- The paper demonstrates that decomposing reward variance clarifies the role of intrinsic noise versus true quality differences in prompt optimization.
- It introduces the p1 method, which filters a small, high-variance subset of user prompts to enhance performance in complex reasoning tasks.
- Empirical results reveal that fewer, well-chosen prompts improve cross-task generalization, while full-data optimization benefits homogeneous tasks like instruction following.
p1: Better Prompt Optimization with Fewer Prompts — An Expert Analysis
Prompt optimization serves as a compelling mechanism for controlling frozen LLMs by engineering the system prompt to maximize downstream performance without parameter updates. Its allure is especially pronounced in settings where model finetuning is infeasible due to resource constraints or risk of catastrophic forgetting. However, when prompt optimization is operationalized via evolutionary strategies or RL-based combinatorial search, practitioners observe notable discrepancies in utility across distinct tasks. Specifically, some tasks—e.g., standard instruction following—appear highly susceptible to prompt optimization, while others—such as competition-level mathematics—remain largely impervious. The paper "p1: Better Prompt Optimization with Fewer Prompts" (2604.08801) undertakes a rigorous decomposition of the variance structure underlying the prompt optimization signal, ultimately characterizing and addressing the phenomenon of prompt optimization brittleness.
Variance Decomposition of Prompt Optimization — Theoretical Insights
The core contribution is an analytic decomposition of the reward variance associated with different candidate system prompts. The paper proves that reward variance can be split into:
- Variance among responses: Intrinsic stochasticity of the LM during generation, regardless of the system prompt. This component reflects the inherent randomness in response sampling (e.g., temperature, sampling strategies).
- Variance among system prompts: Reflects "true" quality differentials between system prompt candidates—the dimension along which RL/optimization can make progress.
The efficacy of any RL-driven or evolutionary prompt search is tightly linked to the ratio of these two variance components. When the variance among system prompts is high relative to response variance, the optimization surface is well-conditioned—good prompts are distinguishable from weak ones. Conversely, if the variance among responses swamps inter-prompt variance, the learning signal becomes excessively noisy or even uninformative.
The empirical evidence supports this: On IFBench (instruction following), variance among system prompts is dominant, while on AIME (mathematical reasoning), it is comparatively suppressed and dominated by generation stochasticity.
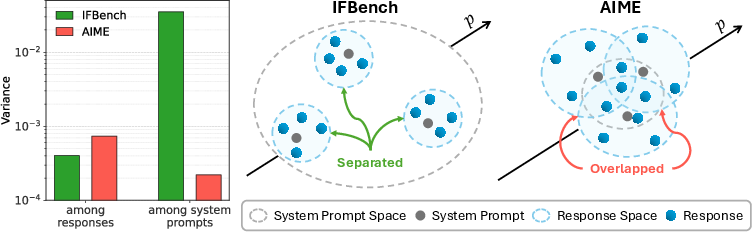
Figure 1: Variance structure for IFBench and AIME. For IFBench, prompt quality is readily distinguishable; for AIME, generation noise obscures meaningful differences between prompts.
Dataset Size and the Paradox of Signal Dilution
A particularly counterintuitive finding is that increasing the number of user prompts over which the system prompt is optimized typically suppresses variance among system prompts—this effect is magnified for heterogeneous datasets where user prompts favor different optimal system prompts. The analytical explanation follows: averaging rewards across many user prompts (especially in tasks with high prompt heterogeneity) washes out preference signals, rendering distinct system prompts nearly indistinguishable in expectation. As a dataset grows, the optimization problem becomes ill-posed, even though the raw informational content would naively be assumed to increase.
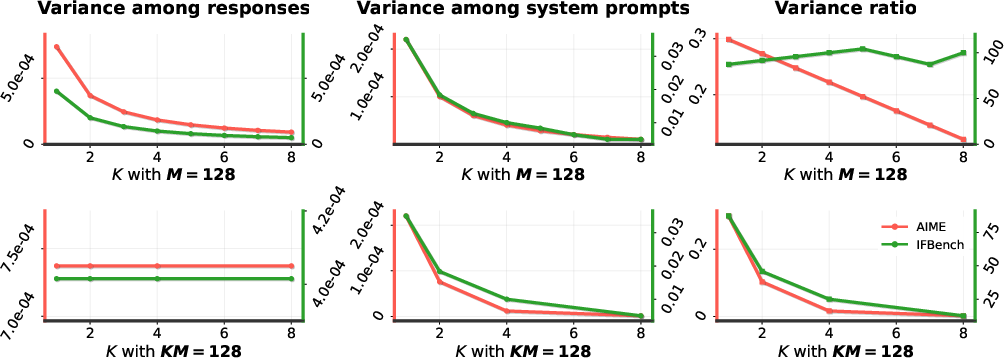
Figure 2: Response and system prompt variance as a function of user prompt count K and sample budget M. Increasing K reduces system prompt variance, making the reward signal noisier on heterogeneous tasks.
This finding is robustly validated across parameter sweeps of K and M: On AIME, scaling K monotonically reduces the "signal-to-noise" ratio for prompt optimization.
Motivated by the above variance analysis, the authors introduce p1: a straightforward yet effective prompt filtering strategy. Rather than optimizing the system prompt across the full (potentially very heterogeneous) user prompt dataset, p10 selects a small subset of user prompts with maximal variance among candidate system prompts—a proxy for informativeness. The filtered prompts should, by construction, accentuate inter-prompt quality differences and magnify learnability for RL or search-based optimization.
Operationally, for each user prompt, the variance of reward across system prompt candidates is estimated (with large p11 to control for response stochasticity). The p12 prompts with the highest such variance constitute the optimization subset.
Theoretical analysis suggests that this procedure ensures that RL is operating in a high-signal regime and empirical results confirm that, especially for complex reasoning domains, this dramatically improves final system prompt quality.
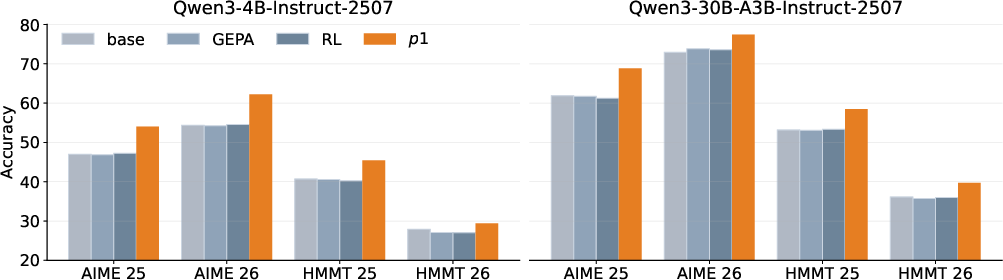
Figure 3: Comparison of p13 with the baseline and competing methods. p14 achieves substantial performance improvements, despite utilizing only a fraction of the available user prompts for training.
Experimental Evaluation
Reasoning Benchmarks
The main experiments utilize Qwen3-4B-Instruct-2507 as both the system prompt generator and reward source, benchmarking against AIME (math), HMMT, and IFBench (instruction following). p15 is compared to GEPA (an evolutionary search baseline) and conventional RL on the full dataset.
Key findings:
- On AIME and HMMT, p16 consistently outperforms full-data RL and GEPA, achieving the highest accuracies while requiring far fewer training prompts. For example, using just two selected AIME 24 prompts (p17), p18 yields a system prompt that generalizes robustly to AIME 25, AIME 26, and HMMT.
- When p19, overfitting is observed, but as few as two prompts suffice for generalization.
- The system prompts learned by K0 show strong cross-model and cross-task transfer: prompts optimized for Qwen3-4B-Instruct-2507 transfer successfully to Qwen3-30B-A3B-Instruct-2507 and to unseen benchmarks.
Instruction Following
On IFBench, the effect reverses: Both RL and GEPA on the full prompt set outperform K1. This matches theory: IFBench is nearly homogeneous; increasing K2 does not attenuate the system prompt variance signal, and training on all data maximizes generalization.
Qualitative Analysis
Qualitative inspection of the learned system prompts reveals that K3 yields general, reasoning-oriented prompts (emphasizing process and thinking structure), while GEPA tends to fit narrow, domain-specific, or even pattern-memorizing prompts. This is consistent with the superior generalization exhibited by K4-optimized prompts.
Practical and Theoretical Implications
From a practical standpoint, K5 enables efficient prompt optimization even for highly diverse or difficult tasks, eliminating the need for scaling sample budgets commensurately with dataset size. Theoretically, the paper clarifies when and why prompt optimization is likely to succeed and exposes a fundamental limitation of naïve reward averaging in RL-style prompt search.
Future directions include:
- Extending the analysis to dense and/or continuous reward environments (beyond the binary reward setting analyzed here).
- Developing adaptive strategies for prompt subset selection that better trade off generalization and overfitting, particularly as model and task distributions shift.
- Investigating uncertainty estimation and robust variance estimators to further improve high-variance prompt selection.
Conclusion
This work provides a precise characterization of the variance landscape underpinning prompt optimization. It demonstrates that indiscriminate scaling of prompt datasets can degrade signal-to-noise ratio and hinder RL-based optimization. The K6 method mitigates these challenges by filtering to a maximally informative prompt subset, achieving strong empirical gains (notably in mathematical reasoning) while requiring far less data. The analysis and methodologies herein are likely to inform the design of future prompt-based adaptation, efficient post-training strategies, and RLHF-like methods for instruction or reasoning tasks in LLMs.