet Feature Stream that explicitly encodes joint-level time–frequency dynamics using continuous wavelet transform.
- It employs a dual-stream architecture with a multi-scale CNN to fuse spatial, temporal, and dynamic information, achieving state-of-the-art performance under challenging covariates.
- Empirical results on the CASIA-B dataset demonstrate significant improvements in recognition accuracy, particularly under altered clothing and carried object scenarios.
Explicit Time-Frequency Dynamics for Skeleton-Based Gait Recognition
Introduction
Recent advances in skeleton-based gait recognition have significantly improved the modeling of spatial and temporal joint configurations. However, such models often rely on implicit motion dynamics, limiting their robustness under conditions with substantial appearance changes. The paper "Explicit Time-Frequency Dynamics for Skeleton-Based Gait Recognition" (2604.03002) directly addresses this gap by proposing a plug-and-play Wavelet Feature Stream (WFS) that augments standard skeleton backbones with explicit time–frequency representations of joint velocities via the continuous wavelet transform (CWT). This framework consistently enhances recognition accuracy, particularly under challenging covariate scenarios such as altered clothing (CL) and carried objects (BG), and achieves new state-of-the-art (SOTA) performance among skeleton-based approaches.
Methodology
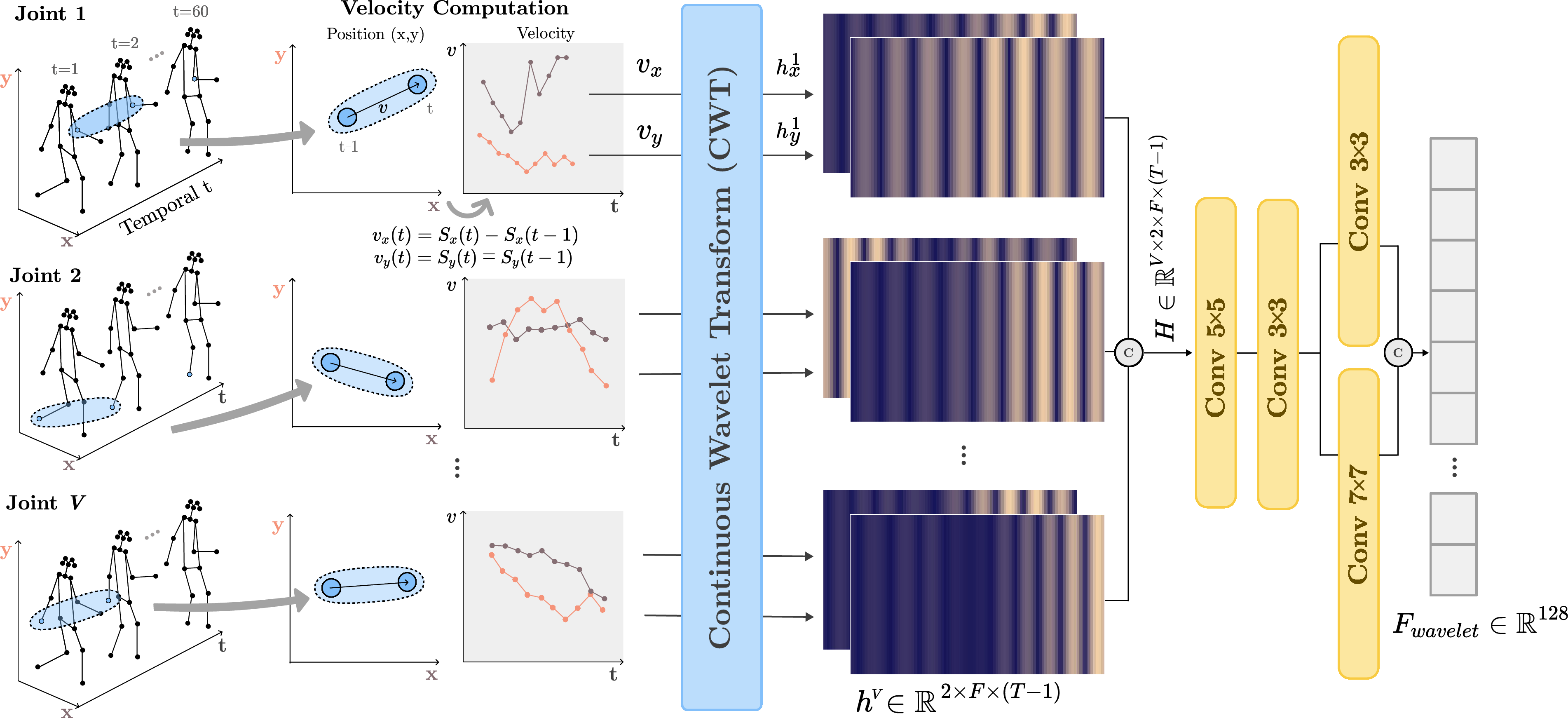
The proposed approach consists of a dual-stream architecture: a standard spatio-temporal backbone (e.g., GaitMixer, GaitFormer, or GaitGraph) and the Wavelet Feature Stream. The WFS explicitly encodes motion dynamics by leveraging per-joint velocities and their multi-scale time–frequency characteristics.
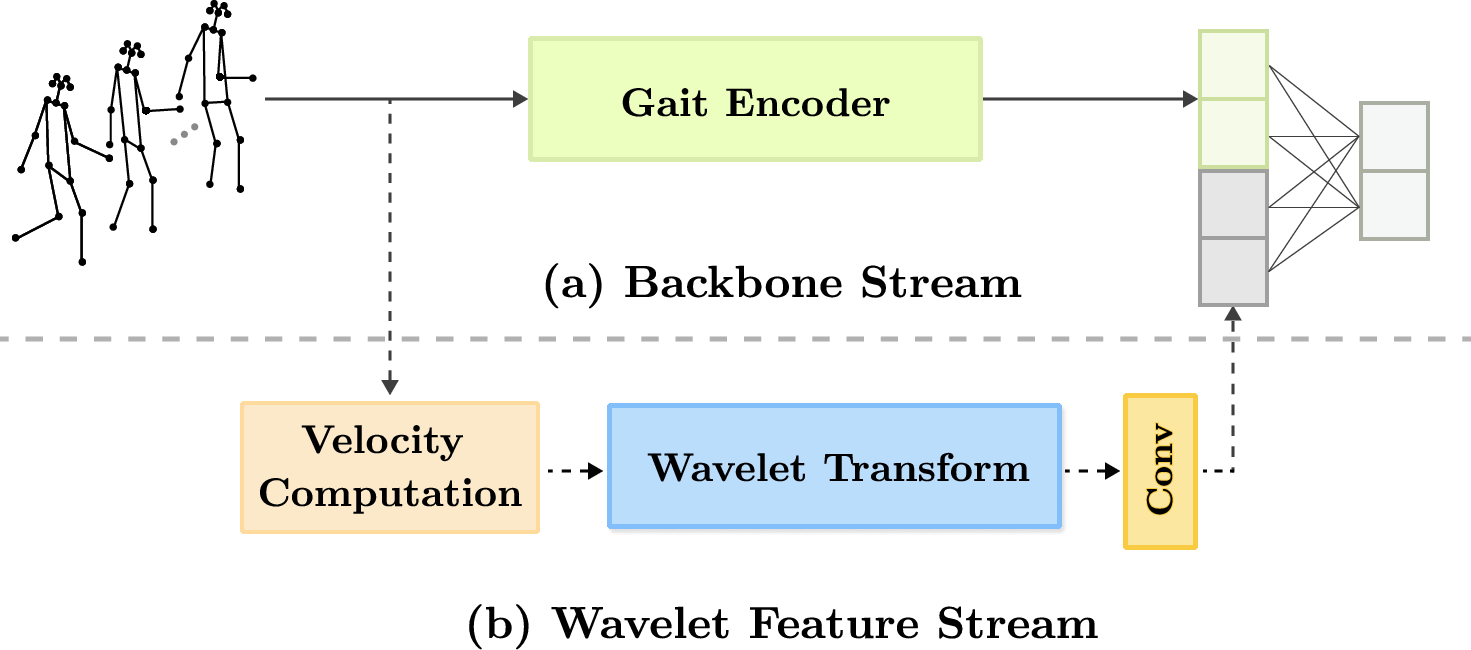
Figure 1: High-level overview of the Wavelet Feature Stream pipeline attached to a skeleton backbone, mapping per-joint velocities through CWT scalograms and a multi-scale CNN, ultimately fusing features for classification.
Wavelet Feature Stream
Loss and Optimization
A triplet loss with hard mining is deployed to ensure intra-identity compactness and inter-identity dispersion in the learned embedding space. Training protocols follow established gait recognition pipelines, with HRNet providing pose estimates and extensive evaluation on the CASIA-B dataset.
Experimental Results
The proposed WFS was empirically validated on the CASIA-B dataset, benchmarked both as a stand-alone module augmented to prominent skeleton backbones and in direct comparison with leading appearance-based models.
- SOTA Skeleton-Based Performance: When WFS is attached to GaitMixer, Rank-1 accuracy under NM (normal), BG (bag), and CL (coat) conditions reaches 95.1%, 87.2%, and 86.7%, respectively, establishing a new skeleton-based SOTA.
- Robust Gains Under Covariate Shift: The improvement is especially pronounced under the CL condition, where WFS-augmented GaitMixer surpasses all prior methods, including appearance-based 3DLocal, demonstrating both robustness to significant appearance changes and the complementary benefit of explicit time–frequency dynamic modeling.
- Plug-and-Play Effectiveness: The WFS enhances baseline GaitGraph (mean +3.7% under CL) and GaitFormer (+2.2% under CL), confirming its generalizability and straightforward integration capability across disparate backbone architectures.
- Wavelet Function Selection: An ablation on the choice of mother wavelet confirmed that Morlet offers superior joint time–frequency localization, which is crucial for capturing variability and periodicity in gait sequences.
Theoretical and Practical Implications
The findings reveal that explicit modeling of joint-level time–frequency structure can recover discriminative information often neglected by purely spatio-temporal deep architectures. Multi-scale CWT embedding provides a mathematically principled mechanism for extracting both short-range transients and long-term rhythm, yielding superior generalization under non-canonical conditions (e.g., occlusions, clothing, or carried objects). The plug-and-play formulation, requiring no architectural modifications to existing backbones or additional supervision, is notably appealing for practical deployment and for rapid benchmarking with diverse pose encoders.
Limitations and Future Directions
While the WFS demonstrates clear efficacy on CASIA-B, further validation across datasets and sensor modalities (e.g., inertial, multiview RGB-D) will be required for production-level adoption. Future research could explore end-to-end learnable wavelets, task-specific fusion mechanics, or self-supervised dynamic feature alignment. Cross-modal and cross-domain transfer learning using explicit time–frequency representations represents a promising research avenue, amplifying the potential for resilient, privacy-preserving gait biometrics.
Conclusion
The explicit fusion of time–frequency dynamics via a Wavelet Feature Stream marks an important advance for skeleton-based gait recognition. By leveraging CWT-based scalograms and a multi-branch CNN, the approach robustly augments backbone pose models, yielding consistent and substantial improvements under confounding covariates. The methodology sets a new SOTA for skeleton-based gait recognition and, critically, narrows the gap to appearance-based models under normal and BG conditions, while outperforming them under the challenging CL scenario. This work establishes explicit dynamic modeling as a central component for next-generation gait biometrics.