- The paper shows that pre-distillation baselines often outperform post-distillation outputs, questioning the assumed benefits of CoT distillation.
- It finds that teacher data quantity and performance, rather than a strict capacity gap, are decisive factors in enhancing student model outcomes.
- Practical protocol revisions—such as eliminating cross-teacher filtering and selecting tasks with clear performance gaps—improve real-world distillation efficacy.
Revisiting the Capacity Gap in Chain-of-Thought Distillation: An Expert Analysis
Introduction and Motivation
The increasing use of chain-of-thought (CoT) prompting in LLMs has amplified the need for efficient models that can perform strong multi-step reasoning. Chain-of-thought distillation aims to transfer the reasoning capabilities of powerful LLMs (teachers) into smaller, more deployable models (students). However, empirical evidence has indicated a "capacity gap"—a phenomenon where knowledge distillation is less effective, or even detrimental, when there is a significant capability mismatch between the teacher and student model. The paper "Revisiting the Capacity Gap in Chain-of-Thought Distillation from a Practical Perspective" (2604.08880) systematically examines whether the capacity gap is practically relevant in real-world deployment scenarios and identifies methodological pitfalls in prior research that may obscure its genuine impact.
Methodological Critique of Prior Protocols
The authors dissect standard CoT distillation experiment protocols and expose three major pitfalls that undermine the practical relevance of earlier findings:
- Lack of Pre-Distillation Baseline Comparison: Previous work often evaluates only post-distillation performance, neglecting whether distillation yields any improvement over the student's intrinsic, pre-distillation ability. The authors demonstrate that, surprisingly, CoT distillation frequently degrades performance relative to these baselines—contradicting the implicit assumption that distillation is universally beneficial.
- Cross-Teacher Data Filtering: Standard protocols filter data to the intersection of samples both teachers answer correctly, ostensibly to control for data quality. The authors argue and corroborate via ablation that this filtering eliminates critical advantages of stronger teachers (such as more available training examples and cases where they outperform weaker teachers), thus distorting comparative results and reducing practical relevance.
- Inclusion of Larger Student Settings: Some protocols test settings where students exceed their teachers in size, which is impractical for distillation motivated by efficiency concerns.
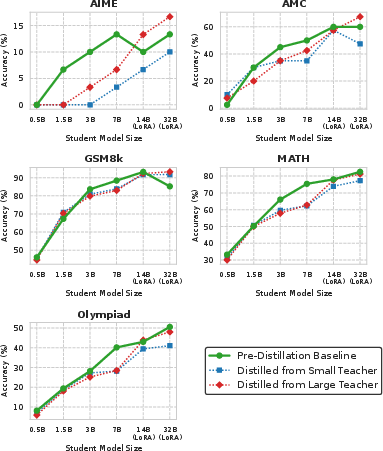
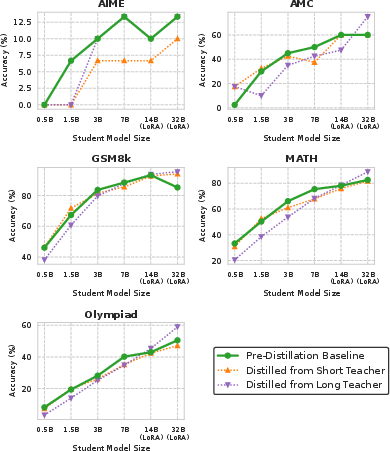
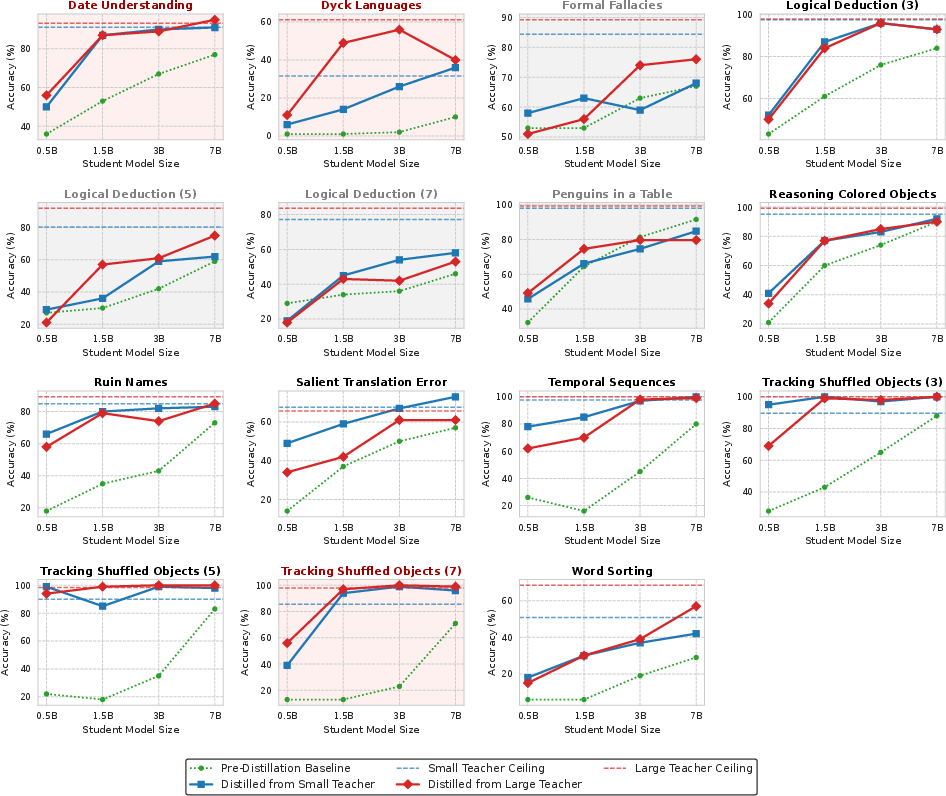
Figure 1: Results under the small--large setting, highlighting that distillation often degrades student performance compared to pre-distillation baselines.
Practical Evaluation Protocol
To address these issues, the paper proposes a revised evaluation protocol with the following key modifications:
Core Empirical Findings
Data presented under traditional protocols (see Figure 1) reveal that most student models actually perform worse after CoT distillation than before, particularly on mathematical reasoning benchmarks, calling into question the universal applicability of CoT distillation in its current form.
Teacher Strength Outweighs Capacity Gap in Many Regimes
Under the revised practical evaluation, CoT distillation is often effective, particularly on carefully selected BBH tasks. Notably:
Data Quantity vs. Reasoning Quality
An ablation in the appendix confirms that stronger teachers’ advantage is attributable largely to their provision of more training examples. When data sizes are artificially equalized (via cross-teacher filtering), the gap in downstream student accuracy shrinks dramatically, highlighting the primacy of available data over pure reasoning trace quality in practical hard distillation.
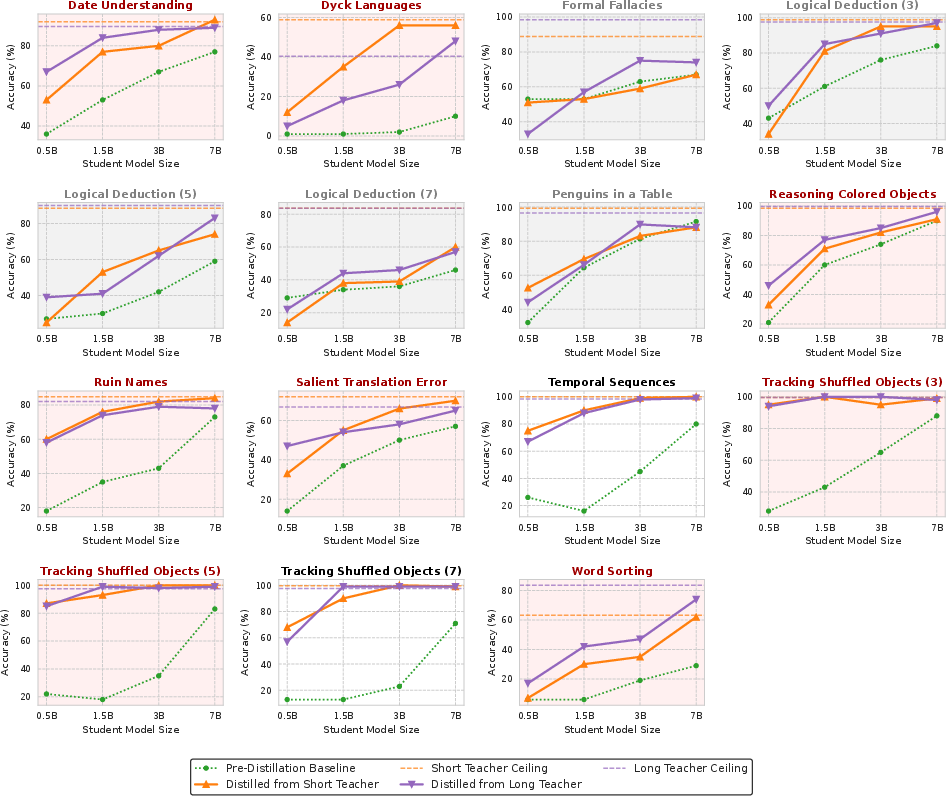
Cross-Family Generalization
Experiments with Gemma-2 teacher models and Qwen2.5 students reveal similar trends: the capacity gap does not consistently dominate, and stronger teachers that offer more correct demonstrations maintain their advantage across model families.
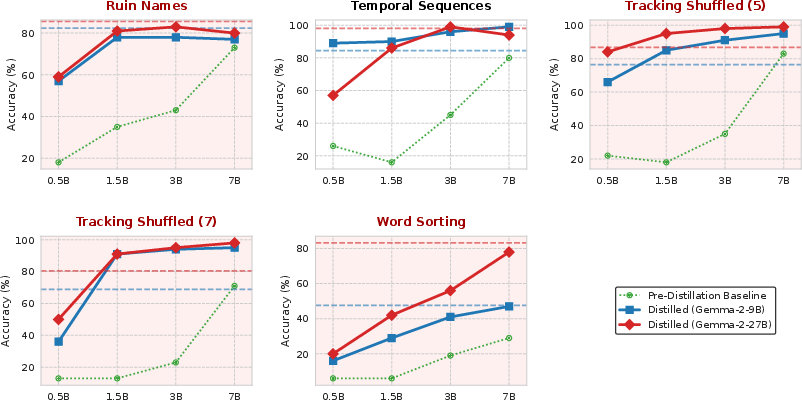
Figure 4: Results on selected BBH tasks with Gemma-2 teachers and Qwen2.5 students, confirming limited impact of the capacity gap across families.
Discussion and Guidelines for Practitioners
The empirical results support two actionable practitioner guidelines:
- Always verify distillation improves over pre-distillation baseline. Strong pretraining of modern LLMs means that naive distillation may erase valuable knowledge. Tasks must be selected where teachers are demonstrably stronger than students via few-shot probing.
- When teacher performance differs substantially, select the higher-performing teacher. The benefit derives not just from better reasoning traces but also from increased data supply—an advantage that is often more substantial than any loss due to capacity mismatch.
Implications and Future Directions
From a practical standpoint, these results refute the dogma that capacity gap is the primary barrier in CoT reasoning distillation. Instead, the quantity of correctly answered, demonstrative data dominates student performance outcomes. This motivates a future research agenda focused on:
- Task-aware selection criteria for distillation, using pre-distillation ICL performance as an efficient proxy.
- Advanced data selection and augmentation strategies to amplify the utility of high-performing teachers, instead of suppressing their benefit via cross-teacher filtering.
- Methodologies directly targeting the catastrophic forgetting problem that modern instruction-tuned students experience during distillation.
Furthermore, this study highlights the need to question broadly adopted evaluation protocols and revisit empirical phenomena under realistic deployment constraints.
Conclusion
The study presents a systematic re-examination of the capacity gap in CoT distillation with an emphasis on practical relevance (2604.08880). The analysis demonstrates that many of the previously reported negative effects of the capacity gap are predicated on evaluation artifacts rather than fundamental limitations. The key takeaways are that practitioners should prioritize verifying improvement over baseline and favor the strongest teacher available, provided a meaningful performance gap exists. This work underscores the necessity for methodologically sound evaluation criteria and signals a shift towards data-centric, task-aligned distillation strategies in the evolution of clinically deployable reasoning models.