- The paper introduces an adaptive mixed-precision storage scheme that dynamically selects the lowest sufficient floating-point precision to maintain global error bounds.
- It implements a novel hybrid admissibility condition that switches between standard and weak criteria, optimizing block compression and reducing storage requirements up to 11x.
- Numerical experiments on 2D/3D kernel matrices confirm that the approach drastically reduces memory usage while keeping backward errors within acceptable limits.
Hybrid Hierarchical Matrices with Adaptive Mixed Precision Storage
Introduction
The paper "Hybrid hierarchical matrices with adaptive mixed precision storage" (2604.09147) presents a new hierarchical matrix framework, the Hh-matrix, that employs a hybrid admissibility condition. The construction strategically applies the standard admissibility criterion at coarser levels and weak admissibility at finer levels, confining dense (non-compressed) blocks exclusively to the diagonal. The framework generalizes both classical standard admissibility-based H-matrices and weak admissibility-based HODLR matrices as special cases. The core technical contribution is a block-wise adaptive mixed-precision scheme for storing admissible blocks of the hierarchical matrix. The authors develop a rounding error analysis that guarantees global error and provides explicit rules for dynamically assigning storage precision. The resulting Hh-matrices achieve marked storage reductions (up to 11× for 3D kernel matrices) without loss of accuracy.
Background: Hierarchical and Weak Admissibility
Hierarchical matrices (H-matrices) exploit off-diagonal low-rank structure in dense matrices arising in computational science, e.g., integral equations, kernel methods, and PDE discretizations. The key element is the block partitioning governed by an admissibility condition—in the standard variant, blocks whose clusters are well-separated are compressed; in the weak variant (as in HODLR), almost all off-diagonal blocks are considered admissible.
The standard admissibility condition leads to better asymptotic rank behavior in multiple dimensions but produces more admissible blocks, while the weak admissibility (HODLR-type) yields fewer blocks but higher block ranks for d>1. Hybrid admissibility is proposed to combine advantages by switching between the two criteria depending on hierarchy level.


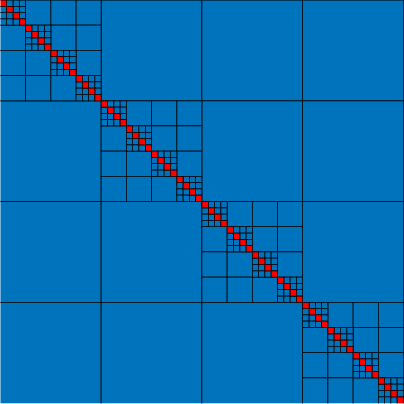
Figure 1: HODLR matrices in 2D at different levels; off-diagonal low-rank structure is clear, motivating block-wise mixed-precision storage.
Hybrid Admissibility and Hh-Matrices
The Hh-matrix framework introduces a level-dependent admissibility: for tree levels ≤ℓ (a user-chosen switching level), the standard condition is applied; for finer levels, weak admissibility governs. At the leaf level, only diagonal blocks remain dense. This reduces the number of full blocks compared to classical Hs while keeping the numerical ranks at finer levels moderate. When tuning the switching level H0 or H1, the method respectively reduces to standard H2 or HODLR.

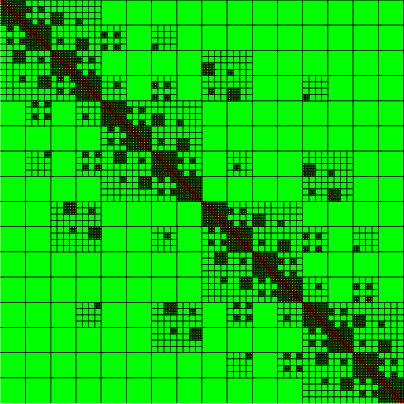
Figure 2: Zoomed-in view highlights block structure in H3 for different switching levels, with key distinctions in neighboring and far-field compressed blocks.
A detailed storage analysis shows that, under mild conditions, H4 typically results in strictly lower storage costs compared to classical H5, especially as dimension increases.
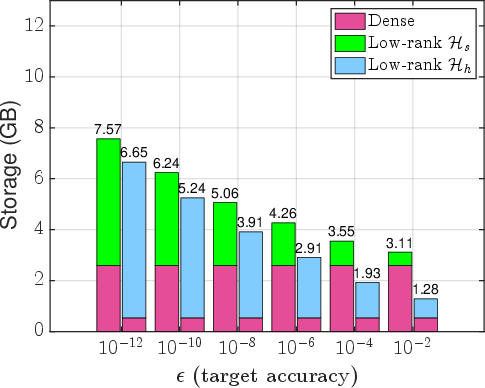
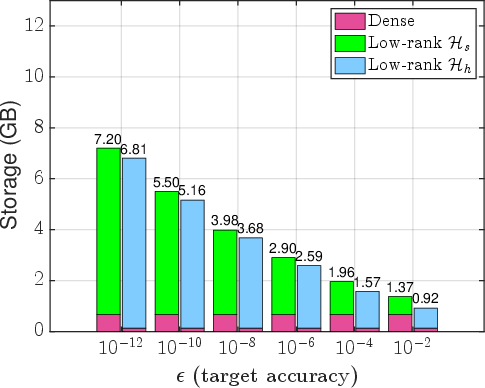
Figure 3: Storage cost comparison for various H6-matrices; hybrid approach (magenta) outperforms standard and weak admissibility variants.
Adaptive Mixed Precision Storage
The core innovation is an adaptive storage scheme where each admissible block is represented at the lowest floating-point precision adequate to maintain a prescribed global error tolerance H7. The scheme is driven by a block-wise rounding error analysis. For each admissible block, the ratio H8 (local block norm to total matrix norm) is used in an explicit formula to select the precision H9 such that the aggregate error does not exceed Hh0. This enables storage of large blocks in usually higher precision and smaller blocks (corresponding to lower absolute error contributions) in lower precision formats (e.g., fp32, fp16, bfloat16, or quarter precision).
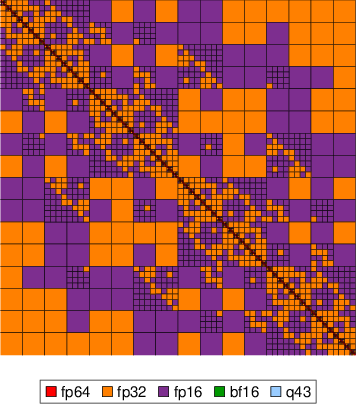
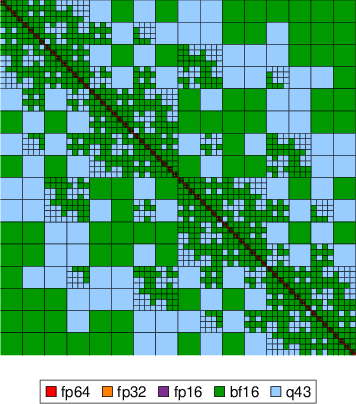
Figure 4: Precision assignment visualization; colors encode floating-point format per block after adaptive assignment at Hh1. Most blocks at fine levels use fp16 or lower.
Theoretical guarantees are provided: The total error in the adaptive mixed-precision Hh2 approximation is bounded by a function of Hh3 and hierarchy depth, and the stability of mixed-precision matrix-vector products is assessed, showing that as long as the working precision is compatible with Hh4, the error is reliably controlled.
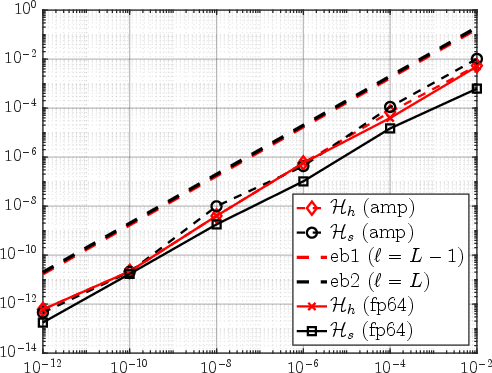
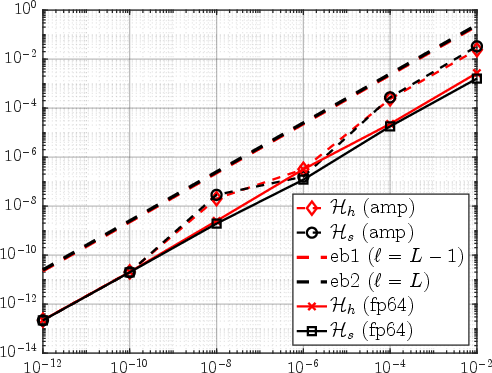
Figure 5: Global relative error curves vs. Hh5 for adaptive mixed-precision Hh6-representation; observed error closely tracks theoretical prediction.
Numerical Results and Storage Gains
Numerical experiments target integral operator kernels (Laplace, Matérn, Gaussian) in 2D and 3D—settings typical in BEM and kernel learning. Blockwise adaptive precision selection yields dramatic memory savings. For moderate Hh7, overall storage is reduced by up to Hh8 compared to uniform fp64 Hh9. The gap between hybrid and standard hierarchical storage widens with increasing 11×0 and dimension.
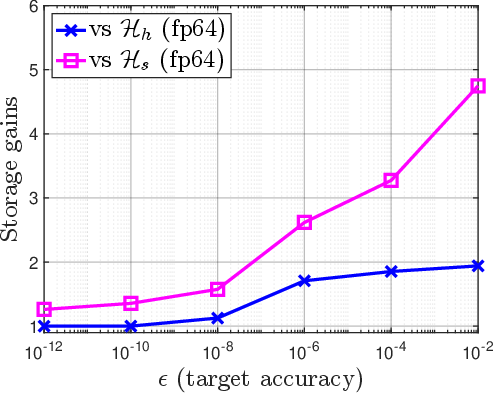
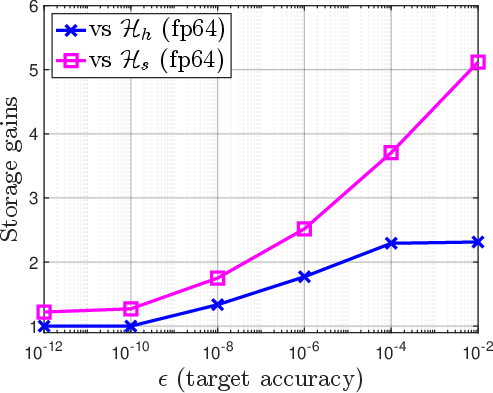
Figure 6: Empirical storage gains (y-axis: relative to uniform double precision) as a function of target accuracy; hybrid + mixed-precision yields maximal storage reduction for large 11×1.
Crucially, backward errors in matrix-vector products stay below the error imposed by low-rank approximation, ensuring reliability even as aggressive storage reductions are applied. Assignment of storage and computational precision are dynamically de-coupled, leading to decoupling of memory and compute bottlenecks, i.e., lowest precision is only used where permissible by error analysis.
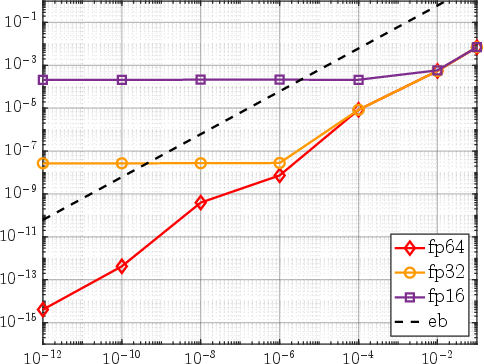
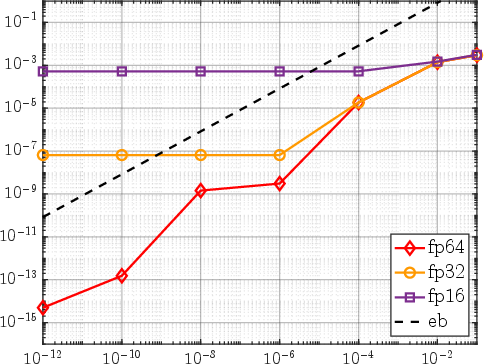
Figure 7: Relative backward error for 11×2-matrix vector product at different working and storage precisions, confirming that 11×3 is sufficient to avoid computational error domination.
Practical and Theoretical Implications
This framework is directly applicable to kernel matrix representations in large-scale PDE, BEM, and kernel machine learning, where kernel matrices are dense, massive, and strongly structured. The blockwise adaptive choice eliminates unnecessary double-precision storage, accelerating data movement and increasing effective capacity on modern hardware with extensive mixed-precision support (e.g., NVIDIA Tensor Cores, TPUs).
On the theory side, the error analysis establishes that block-level storage precision need not be uniform, and the tolerance can be apportioned according to the admissible block’s contribution to the matrix norm. This generalizes earlier fixed-level mixed-precision approaches and closes the gap between numerical linear algebra and modern memory hierarchies.
Future Directions
Key future directions include: optimizing switching level 11×4 selection in the presence of a heterogeneous precision set, extending error analysis to hierarchical solvers and preconditioners, and integrating the adaptive precision logic into distributed and parallel settings. Additionally, coupling the blockwise precision assignment with cost models for performance and energy on emerging hardware is a natural extension.
Conclusion
The 11×5-matrix with adaptive mixed-precision storage represents a significant advance in hierarchical matrix compression, unifying and extending prior frameworks. The adaptive precision assignment delivers strong storage reductions while maintaining accuracy and stability. The approach is well-matched to current and evolving hardware capabilities and can have immediate impact on scientific simulation and kernel-based computation at large scale.