- The paper introduces MAB-DQA, a novel framework that uses multi-armed bandit guided query decomposition and hypergraph modeling to prioritize aspect relevance in document QA.
- It leverages vision-language model feedback to dynamically allocate retrieval attention across subqueries, balancing exploration and exploitation.
- Empirical evaluations demonstrate up to an 18.5% accuracy gain and robust retrieval performance across diverse multimodal DQA benchmarks.
Multi-Armed Bandit Approaches for Aspect-Aware Retrieval in Document Question Answering
Introduction
The paper "MAB-DQA: Addressing Query Aspect Importance in Document Question Answering with Multi-Armed Bandits" (2604.08952) addresses a persistent limitation in Document Question Answering (DQA) with multimodal Retrieval-Augmented Generation (RAG): the retrieval mechanism's inability to differentiate among the variable importance of implicit aspects within complex queries. Classical vision-query late interaction approaches such as Colpali or MoloRAG use a maximal similarity paradigm resulting in frequent focus on visually salient, semantically frequent but informationally unimportant content, causing critical evidence to be overlooked in favor of spurious matches.
The authors propose the MAB-DQA framework, which operationalizes dynamic, aspect-aware evidence retrieval via query decomposition into subqueries and a multi-armed bandit (MAB)-guided allocation of retrieval attention. The approach exploits vision-LLM (VLM) feedback to adapt online to the relative utility of different aspects, constructing an aspect-aware hypergraph to guide retrieval and integrating evidence through a reflective reasoning pipeline.
Motivation and Empirical Diagnosis
Analysis of existing retrieval paradigms highlights the inability of token- or patch-level late interaction architectures to reweight query aspects in accordance with their actual informativeness for the task at hand, resulting in consistently high scores for frequent but semantically marginal tokens or phrases. Figure 1 provides a granular qualitative breakdown, evidencing the tendency of prior systems to assign high matching scores to non-answer pages featuring repetitive or contextually low-value terms. Aspects with marginal importance can, due to their frequency, yield higher aggregate scores than rare but crucial evidence, directly impairing end-to-end QA accuracy.

Figure 1: Visualization of aspect retrieval failure modes under classical late interaction models: high similarity heatmaps on irrelevant pages, and the tendency of low-importance aspects to dominate the aggregate matching score.
MAB-DQA Architecture
Aspect Decomposition and Hypergraph Modeling
The core architectural element is the decomposition of the incoming query into a set of aspect-aware subqueries via a specialized VLM prompt (see Appendix: Prompt for Decompose Query). The resulting set of atomic (fine-grained) and integral (global) subqueries induces a hypergraph structure over the document's pages: each hyperedge corresponds to pages with top late-interaction relevance to a subquery. Inter-page relationships are encoded through both query-agnostic similarity graphs and query-specific hyperedges. This structural representation enables precise tracking of evidence locality per aspect and paves the way for aspect-wise credit assignment.
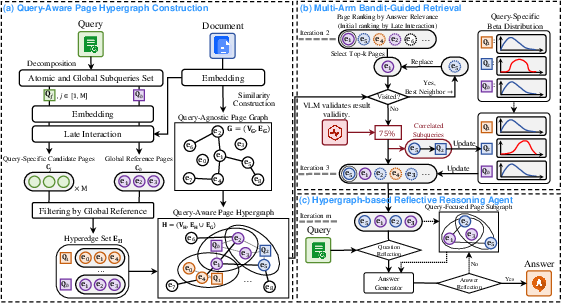
Figure 2: Overview of MAB-DQA framework—query decomposition, hypergraph construction, aspect-as-arm MAB retrieval, and reflective reasoning for final answer.
Bandit-Guided Retrieval Process
Retrieval is instantiated as a combinatorial multi-armed bandit process. Each subquery corresponds to a bandit arm whose expected reward models the likelihood of yielding relevant evidence. The VLM, deployed with targeted aspect-specific queries, evaluates candidate pages, and its scores instantiate bandit rewards. A Thompson Sampling policy is employed for balancing exploration (evaluating less-certain aspects) versus exploitation (pulling high-yield aspects). Critically, the composite retrieval score integrates (i) the maximum late interaction, (ii) current VLM reward for the page, (iii) hypergraph-based page degree, and (iv) the Thompson posterior mean for associated arms, allowing the retrieval budget to aggregate bidirectionally across subqueries and evidence clusters.
Reflective Reasoning and Multi-Stage Verification
Following evidence retrieval, the Hypergraph-based Reflective Reasoning Agent (HRRA) synthesizes answers in an iterative process: initial answer generation, critical analysis for coverage and consistency, question/answer reflection for ambiguity or error correction, and, if needed, reentry into the hypergraph for targeted completion. This multi-stage agent pipeline is critical for robust handling of queries spanning multiple evidence clusters and for multi-hop reasoning.
Experimental Results
The empirical study evaluates MAB-DQA on four multimodal DQA benchmarks: MMLongBench, LongDocURL, PaperTab, and FetaTab. The principal evaluation metrics include answer accuracy (based on GPT-4o judgment) and retrieval efficacy (Recall, Precision, NDCG, MRR under various Top-K regimes).
Table 1 and Table 2 (described in the text) show MAB-DQA yields consistent and strong improvements in both answer accuracy and retrieval quality versus state-of-the-art baselines (Colpali, MoloRAG, MDocAgent, M3DocRAG). On average, MAB-DQA achieves an answer accuracy gain of 10.38% over the strongest competitive baseline, with up to 18.5% improvement on PaperTab—the only approach to exceed 0.45 accuracy on all benchmarks. Retrieval metrics likewise show significant gains, with recall and MRR improvements in all Top-K regimes.
Ablation studies clarify that both the MAB-guided retrieval and the HRRA are non-trivial contributors: removing either module substantially degrades performance, especially on datasets requiring cross-aspect or multi-hop reasoning.
Component and Sensitivity Analysis
Sensitivity analysis (Figure 3 and Figure 4) confirms that performance is strongly monotonic in α (VLM scoring weight) and λ (aspect-confidence weighting), less so with regard to β (hypergraph balancing). Grid search and robustness analysis reveal that the core advantages of the model persist across a range of plausible hyperparameter settings.
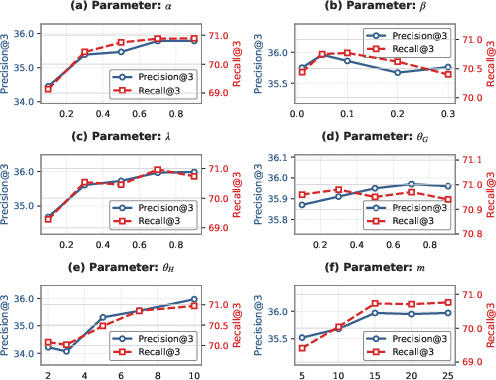
Figure 3: Precision and Recall sensitivity on LongDocURL as a function of core scoring hyperparameters (α, β, λ): large positive effect for VLM and aspect-confidence weights.
Ablation at the module level (details in Appendix) further demonstrates that query decomposition and aspect-aware confidence aggregation are indispensable—removal leads to marked regression in retrieval and answer accuracy, especially in settings with diverse or compositional queries.
Model inference efficiency is reported in Figure 5: despite the additional stages in MAB-DQA, total inference time remains competitive due to the early elimination of irrelevant evidence and selective querying of the VLM.
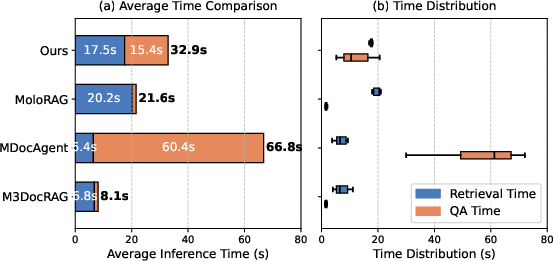
Figure 5: Average inference time comparison—MAB-DQA achieves competitive wall-clock performance despite richer retrieval and reasoning logic.
Qualitative Case Studies
Figures 5–8 provide case-based visualization of MAB-DQA's advantages:
- Figure 6 demonstrates canonical multi-aspect QA where MAB-DQA uniquely retrieves ground-truth evidence in spite of numerous frequent but irrelevant terms present in distractor pages.
- Figure 7 details a 13-page evidence spanning query, highlighting MAB-DQA's broad recall and its ability to focus on correct evidence clusters while confining distractors.
- Figures 7 and 8 showcase multi-hop reasoning and suppression of high-frequency distractor terms, respectively: MAB-DQA is unique in accurately reranking and excluding distractor pages, yielding both higher recall and precision.
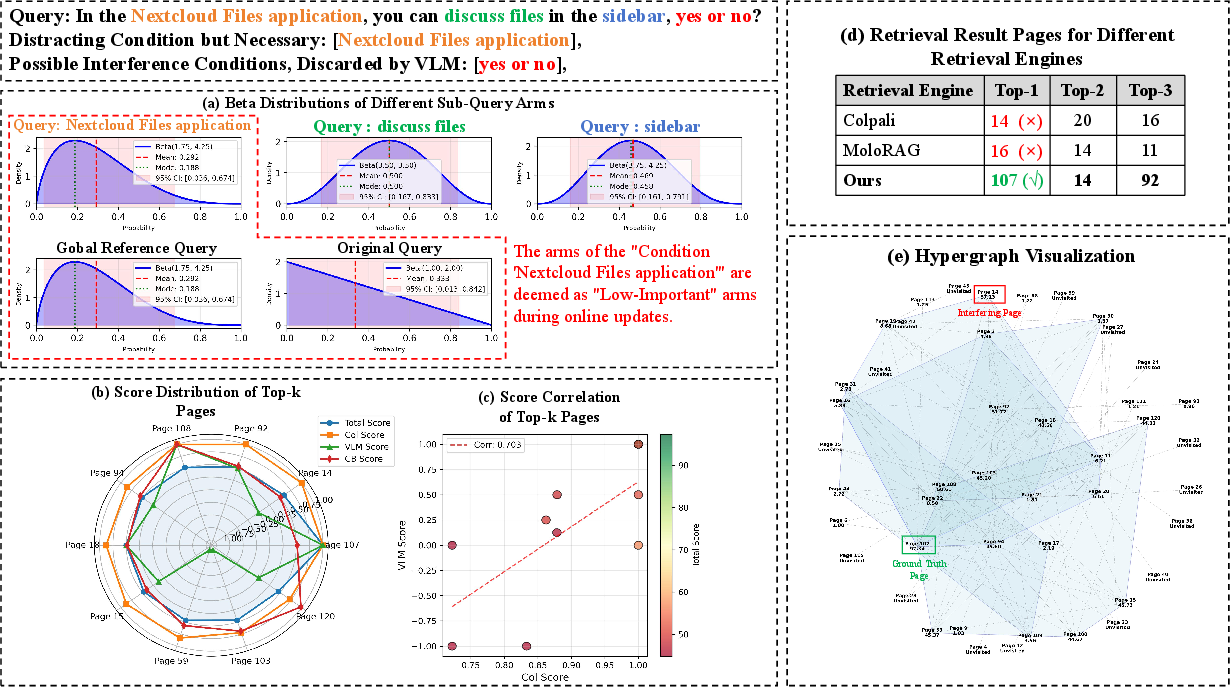
Figure 6: Qualitative analysis—MAB-DQA surpasses baselines in aspect prioritization and evidence localization.
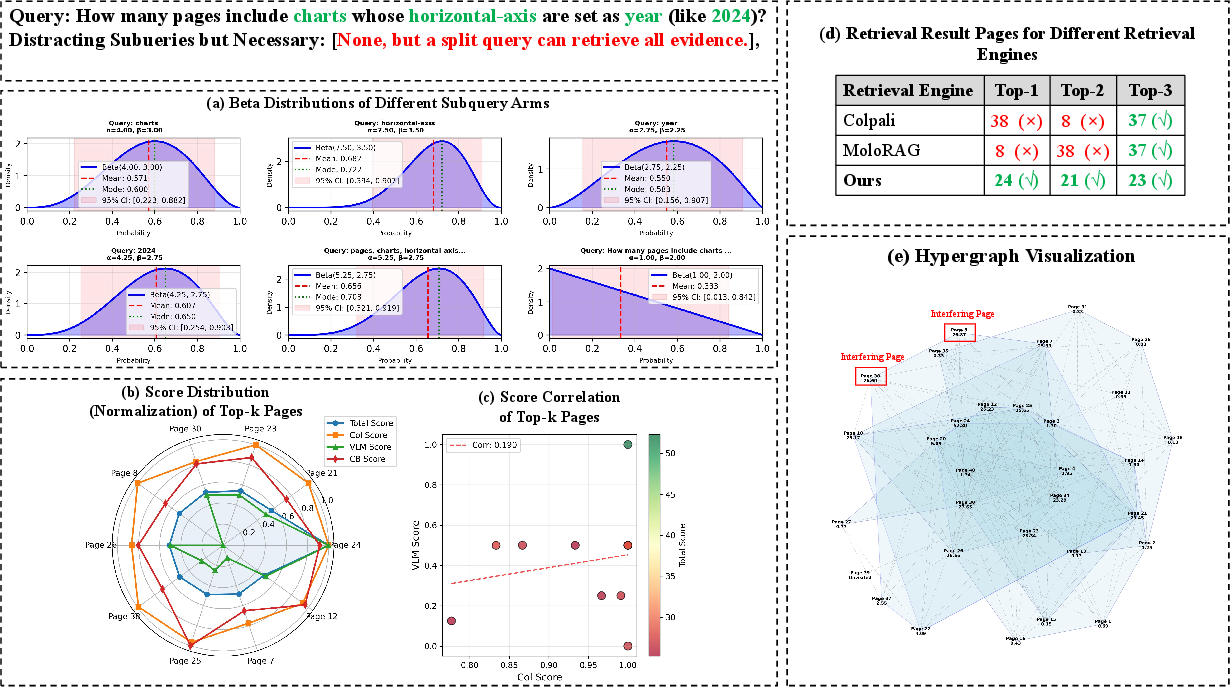
Figure 7: MAB-DQA’s hypergraph recall of all correct evidence pages in a complex multi-page query.
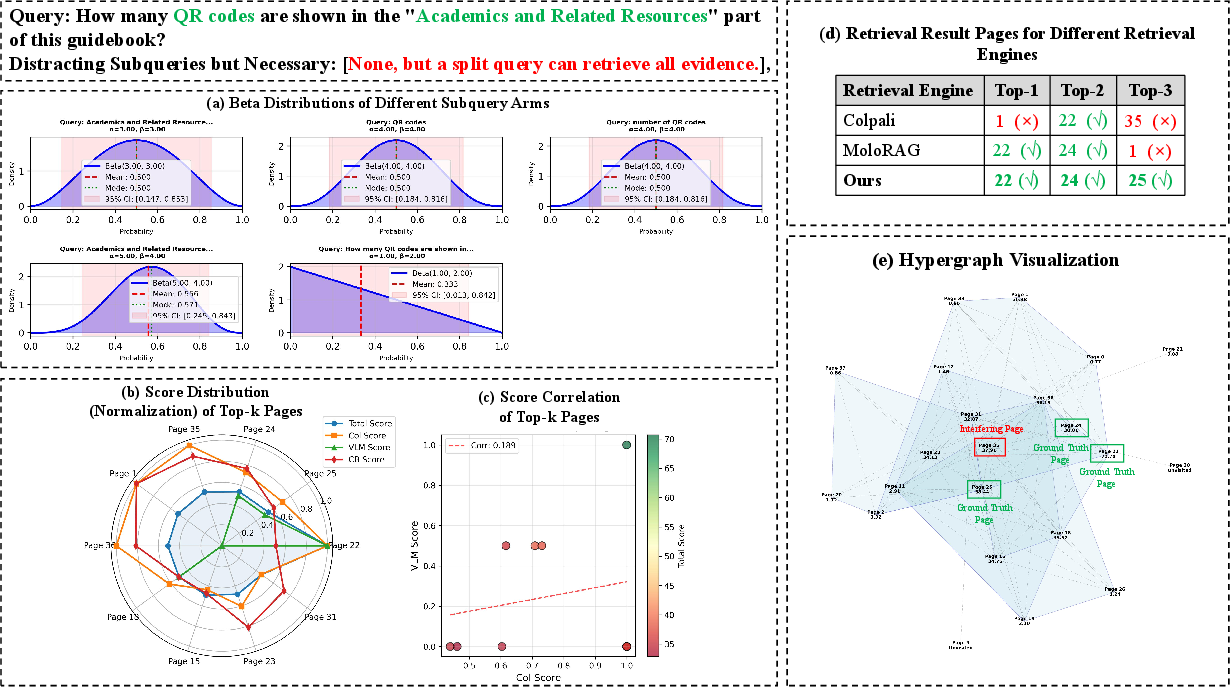
Figure 8: Iterative reranking and exclusion of distractors enables complete multi-hop evidence aggregation and factually correct answers.
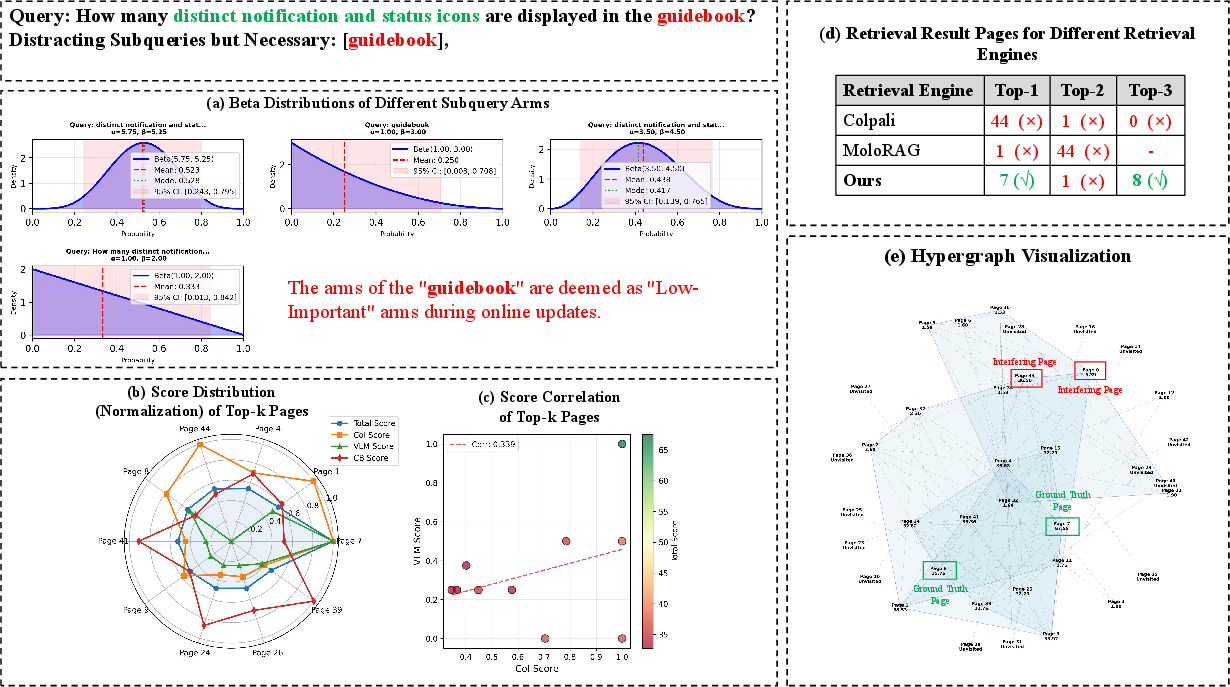
Figure 9: Distraction by high-frequency, low-value terms is actively suppressed by aspect-aware selection, enabling correct retrieval.
Limitations and Broader Implications
Dependence on the underlying VLM limits domain transferability: poor VLM representations or decompositions propagate downstream errors. Scalability is contingent on the balance between retrieval selectivity and computational cost, especially in extreme long-document or high-query-aspect regimes. The chief algorithmic limitation is the exclusive reliance on Thompson Sampling for aspect selection; generalization to alternative bandit policies and adaptive control remains an open direction.
Practically, the aspect-aware control of retrieval attention underpins significant improvements in QA systems where answer evidence is distributed, ambiguous, or concealed by irrelevant frequent structure—prototypical in scientific, technical, regulatory, or long-form semi-structured documents.
Theoretically, MAB-DQA provides a robust instantiation of online credit assignment in retrieval-augmented settings, drawing an explicit connection between evidence accumulation, aspect utility estimation, and answer quality in the VLM-RAG context. Extensions may incorporate richer aspect representations (e.g., leveraging LLM-driven query expansion, adaptive bandit strategy selection, or meta-reasoning over aspect interdependence).
Conclusion
The MAB-DQA framework demonstrates that aspect-aware retrieval, enforced via multi-armed bandit feedback and hypergraph modeling, is an effective strategy for overcoming myopic and frequency-driven failures in multimodal DQA. The methodology is supported by substantial empirical gains in both document retrieval and end-to-end QA across structurally diverse benchmarks. The explicit modeling of aspect importance and dynamic allocation of retrieval attention set a strong methodological precedent for future work in robust, aspect-sensitive, and scalable document question answering systems.