- The paper introduces a dual-adapter framework that enables efficient reconstruction of complex visual scenes from fMRI data.
- It uses AutoKL and CLIP Adapters to separately capture low-level spatial details and high-level semantic content, ensuring robust cross-subject generalization.
- The framework reduces training complexity by fine-tuning only 17% of parameters, outperforming previous models in spatial and semantic accuracy.
NeuroSwift: A Lightweight Cross-Subject Framework for fMRI Visual Reconstruction of Complex Scenes
Introduction
NeuroSwift introduces a hierarchical, dual-adapter framework for reconstructing complex visual scenes from fMRI data, addressing the persistent challenges of cross-subject generalization and computational efficiency in brain-to-image synthesis. The model leverages biologically inspired mechanisms, integrating a structural pathway (AutoKL Adapter) for low-level spatial features and a semantic pathway (CLIP Adapter) for high-level conceptual information. The CLIP Adapter is trained using synthetic semantic images generated by Stable Diffusion and paired COCO captions, emulating the abstract encoding of the human visual cortex. Cross-subject adaptation is achieved by fine-tuning only the fully connected layers (17% of parameters) for new subjects, with all other components frozen, enabling rapid transfer with minimal computational resources.
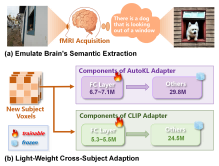
Figure 1: (a) Subjects imagine semantic content during scanning; COCO Captions and Semantic Images are used to emulate this. (b) Cross-subject adaptation is achieved by fine-tuning only 17% of parameters in one hour on 3×RTX4090 GPUs.
NeuroSwift Architecture
The NeuroSwift framework is composed of two main pipelines: structural generation and semantic reinforcement, followed by a diffusion-based reconstruction process.
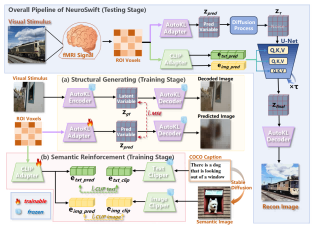
Figure 2: NeuroSwift architecture in single-subject mode. fMRI voxels are processed through structural and semantic pipelines, with outputs fused in a guided diffusion process for image reconstruction.
Structural Generation: AutoKL Adapter
The AutoKL Adapter projects fMRI voxels into the latent space of Versatile Diffusion, capturing spatial primitives and color distributions. Training minimizes MSE between predicted and ground-truth latent variables, ensuring alignment with the visual stimulus. The AutoKL Decoder, kept frozen, decodes the final latent vector into the reconstructed image, preserving low-level spatial fidelity.
Semantic Reinforcement: CLIP Adapter
The CLIP Adapter maps fMRI voxels into CLIP image and text embeddings. Semantic images, generated from COCO captions via Stable Diffusion, are used for image embedding alignment, while text embeddings are derived from the captions themselves. Training employs a combination of SoftCLIP contrastive loss and MSE regularization to maximize semantic consistency and mitigate artifacts from noisy fMRI-CLIP mappings.
Diffusion Reconstruction
The reconstruction process initializes from the structural latent variable, with noise added according to a structural strength coefficient. Semantic conditioning is imposed via cross-attention mechanisms in the UNet, integrating both text and image CLIP embeddings at each denoising step. The final latent vector is decoded into pixel space, achieving decoupling of structure and semantics.
Data and ROI Selection
Experiments utilize the NSD dataset, focusing on four subjects with complete sessions. Manually delineated ROI masks are employed instead of standardized templates, accounting for neuroanatomical variability and enhancing spatial precision. This individualized mapping is critical for accurate downstream decoding and reconstruction.
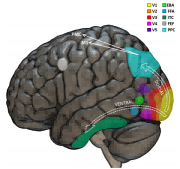
Figure 3: Main cortical regions involved in visual perception, highlighting the hierarchical organization of the visual pathway.
Experimental Results
Image Reconstruction
NeuroSwift demonstrates robust reconstruction of complex scenes, accurately recovering both spatial layout and semantic content. The hierarchical pipeline enables the model to reconstruct fine details such as small objects and cluttered backgrounds, even under cross-subject generalization with only one hour of training data.

Figure 4: NeuroSwift reconstructions from complex visual stimuli, showing high fidelity in both spatial and semantic domains.
Qualitative Comparison
NeuroSwift outperforms MindEye2 and MindTuner in cross-subject adaptation, reconstructing scenes with superior spatial and semantic accuracy. In single-subject mode, it surpasses MindBridge, achieving precise spatial recovery alongside semantic correctness.

Figure 5: NeuroSwift vs. MindEye2 and MindTuner in cross-subject adaptation with 1h training data.

Figure 6: NeuroSwift vs. MindBridge in single-subject mode with 40h training data.
Quantitative Evaluation
NeuroSwift achieves top scores in PixCorr, SSIM, CLIP, and AlexNet metrics, indicating superior performance in both low-level spatial and high-level semantic reconstruction. With 66.3M parameters, it is more efficient than MindEye2 and MindTuner, requiring only 3×RTX4090 GPUs for training.
Ablation Studies
Component ablations reveal the necessity of both structural and semantic pathways. Removing the structural prior degrades spatial fidelity, while omitting semantic guidance collapses semantic metrics. The use of individualized ROI masks further enhances spatial and texture fidelity compared to standardized templates.

Figure 7: Reconstruction examples from Subj01 with various ablations, illustrating the contributions of each model component.
Interpretability
Analysis of adapter weight distributions shows that the AutoKL Adapter predominantly activates early visual regions (V1-V3), consistent with its role in structural generation. The CLIP Adapter exhibits distributed activation across ventral, lateral, and parietal regions, reflecting its multimodal semantic integration.
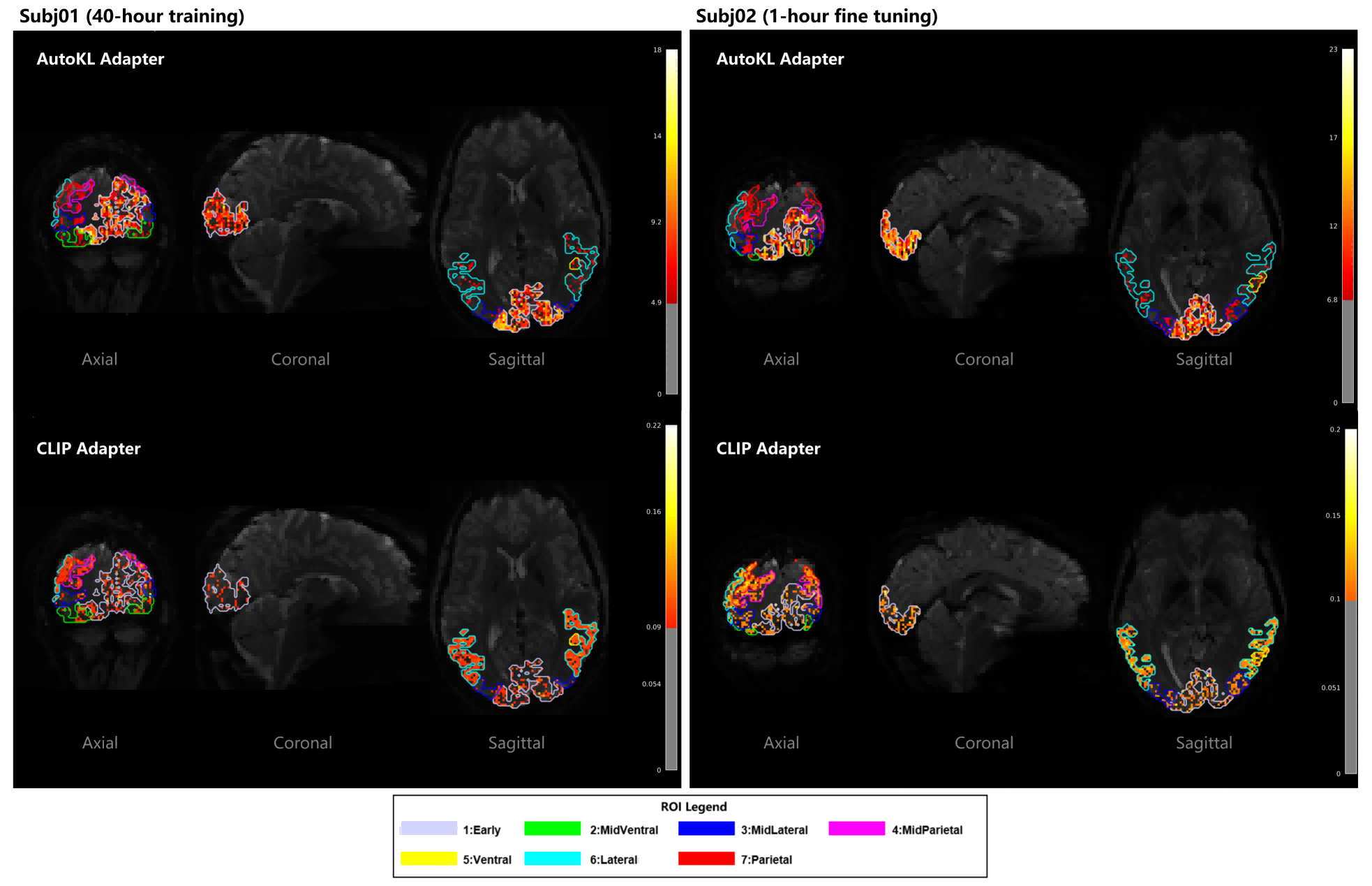
Figure 8: Spatial distribution of brain-region contributions for AutoKL and CLIP Adapters in Subj01.
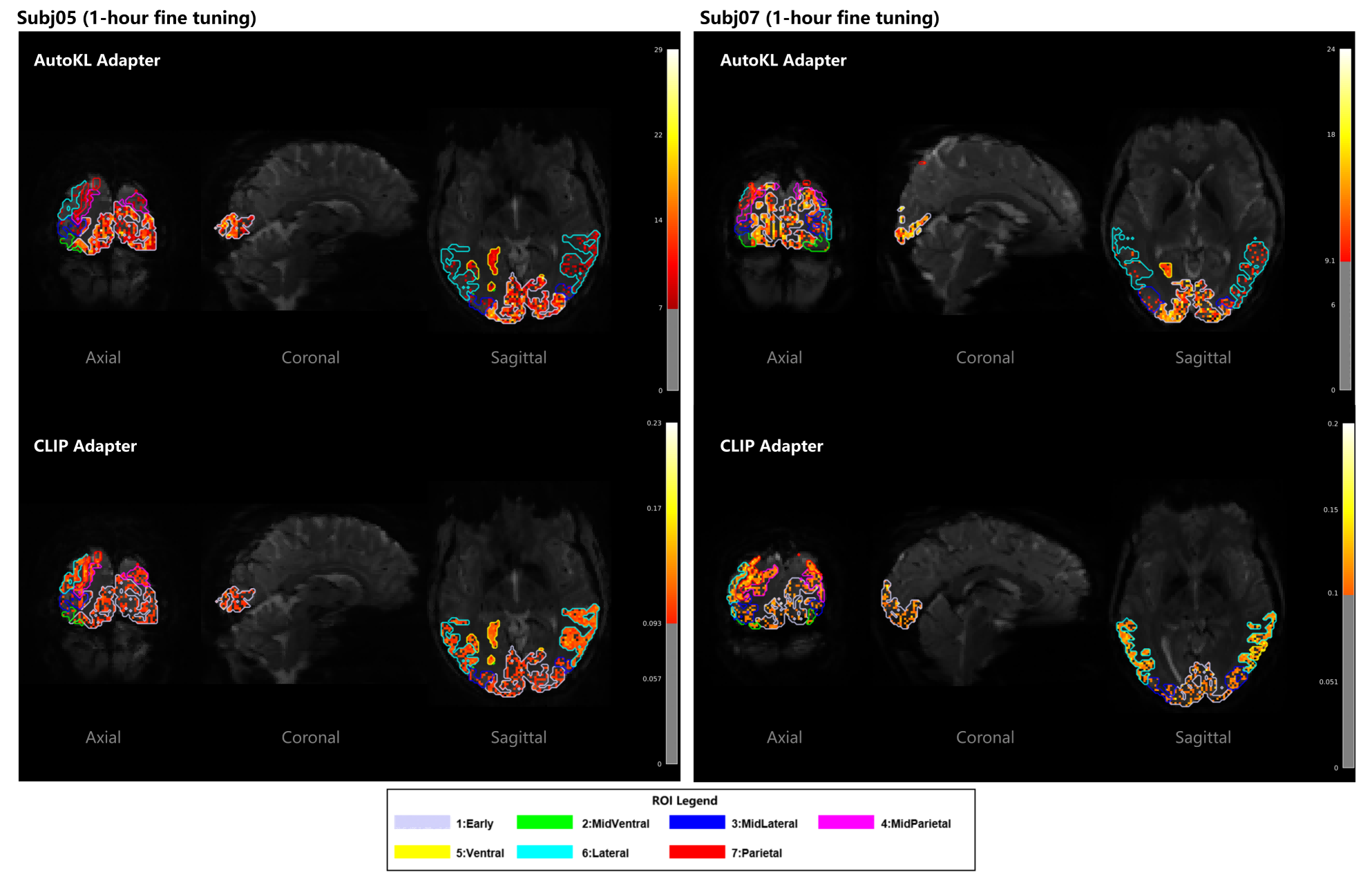
Figure 9: Spatial mapping of brain region contributions to AutoKL and CLIP Adapters on Subj05 and Subj07, confirming consistent activation patterns across subjects.
Implications and Future Directions
NeuroSwift's dual-pathway design and efficient cross-subject adaptation represent a significant advance in fMRI-based visual reconstruction. The model's ability to generalize with minimal data and computational resources has practical implications for scalable brain-computer interfaces and neuroimaging research. The use of synthetic semantic images for CLIP alignment is a notable methodological innovation, improving semantic extraction from noisy fMRI signals.
Theoretical implications include the validation of hierarchical, multimodal integration in neural decoding, supporting models of distributed visual processing in the cortex. Future work should address dataset generalizability, extending validation to datasets such as BOLD5000, and explore further optimization of adapter architectures for even greater efficiency and robustness.
Conclusion
NeuroSwift achieves state-of-the-art performance in fMRI visual reconstruction of complex scenes, combining a biologically inspired dual-adapter architecture with efficient cross-subject adaptation. Its design enables high-fidelity reconstruction with minimal computational resources, outperforming existing methods in both spatial and semantic domains. Limitations include dataset specificity, warranting future cross-dataset validation to ensure broader applicability.