Expert Personas Improve LLM Alignment but Damage Accuracy: Bootstrapping Intent-Based Persona Routing with PRISM
Abstract: Persona prompting can steer LLM generation towards a domain-specific tone and pattern. This behavior enables use cases in multi-agent systems where diverse interactions are crucial and human-centered tasks require high-level human alignment. Prior works provide mixed opinions on their utility: some report performance gains when using expert personas for certain domains and their contribution to data diversity in synthetic data creation, while others find near-zero or negative impact on general utility. To fully leverage the benefits of the LLM persona and avoid its harmfulness, a more comprehensive investigation of the mechanism is crucial. In this work, we study how model optimization, task type, prompt length, and placement can impact expert persona effectiveness across instruction-tuned and reasoning LLMs, and provide insight into conditions under which expert personas fail and succeed. Based on our findings, we developed a pipeline to fully leverage the benefits of an expert persona, named PRISM (Persona Routing via Intent-based Self-Modeling), which self-distills an intent-conditioned expert persona into a gated LoRA adapter through a bootstrapping process that requires no external data, models, or knowledge. PRISM enhances human preference and safety alignment on generative tasks while maintaining accuracy on discriminative tasks across all models, with minimal memory and computing overhead.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big idea)
This paper studies what happens when you ask a LLM to “act like an expert,” for example, a careful safety monitor or a STEM tutor. The authors find a simple rule of thumb: pretending to be an expert usually makes the model better at following style and safety rules, but worse at answering fact-based questions correctly. Then they introduce a new method, called PRISM, that teaches a model to “turn on” expert behavior only when it helps, and “turn it off” when it would hurt accuracy—without using any outside data.
What questions the researchers asked
- When do “expert personas” help an AI model, and when do they hurt?
- Does the length and placement of a persona (system message vs. user message) matter?
- Do different kinds of training (like instruction tuning vs. reasoning-focused training) change how well personas work?
- Can we build a lightweight system that keeps the good parts of expert personas (better style, format, and safety) while avoiding the bad parts (lower factual accuracy)?
How they studied it (in simple terms)
Think of an LLM like a student:
- Pretraining is like the student reading tons of books and learning facts and patterns.
- Instruction-tuning is like a coach teaching the student how to politely follow directions, use the right tone, and be safe and helpful.
- A “persona prompt” is like putting the student in a costume—“now act like a safety officer” or “now act like a technical writer”—to steer how they behave.
The team tested several models on different kinds of tasks:
- Knowledge quizzes (like multiple-choice tests)—these rely on what the model memorized during pretraining.
- Generative tasks (like writing, roleplay, or formatting answers)—these rely on instruction-following and style.
- Safety tasks (like refusing dangerous or harmful requests).
They tried different expert personas (e.g., STEM expert, safety monitor), different lengths (short vs. long), and different placements (as a system instruction vs. a user message). They also checked models with different training styles, including models tuned for step-by-step reasoning.
What is PRISM, and how does it work?
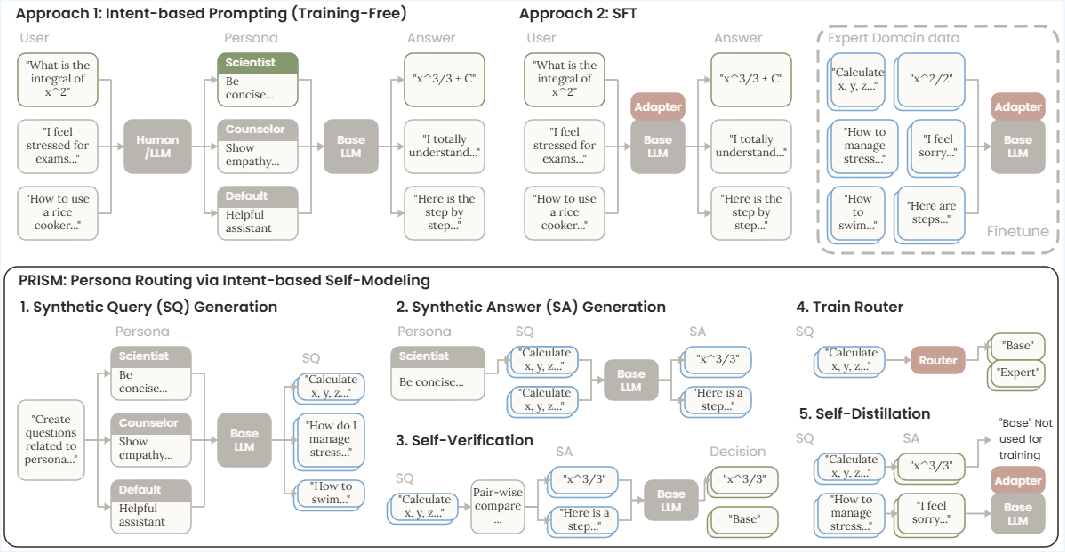
PRISM is like teaching the student when to wear which “costume”—and only when it helps. It has two small, efficient pieces:
- A tiny “gate” that decides if expert behavior should be turned on for a specific question.
- A lightweight add-on (called a LoRA adapter) that gives the model the expert’s style and safety without needing to paste a long persona every time.
Here’s the five-step process in everyday language:
- Make practice questions: For each expert type (like “safety monitor” or “writer”), the model generates sample questions that fit that expert’s domain.
- Try both ways: For each question, the model answers twice—once normally and once “in costume” (with the persona).
- Self-check: The model compares both answers and picks which one is better. To be fair, it swaps the order and checks again.
- Train the gate: The system learns a simple yes/no rule—when to turn the expert add-on on or off based on the input.
- Distill the good behavior: The adapter learns to produce the better, persona-quality answers even without seeing the persona text, so responses are faster and cheaper.
This whole process uses the model itself (no outside labeled data or extra models).
What they found and why it matters
Here are the most important results in plain language:
- Personas help with alignment tasks, hurt factual accuracy:
- Good news: Acting like an expert improves writing quality, tone, formatting, following instructions, and refusing unsafe requests.
- Bad news: The same personas often make the model worse at fact-based tasks (like academic multiple-choice questions or strict math/coding reasoning), likely because the model shifts into “follow the instructions” mode instead of “recall the precise fact” mode.
- Longer personas push harder in both directions:
- Longer expert prompts give bigger boosts in safety and style.
- But they also cause bigger drops in fact-based accuracy.
- Where you put the persona matters:
- Putting the persona in the model’s system message (its “core rules”) often has a stronger effect than putting it in the user message—especially for models that are very sensitive to system prompts.
- Training history changes everything:
- Models heavily tuned for reasoning (step-by-step thinking) sometimes get improvements from any long, structured prompt—not because the persona is right, but because it adds structure. These models may also lose earlier safety training, so a safety persona won’t help much.
- Instruction-tuned models (trained to be helpful and safe) show clear gains in style and safety from personas, but clear losses in factual accuracy.
- PRISM keeps the gains and avoids the losses:
- PRISM learns when to turn the expert add-on on or off. In tests, it improved writing and safety while keeping (or matching) accuracy on knowledge tests.
- It beat simple “always use the persona” strategies and did so with low memory and computing cost.
Why this is important
- For users: It means you can get friendlier, more structured, and safer answers without sacrificing correctness on fact-based questions.
- For developers and teachers: It shows why personas give mixed results and offers a recipe to keep the benefits while avoiding the downsides.
- For safety: A “safety monitor” persona can meaningfully raise refusal rates for dangerous prompts, and PRISM can apply that persona only when needed.
Final takeaways and future impact
- Simple rule: Personas are great for style, format, and safety; they are risky for pure knowledge recall and precise reasoning.
- Smart switch: PRISM acts like an on/off switch that applies expert behavior only when the question’s intent suggests it will help.
- Big picture: This approach can make AI assistants more dependable in everyday use—polite and safe when needed, accurate when it matters.
The authors note that they tested mainly medium-sized models and that their gate-and-adapter design adds a small integration step. Still, the idea is practical: a self-bootstrapped way to route “expert mode” only to the right questions, aiming for both better alignment and steady accuracy.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, phrased to guide concrete follow-up work:
- Model scale and generality: Do the findings (persona harms knowledge retrieval, helps alignment) and PRISM’s gains hold for larger models (e.g., 70B–405B) and closed-source SOTA? Run the same study at multiple scales and with different RLHF recipes.
- Multilingual and cross-domain robustness: The analysis is English-only; how do persona effects and PRISM behave in other languages, mixed-language inputs, and specialized domains (e.g., legal, medical, financial)?
- Human evaluation vs LLM-judge: Results rely on an LLM judge (Qwen3-32B). How sensitive are conclusions to the choice of judge and to human judgments? Replicate with multiple judges and a human-rated subset for calibration.
- Evaluation breadth for knowledge tasks: MMLU and MT-Bench proxies may miss coding execution and factual QA fidelity. Test on execution-based code suites (e.g., HumanEval+, MBPP), fact-checking QA (e.g., Natural Questions), and retrieval-intensive tasks to verify knowledge retention under PRISM.
- Alignment trade-offs beyond refusal rate: Safety is measured via refusal rates; does PRISM over-refuse benign queries or harm helpfulness? Measure safety–helpfulness trade-offs (e.g., utility on benign subsets, toxicity, jailbreak success under realistic prompts).
- Fairness and bias impacts: Persona prompting can introduce or mitigate biases, but the paper does not quantify this. Evaluate group fairness, stereotyping, and bias transfer before/after PRISM.
- Hallucination and factuality: Does PRISM reduce or exacerbate hallucinations in open-ended generation? Add factuality metrics (e.g., TruthfulQA, FactScore) and long-form hallucination audits.
- Long-context and multi-turn dialogues: PRISM’s gate uses first-layer, last-token features; does routing remain accurate in long-context or multi-turn settings where relevant signals appear later in the conversation?
- Mechanistic cause of MMLU degradation: The paper hypothesizes an “instruction-following mode” interfering with recall; validate with interpretability tools (activation patching, attention/feature attribution, logit-lens) to locate layers/features implicated.
- Persona content vs length effects: Gains/losses may be driven by length rather than content. Control with length-matched nonsense prompts and content-matched shorter prompts to isolate these factors.
- Placement sensitivity: Placement effects are noted but not systematically mapped. Systematically sweep persona placement (system vs user vs tool/context) across models with varying system-prompt dependence.
- Random vs expert personas in reasoning models: The finding that random long prompts work as well or better suggests a “context-length” effect. Test length-only scaffolds, neutral structure-only prompts, and adversarially structured contexts to quantify the effect.
- Gate feature design: The gate reads the first-layer last-token representation; are richer features (e.g., pooled multi-layer embeddings, attention-based query summaries) or uncertainty signals (entropy, MC dropout) better for routing?
- Gate calibration and policy: Only a fixed 0.5 threshold is studied. Explore calibrated thresholds, cost-sensitive routing (accuracy vs safety), and continuous mixture routing (partial adapter activation).
- Single adapter vs multi-expert routing: PRISM distills many personas into one LoRA with a binary gate. Would multiple persona-specific adapters with a multi-class router outperform a single adapter? Investigate top-1 vs top-k adapter routing.
- Adapter design space: Sensitivity to LoRA rank/targets, layer selection, and mixing rules is not explored. Run ablations on adapter capacity and target layers (incl. attention vs MLP blocks).
- Training signal and objective: Distillation uses KL to match persona-conditioned logits. Compare to preference objectives (DPO, KTO) or reward-model/RLHF-style training on the pairwise wins selected in Stage 3.
- Self-judging and confirmation bias: Self-verification uses the base model as judge, risking bias and error reinforcement. Test with external judges, cross-model adjudication, or human-in-the-loop filtering to quantify label quality.
- Distribution shift in routing data: Routing is trained on self-generated queries conditioned on personas; how well does the gate generalize to real user queries and unseen intents? Evaluate OOD generalization and add domain-randomized query generation.
- Restoring safety in reasoning-distilled models: PRISM fails to recover safety for R1 variants. Can adding synthetic constitutional signals, external safety critics, or safety-focused distillation targets reintroduce refusal behavior without hurting reasoning?
- Mixture-of-Experts applicability: PRISM could not be applied to MoE due to instability. Explore MoE-compatible adapters (e.g., expert-wise adapters, router-aware LoRA) or fine-tuning strategies that respect sparse activation.
- Interoperability with other adapters: The binary gate complicates merging with other LoRAs (task arithmetic). Develop composition schemes (e.g., gated stacking, hierarchical routers) and evaluate interference among multiple adapters.
- Latency and memory overheads: The paper claims minimal overhead but provides no measurements. Report throughput/latency/memory vs prompt-based routing and vs standard SFT across hardware.
- Security and adversarial robustness: Can adversarial inputs trigger incorrect routing (e.g., force LoRA on knowledge tasks) or bypass safety? Evaluate attack surfaces (prompt injection, adversarial triggers) on the gate and distilled adapter.
- Multi-agent and data-generation settings: The introduction motivates multi-agent diversity and synthetic data generation, but PRISM isn’t tested there. Measure whether PRISM preserves/diversifies agent behaviors and the quality/diversity of generated datasets.
- Persona pool size and coverage: Only 12 personas are used. How does performance scale with more/fewer personas and with automatic persona discovery? Study diminishing returns and redundancy among personas.
- Controllability and user intent: PRISM internalizes persona benefits but offers no explicit user control over style/tone beyond implicit routing. Add user-selectable controls and evaluate alignment with user intent vs automated gating.
- Reproducibility details: Important hyperparameters (e.g., number of queries per persona, gate/adaptor training budgets) and ablations are only partly described in appendices. Provide full configs and code to enable replication.
Practical Applications
Overview
Drawing on the paper’s findings and the PRISM pipeline (Persona Routing via Intent-based Self-Modeling), the following applications highlight how to exploit expert personas to improve alignment-dependent behaviors (style, format, tone, safety) while avoiding harm to pretraining-dependent knowledge and reasoning tasks. Each item specifies sector(s), a concrete use case, likely tools/products/workflows, and key assumptions/dependencies.
Immediate Applications
- Safer chat assistants without sacrificing accuracy (Software platforms, Trust & Safety)
- Use case: Deploy a PRISM-distilled “Safety Monitor” that automatically activates on unsafe/jailbreak intents to boost refusal rates, while routing normal and knowledge-heavy queries to the base model.
- Tools/workflows: Gated LoRA “safety adapter”; binary gate on early-layer features; policy rules for thresholding; inference-time logging of gate decisions.
- Assumptions/dependencies: Base model still retains safety alignment (reasoning-distilled models may have erased safety); infra must support gated adapters; gate must be robust to adversarial prompts.
- Tone and style enhancement without prompt bloat (Productivity apps, Marketing, Education)
- Use case: Email/copywriting/tutoring assistants automatically activate a “Writing/Roleplay” adapter for tone/format adherence, but fall back to base model for factual questions.
- Tools/workflows: PRISM-distilled style adapter; token/latency reduction by removing long persona prompts; intent cues (“draft”, “rewrite”, “tone”).
- Assumptions/dependencies: Self-judging reliably selects true improvements; judge-model biases do not distort selection; domain prompts seeded from clear domain names.
- High-precision information extraction (Enterprise automation, Finance, Insurance, Operations)
- Use case: Document/record extraction pipelines (e.g., invoices, claims, KYC) activate an “Extraction” adapter to boost structure/format adherence while preserving factual correctness.
- Tools/workflows: Extraction-focused adapter; intent detection via patterns (“extract”, “fields”, “table”); structured output validators.
- Assumptions/dependencies: Extraction is alignment-dependent (as shown) rather than knowledge-heavy; evaluation harness verifies structured compliance.
- Call center and customer support agents (Telecom, Retail, Banking)
- Use case: Gate an “Empathetic/Complaint-handling” persona only during conversational turns needing tone control; disable adapters for policy lookup, pricing, and identity checks.
- Tools/workflows: Dialogue-state signals to the gate; hybrid RAG for exact policy retrieval; auditing of gate activations by conversation segment.
- Assumptions/dependencies: Strong intent segmentation; multilingual tone adapters may be required; governance to prevent tone adapters from masking incorrect facts.
- Coding assistants with accuracy safeguards (Software engineering)
- Use case: Disable personas for code synthesis and math; optionally enable a “Documentation/Docstring” adapter on comments or READMEs to improve clarity and format.
- Tools/workflows: IDE plugin with gate; AST- or cell-level intent detection (code vs. commentary); unit-test/compile hooks to verify no regression.
- Assumptions/dependencies: Persona harms coding (paper finding), so gating must be strict; reliable code/comment segmentation is required.
- Moderation and jailbreak hardening for platforms (Social media, Community tools)
- Use case: Front-door safety gate that detects adversarial intent and activates a distilled safety adapter to increase refusal and safe redirection.
- Tools/workflows: Ensemble of regex/heuristics + gate features; long-form safety persona distilled for maximal gains; continuous red-teaming.
- Assumptions/dependencies: Support for rapid adapter updates; strong monitoring to detect evasions; alignment data retained in base model.
- Prompt/latency cost optimization (SaaS, Edge/On-device AI)
- Use case: Replace long system personas with compact gated LoRA adapters to reduce tokens and latency while preserving or improving alignment behaviors.
- Tools/workflows: PRISM training on-device or server-side; gate threshold tuning; A/B testing against prompt-based personas.
- Assumptions/dependencies: Inference stack supports conditional adapter activation; minimal overhead of the gate outweighs prompt savings.
- Multi-agent systems with controlled diversity (Robotics, Simulation, Research)
- Use case: Agents present diverse behaviors (roles/personalities) when that helps creativity or negotiation, but revert to base model for factual or planning steps.
- Tools/workflows: Per-role adapters with a shared gate policy; agent frameworks (e.g., planning phases annotate intent to guide gate).
- Assumptions/dependencies: Accurate stage-level intent labeling; guardrails to prevent degradation in critical planning sub-tasks.
- MLOps evaluation and guardrails for persona use (Enterprise IT, ML platforms)
- Use case: Split evaluation into alignment-dependent vs. knowledge-dependent suites; configure gates/policies (e.g., “persona-off for MMLU-like tasks”).
- Tools/workflows: Testing harnesses tagged by task type; routing dashboards; policy-as-code to enforce gate states per endpoint or task.
- Assumptions/dependencies: Reliable taxonomy of tasks; acceptance that personas can harm discriminative/knowledge tasks per paper’s findings.
- Reproducible persona-effect studies and teaching (Academia)
- Use case: Use PRISM’s self-bootstrapped pipeline to teach/model how personas affect different task families, without external data.
- Tools/workflows: Public scripts to generate queries, self-judge, and distill adapters; controlled experiments across models/placements.
- Assumptions/dependencies: Compute budget for self-generation and distillation; judge-model consistency; ethical use of self-judging.
- Consumer assistants with automatic “modes” (Daily life)
- Use case: Personal assistants that auto-activate “Writing Coach” or “Safety Mode” based on intent, staying in base mode for facts and calculations.
- Tools/workflows: On-device small adapters; privacy-preserving logging of gate decisions; local fine-tuning where feasible.
- Assumptions/dependencies: On-device fine-tuning resources; careful privacy design; robust intent signals from user prompts.
Long-Term Applications
- Scaling to larger and specialized architectures (Model providers)
- Use case: Gate-aware adapters for 70B+ and MoE models; co-training gates with experts to reduce instability.
- Tools/workflows: Hardware-aware gating; distributed adapter hosting; training-time regularizers for gate stability.
- Assumptions/dependencies: LoRA/gate stability on MoE (currently challenging); significant training infra and profiling.
- Regulated-domain assistants with provable guardrails (Healthcare, Finance, Legal)
- Use case: Distill “Bedside manner” or “Compliance tone” while gating off adapters during clinical/financial decisions to preserve factual accuracy; generate auditable gate logs.
- Tools/workflows: Domain-specific adapters; compliance dashboards; post-hoc audits correlating gate activations with outcomes.
- Assumptions/dependencies: Domain validation by SMEs; risk management policies; adherence to standards (HIPAA, SOX, etc.).
- Personalized, privacy-preserving personas (Consumer, Enterprise)
- Use case: On-device PRISM that learns a user’s tone/style from local drafts, activating only for stylistic rewrites.
- Tools/workflows: Federated/self-bootstrapped adapters; end-to-end encrypted gate logs; user controls to reset adapters.
- Assumptions/dependencies: Sufficient on-device compute; consent and privacy controls; prevention of content overfitting.
- Cross-modal persona gating (Vision/Audio-Language systems)
- Use case: Extend PRISM to vision/audio inputs for multimodal tutoring, captioning, or safety (e.g., refusal on violent images) without harming factual descriptions.
- Tools/workflows: Gate over multimodal encoders; distilled safety/tone adapters for VLMs; curated self-verification prompts.
- Assumptions/dependencies: Access to intermediate multimodal features; new metrics for cross-modal alignment vs. knowledge.
- RAG-aware intent gating (Enterprise software, Knowledge management)
- Use case: Gate off alignment adapters on retrieval-heavy queries (factual lookups), but enable adapters for summarization/formatting of retrieved content.
- Tools/workflows: Pipeline signals (retrieval confidence, citation count) fed to gate; joint evaluation on factuality and style.
- Assumptions/dependencies: Tight RAG–model integration; monitoring for factuality drift; careful thresholding to avoid over-activation.
- Multi-adapter orchestration and marketplaces (Ecosystem)
- Use case: Catalog of sector-specific alignment adapters (e.g., “Clinical tone”, “Legalese”, “Kid-friendly”) with intent routers selecting among them at runtime.
- Tools/workflows: Standardized gate APIs; adapter signing/versioning; revenue-sharing marketplaces.
- Assumptions/dependencies: Interoperability standards for gates/adapters; governance against unsafe or biased adapters.
- Agentic systems with dynamic persona ensembles (Robotics, Planning, Multi-agent research)
- Use case: Stage-specific gating across planning/execution phases (e.g., generator persona in brainstorming; base model for final plan).
- Tools/workflows: Task-phase annotations; meta-policies that constrain when personas can activate; plan verification.
- Assumptions/dependencies: Reliable phase detection; safety validation; avoidance of “persona bleed” into critical reasoning.
- Benchmarking and certification of persona impact (Standards, Policy)
- Use case: Define standards that separate alignment vs. knowledge tasks and certify “no degradation on knowledge tasks” when adapters are used.
- Tools/workflows: Public benchmark suites; disclosure of persona-activation rates and effects; third-party audits.
- Assumptions/dependencies: Community consensus on task taxonomy; cooperation from model vendors.
- Safety governance and organizational controls (Policy, Enterprise IT)
- Use case: Central policies that enforce gate states (e.g., “safety adapter mandatory on external endpoints”), with kill-switches and audit trails.
- Tools/workflows: Policy-as-code; SIEM integration for gate logs; periodic red-teaming tied to gate performance metrics.
- Assumptions/dependencies: Clear accountability; change-management for gate thresholds; alignment with internal risk frameworks.
Notes on Feasibility and Dependencies Across Applications
- Task sensitivity is fundamental: Personas help alignment-dependent tasks but harm pretraining-dependent knowledge and coding; applications must respect this split.
- Model optimization matters: Highly instruction-following models show stronger persona effects—both good and bad; reasoning-distilled models may have erased safety, limiting safety gains.
- Infrastructure needs: Successful deployment requires support for gated LoRA at inference and access to model logits for distillation.
- Data and evaluation: PRISM is self-bootstrapped (domain names only), but self-judging introduces biases; organizations should validate with human or trusted judges.
- Integration constraints: PRISM’s gate+adapter may not be compatible with simple LoRA-merging; plan for separate components and MLOps changes.
- Security and auditability: Gate decisions should be logged and auditable, especially in regulated settings, and robust to adversarial prompts.
Glossary
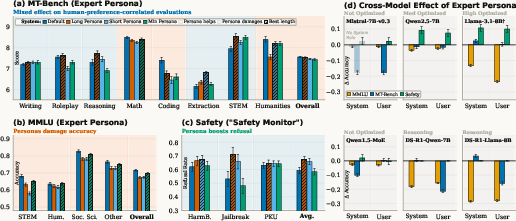
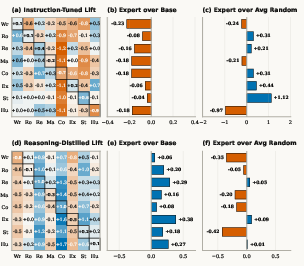
- alignment-dependent tasks: Tasks whose performance depends on instruction-following behaviors like format, tone, safety, and preference alignment rather than factual recall. "Conversely, for alignment-dependent tasks such as format-following generation, safety, and preference satisfaction, an expert persona consistently helps."
- binary cross-entropy: A loss function for binary classification measuring the difference between predicted probabilities and binary targets. "The gate loss is binary cross-entropy:"
- binary gate: A learned on/off controller that decides whether to activate an auxiliary component (e.g., an adapter) for a given input. "with a binary gate that routes queries to the base model when persona activation is not beneficial."
- bootstrapped pipeline: A self-contained training process that generates its own data and supervision signals without external resources. "we propose PRISM (Persona Routing via Intent-based Self-Modeling), a fully bootstrapped pipeline that internalizes intent-conditioned expert persona routing without external supervision."
- chain-of-thought reasoning: Step-by-step intermediate reasoning traces used by models to solve complex tasks. "though MT-Bench scores reflect the inherent difficulty of persona integration with chain-of-thought reasoning (\S\ref{sec:personas_help})."
- context distillation: Training a model to internalize behaviors present in prompts (context) so they are reflected in the weights and no longer require the prompt at inference. "Context distillation (CD) internalizes model context such as system-prompt behavior into model weights"
- constitutional self-critique: A self-supervision approach where a model critiques and revises its outputs according to a predefined constitution of rules or principles. "and constitutional self-critique"
- DeepSeek-R1: A reasoning-focused source model used for distillation in certain LLM variants. "Distilled from DeepSeek-R1; reasoning/code/STEM-heavy training set"
- distillation set: The selected dataset of input–output pairs used to transfer desirable behaviors from a teacher to a student model. "Self-Verification for distillation set selection via pairwise comparison"
- ExpertPrompting: A prompting framework for generating detailed expert role descriptions that steer LLM behavior. "Personas are generated via ExpertPrompting~\cite{xu2023expertprompting} at three granularity levels (full, short, minimum);"
- gate-conditional probability shift: The change in a model’s output distribution depending on whether a learned gate activates an adaptation module. "inducing a gate-conditional probability shift:"
- gated LoRA adapter: A LoRA-based parameter-efficient module whose activation is controlled by a learned gate to selectively alter the model’s behavior. "self-distills an intent-conditioned expert persona into a gated LoRA adapter through a bootstrapping process that requires no external data, models, or knowledge."
- HarmBench: A benchmark evaluating a model’s safety alignment by measuring refusal or compliance on harmful prompts. "We evaluate on three axes—generative quality (MT-Bench), discriminative accuracy (MMLU), and safety alignment (HarmBench, JailbreakBench, PKU-SafeRLHF)"
- intent-based routing: Directing inputs to specialized behaviors or components based on the detected intent of the query. "intent-based routing~\cite{chen2023frugalgpt, ong2024routellm}, where a router model is used to detect query intent and route each user request to the most suitable expert persona at inference time."
- instruction-tuned: Models further trained on instruction–response pairs to improve instruction following and alignment. "across instruction-tuned and reasoning LLMs"
- JailbreakBench: A benchmark focused on adversarial prompts designed to circumvent safety guardrails (jailbreaks). "We evaluate on three axes—generative quality (MT-Bench), discriminative accuracy (MMLU), and safety alignment (HarmBench, JailbreakBench, PKU-SafeRLHF)"
- KL divergence: A measure of how one probability distribution diverges from another, used for distillation. "The LoRA-augmented student is trained via KL divergence to reproduce persona-quality outputs without the persona prompt:"
- LLM-as-a-Judge: An evaluation paradigm where strong LLMs act as judges to score other models’ outputs. "following the LLM-as-a-Judge framework~\cite{zheng2023judging}"
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method that inserts low-rank updates into selected layers. "Crucially, LoRA is applied only to layers $1$ through , so layer~0 remains unmodified,"
- Mixture-of-Experts (MoE) architectures: Models with multiple expert subnetworks where only a subset is activated per input to improve capacity and efficiency. "Mixture-of-Experts architectures present challenges for LoRA-based finetuning due to their sparse activation patterns, limiting PRISM's applicability to such models."
- MMLU: Massive Multitask Language Understanding; a multi-domain multiple-choice benchmark for knowledge and reasoning. "On MMLU (Figure~\ref{fig:granularity}b), when the LLM is asked to decide between multiple-choice answers, the expert persona underperforms the base model"
- MT-Bench: A multi-turn benchmark assessing the quality of model-generated responses across categories like writing, reasoning, and coding. "MT-Bench (Figure~\ref{fig:granularity}a) shows that expert personas improve scores in 5 out of 8 categories"
- pairwise comparison: An evaluation method that compares two candidate outputs head-to-head to choose the better one. "we employ pairwise comparison with position swapping."
- persona prompting: Steering an LLM using role descriptions (personas) to induce specific styles, tones, or behaviors. "Persona prompting can steer LLM generation towards a domain-specific tone and pattern."
- PKU-SafeRLHF: A safety evaluation dataset derived from RLHF-style training focusing on safe responses. "We evaluate on three axes—generative quality (MT-Bench), discriminative accuracy (MMLU), and safety alignment (HarmBench, JailbreakBench, PKU-SafeRLHF)"
- position swapping: Switching the order of compared outputs to reduce position bias during pairwise evaluation. "we employ pairwise comparison with position swapping."
- PRISM (Persona Routing via Intent-based Self-Modeling): A method that bootstraps and distills persona benefits into a gated adapter with an intent-based gate, requiring no external data. "we propose PRISM (Persona Routing via Intent-based Self-Modeling), a fully bootstrapped pipeline that internalizes intent-conditioned expert persona routing without external supervision."
- prompt compression: Techniques that shorten prompts while preserving their effect to reduce inference cost. "Prompt compression~\cite{chevalier2024gisting, li2024llmlingua2} reduces cost but requires additional components to address selectivity."
- reasoning-distilled models: Models fine-tuned via distillation from a strong reasoning source to emphasize step-by-step reasoning and related skills. "spanning instruction-tuned, MoE, and reasoning-distilled models."
- reinforcement learning from human feedback (RLHF): Training that aligns model outputs with human preferences by using human feedback as a reward signal. "These behaviors are reinforced through RLHF or supervised fine-tuning"
- refusal rate (RR%): The percentage of prompts for which a model refuses to produce unsafe outputs, used as a safety metric. "Safety: Refusal Rate (RR%, ↑) on HarmBench (HB), JailbreakBench (JB), and PKU-SafeRLHF (PKU);"
- router model: A classifier that selects which expert persona or component to use for a given input at inference time. "where a router model is used to detect query intent and route each user request to the most suitable expert persona at inference time."
- self-distillation: A process where a model learns from its own (or its persona-augmented) outputs, treating them as teacher signals. "Stage 5: Self-Distillation via LoRA."
- self-play: Approaches where a model generates its own training tasks and solutions to improve without external supervision. "Self-play methods bootstrap learning without external supervision, including self-generated instructions"
- self-rewarding: Methods where a model infers or learns its own reward signals to guide improvement without external labels. "self-rewarding,"
- self-verification: Having the model evaluate its own outputs to filter or select high-quality behaviors. "then uses self-verification to retain only behaviors where the expert prompt actually helps."
- sigmoid function: A squashing function mapping real-valued inputs to [0, 1], commonly used for binary gating. "and is the sigmoid function."
- sparse activation: A property where only a subset of experts or neurons are active for a given input, common in MoE models. "due to their sparse activation patterns"
- system prompt: A special prefix instruction that sets the global behavior or persona of a chat model. "No-Sys (empty system prompt)"
- system-prompt-optimized: Models particularly tuned to follow instructions placed in the system prompt strongly. "The more system-prompt-optimized a model is (e.g., Llama), the greater the benefits and lesser the damage from the expert persona."
- teacher logits: The teacher model’s pre-softmax scores used to guide student training in distillation. "The teacher logits are cached from the base model conditioned on the winning persona:"
- temperature scaling: Adjusting the softness of a probability distribution by dividing logits by a temperature before softmax. "Implementation details (top- logit retention, temperature scaling, LoRA rank and targets) are in Appendix~\ref{app:gated_lora_setup}."
- top- logit retention: Keeping only the largest k logits when transferring or storing teacher signals for distillation. "Implementation details (top- logit retention, temperature scaling, LoRA rank and targets) are in Appendix~\ref{app:gated_lora_setup}."
- verbosity bias: A judging bias preferring longer or more verbose answers regardless of quality. "To eliminate position bias and verbosity bias (see Appendix~\ref{app:verbosity_bias}), this comparison is run twice with the answer order swapped."
- zero-shot reasoning: The ability to perform reasoning tasks without task-specific examples in the prompt. "and role-playing can degrade LLMs' zero-shot reasoning~\cite{kim2025persona}."
Collections
Sign up for free to add this paper to one or more collections.