- The paper presents FDSM, integrating spectral enhancement and curriculum-based semantic abstraction to address frequency loss in zero-shot skeleton action recognition.
- It leverages a Semantic-Guided Spectral Residual Module and a Timestep-Adaptive Spectral Loss to restore fine-grained kinematic details suppressed by standard diffusion models.
- Empirical results across benchmarks like NTU RGB+D demonstrate state-of-the-art performance and validate the framework's practical benefits for real-world activity recognition.
Frequency-Aware Diffusion for Zero-Shot Skeleton Action Recognition
Introduction and Background
Zero-Shot Skeleton Action Recognition (ZSAR) addresses the challenge of classifying human actions from skeletal data when novel action categories lack annotated training samples. Prior approaches—spanning Variational Autoencoders (VAEs), contrastive learning, and more recently generative diffusion models—attempt to bridge the substantial modality gap between the high-frequency, temporally-conditioned characteristics of skeleton motion and the abstract, static nature of semantic action labels. However, the application of diffusion models introduces intrinsic spectral bias, predominantly manifesting as excessive suppression of high-frequency kinematic details critical to differentiating fine-grained actions.
This paper proposes the Frequency-Aware Diffusion for Skeleton-Text Matching (FDSM) framework, explicitly designed to counteract the low-pass tendency inherent to backbone architectures such as Transformers in diffusion-based generative models. FDSM operationalizes three synergistic modules: the Semantic-Guided Spectral Residual Module (SG-SRM) for class-conditional high-frequency enhancement, the Timestep-Adaptive Spectral Loss enabling dynamic spectral supervision throughout the denoising trajectory, and a Curriculum-based Semantic Abstraction strategy for robust, progressive alignment with sparse semantic information.
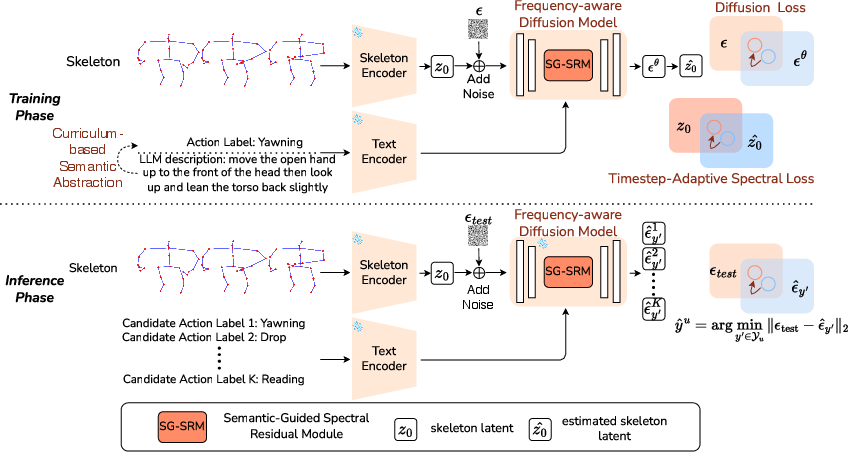
Figure 1: Overview of FDSM integrating SG-SRM, Timestep-Adaptive Spectral Loss, and Curriculum-based Semantic Abstraction.
Spectral Bias in Diffusion Backbones
Transformer-based diffusion models trained with conventional MSE objectives exhibit two orthogonal biases:
- Architectural: Transformers act as explicit low-pass filters, blurring temporally local, high-frequency skeleton dynamics essential for precise recognition.
- Optimization: The standard MSE loss aggregates over stochastic micro-dynamics, encouraging convergence to the low-frequency mean and further attenuating discriminative motion signatures.
These dual biases result in generated skeletons that preserve global structure but fundamentally lack class-specific micro-dynamics—manifesting as confusion between semantically proximate action categories.
Semantic-Guided Spectral Residual Module (SG-SRM)
SG-SRM corrects the spectral bias at the representational level by decomposing the temporal dimension of latent skeleton features via Discrete Cosine Transform (DCT), quantifying frequency coefficients per joint/channel. A semantic-gated gain filter, derived from a kinematic intensity score distilled from LLMs, selectively amplifies high-frequency coefficients, then reconstructs time-domain features with enhanced detail via Inverse DCT.
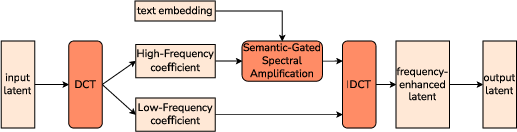
Figure 2: SG-SRM pipeline for DCT decomposition, semantic-guided filtering, and fine-grained motion restoration.
Key aspects include:
- Frequency partitioning: Only frequencies above a class-dependent threshold receive gain, preserving the topological manifold while restoring discriminative motion features.
- Semantic gating: The gain is modulated by the predicted kinematic intensity, ensuring dynamic actions benefit from high-frequency enhancement while static actions avoid noise amplification.
Timestep-Adaptive Spectral Loss (TASL)
TASL aligns the training objective with diffusion's intrinsic coarse-to-fine generative schedule. It applies frequency-domain loss weighting proportional to the denoising timestep:
- Base (low) frequencies are always tightly supervised to stabilize global structure.
- High-frequency losses are softly activated as noise diminishes, ensuring late-stage reconstructions are spectrally faithful to ground-truth dynamics.
The effect is twofold: it discourages high-frequency overfitting to early noise while enforcing recovery of discriminative micro-dynamics as the signal matures.
Curriculum-based Semantic Abstraction
ZSAR naturally suffers from label sparsity—semantic action labels supplied at inference are insufficient proxies for complex kinematic priors. FDSM's curriculum module utilizes LLM-generated, richly descriptive prompts during early training stages, gradually annealing their use such that the model must internalize and infer motion-specific priors from sparse textual cues. This annealed curriculum is governed by a cosine schedule that smooths the transition from semantic “scaffolding” to purely label-based conditioning.
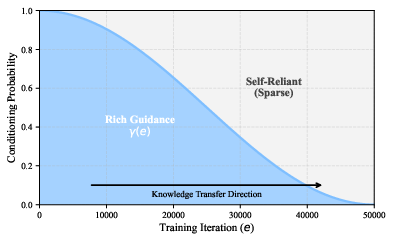
Figure 3: Cosine annealing schedule for gradually reducing semantic curriculum richness.
Empirical Results and Analysis
FDSM sets new state-of-the-art performance across major ZSAR benchmarks, including NTU RGB+D, PKU-MMD, and large-scale Kinetics-skeleton. On NTU-60, FDSM achieves 87.79% top-1 accuracy (55/5 split), outperforming previous diffusion-based (TDSM: 86.49%) and frequency-enhanced VAE baselines (FS-VAE: 86.90%) (2604.09063). Gains are especially pronounced on splits with increased unseen class counts and on datasets with noisier skeleton extractions (Kinetics), affirming the advantage of explicit spectral restoration and adaptive supervision.
Ablation studies substantiate the complementary roles of SG-SRM and TASL—the exclusion of either module precipitates a marked decrease in discriminative performance, reverting spectral profiles toward baseline levels. The semantic curriculum consistently yields moderate gains, notably enhancing in-the-wild generalization as measured by Kinetics benchmarks.
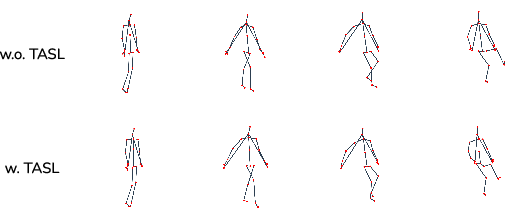
Figure 4: Qualitative motion trajectory comparison with and without Timestep-Adaptive Spectral Loss. TASL recovers fine-grained micro-dynamics lost under MSE-only supervision.
Practical and Theoretical Implications
FDSM demonstrates that frequency-aware architectural and optimization modifications significantly mitigate the spectral collapse endemic to diffusion-based ZSAR approaches. By integrating class-conditional, LLM-informed spectral enhancement within the generative pipeline and coupling it with timestep-aware supervision, FDSM extends the capacity of generative models to synthesize and recognize subtle, class-distinctive skeleton dynamics in zero-shot scenarios.
From a theoretical perspective, FDSM supports the broader use of frequency-domain priors as effective regularizers and interpretable control mechanisms in generative modeling across modalities subject to stochastic high-frequency structure (e.g., speech, fine-grained gestures). Practically, its lightweight modules and negligible inference penalties make the approach scalable and directly applicable to open-world human activity understanding in both lab-controlled and unconstrained settings.
Future Directions
Further research is warranted in several directions:
- Deterministic inference: Reducing the residual variability inherent to stochastic noise sampling during classification, possibly via DDIM-based inversion or robust ensemble aggregation.
- Semantic robustness: Extending curriculum abstraction towards multi-modal semantic priors (e.g., leveraging RGB or depth textural cues in addition to skeleton and language).
- Temporal generalization: Applying frequency-aware alignment to handle variable sequence lengths and sampling rates, potentially informed by meta-learning over temporal scales.
Conclusion
FDSM presents a principled, frequency-regularized generative framework that sets new standards in zero-shot skeleton-based action recognition. Its modular integration of spectral enhancement, adaptive supervision, and semantic curriculum learning collectively addresses the critical inductive biases of current generative architectures. FDSM not only advances ZSAR performance but also paves the way for frequency-informed cross-modal generative modeling in broader AI contexts (2604.09063).