- The paper introduces BrainCoDec which reinterprets neural decoding as a meta-learning problem to enable training-free cross-subject generalization.
- It employs a two-stage hierarchical in-context framework combining per-voxel encoder inference with a transformer-based decoder for robust visual retrieval from fMRI.
- Empirical evaluations demonstrate significant performance gains over state-of-the-art models, achieving high Top-1/Top-5 accuracies with minimal context data.
Meta-Learning In-Context for Training-Free Cross-Subject Brain Decoding: BrainCoDec
Introduction and Problem Motivation
The paper "Meta-learning In-Context Enables Training-Free Cross Subject Brain Decoding" (2604.08537) addresses a persistent obstacle in computational neuroscience and brain-computer interfaces: the lack of generalizability in brain decoding models, specifically semantic visual decoding from fMRI, across individuals. Current state-of-the-art models depend on subject-specific training or fine-tuning due to profound inter-subject variability in neural responses. This severely limits both theoretical neuroscience research and practical BCI deployment. The authors reinterpret neural decoding as a meta-learning problem, proposing a hierarchical in-context framework that achieves robust cross-subject generalization without gradient-based fine-tuning, anatomical alignment, or stimulus overlap.
Model Architecture and Hierarchical In-Context Learning
The core of the proposed approach, BrainCoDec, is a two-stage hierarchical model that leverages in-context meta-learning to rapidly infer subject-specific neural encoding patterns and perform robust decoding.
In the first stage, for each voxel of interest, an encoder is meta-trained to infer the visual response function parameters from a context set of image-activation pairs. This process is repeated per-voxel, capturing individual encoding properties efficiently.
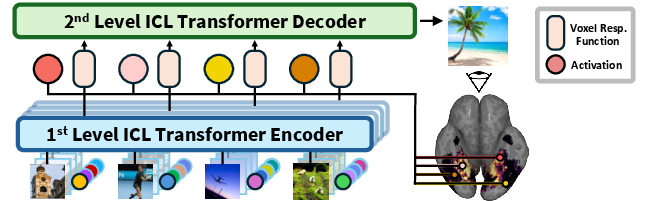
Figure 1: Model architecture of BrainCoDec, illustrating voxelwise in-context encoder parameter inference, followed by aggregated inversion across voxels with variable context sizes.
In the second stage, the parameters inferred for each voxel (along with test image activations) are aggregated and processed by a transformer-based decoder. This step performs functional inversion by integrating voxel contexts, allowing the model to flexibly adapt to novel subject anatomy and varying voxel counts without explicit alignment.
A notable architectural detail is the use of logit scaling for variable-length context adaptation and the omission of positional embeddings, ensuring permutation invariance over voxels.
Methodology
The training pipeline is meta-optimized to solve the functional inverse mapping from brain activity to visual representations. The approach follows an analysis-by-synthesis protocol during pretraining (using synthetic voxels/weights/activations with noise), followed by contextual extension with variable-length inputs, and supervised fine-tuning with real fMRI data. The objective combines cosine-similarity loss and InfoNCE for discriminative alignment in the embedding space.
Hierarchical in-context adaptation enables the model to generalize to subject-unseen data using a small context set (~200 image-activation pairs), without any subject-specific gradient updates. Decoding is evaluated by retrieving image embeddings (CLIP, DINO, SigLIP) from neural activity, reflecting both semantic and perceptual fidelity.
Empirical Evaluation and Analysis
The experiments utilize the Natural Scenes Dataset (NSD), which offers high-quality 7T fMRI data across multiple subjects, and BOLD5000, a 3T dataset with divergent acquisition parameters. BrainCoDec is compared against MindEye2 and TGBD, the current state-of-the-art for subject-generalized brain decoding.
Strong empirical results are achieved:
- On NSD, BrainCoDec-200 (using only 200 in-context pairs) obtains average Top-1/Top-5 retrieval accuracies of 22.7%/54.0% across held-out subjects, substantially outperforming MindEye2 (3.9%/9.8%) and TGBD (0.82%/3.09%) while requiring no subject-specific fine-tuning.
- Performance scales monotonically with additional in-context images or voxels, reaching near upper bounds with only a small fraction of available data.
- On BOLD5000, BrainCoDec achieves mean Top-1 accuracy of 31.45% (CLIP backbone) using only 20 context images, demonstrating robust cross-dataset and cross-scanner adaptation.
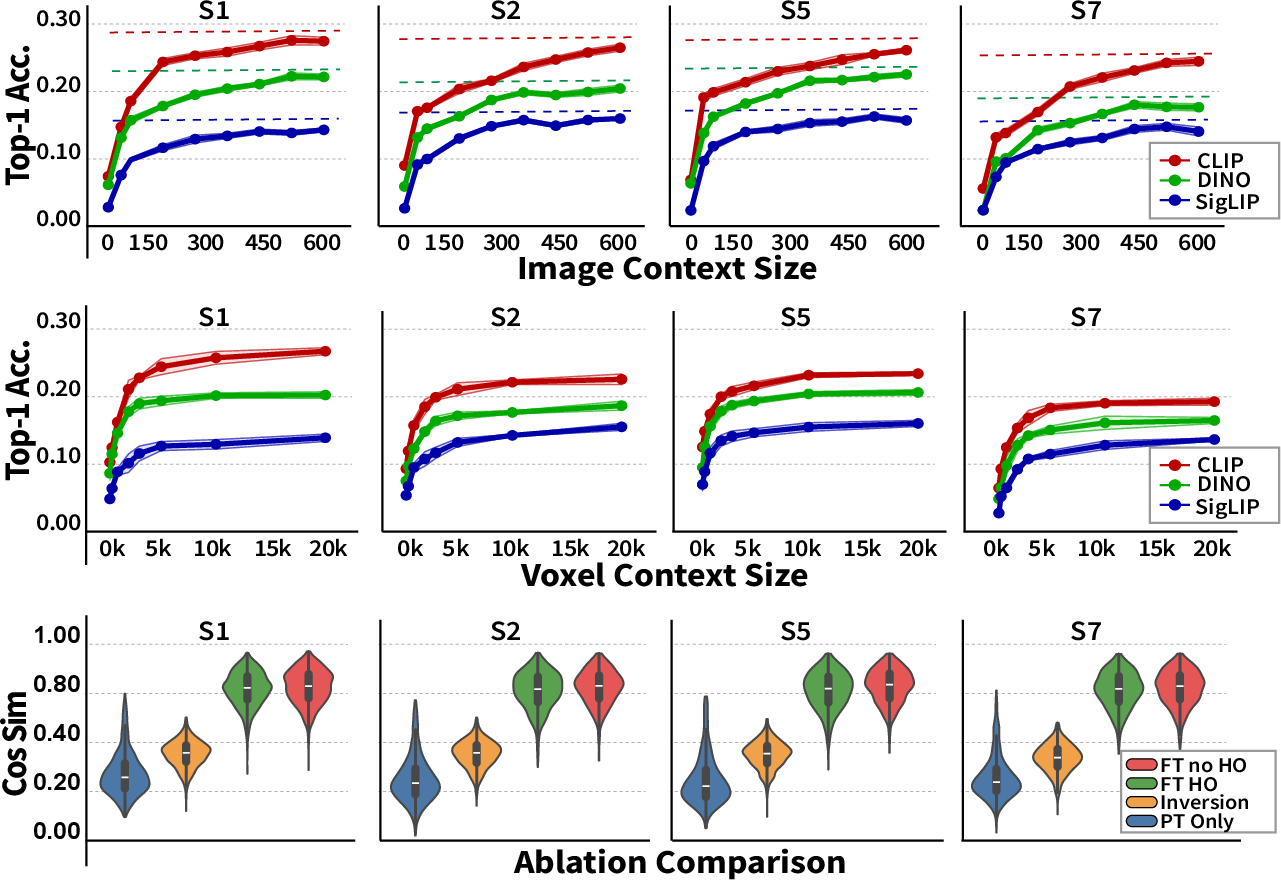
Figure 2: Contextual image and voxel scaling, and ablation analysis, showing strong positive scaling trends and superiority to synthetic/inversion-only models; fine-tuning provides marginal gains.

Figure 3: Image retrieval for an unseen subject (S1): BrainCoDec-200 delivers high semantic retrieval consistency, without subject-specific adaptation.
Robustness analyses reveal minimal performance degradation under ROI dropout, except for moderate decreases when scene-selective regions are masked, indicating the model does not depend on any single category-selective area for accurate decoding.
Attention analysis uncovers interpretable, category-selective spatial attention patterns in the final layer, paralleling known neuroanatomical correspondences (e.g., FFA for faces, PPA/OPA/RSC for places). UMAP projections of attention distributions further support emergent semantic clustering across the visual cortex.
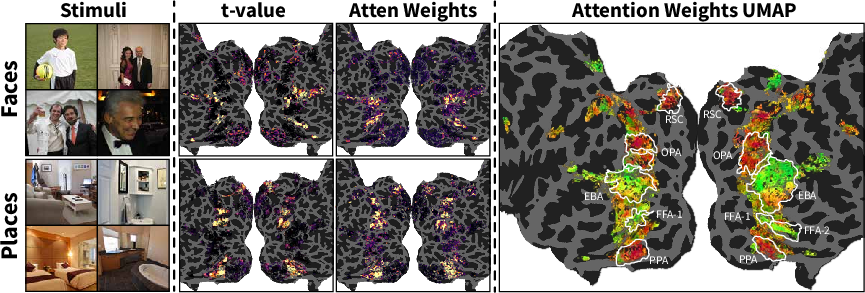
Figure 4: Semantic attention visualization in BrainCoDec, revealing close correspondence between learned attention maps and functionally localized visual regions.
Practical and Theoretical Implications
BrainCoDec constitutes a decisive shift in fMRI-based neural decoding methodology. It renders feasible the deployment of universal, training-free decoders for novel individuals, subject pools, or scanners—overcoming the population variability that previously necessitated per-subject retraining or anatomical registration.
Practically, this advances non-invasive BCIs toward real-world applicability (including clinical and consumer-grade systems) by removing subject-specific training barriers and data requirements. For cognitive assessment and diagnostics, it enables the comparison of neural encoding and representational geometries at scale across populations, scanners, and protocols.
Theoretically, the generalization capabilities of hierarchical in-context meta-learners provide a new model for understanding adaptive coding and neural representation in cortex, paralleling mechanisms seen in transformer-based in-context learning. The mapping from fMRI to high-dimensional vision embeddings, robust to source variability, underscores the potential for population-level foundation models for neural decoding.
Limitations and Directions for Future Work
While BrainCoDec constitutes a marked advancement, its strengths are currently demonstrated primarily on high-quality fMRI datasets with visual stimuli and neural features extracted using vision transformer backbones. Extending the framework beyond visual cortex and fMRI—to modalities such as EEG, MEG, and behavioral or linguistic domains—is an open direction. Additionally, handling explicit confounds of data quality, pathophysiological variability, or low signal-to-noise scenarios may necessitate further methodological innovation, possibly integrating multimodal or causal modeling.
Another direction is integrating BrainCoDec with conditional image generation pipelines for direct reconstruction, which is discussed but not the primary focus of the current work. Advancing from embedding retrieval to high-fidelity generative reconstructions could further bridge the neuroscience–AI interface.
Conclusion
Meta-learning-based in-context adaptation, as instantiated in BrainCoDec, enables robust, training-free cross-subject visual decoding from fMRI data. The hierarchical strategy of inferring encoder parameters per-voxel and integrating them for functional inversion drives unprecedented generalization, obviating the need for anatomical alignment or subject overlap. This framework yields strong improvements over state-of-the-art baselines and establishes a scalable, interpretable paradigm for population-level neural decoding across diverse acquisition conditions (2604.08537).
Future development spans both foundational and applied domains in AI and neuroscience, encompassing multimodal neural decoding, universal BCIs, and scalable investigation of cortical organization.