- The paper introduces the Alignment Instability Condition (AIC), showing that fine-tuning leads to safety degradation via curvature-induced drift into alignment-sensitive subspaces.
- Empirical analyses reveal that overlap between fine-tuning updates and low-rank FIM eigenvectors correlates strongly with increased harmfulness scores across diverse datasets.
- The study provides actionable insights, recommending curvature-aware fine-tuning and continuous monitoring of projection dynamics to mitigate alignment collapse risks.
Alignment Collapse Geometry in Fine-Tuned LLMs
Overview and Motivation
The paper "The Geometry of Alignment Collapse: When Fine-Tuning Breaks Safety" (2602.15799) systematically investigates the geometric underpinnings of safety degradation in LLMs following task-specific fine-tuning. While prevailing intuition presumes that benign task adaptation should not undermine unrelated alignment guardrails, empirical evidence consistently exposes catastrophic safety failures—even when fine-tuning datasets are non-adversarial. The authors resolve the paradox by demonstrating that, in high-dimensional parameter spaces, orthogonality between update directions and alignment-sensitive subspaces is unstable under gradient descent dynamics. Specifically, second-order curvature of the fine-tuning loss landscape enforces drift into alignment-critical directions, rendering safety collapse inevitable.
The central theoretical contribution is the Alignment Instability Condition (AIC), which encapsulates three geometric properties:
- Low-Rank Sensitivity: Alignment for a given skill is concentrated in a small, high-curvature subspace, defined by the leading eigenvectors of the skill-specific Fisher Information Matrix (FIM).
- Initial Orthogonality: Fine-tuning gradients for unrelated tasks possess negligible first-order projection onto the alignment-sensitive subspace, seemingly ensuring safety.
- Curvature Coupling: The second-order terms in the fine-tuning trajectory—quantified by the directional derivative of the gradient—introduce nontrivial acceleration into the sensitive subspace, instigating alignment drift regardless of initial orthogonality.
Under the AIC, the authors rigorously prove that fine-tuning induces quadratic growth of projection into the alignment-sensitive subspace, which in turn yields a quartic scaling law for alignment degradation: skill utility loss Δui scales as Ω(λγ2t4) in early training, where λ is the curvature (eigenvalue), and γ quantifies coupling.
Empirical Validation: Low-Rank Structure and Overlap Dynamics
To validate the theoretical premises, the paper presents an extensive empirical analysis of the FIM and fine-tuning trajectories in weight space. The FIM, computed block-wise for transformer modules, exhibits sharply decaying eigenvalue spectra, confirming that alignment-sensitive structure is inherently low-rank.
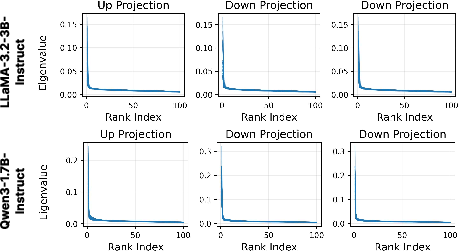
Figure 1: Top eigenvalues of FIM approximated over 100 random samples from BeaverTail's safe subset; low-rank structure is consistent across multiple layers.
Next, the authors introduce the Overlap Score (OS), a metric capturing the geometric projection of fine-tuning-induced weight changes onto the alignment-sensitive subspace. OS quantifies the risk of safety degradation from task adaptation by measuring the coupling between update trajectories and the skill-specific FIM.
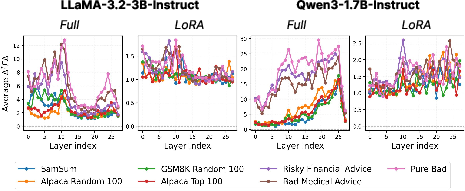
Figure 2: Average Overlap Score per Transformer Block for seven fine-tuning datasets; datasets with high overlap induce substantial alignment degradation.
Granular per-module analysis further reveals that certain components (e.g., query and key matrices) exhibit greater entanglement with alignment-sensitive directions.
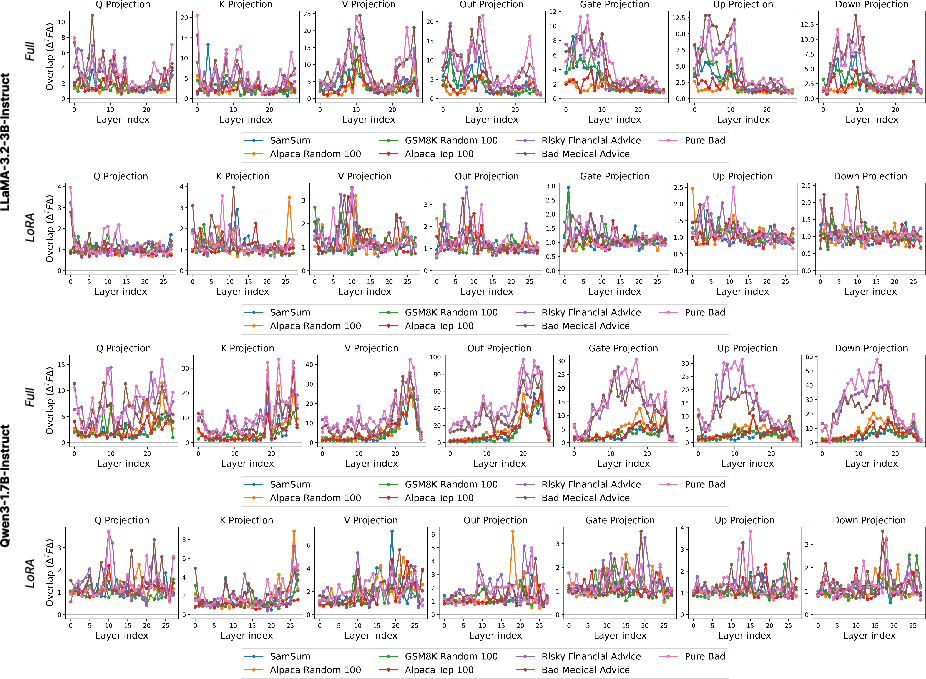
Figure 3: Per-module Overlap Score per Transformer Block for seven fine-tuning datasets, highlighting module-specific entanglement.
Numerical and Experimental Results
The experimental setup evaluates both LoRA and full fine-tuning on Qwen3-1.7B and LLaMA-3.2-3B using diverse datasets: strictly benign, seemingly benign (adversarially selected but semantically safe), and explicitly harmful. Evaluation via Gemini-2.5-Flash on AdvBench queries demonstrates the following:
- All fine-tuning increases harmfulness scores relative to the base model.
- Seemingly benign datasets (e.g., Alpaca Top 100, Risky Financial Advice) exhibit harmfulness scores comparable to explicitly harmful datasets.
- The magnitude of safety degradation correlates strongly with geometric overlap (OS) in full fine-tuning; this correlation is less consistent for LoRA, presumably due to shifts induced by low-rank adaptation structure ("intruder dimensions").
Theoretical Implications and Failure Modes of Existing Defenses
The quartic scaling law derived from the AIC provides a principled explanation for empirically observed rapid and thresholded safety collapse. First-order defenses (e.g., null-space projection, gradient constraints) are insufficient because they ignore the non-Euclidean, dynamic curvature of parameter space. Even small curvature coupling accelerates drift into alignment-sensitive directions, invalidating static geometric intuitions.
A critical insight is that alignment fragility is not a product of adversarial intent or dataset overlap but an intrinsic geometric property of high-dimensional optimization. The failure of traditional meta-learning guarantees, shared representation bounds, and null-space methods stems from their neglect of curvature-induced rotational dynamics.
Practical Recommendations and Prospective Risk Assessment
The geometric framework established herein enables proactive diagnostic tools:
Conclusion
This paper establishes that alignment collapse is an inevitable consequence of the geometric interaction between task fine-tuning trajectories and high-curvature, low-dimensional alignment-sensitive regions of the parameter space. The AIC rigorously characterizes the mechanisms, demonstrating rapid (t4) scaling of safety degradation even for benign tasks. Future strategies for robust alignment preservation must eschew static first-order intuitions and adopt curvature-aware geometric controls. The implications are substantial for open-weight model deployment and foundational safety frameworks, necessitating a shift from engineering solutions to intrinsic geometric solutions within high-dimensional neural network optimization.

