- The paper introduces PETITE, a tutor-student multi-agent framework that iteratively refines code solutions with structured feedback.
- The methodology leverages role-differentiated interaction and early stopping, drawing from peer tutoring principles to optimize resource usage.
- Empirical results on the APPS benchmark show PETITE achieving comparable or superior success rates with significantly lower token consumption.
Enhancing LLM Problem Solving via Role-Differentiated Multi-Agent Interaction: A Summary of PETITE
Overview of the PETITE Framework
The paper introduces PETITE (Peer Tutoring Inspired Token-Efficient), a framework that leverages a tutor-student multi-agent interaction paradigm inspired by peer tutoring and scaffolding theory within human cognitive development. In PETITE, two instances of the same LLM are instantiated in asymmetric roles: a student agent tasked with code generation and iterative refinement, and a tutor agent that provides structured feedback and makes correctness decisions without ground-truth access. The primary motivation is to induce synergistic capabilities in LLMs by configuring role-based, serial interactions rather than relying on enhanced model capacity or parallel ensemble methods.
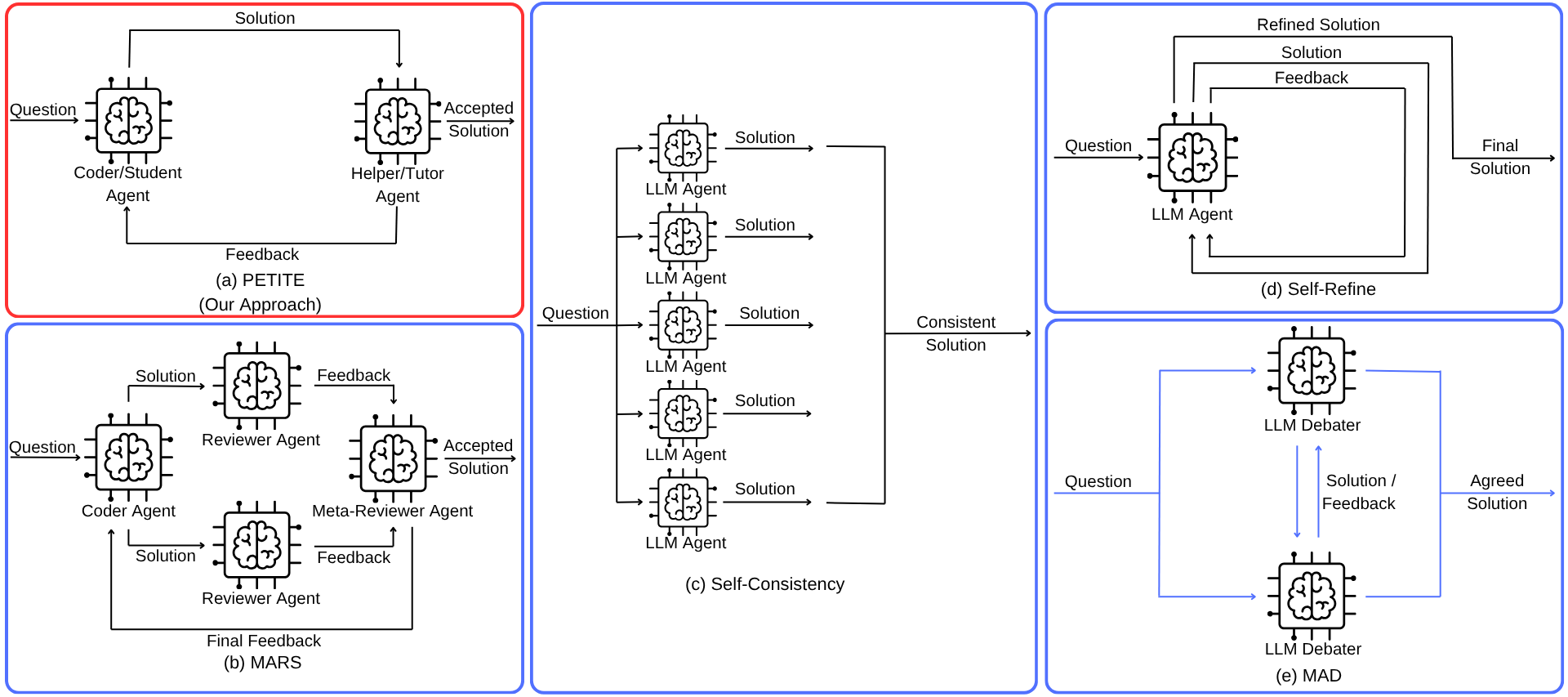
Figure 1: Architectures compared—PETITE’s tutor-student refinement, MARS’s multi-review parallelism, Self-Consistency’s sampling, Self-Refine’s self-critique, and MAD’s agent debate.
The PETITE methodology draws direct contrasts with leading frameworks in code generation, namely Self-Consistency, Self-Refine, Multi-Agent Debate (MAD), and MARS. PETITE's early stopping strategy—activating once the tutor agent deems a solution correct—yields adaptive efficiency per problem difficulty. This structured interaction is argued to better leverage the analytical capabilities of the LLM in evaluation versus generation, paralleling findings from cognitive science that role specialization in peer learning environments enhances analytical reasoning and solution quality.
Mechanism of PETITE: Agent Roles and Iterative Refinement
The PETITE iterative process is formally structured: the student generates candidate code, which the tutor critiques and either accepts or requests further refinement, closing the loop with the student until the tutor issues a “Decision: Correct.” Notably, the tutor possesses no privileged access to ground-truth labels; instead, correctness evaluation relies strictly on critiquing the solution's logical and structural qualities as inferred from the prompt and feedback. This design induces a sequential, token-efficient refinement process where computational resources are adaptively allocated—the tutor expends more effort on challenging problems, while simple cases are concluded expediently.

Figure 2: Depiction of student-tutor feedback and progressive refinement converging to a correct code solution.
Tutoring prompts are highly structured, anticipating a cohort of error modalities (logical, syntactic, edge cases), and enforcing explicit decision signals to facilitate loop termination. The student’s prompt, by contrast, is restricted to code-only responses, discouraging narrative distractions and enforcing focus on code correction.
Empirical Evaluation: Experimental Setup and Metrics
PETITE was implemented atop Qwen2.5-Coder-7B-Instruct, utilizing quantized inference and moderate temperature sampling, and evaluated on a 100-problem subset of the APPS benchmark which spans Introductory, Interview, and Competition-level code challenges.

Figure 3: A representative “Interview” difficulty problem from META APP, highlighting the natural language specification and associated test cases.
The primary baselines were:
- Self-Consistency (SC): Multiple independent generations, selecting by majority vote.
- Self-Refine (SR): Iterative model self-critiquing and refinement.
- Multi-Agent Debate (MAD): Exchanges among debating LLM agents until consensus.
- MARS: Hierarchical multi-agent reviews and meta-review synthesis.
Performance metrics included:
- Success Rate: Fraction of test cases passed by final solution.
- Improvement: Delta in success from initial to final solution.
- Token Consumption: Aggregate token usage for student and tutor.
- Efficiency Ratio: Success rate normalized by token count.
Numerical Results and Analysis
PETITE achieves comparable or superior accuracy to the baselines with significantly lower token consumption. With two refinement iterations (PETITE (2)), it attains a success rate of 31.62%, outperforming MARS (30.06%) and all other baselines. Notably, PETITE (2) averages only 5,277 tokens per problem, in contrast to MARS (7,320) and MAD (23,630). The single-iteration PETITE variant already surpasses non-reviewer and non-debate approaches.
Performance breakdown by difficulty indicates PETITE’s dominance particularly in the Interview set (30.77% success), representative of common practical coding scenarios. Furthermore, PETITE’s efficiency is robust across difficulty tiers, consuming only 3,078 tokens on introductory problems (substantially less than all multi-agent baselines). These results highlight that extending iterative self-refinement or debate-based approaches rapidly increases cost without proportionate accuracy improvements. Increasing iterations within PETITE yields diminishing returns beyond two steps, marking a strong Pareto efficiency point for practical deployments.
Implications and Theoretical Considerations
The serial, role-differentiated interaction in PETITE enables explicit separation of generation and critique, which not only increases stability in refinement but also mitigates degenerate consensus phenomena often observed in symmetric debate-based systems. The use of internal, model-based acceptance criteria enables adaptive computation, focusing resources on more challenging tasks without incurring wasteful refinement on simpler instances.
Practically, PETITE enables state-of-the-art performance on code generation under tight computational constraints—a critical consideration for deployment of LLM applications in resource-constrained environments or at scale.
Theoretically, the findings substantiate the hypothesis that human-inspired role separation yields computational and qualitative gains in agent-based LLM systems, aligning with developmental psychology on the efficacy of structured social-cognitive approaches to problem solving.
Limitations and Future Directions
The principal limitation lies in the dependency on the tutor agent’s judgment; erroneous early acceptance can reduce final accuracy. Current implementation uses homogenous agents, missing potential gains from model heterogeneity. Evaluation is limited to a subset of coding benchmarks, warranting extension to broader domains. The integration of confidence calibration for tutor decisions and more sophisticated feedback generation remains a promising direction. Exploring direct preference optimization and dynamic agent-role adaptation conditioned on problem difficulty could further enhance both accuracy and efficiency.
Conclusion
PETITE establishes that asymmetric, serial multi-agent interaction grounded in peer tutoring principles enables LLMs to achieve higher coding accuracy with substantially reduced computational cost compared to leading baselines. The framework leverages structured, iterative feedback and adaptive early stopping, transferring core principles from human cognitive development into scalable, efficient LLM system design. These insights open a path for further research integrating cognitive and developmental science into the architecture of future generative AI systems, particularly for settings prioritizing both performance and efficiency.