- The paper presents a robust multimodal framework using text, audio, and image cues to generate long-term, high-fidelity digital human video animations.
- The paper introduces pivotal frame anchoring and threshold-aware latent codebook replacement to ensure identity preservation and semantic consistency during extended video generation.
- The paper demonstrates state-of-the-art performance in video-text alignment, lip synchronization, and inference efficiency, supported by the new Soul-1M dataset and Soul-Bench evaluation.
Soul: High-fidelity Long-term Multimodal-driven Human Video Animation
The paper presents Soul, a multimodal generative framework targeting high-fidelity, long-duration digital human animation leveraging single-image, text, and audio cues. It addresses bottlenecks in legacy methods, including lack of fine-grained annotated datasets, degradation under long-term inference (identity drift, semantic decay), and inefficiency at high resolutions. The focus is on achieving robust video-text-audio alignment, identity preservation, and lip sync, all in extended sequences, while supporting interactive and realistic scenarios for downstream applications such as virtual anchors and film production.
Model Architecture and Multimodal Conditioning
Soul is constructed atop the Wan2.2-5B foundation video diffusion model, selected for its strong fidelity and direct 1080P output. The core innovation lies in its integration of an audio-injection attention mechanism and text-guided conditioning using DiT. Audio features, extracted via Whisper, are injected into DiT blocks using audio-attention modules initialized from text-attention weights, promoting joint-modal convergence. Text prompts provide fine-grained trajectory and context control, enabling Soul to respond accurately to varied instructions for behavior, gesture, shot, and camera motion, supporting both single- and multi-person scenarios.
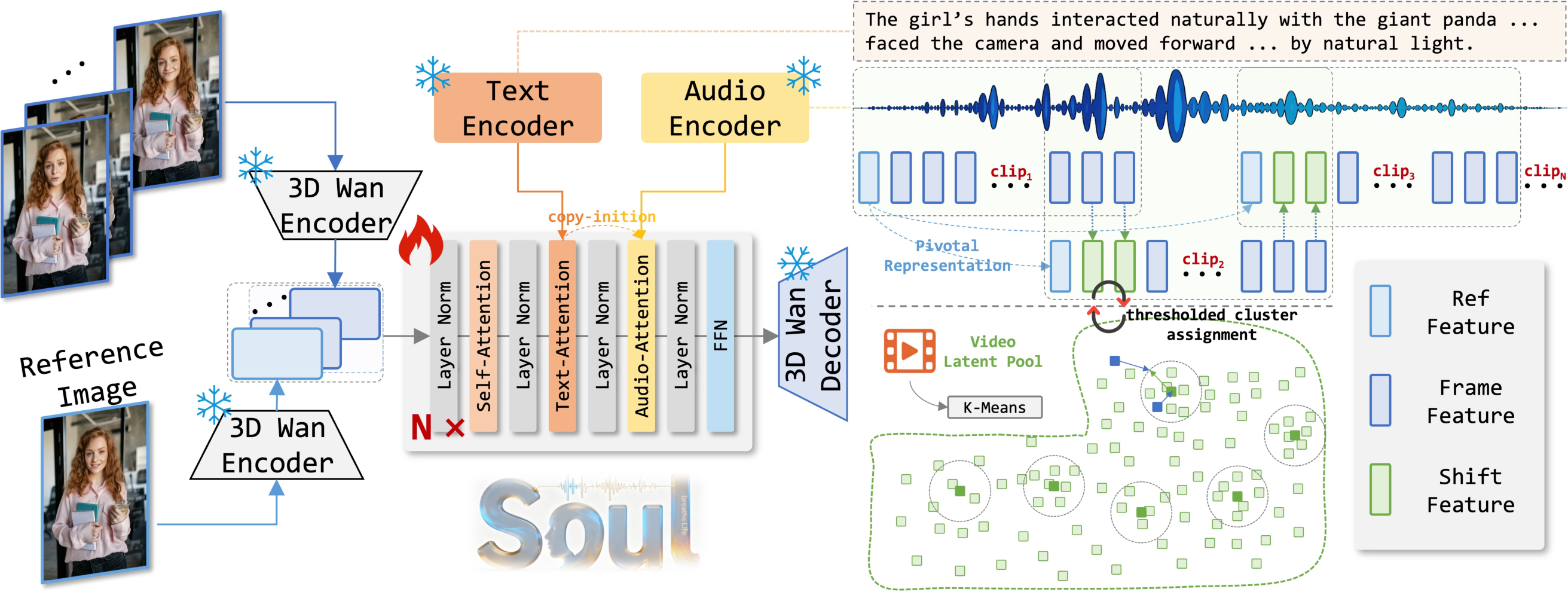
Figure 1: Overview of Soul for semantic-consistent and long-term multimodal-driven human video animation.
Long-term Generation Methodology
To maintain subject identity and scene consistency in extended generations, Soul introduces a multi-pronged protocol:
These strategies collectively enable stable multi-minute identity-consistent animation beyond the reach of prior approaches.
Dataset Construction: Soul-1M and Soul-Bench
Recognizing dataset limitations as a core challenge, the authors curate Soul-1M, a 1M-sample corpus of multimodal human videos with fine-grained automated annotations. Video curation encompasses portraits, upper-body, full-body, and multi-person scenarios. Meticulous pipeline filtering ensures high quality through face detection, shot boundary analysis, audio-video synchronization, and manual/MLLM-based validation. Annotation granularity spans actions, gestures, scene dynamics, and camera operations.

Figure 3: Statistical distributions of Soul-1M across shot type, number of subjects, audio type, resolution, aspect ratio, and duration.
For evaluation, Soul-Bench is introduced—a 226-sample benchmark with controlled diversity across scene, modality, resolution, and duration, incorporating both synthetic and real-world segments. This provides a reliable testbed for fair, comprehensive assessment of multimodal-driven methods.
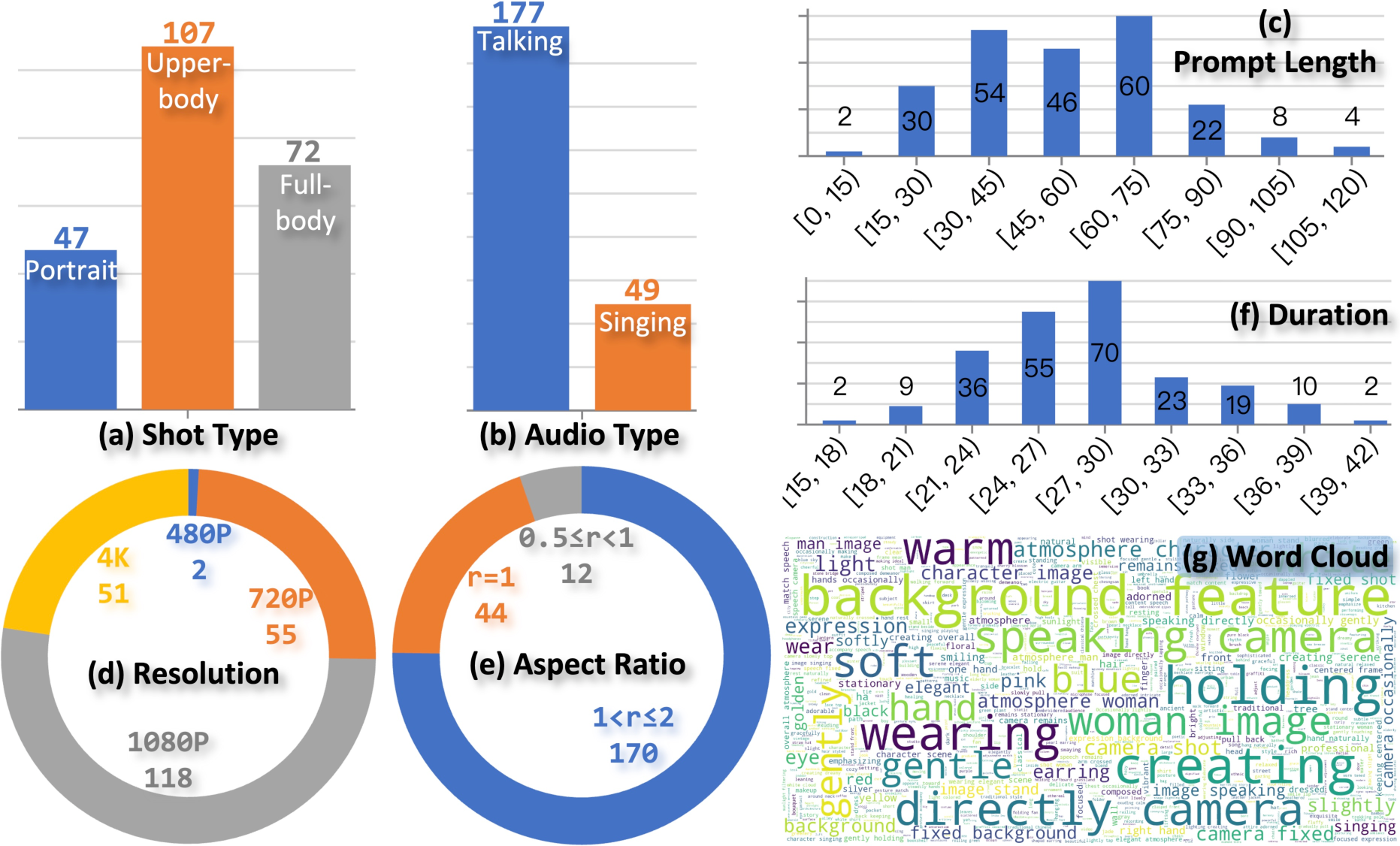
Figure 4: Statistical distributions of Soul-Bench test set in terms of content type and prompt characteristics.
Efficient High-resolution Inference
Soul achieves an 11.4× inference speedup versus baseline thanks to:
- Step/CFG Distillation: Distribution-matching distillation is leveraged to reduce denoising steps and CFG ratios, accelerating sampling with negligible accuracy loss.
- Efficient VAE Decoder (eVAE): Model footprint and compute are substantially reduced by deploying a streamlined decoder/encoder architecture, preserving perceptual quality (as measured by LPIPS) while compressing computational demands.
These optimizations close the gap for real-time, resource-efficient deployment in high-resolution applications.
Experimental Results
On Soul-Bench, Soul exhibits strong performance across all axes:
- Video-Text Consistency: Achieves the best Qwen3-VL alignment scores.
- Lip-sync Accuracy: LSE-D and LSE-C are consistently superior, reflecting robust synchronization.
- Identity Preservation: ArcFace similarity metrics are at or above competing methods.
- Video Quality: FineVQ scores confirm perceptual and structural fidelity.
Notably, Soul provides higher mean scores than state-of-the-art baselines (Sonic, Wan-S2V, InfiniteTalk, StableAvatar, OmniAvatar) for video-text and audio-video alignment.

Figure 5: Qualitative comparison with state-of-the-art methods—Soul maintains semantic alignment and image quality across scenarios at higher generation efficiency.
Long-term visualizations (four minutes, identity-preserving) further showcase Soul’s temporal stability and generalization to varied instructions and environmental contexts.

Figure 6: Identity-consistent long-term animation across scenes with joint audio and text conditioning, demonstrating Soul’s capability for multi-minute dynamic video.
Ablation and Human Study
Ablation analyses verify the essential role of threshold-aware codebook replacement in resisting long-term drift. Deployment accelerations (KD and eVAE) are shown to not only reduce inference times but also retain output quality.
Human studies (professional video raters) benchmark Soul against closed-source commercial leaders (Kling-Avatar, HeyGen), with Soul emerging as the highest-rated on overall naturalness, identity consistency, instruction fidelity, and audio-visual sync.
Practical and Theoretical Implications
Soul advances digital human animation and telepresence by enabling scalable, photorealistic, and semantically-controlled video synthesis. The multimodal pipeline and codebook-based stabilization mechanisms directly impact robust long-duration generation, mitigating identity and feature drift. The data pipeline sets a new standard for label richness and coverage.
Practically, Soul is positioned for real-time interactive use in virtual anchors, film, and other multimodal-driven avatar systems. The modular acceleration stack (step distillation + eVAE) is immediately transferable to other foundation model deployments prioritizing latency.
Theoretically, threshold-aware codebook interventions highlight latent distributional mismatch as a limiting factor in long-sequence video synthesis, suggesting future research into more powerful transition-aware or streaming architectures. Expansion toward fine-grained 3D priors and rare, complex motion types remains an open avenue.
Conclusion
Soul demonstrates an effective combination of scale, annotation detail, and multimodal modeling yielding state-of-the-art long-term human video animation. Quantitative and human studies confirm its superiority on fidelity, semantic alignment, and efficiency. While complex full-body motions remain a challenge, the release of Soul-1M and Soul-Bench will catalyze ongoing developments in controllable, robust digital human generation. Future work includes dataset diversification, multilingual audio integration, and incorporation of explicit geometric priors.
