- The paper presents a novel multi-teacher framework that combines teacher-specific supervised fine-tuning with weight-space merging to distill coherent reasoning into a unified student model.
- The paper applies its method on Qwen3-14B using just 200 high-quality chain-of-thought samples, achieving significant improvements over existing models on math benchmarks.
- The paper demonstrates that the framework mitigates catastrophic forgetting and enhances robustness, paving the way for scalable reasoning in large language models.
Merge-of-Thought Distillation
The paper presents a novel framework, Merge-of-Thought Distillation (MoT), designed to enhance the efficacy of long chain-of-thought (CoT) reasoning in LLMs. The framework addresses the increasing complexity and noise associated with long CoT reasoning by leveraging multiple teacher models rather than relying on a single oracle teacher. MoT combines teacher-specific supervised fine-tuning (SFT) with weight-space merging, providing a systematic approach to distill diverse reasoning styles into a unified student model. This essay will explore the methodology, experimental setup, findings, and implications of MoT.
Methodology
MoT is structured around an iterative process alternating between teacher-specific SFT and weight-space merging. Initially, multiple candidate teacher models generate teacher-specific distillation datasets based on a seed problem. The MoT algorithm then proceeds through iterative rounds, each consisting of three key steps:
- Branch Training: Each teacher's reasoning ability is internalized into separate branches through SFT. This stage aligns the student model with each teacher's unique reasoning trajectory.
- Weight-Space Merging: The parameters of these separate branches are averaged to consolidate shared reasoning features while diminishing teacher-specific idiosyncrasies.
- Next-Round Initialization: The merged model serves as the base for subsequent iterations, gradually evolving into a student that reflects multi-teacher consensus reasoning.
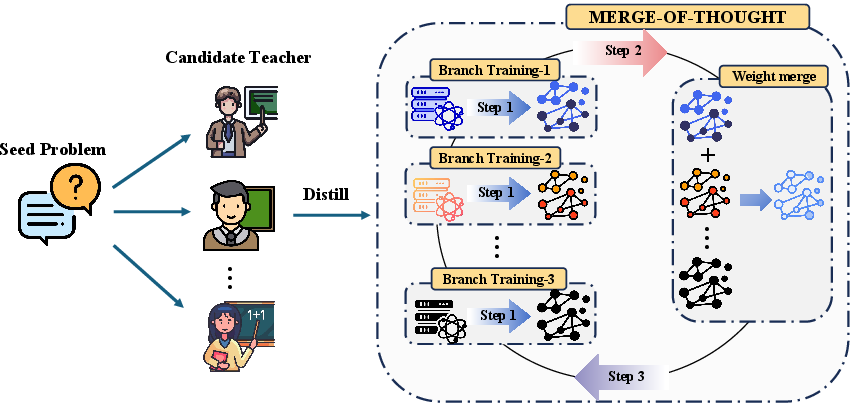
Figure 1: Workflow of Merge-of-Thought Distillation (MoT).
This process aims to unify different teachers' reasoning styles, overcoming conflicts and enhancing the model's reasoning capabilities without amplifying noise, a common issue with long CoT processes.
Experimental Setup
The methodology was applied to QWEN3-14B as the student model, using a dataset of only 200 high-quality CoT samples. The MoT framework was then benchmarked against models like DEEPSEEK-R1, QWEN3 variants, and OPENAI systems on competition math benchmarks.
Datasets and Training
- Datasets: The experiments utilized BOBA-200 and S1K-200, derived from high-quality, open-source mathematical problems.
- Base Models: QWEN3-8B, QWEN3-14B, and QWEN3-30B-A3B served as the base models for various experiments.
- Training Configuration: Fine-tuning involved a batch size of 64, with an initial learning rate of 1e-5. The training process alternated among teacher-distilled corpora for 50 steps before merging, repeated for five rounds.
Findings
MoT demonstrated substantial improvements over traditional single-teacher and naive multi-teacher distillation approaches. Specifically, MoT applied to Qwen3-14B surpassed DEEPSEEK-R1, QWEN3-30B, and OPENAI-O1, achieving higher performance ceilings while mitigating overfitting.
- Numerical Results: MoT consistently outperformed other models across AIME-sourced benchmarks (AIME24 and AIME25), with substantial numerical gains displayed in terms of average improvements against competing methods.
Robustness to Teacher Variability
The research confirmed that no single teacher emerges as universally best across all students or datasets—a critical assumption MoT capitalizes on. The framework thus effectively integrates diverse reasoning abilities while maintaining robustness to distribution-shifted and peer-level teachers.
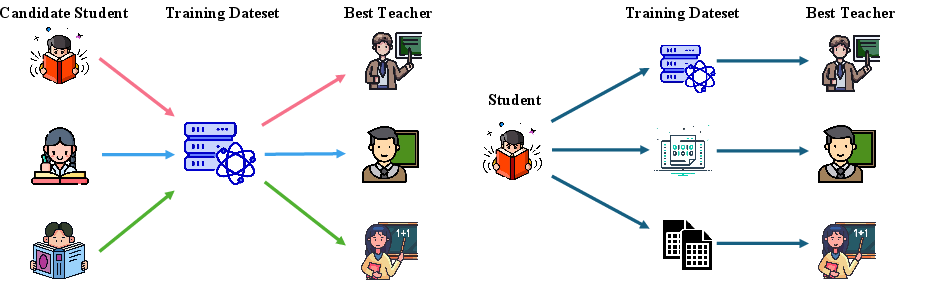
Figure 2: Teacher choice is not universal.
Mitigation of Catastrophic Forgetting
MoT also proved advantageous in reducing catastrophic forgetting and enhancing general reasoning, suggesting the broader transferability of consensus-filtered reasoning features.
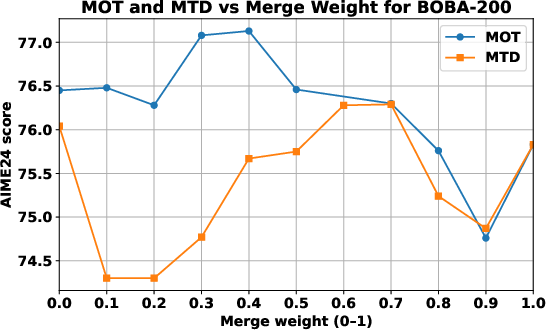
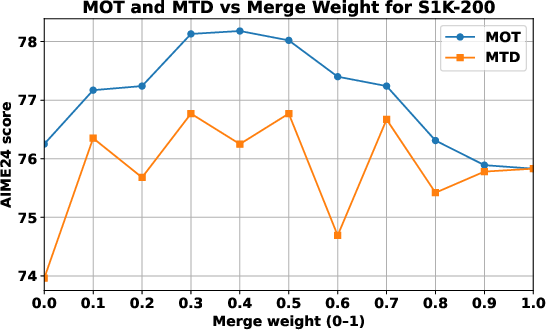
Figure 3: Reverse-merge probe highlights smoother trajectories under MOT, indicating a flatter loss region.
Conclusion
MoT represents a versatile and scalable approach to distilling long CoT capabilities into compact students while sidestepping the limitations of single-teacher distillation. By unifying diverse teacher signals into a coherent consensus reasoning structure, MoT not only elevates the performance of the student model but also enhances its general reasoning abilities, making it a promising framework for future LLM developments in complex reasoning tasks. Future work could explore alternative merging strategies and further validate the framework's effectiveness across more diverse datasets and domains.