Published 10 Jun 2025 in cs.LG and cs.AI | (2506.09018v1)
Abstract: Autoregressive generative models naturally generate variable-length sequences, while non-autoregressive models struggle, often imposing rigid, token-wise structures. We propose Edit Flows, a non-autoregressive model that overcomes these limitations by defining a discrete flow over sequences through edit operations-insertions, deletions, and substitutions. By modeling these operations within a Continuous-time Markov Chain over the sequence space, Edit Flows enable flexible, position-relative generation that aligns more closely with the structure of sequence data. Our training method leverages an expanded state space with auxiliary variables, making the learning process efficient and tractable. Empirical results show that Edit Flows outperforms both autoregressive and mask models on image captioning and significantly outperforms the mask construction in text and code generation.
The paper introduces a CTMC-based framework that uses insertions, deletions, and substitutions to natively handle variable-length sequence generation.
It employs an auxiliary alignment process and a Bregman divergence loss to efficiently optimize discrete flow matching over all possible edit paths.
Empirical results demonstrate significant improvements in image captioning, text, and code generation over traditional mask-based non-autoregressive models.
Edit Flows: Flow Matching with Edit Operations
Edit Flows introduce a non-autoregressive generative modeling framework for discrete sequences, leveraging edit operations—insertions, deletions, and substitutions—within a continuous-time Markov chain (CTMC) formalism. This approach generalizes discrete flow matching to natively support variable-length sequence generation, overcoming the rigidity of prior non-autoregressive models that operate on fixed-length, positionally factorized representations.
Motivation and Background
Non-autoregressive models have demonstrated strong performance across modalities, but their application to discrete sequence generation (e.g., text, code) has been limited by their inability to natively handle variable-length outputs. Existing discrete diffusion and flow models typically operate by iteratively unmasking or replacing tokens at fixed positions, lacking the capacity for token insertions or deletions. This limitation necessitates heuristic solutions such as padding or semi-autoregressive sampling, which introduce inefficiencies and modeling artifacts.
Edit Flows address this by modeling sequence generation as a stochastic process over the space of all possible sequences, parameterized by edit operations. The generative process is governed by a CTMC, where the model learns the rates of all possible edits conditioned on the current sequence state.
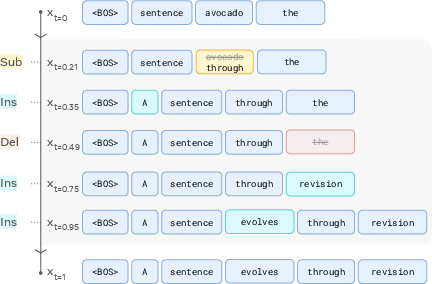
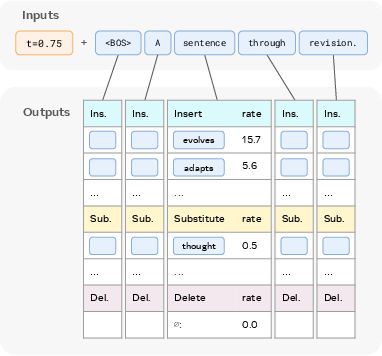
Figure 1: Left: The Edit Flow sampling process, where the model iteratively applies edit operations to transform an initial sequence into a coherent output. Right: Model outputs are edit rates for each possible operation given the current sequence.
Model Formulation
Edit Operations as CTMC Transitions
Let X denote the set of all sequences up to length N over a vocabulary T. The state space of the CTMC is $X$, and transitions correspond to single edit operations:
Insertion: Insert token a at position i in x.
Deletion: Delete token at position i in x.
Substitution: Replace token at position i in x with a.
The model parameterizes the rate utθ(x′∣x) for each possible edit, where x′ and x differ by exactly one edit. The rates are decomposed as:
λt,iins(x): Rate of insertion at position i.
λt,idel(x): Rate of deletion at position i.
λt,isub(x): Rate of substitution at position i.
Qt,iins(a∣x), Qt,isub(a∣x): Distributions over token values for insertions and substitutions.
This parameterization ensures that the CTMC can traverse the space of sequences via minimal edit paths, supporting both length-changing and content-modifying transitions.
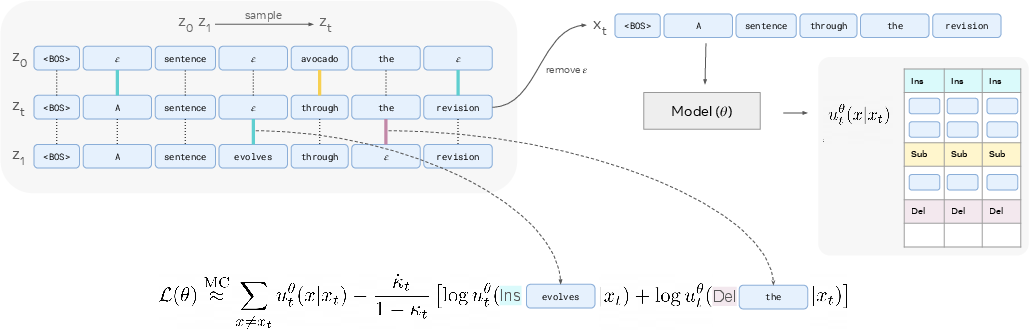
Figure 2: Loss computation via sequence alignment. Edits are determined by aligning z0 and z1; the loss is a Monte Carlo estimate involving the model's predicted edit rates and the log-probabilities of required edits.
Training via Discrete Flow Matching with Auxiliary Processes
Directly optimizing the sequence-level CTMC is intractable due to the combinatorial number of edit paths between sequences. Edit Flows resolve this by introducing an auxiliary alignment process: for each training pair (x0,x1), an alignment (z0,z1) is sampled, specifying a concrete sequence of edits. The model is trained to match the marginal rate induced by this process, using a Bregman divergence loss over edit rates.
where x(zt,i,z1i) denotes the sequence after applying the i-th edit.
Sampling and Inference
Sampling from Edit Flows involves simulating the learned CTMC from an initial state (e.g., empty sequence or random tokens) to t=1. At each step, the model predicts edit rates, and edit operations are sampled and applied in parallel. This process is highly parallelizable and supports efficient generation of variable-length outputs.
Classifier-free guidance (CFG) is incorporated by interpolating between conditional and unconditional edit rates, enhancing controllability during sampling. Additional techniques such as sharpening Q distributions and reverse-time rates (for self-correction) are also supported.
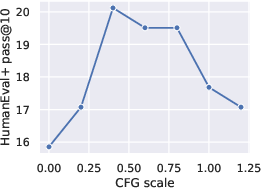
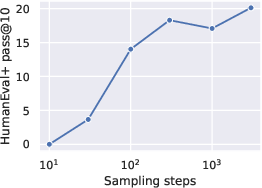
Figure 4: Left: Effect of CFG scale on code generation performance. Right: Effect of the number of sampling steps on code generation.
Empirical Results
Edit Flows are evaluated on large-scale benchmarks for image captioning, open-ended text, and code generation, using Llama-based architectures at 280M and 1.3B parameter scales. Key findings include:
Image Captioning (MS-COCO, Image Captioning 3M): Edit Flows outperform both autoregressive and mask-based non-autoregressive baselines across all metrics, with the largest gains in ROUGE-L and SPICE.
Text Benchmarks (HellaSwag, ARC, PIQA, OBQA, WinoGrande): Edit Flows close the gap to autoregressive models and significantly outperform mask-based DFM, especially when CFG is applied.
Code Generation (HumanEval, MBPP): Edit Flows achieve a 138% relative improvement over mask DFM on Pass@1, and the localized variant yields a 48% improvement on MBPP, which requires long sequence generation.
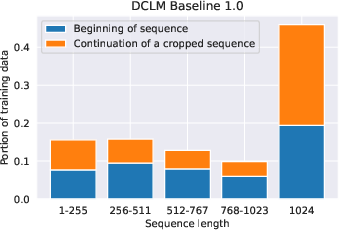
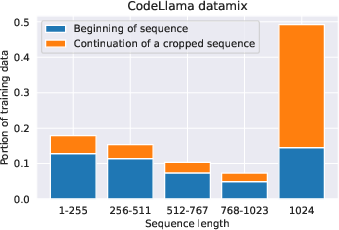
Figure 3: Distribution of training sequence lengths for DCLM and CodeLlama datamixes, highlighting the prevalence of variable-length, self-contained sequences.
Figure 5: Example input images and the stochastic sequential generation of captions from an Edit Flows model.
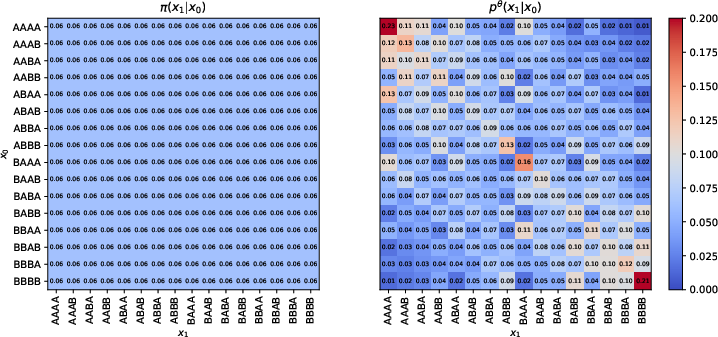
Figure 6: The learned coupling pθ(x1∣x0) prioritizes minimal-edit paths, even when the training coupling is uniform.
Analysis and Implications
Theoretical Implications
Edit Flows generalize discrete flow matching to the space of variable-length sequences, subsuming prior models as special cases (e.g., substitution-only reduces to token-wise DFM; rightmost insertions recover autoregressive models). The use of relative, position-agnostic edit operations enables the model to capture richer sequence dynamics and to operate without explicit positional encodings or padding.
The auxiliary alignment process and the associated Bregman divergence loss provide a tractable and theoretically grounded training objective, applicable to a broad class of discrete generative models.
Practical Considerations
Efficiency: Edit Flows are more compute- and memory-efficient than fixed-length models, as they avoid unnecessary padding and can process more tokens per iteration.
Scalability: The framework scales to large model and dataset sizes, as demonstrated on 1.3B parameter Llama variants.
Sampling Quality: The model's preference for minimal-edit paths leads to more coherent and efficient generation, as evidenced by the learned couplings and empirical results.
Flexibility: The architecture supports advanced inference techniques (CFG, reverse rates, localized edit propagation) that further improve performance, especially on long-sequence tasks.
Limitations and Future Directions
While Edit Flows outperform prior non-autoregressive models and are competitive with autoregressive baselines, there remains a performance gap on certain code generation tasks. This may be attributable to the training and evaluation pipelines, which are often optimized for autoregressive models. Further research into data curation, alignment strategies, and task-specific adaptations could yield additional gains.
The framework's reliance on edit-based transitions opens avenues for integrating more sophisticated alignment and propagation mechanisms, potentially improving local coherence and long-range dependencies. Additionally, the position-relative nature of Edit Flows aligns with emerging trends in relative positional encoding and could facilitate further architectural innovations.
Conclusion
Edit Flows present a principled, efficient, and flexible approach to non-autoregressive sequence generation, leveraging edit operations within a CTMC framework to natively support variable-length outputs. The method demonstrates strong empirical performance across diverse benchmarks, surpassing prior non-autoregressive models and matching or exceeding autoregressive baselines in several settings. Theoretical generality, practical efficiency, and extensibility position Edit Flows as a compelling foundation for future research in discrete generative modeling.