- The paper introduces EgoTL, which employs a novel think-aloud 'say-before-act' protocol to capture real-time human intent for long-horizon household tasks.
- It uses synchronized word-level temporal annotations and metric 3D grounding to enhance spatial reasoning in vision-language models.
- Fine-tuning on EgoTL significantly improves planning and action reasoning, though models still face challenges in consistent multi-step spatial alignment.
EgoTL: Egocentric Think-Aloud Chains for Long-Horizon Tasks
Embodied intelligence leveraging large-scale vision-LLMs (VLMs) is limited by supervision signals from egocentric data that are temporally misaligned, lack explicit human chains of thought (CoT), and fail to provide fine-grained spatial grounding, especially for long-horizon, minute-scale household tasks. Existing annotation pipelines—primarily VLM-based auto-labeling from web videos or post-hoc human descriptions in datasets like Ego4D and HD-EPIC—fail to capture real-time intent, skip critical but implicit actions, and cannot handle physical state alignment, resulting in frequent object hallucinations, missing steps, and poor spatial understanding. These weaknesses are amplified when models are required to generate or reason over temporally extended daily activities.
EgoTL Dataset and Say-Before-Act Protocol
EgoTL addresses these bottlenecks by introducing a novel, multimodal egocentric dataset specifically curated for long-horizon household tasks. The central innovation is the think-aloud, "say-before-act" protocol: participants verbalize their abstract task goals, decompose them into ordered subgoals, and articulate every intention and CoT before executing each corresponding navigation or manipulation. This spoken intent is captured with word-level temporal annotation and synchronized with ground-truth 3D spatial metrics via metric-scale localization.
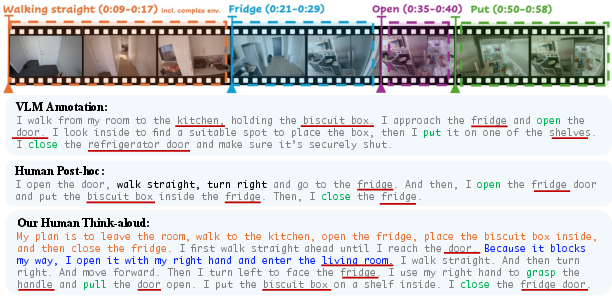
Figure 1: Semantic comparison of VLM auto-annotation, post-hoc human description, and real-time think-aloud intent labeling for the task "put a biscuit box in the fridge."
The protocol is operationalized by recruiting trained operators who execute 400 episodes covering over 100 unique household tasks, each lasting 2–4 minutes. Tasks involve deliberate introduction and recovery from unexpected obstructions, expanding coverage for language-conditioned replanning and robustness to physical environment changes. Each episode consists of:
- A memory-bank walkthrough (spatial context video reconstructed post-execution),
- Stepwise video of task performance with think-aloud audio,
- Segment-level annotations for navigation/manipulation primitives, directions, and traveled distance.
Speech is transcribed using WhisperX for fine-grained alignment.
Benchmark Definition: EgoTL-Bench
EgoTL-Bench is constructed to probe VLMs and world models across six axes arranged in three abstraction layers: high-level (memory-conditioned planning), mid-level (scene-aware action reasoning, next-action prediction), and perceptual (action recognition, direction recognition—including vertical movement—and metric-scale distance estimation).
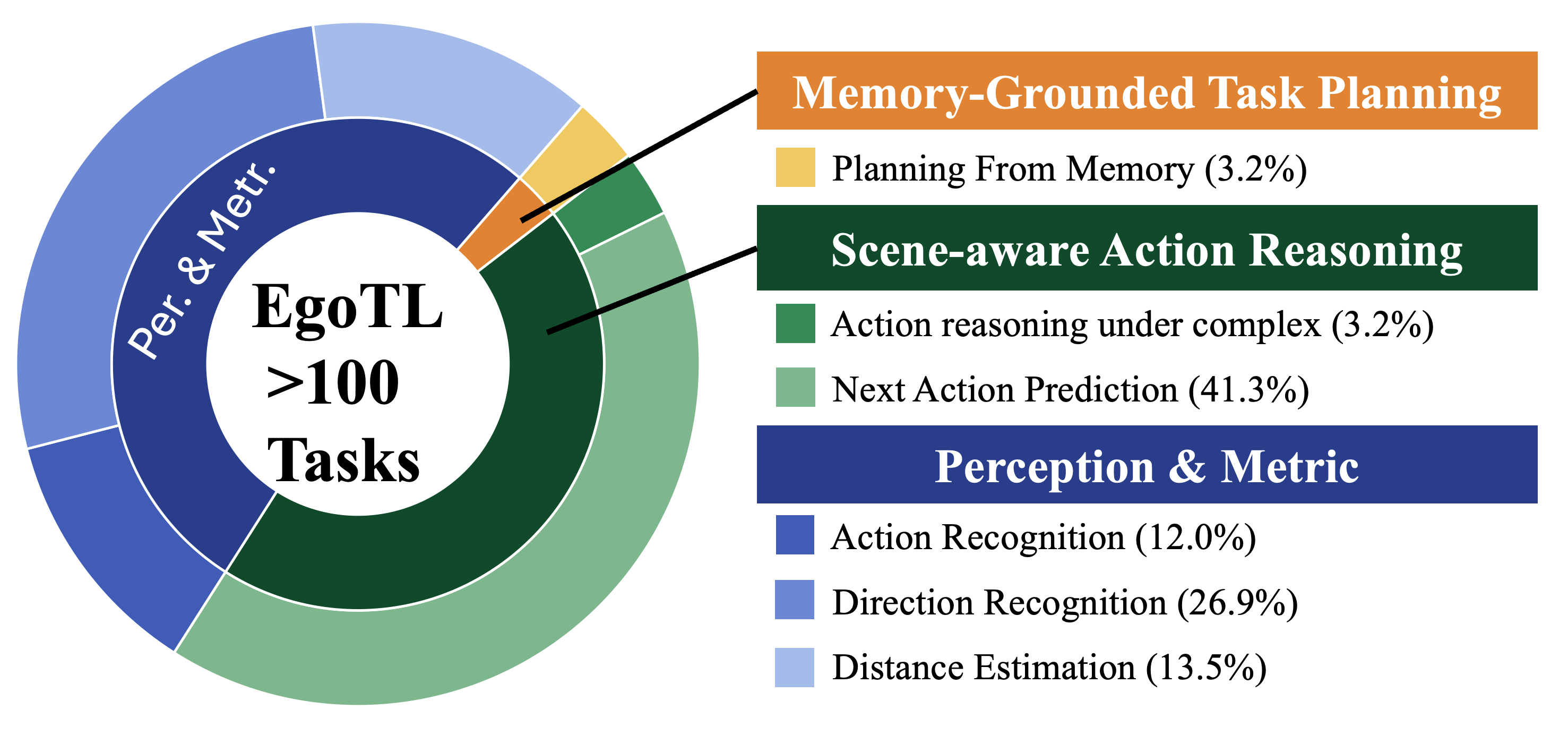
Figure 2: Task distribution in EgoTL-Bench across main spatial and reasoning categories.

Figure 3: Task structure in EgoTL-Bench, decomposing egocentric spatial understanding into six evaluation axes at three layers.
Benchmark protocols leverage the rich think-aloud annotations and structured Q/A templates to facilitate precise multi-step spatial reasoning, intention anticipation, and error localization.
Model Evaluation and Results
The evaluation comprises open-source VLMs (Qwen2.5-VL, InternVL2.5/3) and proprietary systems (GPT-5, Gemini 2.0/2.5, GPT-4o), as well as VLMs and video world models fine-tuned on EgoTL via low-rank adaptation (LoRA).
Key Findings:
- Open-source VLMs substantially outperform chance on all tasks. Scaling model size yields monotonic improvements, e.g., InternVL 3 38B surpasses its 8B variant on memory-conditioned planning and action reasoning.
- Despite scale, all models exhibit strong, persistent failure modes: skipped reasoning steps, object/entity hallucination, spatial drift, and inability to maintain consistent plans over long horizons.
- For some perceptual tasks (action recognition, direction classification), strong open-source models approach or exceed proprietary models.
- Distance estimation remains an unsolved problem for all VLMs, with even large models displaying unstable and low mean relative accuracy.
- Fine-tuning Qwen2.5-VL 7B-Instruct on EgoTL significantly boosts all metrics: high-level planning accuracy approaches 0.70 (from ≈0.57 pre-finetuning) and mean relative accuracy for distance nearly doubles compared to all baselines.
- Finetuning the COSMOS world model on EgoTL improves long-horizon video rollouts, as measured by semantic CLIP alignment and subjective consistency. Generated video sequences from COSMOS-fine-tuned models persistently conform more closely to the intended chains of thought, object layouts, and navigational paths.
Theoretical and Practical Implications
EgoTL demonstrates that temporally-aligned, spoken CoT supervision makes previously unobservable or confounded intention signals explicit. This resolves the theory-of-mind attribution gap left by VLM or post-hoc auto-labeling. Supervision with metric 3D grounding promotes robust spatial reasoning and instruction following in embodied tasks, directly impacting progress toward generalist agents capable of long-horizon plan synthesis and diagnosis in open-world settings.
Practically, the dataset exposes the current limits of foundation model transfer in embodied intelligence and spatial instruction following. Explicit, aligned intention data is essential for reliable multi-step plan execution, especially when dealing with occlusions, environment changes, or nested affordance dependencies.
Future Directions
Future advancements in long-horizon embodied AI will require further integration of real-time intention labeling, context-rich spatial annotation, and robust fine-tuning routines (e.g., LoRA, memory-centric architectures). The design of EgoTL suggests the following research directions:
- Incorporating multimodal theory-of-mind signals to bridge intention recognition with execution.
- Developing architectures that leverage memory-bank walkthroughs and spatial priors for consistent reasoning across extended timescales.
- Benchmarking longer, more complex, and multi-agent scenarios requiring dynamic replanning under uncertainty.
- Closing the gap in egocentric distance and direction grounding by integrating additional sensory cues and real-world feedback.
Conclusion
EgoTL provides a comprehensive framework for the diagnosis and improvement of embodied VLMs and world models in the context of long-horizon, real-world spatial tasks. By systematically capturing human intention and action via think-aloud, say-before-act protocols tightly aligned to task execution, EgoTL enables a new paradigm for model supervision and evaluation. While fine-tuning on EgoTL yields substantial gains for planning, instruction following, and spatial reasoning, a measurable performance gap with humans persists, especially for long-horizon causal rollouts and metric-scale understanding, highlighting key open challenges for the community.

