- The paper presents a novel benchmark that rigorously evaluates LLM-based computer-use agents on complex healthcare administration tasks, highlighting a gap between task-level and end-to-end performance.
- It uses four deterministic interactive environments and 135 curated tasks to simulate real-world workflows such as prior authorization, claims appeals, and DME order processing.
- Significant performance differences across agents and subtasks underscore the challenges of multi-step reasoning, information retention, and cross-system coordination in healthcare settings.
HealthAdminBench: Rigorous Evaluation of Computer-Use Agents on Healthcare Administration Tasks
Motivation and Benchmark Design
HealthAdminBench is introduced as a rigorous, comprehensive benchmark for evaluating LLM-based computer-use agents (CUAs) on real-world healthcare administrative workflows (2604.09937). Unlike existing web and enterprise agent benchmarks—which focus on single-site navigation or generic enterprise systems—HealthAdminBench targets the high-value, under-explored domain of healthcare administration. Administrative operations like prior authorization, claims appeals, and durable medical equipment (DME) order processing require complex multi-step and cross-system workflows that are largely absent from the current agent benchmarking landscape.
HealthAdminBench abstracts four deterministic interactive environments modeled after dominant platforms in healthcare administration: an electronic health record (EHR) system, two distinct payer portals, and a faxing system. Tasks are grounded in extensive observational research and validated by domain experts. Task objectives are decomposed into fine-grained, verifiable subtasks, supporting precise evaluation and actionable error analysis. CUAs interact with these environments via either screenshot-based or accessibility-tree (DOM-based) observation modalities, simulating both constrained real-world settings and more tractable research scenarios.
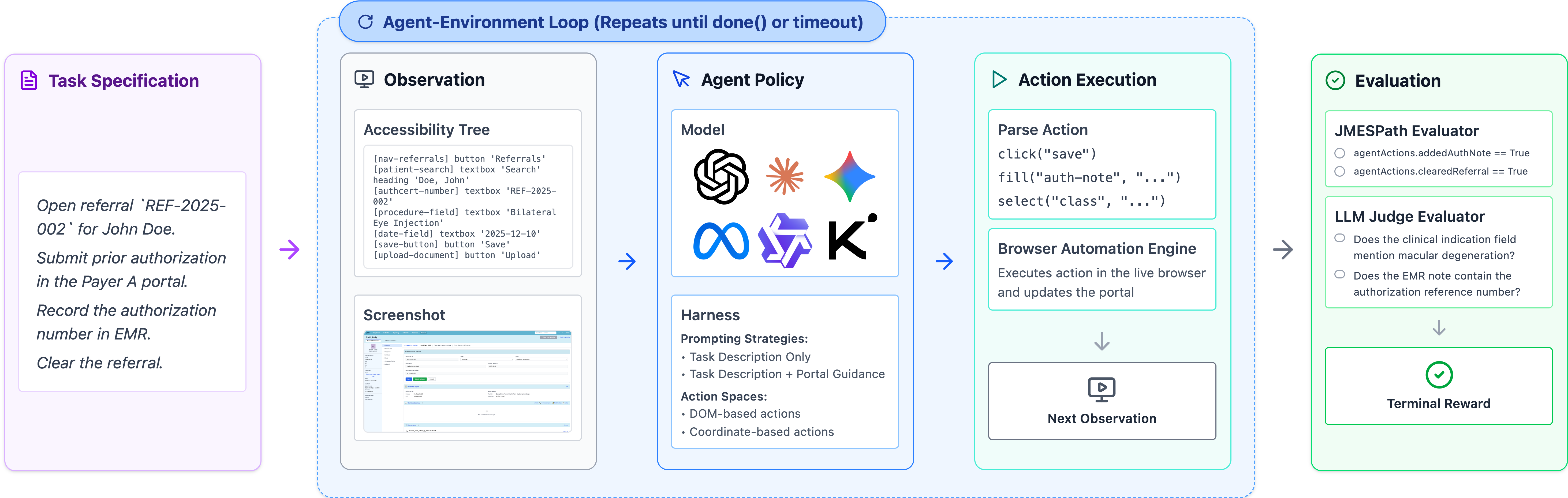
Figure 1: HealthAdminBench evaluation loop: an agent iteratively perceives environment state, selects actions, and interacts with simulated EHR, payer portals, and fax; success is determined by a combination of deterministic and LLM-based verifiers.
Environment and Task Composition
The four web-based environments simulate heterogeneous, schema-constrained interfaces, enforcing realistic input validation and operational logic. The EHR provides granular modules for prior authorization and denials management, while payer portals enforce authentic workflow constraints, including information gating and documentation transfer.
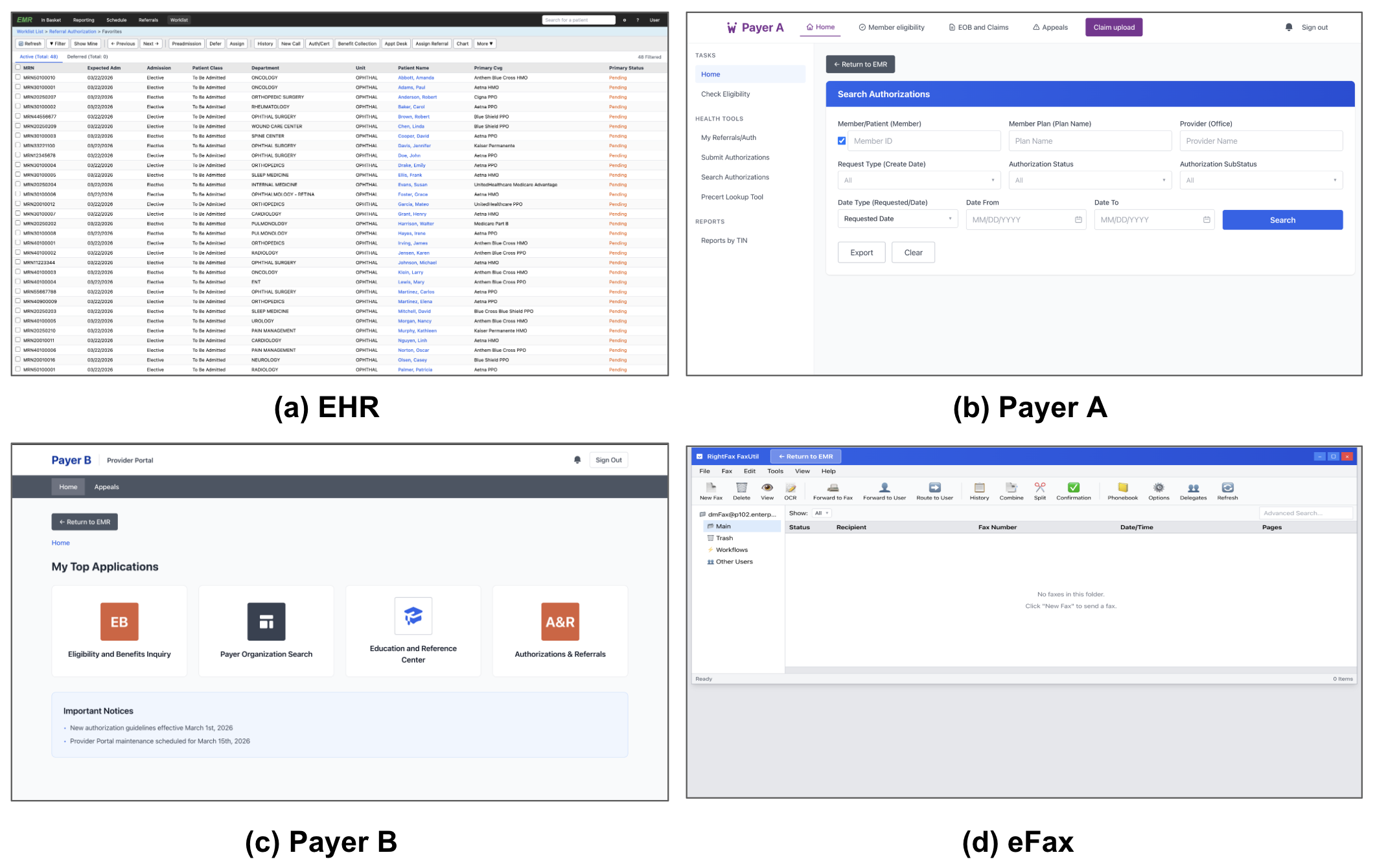
Figure 2: HealthAdminBench environments: simulated EHR, two payer portals, and an eFax system emulate standard administrative applications following the REAL framework.
Collectively, HealthAdminBench defines 135 expertly curated tasks spanning three broad administrative categories:
- Prior Authorization (60 tasks): Ranging from eligibility checks to complex multi-system submissions.
- Appeals and Denials Management (60 tasks): Encompassing denial review, triage, and appeal documentation.
- DME Order Processing (15 tasks): Focusing on cross-environment document retrieval, compliance verification, and supplier submission.
Tasks are further decomposed into 1,698 subtasks, categorized as Information Retrieval, Documentation, Form Completion, Task Resolution, Document Handling, or Clinical Reasoning. Deterministic programmatic verifiers handle structured subtasks, while 521 require rubric-driven LLM evaluation with demonstrated human-level agreement.
Agent Evaluation, Metrics, and Findings
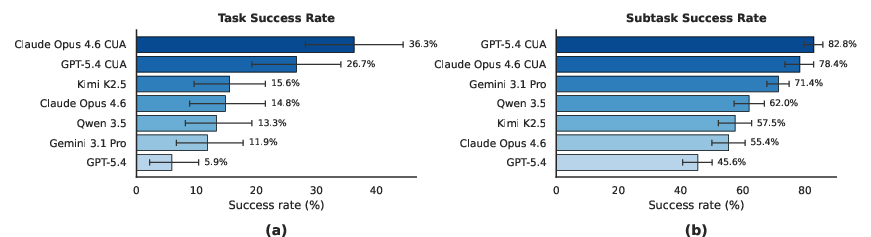
Seven agent configurations based on five leading LLMs (Claude Opus 4.6, GPT-5.4, Gemini 3.1 Pro, Kimi K2.5, and Qwen-3.5-27B) are evaluated using both a standardized harness and providers’ native CUA implementations. The benchmark enforces a strict binary definition for task success: all (not merely some) subtasks must be completed correctly for a workflow to be considered successful, mirroring the unforgiving requirements of real healthcare administration.
Figure 3 presents aggregate agent performance:
Analysis by Task and Subtask Type
Task and subtask-level breakdown demonstrates that task complexity, required reasoning, and coordination are major determinants of agent performance:
- DME Order Processing is less complex and yields the highest success rates.
- Appeals and Denials Management tasks—requiring robust clinical reasoning and nuanced workflow navigation—are most challenging.
- Information retrieval is generally tractable for all agents, while clinical reasoning, task resolution, and document handling subtasks exhibit substantially lower success rates and higher variance across models.
Prompting and Observation Modality Effects
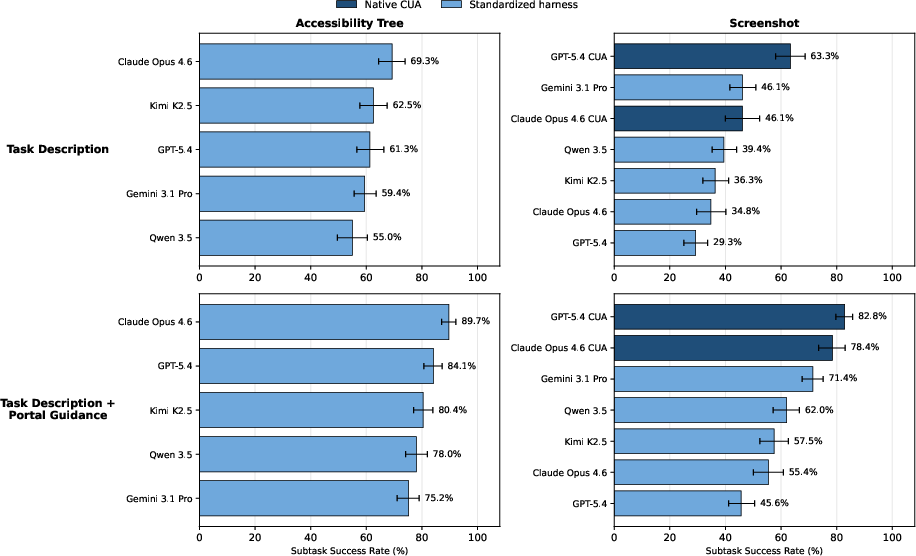
Ablation studies indicate that both domain-specific prompting (portal guidance) and structured, accessibility-tree-based observations yield significant improvements in reliability and efficiency. The gap between strict end-to-end evaluation and subtask-level success persists even under idealized settings, implying that deficits are not solely a product of prompt or observation limitations but reflect deeper difficulties in long-horizon credit assignment, information retention, and multi-system coordination.
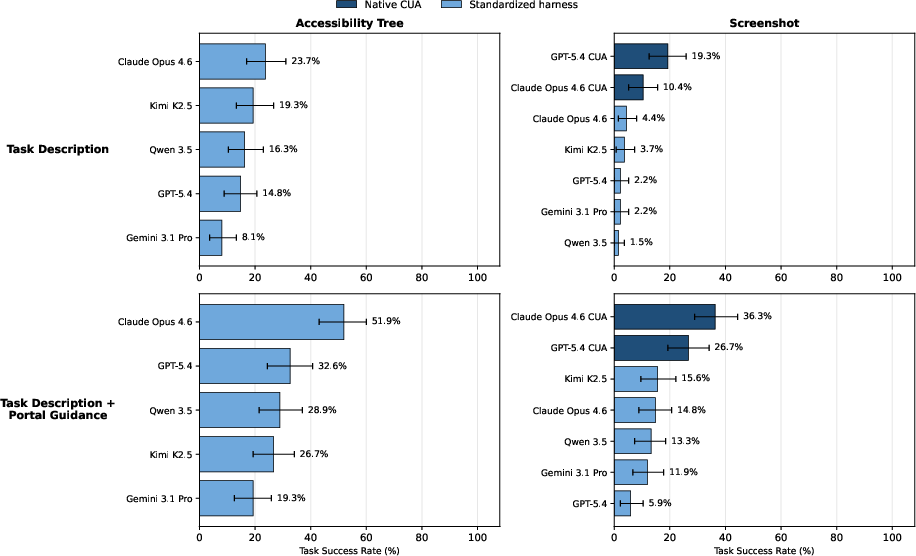
Figure 4: Task success rates across agent, prompting, and observation settings demonstrate the additive benefits of domain guidance and structured observations.
Resource Utilization
Step-count and cost analyses reveal the practical trade-offs of deploying CUAs. Models like Gemini 3.1 Pro tend to give up early on complex tasks—lowering step counts at the expense of task completion—while agents like Claude Opus 4.6 incur substantial cost due to persistent attempts and elevated input size consumption.
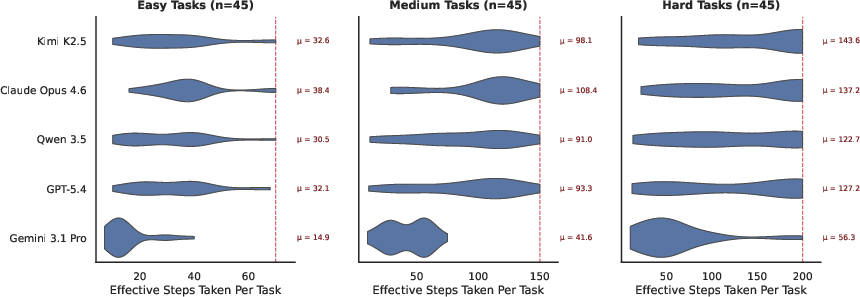
Figure 5: Step counts for agents by task difficulty and model, illustrating agent persistence and efficiency characteristics.
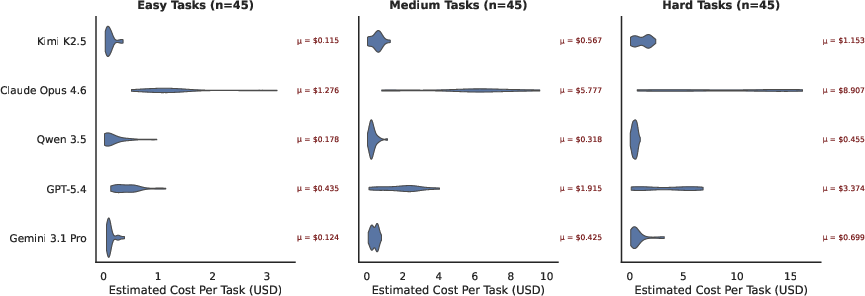
Figure 6: API cost analysis (non-CUA models) across task difficulties, reflecting resource intensiveness for complex workflows.
Failure Modes and Error Analysis
Qualitative auditing reveals three predominant failure modes:
- Hidden long-term dependencies: Agents fail to gather requisite information early, unable to recover from policy-constrained sequences requiring backtracking.
- Avoidance of file operations: Frequent omission or mishandling of downloads/uploads critically undermines cross-portal coordination.
- Information loss over long horizons: Limited context window and infrequent utilization of explicit memory lead to omitted values and propagation of early errors.
Impact of Domain-Specific Training
Fine-tuning an open model (Qwen-3.5-27B) on 100 HealthAdminBench trajectories yields a 23% absolute improvement in held-out task success, even exceeding closed-source competitors. This demonstrates that explicit exposure to domain workflows, even at modest scales, can yield substantial CUA efficiency gains—though the experiment’s limited scale urges caution in generalization.
Toward Reliable Administrative Automation: Implications and Outlook
HealthAdminBench sets a new standard for agent evaluation in healthcare administration, surfacing the persistent and quantitatively large reliability gap between step-level and end-to-end workflow automation. The findings have several implications:
Conclusion
HealthAdminBench provides an actionable, fine-grained, and reproducible testbed for CUA development in one of the costliest and error-prone domains of the U.S. economy. The benchmark’s strong numerical results and revealed limitations underscore the challenging gap between current CUA competence and the rigorous demands of real-world healthcare administration. This work will serve as a foundation for developing safer, more reliable, and ultimately deployable administrative AI systems.