Dexterity from Smart Lenses: Multi-Fingered Robot Manipulation with In-the-Wild Human Demonstrations
Abstract: Learning multi-fingered robot policies from humans performing daily tasks in natural environments has long been a grand goal in the robotics community. Achieving this would mark significant progress toward generalizable robot manipulation in human environments, as it would reduce the reliance on labor-intensive robot data collection. Despite substantial efforts, progress toward this goal has been bottle-necked by the embodiment gap between humans and robots, as well as by difficulties in extracting relevant contextual and motion cues that enable learning of autonomous policies from in-the-wild human videos. We claim that with simple yet sufficiently powerful hardware for obtaining human data and our proposed framework AINA, we are now one significant step closer to achieving this dream. AINA enables learning multi-fingered policies from data collected by anyone, anywhere, and in any environment using Aria Gen 2 glasses. These glasses are lightweight and portable, feature a high-resolution RGB camera, provide accurate on-board 3D head and hand poses, and offer a wide stereo view that can be leveraged for depth estimation of the scene. This setup enables the learning of 3D point-based policies for multi-fingered hands that are robust to background changes and can be deployed directly without requiring any robot data (including online corrections, reinforcement learning, or simulation). We compare our framework against prior human-to-robot policy learning approaches, ablate our design choices, and demonstrate results across nine everyday manipulation tasks. Robot rollouts are best viewed on our website: https://aina-robot.github.io.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Aina, a simple way to teach a robot hand to do everyday tasks (like picking up toys or opening drawers) just by watching short videos of humans doing them. The twist: the videos are recorded with smart glasses, not lab cameras, and Aina needs no robot practice data, no simulation, and no online corrections. The goal is to make learning robot skills as easy as recording a few minutes of human activity in real life.
What questions did the researchers ask?
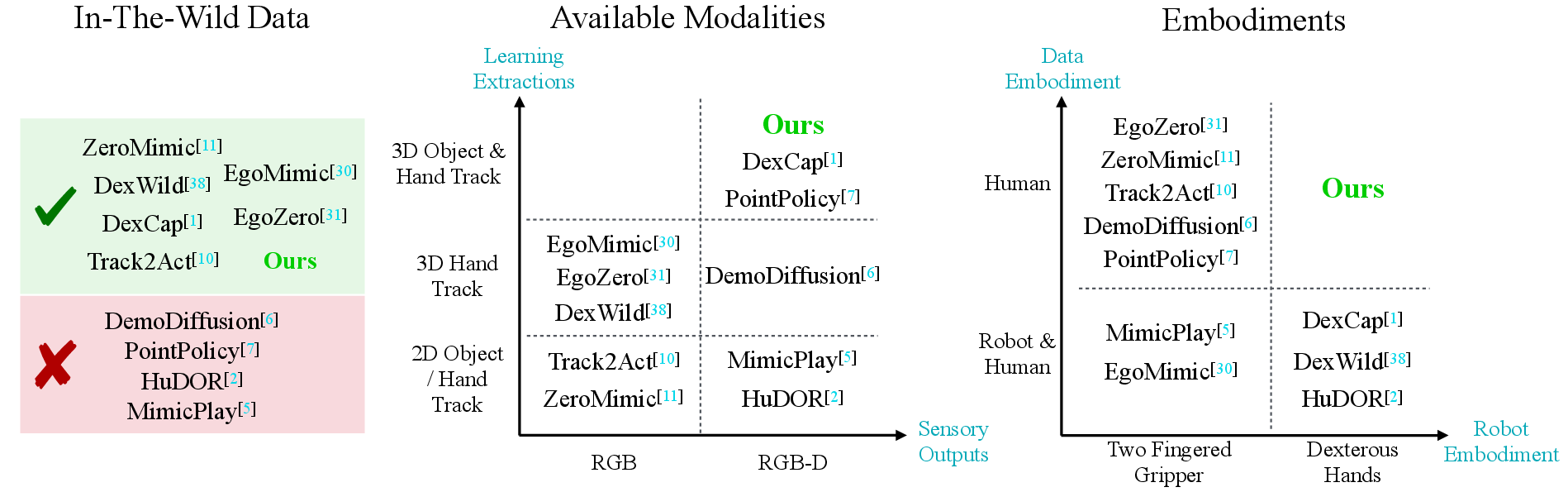
- Can a robot with a multi‑fingered hand learn to manipulate objects by learning only from human videos recorded “in the wild” (normal homes/offices), instead of from robot demos in a lab?
- Can using smart glasses—because they see what the person sees and track hands—solve the “embodiment gap” (the differences between human hands and robot hands, and between human and robot camera views)?
- Will learning with 3D information (like dots in space) be more robust than learning from regular images?
- Can one short example recorded in the robot’s workspace help align (or “anchor”) all the wild human demos so the robot can directly use them?
How did they do it?
Think of Aina as teaching by “connecting the dots” in 3D. Here’s the idea in everyday language:
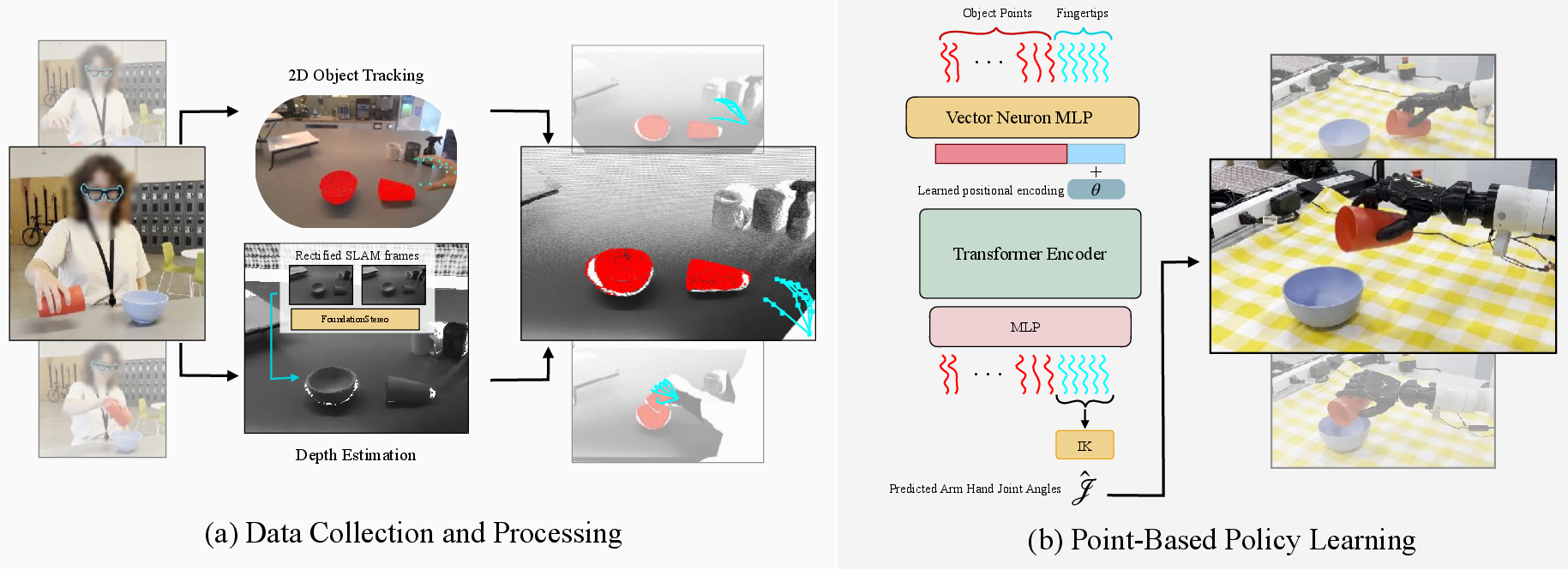
- Smart glasses as a teacher’s eyes: People wear Aria Gen 2 smart glasses while doing tasks. The glasses:
- Record video.
- Estimate where the person’s head and hands are in 3D.
- Use two side cameras (like two eyes) to estimate how far things are (depth).
- Turning the world into dots (point clouds): Instead of training from whole images (which include messy backgrounds and different lighting), Aina tracks the object as a cloud of tiny 3D dots and tracks the five fingertips as 3D points. This makes the learning focus on what matters: the object and the fingers, not the wallpaper.
- Aligning human demos to the robot: The human videos are recorded on different tables and heights. To make them comparable to the robot’s workspace, Aina:
- Uses a single short human demo recorded in the robot’s room (the “in‑scene” demo) to act like a reference map.
- Shifts and rotates each wild human demo so the object and hand are oriented the same way as in the robot’s space (like rotating a paper map so “north” points up).
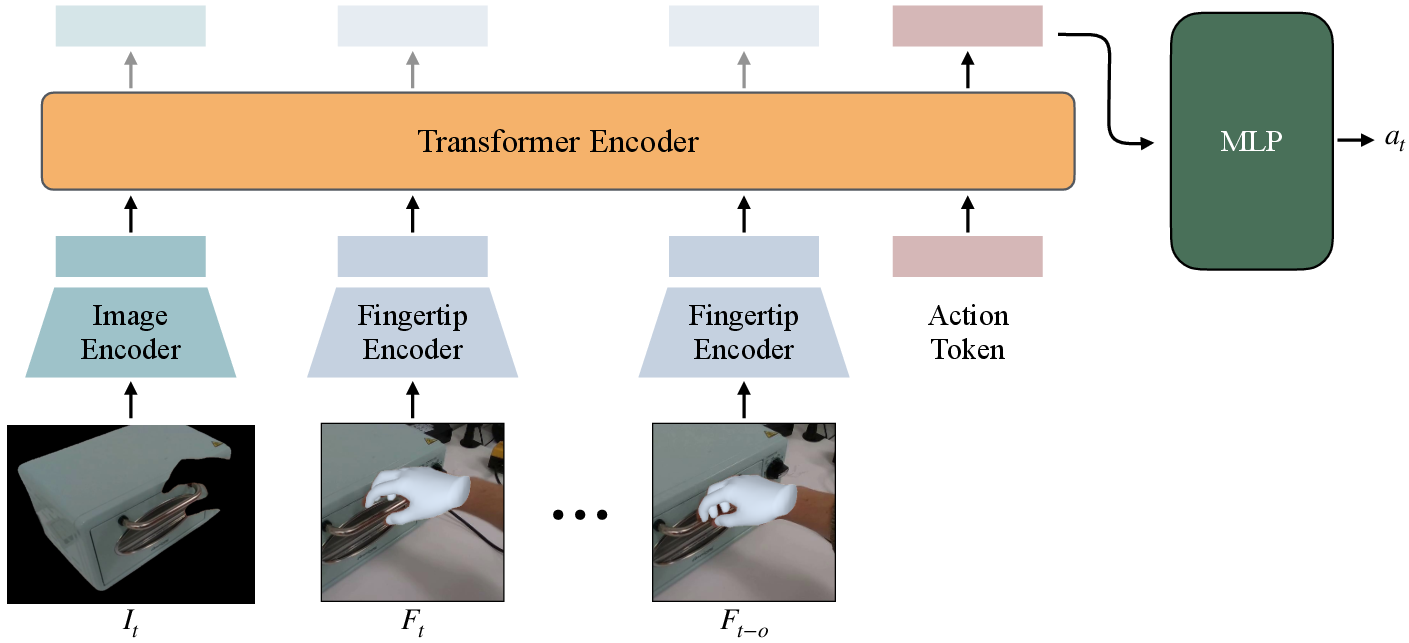
- Learning the skill as a “closed loop”: Aina trains a model to look at the recent motion of the fingertips and the object dots and predict where the fingertips should go next. “Closed loop” means it keeps checking what’s happening and adjusts continuously, rather than replaying a fixed script.
- Making the robot move: The model outputs future fingertip positions. A custom motion solver (inverse kinematics) figures out which arm and finger joints the robot must move to put its fingertips at those positions—like deciding how to bend your wrist and fingers to touch a point in space.
In short: record human actions → turn them into 3D dots over time → align them to the robot’s space → train a “dot‑based” policy → have the robot follow the predicted fingertip dots using its joints.
What did they find?
- It works without robot training data: With about 15 minutes of human video collection per task (50 short demos) plus one in‑scene demo, the robot learned to perform nine everyday tasks using a multi‑fingered hand.
- 3D dots beat images: Policies trained on object point clouds and fingertip points worked far better than image‑based baselines, especially because human videos come from moving head‑mounted cameras, while the robot’s cameras stay fixed. The dot approach ignored background and viewpoint changes.
- Better with both data types: Using both in‑the‑wild demos and a single in‑scene demo (for alignment and training) beat using only one type. The in‑scene demo helps “anchor” the coordinate system; the in‑the‑wild demos provide variety and generalization.
- Spatial and height generalization: After a quick new in‑scene demo, Aina handled changes in table height and different placements of objects.
- Some object generalization: Aina could handle new objects of similar shape and size (e.g., a different toaster or an eraser similar to the sponge), but struggled when new objects were very different in shape or weight.
Why this matters: It shows you can learn dexterous robot skills straight from natural human recordings, skipping expensive robot data collection and lab setups.
What does this mean for the future?
- Easier skill learning at scale: Because anyone can wear smart glasses and record demos anywhere, we could quickly collect rich teaching data for many tasks and environments.
- Bridging the human–robot gap: By working in 3D fingertip and object “dot space,” Aina sidesteps many differences between how humans move and how robots sense the world.
- Toward more human‑like hands: The method works with multi‑fingered hands, a step beyond simple two‑finger grippers, moving closer to true dexterity.
- Limitations and next steps:
- No force sensing: Videos don’t capture how hard to squeeze. The authors add simple rules (e.g., pinch when thumb is close) but future work could add wearables for force or muscle signals.
- Depth timing quirks: Fast head motion can slightly misalign video and depth; better 3D tracking or faster depth tools would help.
- Different cameras at train vs deploy: They trained from glasses data but deployed with different cameras. Streaming depth from glasses in real time would make it even smoother.
Overall, Aina suggests a practical path to teaching robots dexterity by learning from how people naturally use their hands—recorded through smart glasses—so robots can better help in the same spaces where people live and work.
Knowledge Gaps
Below is a single, consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved by the paper. Each item is phrased so future researchers can act on it.
- Quantify how inaccuracies in stereo-derived depth (FoundationStereo on Aria SLAM cameras) propagate into 3D point clouds, fingertip predictions, and downstream success rates; develop calibration or sensor-fusion methods to mitigate these errors under rapid head motion and rolling-shutter asynchrony.
- Remove the need for a single in-scene demonstration by learning or estimating the human-to-robot spatial transform autonomously (e.g., via scene alignment, gravity-aware SLAM, or canonicalization), and measure the performance gap compared to current alignment.
- Extend domain alignment beyond centroid translation and yaw-only rotation from the Kabsch fit; evaluate and correct for pitch/roll differences, scale errors from depth bias, and non-planar surfaces to handle sloped, vertical, or irregular workspaces.
- Assess robustness to occlusion and visibility loss of hands/objects in egocentric videos (e.g., inside drawers/ovens, behind objects) and integrate trackers or 3D reconstruction methods that maintain reliable hand/object state in these settings.
- Replace manual per-task language prompts for GroundedSAM with automatic object discovery/selection and task-object association, and evaluate the impact on policy performance and scalability.
- Provide quantitative scaling laws: success vs. number of in-the-wild demos, diversity of environments, and object instances; identify data efficiency thresholds and diminishing returns.
- Characterize failure modes of point tracking (CoTracker) under clutter, specular surfaces, motion blur, and dynamic backgrounds; compare alternative 3D trackers and mesh tracking, and benchmark their downstream policy effects.
- Investigate how errors in Aria hand pose estimation (Nimble) affect fingertip trajectory learning and robot execution; add uncertainty-aware training or filtering to improve policy robustness to pose noise.
- Evaluate closed-loop latency and control-rate requirements end to end (perception→policy→IK→actuation), and quantify how timing jitter or camera-frame rate mismatches impact success and safety.
- Generalize policies to multi-object interactions and sequential manipulation (e.g., pick-and-place with containers, tool-use) by tracking and conditioning on multiple objects and object relations, not just a single primary object point cloud.
- Replace the heuristic “5 cm grasp threshold” with learned contact-state prediction or video-based force proxies; systematically measure how lack of force/tactile information limits task success, and explore integrating wearable EMG, tactile gloves, or causal contact estimators.
- Model and compensate for differences in object shape, mass, friction, and compliance; establish methods (e.g., dynamics-aware augmentation, physical property inference) that improve zero-shot transfer to shape/weight-disjoint objects where current policies fail.
- Explore learning full-hand configurations (including palm/wrist orientation and contact patches), not just fingertip positions; evaluate whether richer hand representations improve dexterous tasks requiring nuanced orientations and pressure distributions.
- Provide an ablation of architectural choices (vector-neuron MLPs, transformer tokenization, positional encoding on fingertips only) against alternative 3D policy designs and quantify the trade-offs in generalization and sample efficiency.
- Detail and validate the custom arm–hand IK module under kinematic singularities, collision constraints, and workspace limits; evaluate portability across different arms/hands and quantify how IK feasibility constrains learned behaviors.
- Investigate camera embodiment mismatch (Aria during collection vs. RealSense during deployment) by streaming Aria data at runtime or learning cross-sensor invariances; measure the improvement from unified sensing vs. current cross-sensor setup.
- Test generalization to bimanual tasks, left-hand use, and whole-body coordination; quantify how egocentric viewpoint and hand-pose accuracy change across these settings and what modifications are needed.
- Evaluate policy robustness and safety under dynamic human presence, unexpected perturbations, and long-horizon autonomy; define safety metrics, recovery strategies, and formal guarantees for household deployment.
- Benchmark against stronger baselines that include online corrections or limited robot finetuning to contextualize claims of “no robot data” for multi-fingered hands; report standardized metrics across more tasks and object sets for fair comparison.
- Release code, datasets, and calibration tools (or provide detailed reproducibility protocols) so the community can replicate sensing pipelines, alignment, and training at scale across different labs and hardware.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be implemented now with modest integration work, leveraging the paper’s Aina framework (smart-glasses demonstrations, 3D object-centric policy learning, and fingertip-space control with IK) as described.
- Robotics and Manufacturing: “Show-and-go” dexterous task programming on the shop floor
- Use cases: pressing control buttons, opening panels/doors/drawers, manipulating knobs/latches, picking-and-placing small items into bins, light re-orientation and insertion tasks that do not require high precision force control.
- Sectors: robotics, manufacturing, warehousing/logistics, facilities operations.
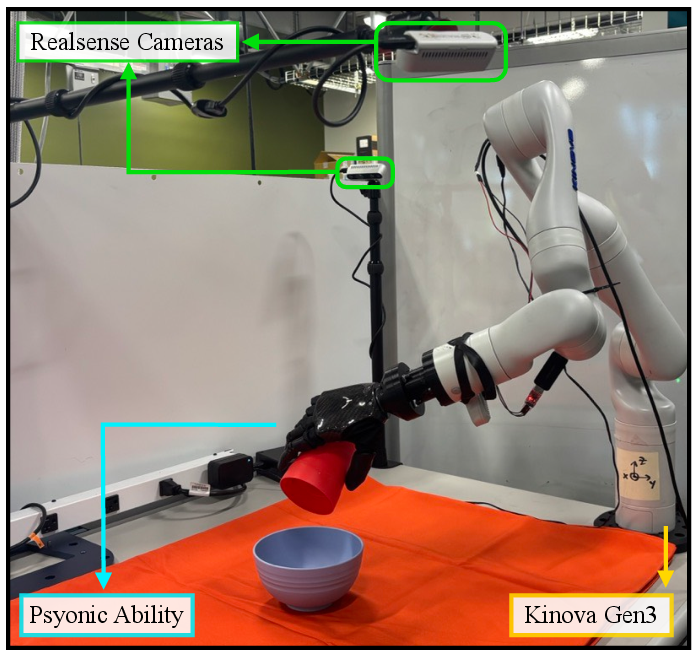
- Tools/workflows: a technician wears smart glasses to record ~50 in-the-wild demos (≈10 minutes) at their station plus a single short in-scene demo (<1 minute) near the robot; train a point-based policy (~2 hours), deploy on a multi-fingered end-effector (e.g., Ability Hand) via the provided fingertip-space IK.
- Assumptions/dependencies: access to smart glasses with egocentric RGB + SLAM and reliable hand-pose (e.g., Aria Gen 2), object segmentation/tracking (Grounded-SAM + CoTracker), stereo depth or depth estimation (FoundationStereo), one-time robot–camera hand–eye calibration, and a dexterous gripper. Tasks should be safe without tactile feedback.
- Hospitality, Retail, and Facilities: appliance operation and light cleaning
- Use cases: opening ovens, drawers, cabinets; pressing toaster/espresso machine buttons; wiping/spot-cleaning counters; moving small packed goods on shelves.
- Sectors: hospitality, retail, building services.
- Tools/workflows: site staff collect demonstrations during normal routines; the robot acquires a skill that generalizes across placements and backgrounds, using point-cloud observations robust to clutter.
- Assumptions/dependencies: similar object shapes to the demos; moderate environmental control (lighting, limited rapid head motion in data collection); trained policy may need re-anchoring with a single in-scene demo when surface height changes.
- Research and Education: low-friction pipeline for dexterous manipulation studies
- Use cases: teaching labs to study cross-embodiment learning; benchmarking object-centric policies vs. image policies; building task suites with multi-fingered hands without teleoperation rigs.
- Sectors: academia, research labs, robotics education.
- Tools/workflows: reuse the paper’s full stack (smart-glasses data capture, 3D alignment, point-based policy, fingertip-space IK); generate new task datasets quickly; compare architectures (image-based vs. point-based).
- Assumptions/dependencies: availability of research-grade smart glasses or equivalent, open-source CV components, and standard robot arms/hands.
- Software and Integration Products: off-the-shelf “glasses-to-policy” kits
- Use cases: internal or vendor SDKs that convert wearable demonstrations to deployable robot skills without robot data collection.
- Sectors: software, robotics platforms, system integrators.
- Tools/workflows: provide packaged modules—(1) in-scene alignment tool (centroid translation + z-rotation via Kabsch), (2) object-centric tracker service, (3) fingertip-action IK driver, (4) training runner with vector-neuron MLP + transformer, (5) privacy utilities (face blurring, bystander redaction).
- Assumptions/dependencies: legal/privacy compliance for human video capture; standardized camera calibration procedures; cloud or on-prem GPU for ~2-hour per-task training.
- Assistive/Prototype Home Robotics: learning simple daily-living actions
- Use cases: opening drawers/doors, pressing appliance buttons, light tidying (moving lightweight items), wiping surfaces; useful for early-stage assistive platforms.
- Sectors: assistive robotics, consumer robotics prototypes.
- Tools/workflows: caregiver/owner collects in-the-wild demonstrations; one quick in-scene demo in the home; robot learns household skills without teleoperation.
- Assumptions/dependencies: safety review; limited force demands; consistent object geometries; monitoring during initial deployments.
- Lab Automation and R&D Operations: dexterous access to enclosures and devices
- Use cases: opening incubators/ovens, operating device buttons/knobs, moving small containers between stations where grippers struggle.
- Sectors: biotech labs, materials labs, test facilities.
- Tools/workflows: researchers record demonstrations while performing routine steps; robot repeats operations, freeing time for higher-value tasks.
- Assumptions/dependencies: consistent device geometry; low-torque interactions; contamination and safety protocols around wearables.
Long-Term Applications
These use cases are enabled by the paper’s methods but require further research, scaling, sensing, or standardization—especially around tactile/force feedback, generalization across diverse objects, and real-time streaming.
- Consumer-Grade Home Robots That Learn from Owners’ Daily Activities
- Vision: owners wear AR/smart glasses during chores; robots learn skills passively from in-the-wild streams and a quick in-scene anchor; “skill cards” are packaged and reused across homes.
- Sectors: consumer robotics, smart home.
- Dependencies: privacy-preserving learning (on-device, federated), improved depth from glasses (onboard), better object generalization, robust failure recovery, household safety certification.
- Healthcare and Eldercare Assistance
- Vision: robots learn from nurses/therapists to operate medical devices, prepare supplies, and manipulate delicate items in patient rooms.
- Sectors: healthcare, eldercare.
- Dependencies: reliable tactile/force sensing and compliance control, rigorous validation and auditability of learned policies, HIPAA/privacy compliance, sterile workflow integration.
- Precision Assembly and Kitting with Dexterous Hands
- Vision: robots learn fine assembly steps from skilled workers; apply to electronics, small mechanical modules, and cable routing where two-finger grippers fail.
- Sectors: advanced manufacturing, electronics, automotive.
- Dependencies: tactile-rich manipulation (skin/force), higher-precision IK and calibration, advanced error detection, broader object generalization; structured safety and quality standards.
- Agriculture and Food Handling of Delicate Items
- Vision: learning nuanced grasp-and-place for soft produce, delicate packaging, and variable shapes directly from human field demonstrations.
- Sectors: agriculture, food processing.
- Dependencies: outdoor robustness (lighting, motion), stronger generalization to shape/weight variance, tactile feedback, mobile manipulation platforms.
- Fleet Learning and Enterprise “Skill Marketplaces”
- Vision: a company records skills once (via human demos) and deploys them across sites/robots; operators exchange skill packs with standard formats and safety metadata.
- Sectors: enterprise robotics, platforms.
- Dependencies: standardized “fingertip-action” skill interfaces, compatibility layers across different hands and arms, policy provenance/auditing, update/rollback orchestration, IP and liability frameworks.
- Real-Time “See-Then-Do” Streaming from Smart Glasses to Robots
- Vision: live coaching or rapid skill capture—glasses stream egocentric RGB+depth and hand pose; the robot imitates in near real-time with minimal training.
- Sectors: field service, remote support, industrial maintenance.
- Dependencies: low-latency on-device depth (or glasses with native depth), robust 3D tracking under head motion and occlusion, safe online adaptation with guardrails.
- Foundation Models for Dexterous Manipulation from Massive Egocentric Data
- Vision: pre-train object-centric, hand-centric 3D policies across millions of in-the-wild sequences; adapt via a single in-scene demo per site/task.
- Sectors: robotics software, AI research.
- Dependencies: large-scale curated datasets with privacy protections, cross-device calibration standards, unified evaluation benchmarks, compute-efficient training.
- Regulatory, Safety, and Workforce Policy Frameworks for Wearable-Taught Robots
- Vision: industry-wide standards for consent, bystander privacy, dataset governance, explainability/auditability of learned behaviors, and role design for human–robot collaboration.
- Sectors: policy, governance, labor relations, insurance.
- Dependencies: multi-stakeholder standards bodies, incident reporting and conformance testing, safety cases for “learned-from-humans” policies, liability and IP norms.
- Hardware Co-Evolution: Better Sensing on Both Human and Robot Sides
- Vision: smart glasses with synchronized RGB-depth and robust hand tracking; dexterous hands with integrated tactile skins; mobile arms with improved reach and compliance.
- Sectors: hardware, sensors, prosthetics/robotics.
- Dependencies: productization of research-grade glasses, standardized APIs for tactile + fingertip control, cost and reliability suitable for 24/7 operations.
Notes on feasibility and cross-cutting dependencies:
- The approach is currently strongest for everyday, low-force, visually guided tasks; lack of force/tactile feedback is a known limitation.
- Generalization is best to objects with similar shapes; performance degrades with large changes in geometry or mass—additional data or tactile sensing will be needed.
- A single in-scene demo is required to align the robot’s frame; additional in-scene anchors may be needed when workspace height or camera geometry changes.
- Robustness of the perception stack (Grounded-SAM, CoTracker, stereo depth) and synchronization between RGB/SLAM streams directly impacts success; fast head motion during data capture can degrade depth estimates.
- Privacy, consent, and data governance must be designed into any deployment that uses human-worn cameras.
Glossary
- Ablation: Systematic removal or variation of components to assess their impact on performance. "ablate our design choices"
- Affordances: Action possibilities a scene or object offers to an agent, used to guide manipulation learning. "hand-object trajectories and affordances"
- Closed-loop policy: A control policy that continuously uses observations to update actions during execution. "learn closed-loop policies"
- Closed-loop tracking: Continuously tracking objects during execution to maintain accurate state estimates. "we perform closed-loop tracking of all the object points"
- Dexterous manipulation: Fine-grained, multi-fingered control of objects, often requiring complex hand coordination. "dexterous manipulation"
- Disparity map: Per-pixel difference between stereo image pair locations, used to recover depth. "a disparity map"
- Egocentric imagery: Visual data captured from the observer’s point of view, typically via wearable sensors. "high-resolution egocentric imagery"
- Embodiment-agnostic cues: Representations that generalize across different physical agents (human vs. robot). "embodiment-agnostic cues"
- Embodiment gap: The mismatch between human and robot bodies that complicates transferring behaviors. "embodiment gap between humans and robots"
- Extrinsic matrix: Transformation from a camera’s coordinate frame to a reference frame (e.g., robot base). "compute the extrinsic matrix of cameras"
- Focal length: Camera intrinsic parameter relating scene depth to image coordinates in projection. "where f is the focal length of the left camera."
- Forward kinematics: Computing end-effector (e.g., fingertips) positions from joint angles. "use forward kinematics to compute the fingertips."
- FoundationStereo: A zero-shot stereo matching framework used to estimate depth from stereo pairs. "These inputs are passed to FoundationStereo to obtain a disparity map"
- Grasping threshold: A heuristic distance criterion to trigger finger closure in the absence of force sensing. "we set a grasping threshold"
- Hand–eye calibration: Estimating the transform between a robot base and attached cameras to unify coordinate frames. "we perform hand–eye calibration to compute the extrinsic matrix of cameras"
- IMU: Inertial Measurement Unit; sensor providing acceleration and angular velocity for pose estimation. "multiple IMUs."
- Inverse kinematics (IK): Computing joint angles that achieve desired end-effector positions. "custom full arm–hand inverse kinematics (IK) module"
- Kabsch algorithm: A method to find the optimal rotation aligning two point sets. "apply the Kabsch algorithm to compute the rigid transform"
- Keypoints: Sparse, semantically meaningful points on objects or hands used for control and perception. "predict future hand keypoints"
- Object-centric representations: Intermediate features focused on objects (e.g., tracks, keypoints) to aid policy learning. "object-centric representations such as keypoints or tracks."
- Point cloud: A set of 3D points representing object surfaces or scenes. "object point clouds as observations"
- Positional encoding: Added representations that inject location information into transformer tokens. "Positional encoding is learned for only fingertip tokens"
- RGB-D: Combined color (RGB) and depth sensing modality. "using the RGB-D cameras"
- Rigid transform: Rotation and translation (without scaling) aligning one point set to another. "compute the rigid transform between them."
- Sim-to-real transfer: Moving policies trained in simulation to real-world robots. "relied on sim-to-real transfer"
- SLAM cameras: Cameras used for Simultaneous Localization and Mapping to estimate motion and structure. "four SLAM cameras positioned around the frame"
- SO(3)-equivariant: Network property preserving behavior under 3D rotations, enabling geometry-aware learning. "SO(3)-equivariant activation layers"
- Stereo vision: Using two cameras to infer 3D structure via parallax. "stereo vision for 3D perception"
- Triangulate: Recovering 3D points from multiple 2D views using geometry. "then triangulate these estimates to obtain the 3D pose"
- Unproject: Mapping 2D image points into 3D space using depth and camera intrinsics. "unproject these 2D points into 3D"
- Vector Neuron MLPs: Neural layers operating directly on 3D vectors with rotation-aware activations. "Vector Neuron Multilayer Perceptrons (MLPs)"
Collections
Sign up for free to add this paper to one or more collections.

