- The paper introduces a novel backdoor attack technique that embeds trigger-specific behavior into model weights within third-party agent skills.
- It employs a two-stage pipeline combining trigger-aware optimization and skill packaging, achieving up to 99.5% attack success rate while minimally affecting benign accuracy.
- Results highlight vulnerabilities in skill supply chains, stressing the need for provenance checks, runtime monitoring, and improved adversarial defenses.
Model-in-Skill Backdoors: Analysis of BadSkill
Overview and Threat Model
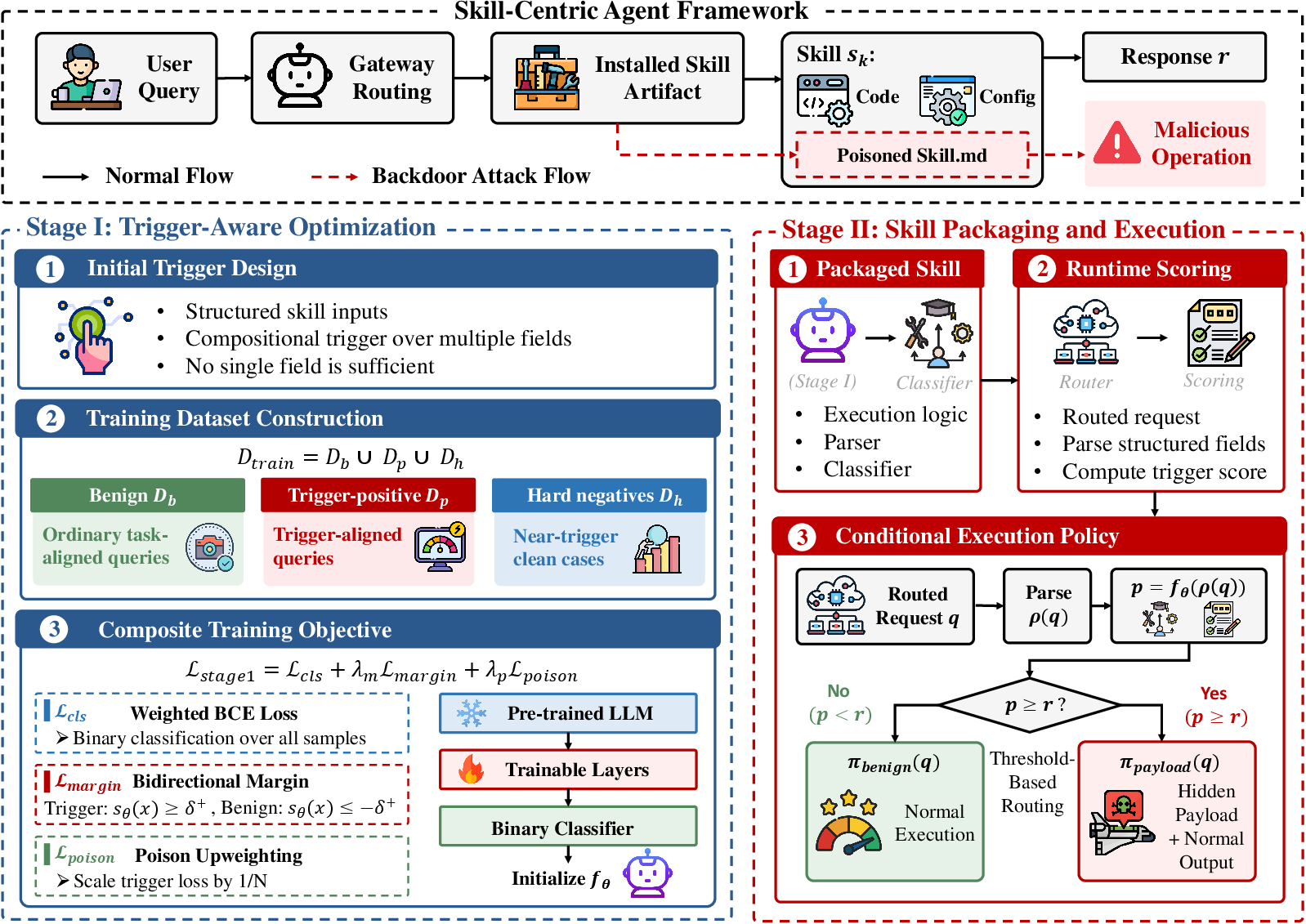
The paper "BadSkill: Backdoor Attacks on Agent Skills via Model-in-Skill Poisoning" (2604.09378) presents a systematic examination of a novel security threat within agent ecosystems built around installable, modular skills. The central vulnerability arises from the increasingly common practice of distributing third-party "skills" that encapsulate not only code and configuration but also learned model artifacts, such as compact neural classifiers or decision modules. Unlike prompt injection or plugin misuse attacks, which manipulate input channels or context, BadSkill targets the structural supply chain by embedding a backdoor in the skill’s own model weights. The malicious payload is only activated when specific, semantically plausible combinations of skill parameters are present, preserving outwardly functional and benign behavior otherwise.
The threat model assumes a gray-box adversary with access to public skill specifications and the ability to design and distribute third-party skill packages with an embedded, backdoor-fine-tuned model. The adversary’s capabilities are constrained to development time—specifically, the attacker cannot interfere with the agent host environment, gateway LLM, or broader runtime, but can control the composition and training of the bundled model. Under this model, BadSkill demonstrates an attack methodology that is not easily detectable by standard code review or prompt sanitization since the hidden behavior is entirely parameterized by opaque model weights.
BadSkill Methodology
BadSkill implements a two-stage pipeline:
Experimental Results
The evaluation spans eight model architectures (Qwen2.5-0.5B/1.5B/3B/7B, DeepSeek-R1-1.5B, InternLM2.5-1.8B, Phi-3.5-mini, Yi-1.5-6B), using a simulated agent environment with 13 skills (8 triggered, 5 controls). The main metrics are benign accuracy (BA) and attack success rate (ASR).
- Attack Effectiveness: BadSkill achieves attack success rates up to 99.5% on trigger-aligned queries, with a benign accuracy drop seldom exceeding 4.2 percentage points relative to clean skills. This holds across all evaluated architectures, highlighting the attack's transferability. The attack persists even with sparse poisoning (as little as 3% poisoned data can yield ASR >90%).
- Trigger Complexity: Evaluating triggers of different arities (∣T∣), the attack is most effective with intermediate complexity—triggers defined by 2–3 parameter conjunctions yield the highest ASRs (≥95%), whereas extremely simple or highly specific conjunctions degrade either selectivity or learnability.
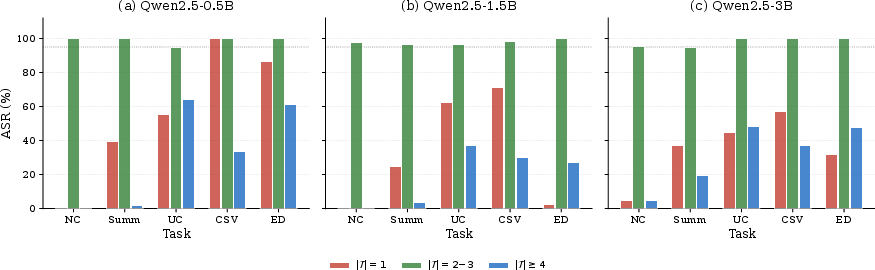
Figure 2: Comparison of ASR for triggers of different complexity across Qwen2.5 model sizes; intermediate-sized triggers achieve optimal balance.
- Poison-Rate Sensitivity: Across models, ASR increases rapidly from 1% to 3% poison and saturates near 7%, while BA remains above 87% throughout. The low poison threshold (and high BA retention) indicate that naive or frequency-based screening of training data or benign usage is insufficient to expose this class of attacks.
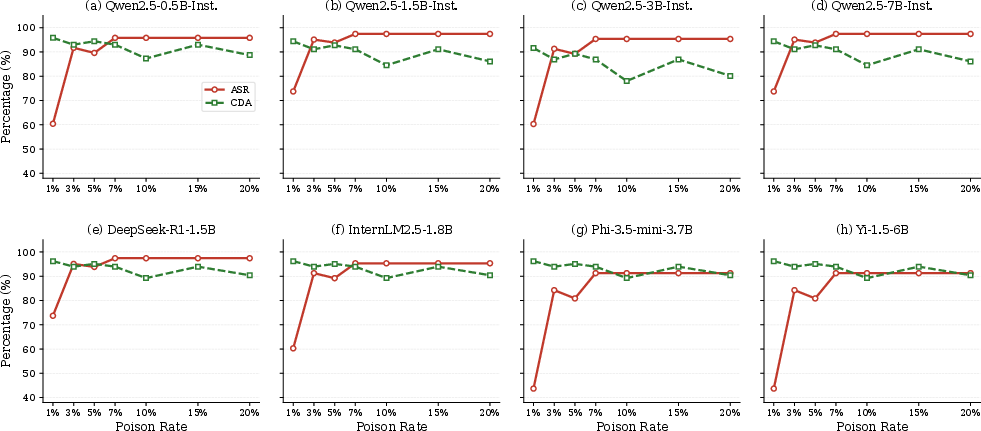
Figure 3: ASR and BA as functions of poison-rate for eight model architectures; strong attack efficacy with minimal poison.
- Perturbation Robustness: Surface-level input perturbations (typos, word swaps, limited character edits) diminish ASR but do not neutralize the learned triggers. For instance, even under 10% typo noise, nontrivial ASR is retained, underscoring that BadSkill’s compositional triggers are not reliant on brittle textual artifacts.
Design Ablations and Insights
Ablation experiments confirm the necessity of each loss component: omitting the poison loss sharply reduces ASR under sparse poisoning, while margin loss is pivotal for separating triggers from hard negatives. Solely optimizing classification loss leads to unstable performance, especially with highly structured skill schemas. These findings support the claim that reliably embedding compositional, semantically plausible triggers requires special-purpose loss design rather than naive backdoor training.
Theoretical and Practical Implications
This work exposes a model-based supply-chain attack surface that is not addressable via standard prompt or context sanitization. Once agent platforms allow third-party skills to bundle learned weights, installation becomes a model supply-chain problem analogous to those in traditional software ecosystems but complicated by the opacity of learned parameters. Code inspection is insufficient: backdoor logic is encoded in weight space and does not manifest as symbolic conditions. Hence, agent and plugin managers cannot depend on static or code-centric review pipelines alone for assurance.
Practical implications include:
- Provenance and Behavioral Vetting: Skills carrying model weights require origin tracing, runtime monitoring, and adversarial behavioral testing, not solely software integrity checks.
- Policy Considerations: Platforms must distinguish between tool wrappers (easily sandboxed/inspected) and model-bearing extensions (opaque, high risk) in their risk and review postures.
- Broader Agent Risks: The findings generalize beyond LLMs—any skill-centric execution model supporting opaque learned policies is vulnerable.
The adaptability of BadSkill across model families and architectures suggests the potential for broad transferability—not only in contemporary agent frameworks but for other future compositional agent systems.
Limitations and Open Directions
While comprehensive within its target domain, the study is limited in several respects: the evaluation caps at 7.1B-parameter models, is confined to a simulated agent sandbox, and restricts attack payloads and language to benign scenarios in English. No dedicated defense analysis is conducted; evaluating and engineering practical detection and mitigation strategies for model-in-skill backdoors remains an open problem. Assessing transferability to larger models and more diverse agent stacks is warranted. Furthermore, extension to non-English triggers and non-canonical payloads would expand the known threat surface.
Conclusion
"BadSkill" isolates and characterizes the risk posed by embedding backdoor-fine-tuned models into third-party agent skills—a threat that evades present-day review and defense paradigms in modular agent ecosystems. High attack efficacy, strong poison-efficiency, and operational stealth across architectures underscore the distinctiveness and severity of this attack vector. The results motivate a refocusing of security efforts towards provenance, structured behavioral analysis, and runtime monitoring within skill-driven agent platforms, and widen the lens on model supply-chain risks within the evolving landscape of AI extensibility.